使用python实现knn算法
本文实例为大家分享了python实现knn算法的具体代码,供大家参考,具体内容如下
knn算法描述
对需要分类的点依次执行以下操作:
1.计算已知类别数据集中每个点与该点之间的距离
2.按照距离递增顺序排序
3.选取与该点距离最近的k个点
4.确定前k个点所在类别出现的频率
5.返回前k个点出现频率最高的类别作为该点的预测分类
knn算法实现
数据处理
#从文件中读取数据,返回的数据和分类均为二维数组
def loadDataSet(filename):
dataSet = []
labels = []
fr = open(filename)
for line in fr.readlines():
lineArr = line.strip().split(",")
dataSet.append([float(lineArr[0]),float(lineArr[1])])
labels.append([float(lineArr[2])])
return dataSet , labels
knn算法
#计算两个向量之间的欧氏距离
def calDist(X1 , X2):
sum = 0
for x1 , x2 in zip(X1 , X2):
sum += (x1 - x2) ** 2
return sum ** 0.5
def knn(data , dataSet , labels , k):
n = shape(dataSet)[0]
for i in range(n):
dist = calDist(data , dataSet[i])
#只记录两点之间的距离和已知点的类别
labels[i].append(dist)
#按照距离递增排序
labels.sort(key=lambda x:x[1])
count = {}
#统计每个类别出现的频率
for i in range(k):
key = labels[i][0]
if count.has_key(key):
count[key] += 1
else : count[key] = 1
#按频率递减排序
sortCount = sorted(count.items(),key=lambda item:item[1],reverse=True)
return sortCount[0][0]#返回频率最高的key,即label
结果测试
已知类别数据(来源于西瓜书+虚构)
0.697,0.460,1
0.774,0.376,1
0.720,0.330,1
0.634,0.264,1
0.608,0.318,1
0.556,0.215,1
0.403,0.237,1
0.481,0.149,1
0.437,0.211,1
0.525,0.186,1
0.666,0.091,0
0.639,0.161,0
0.657,0.198,0
0.593,0.042,0
0.719,0.103,0
0.671,0.196,0
0.703,0.121,0
0.614,0.116,0
绘图方法
def drawPoints(data , dataSet, labels):
xcord1 = [];
ycord1 = [];
xcord2 = [];
ycord2 = [];
for i in range(shape(dataSet)[0]):
if labels[i][0] == 0:
xcord1.append(dataSet[i][0])
ycord1.append(dataSet[i][1])
if labels[i][0] == 1:
xcord2.append(dataSet[i][0])
ycord2.append(dataSet[i][1])
fig = plt.figure()
ax = fig.add_subplot(111)
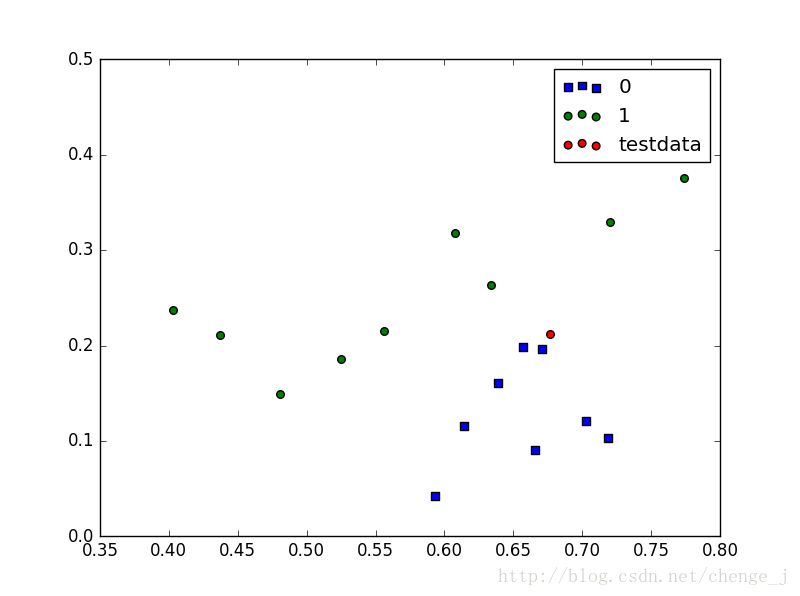
ax.scatter(xcord1, ycord1, s=30, c='blue', marker='s',label=0)
ax.scatter(xcord2, ycord2, s=30, c='green',label=1)
ax.scatter(data[0], data[1], s=30, c='red',label="testdata")
plt.legend(loc='upper right')
plt.show()
测试代码
dataSet , labels = loadDataSet('dataSet.txt')
data = [0.6767,0.2122]
drawPoints(data , dataSet, labels)
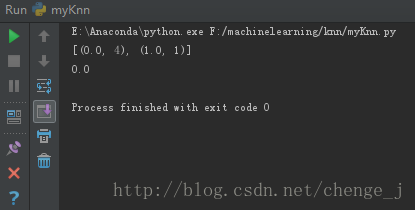
newlabels = knn(data, dataSet , labels , 5)
print newlabels
运行结果
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

以Python代码实例展示kNN算法的实际运用
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表. kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性.该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别. kNN方法在类别决策时,只与极少量的相邻样本有关.由于kNN方法主
-
python机器学习实战之最近邻kNN分类器
K近邻法是有监督学习方法,原理很简单,假设我们有一堆分好类的样本数据,分好类表示每个样本都一个对应的已知类标签,当来一个测试样本要我们判断它的类别是, 就分别计算到每个样本的距离,然后选取离测试样本最近的前K个样本的标签累计投票, 得票数最多的那个标签就为测试样本的标签. 源代码详解: #-*- coding:utf-8 -*- #!/usr/bin/python # 测试代码 约会数据分类 import KNN KNN.datingClassTest1() 标签为字符串 KNN.datingC
-
python实现kNN算法
kNN(k-nearest neighbor)是一种基本的分类与回归的算法.这里我们先只讨论分类中的kNN算法. k邻近算法的输入为实例的特征向量,对对应于特征空间中的点:输出为实例的类别,可以取多类,k近邻法是建设给定一个训练数据集,其中的实例类别已定,分类时,对于新的实例,根据其k个最邻近的训练实例的类别,通过多数表决等方式进行预测.所以可以说,k近邻法不具有显示的学习过程.k临近算法实际上是利用训练数据集对特征向量空间进行划分,并作为其分类的"模型" k值的选择,距离的度量和分类
-
Python语言描述KNN算法与Kd树
最近邻法和k-近邻法 下面图片中只有三种豆,有三个豆是未知的种类,如何判定他们的种类? 提供一种思路,即:未知的豆离哪种豆最近就认为未知豆和该豆是同一种类.由此,我们引出最近邻算法的定义:为了判定未知样本的类别,以全部训练样本作为代表点,计算未知样本与所有训练样本的距离,并以最近邻者的类别作为决策未知样本类别的唯一依据.但是,最近邻算法明显是存在缺陷的,比如下面的例子:有一个未知形状(图中绿色的圆点),如何判断它是什么形状? 显然,最近邻算法的缺陷--对噪声数据过于敏感,为了解决这个问题,我们可
-
kNN算法python实现和简单数字识别的方法
本文实例讲述了kNN算法python实现和简单数字识别的方法.分享给大家供大家参考.具体如下: kNN算法算法优缺点: 优点:精度高.对异常值不敏感.无输入数据假定 缺点:时间复杂度和空间复杂度都很高 适用数据范围:数值型和标称型 算法的思路: KNN算法(全称K最近邻算法),算法的思想很简单,简单的说就是物以类聚,也就是说我们从一堆已知的训练集中找出k个与目标最靠近的,然后看他们中最多的分类是哪个,就以这个为依据分类. 函数解析: 库函数: tile() 如tile(A,n)就是将A重复n次
-
Python代码实现KNN算法
kNN算法是k-近邻算法的简称,主要用来进行分类实践,主要思路如下: 1.存在一个训练数据集,每个数据都有对应的标签,也就是说,我们知道样本集中每一数据和他对应的类别. 2.当输入一个新数据进行类别或标签判定时,将新数据的每个特征值与训练数据集中的每个数据进行比较,计算其到训练数据集中每个点的距离(下列代码实现使用的是欧式距离). 3.然后提取k个与新数据最接近的训练数据点所对应的标签或类别. 4.出现次数最多的标签或类别,记为当前预测新数据的标签或类别. 欧式距离公式为: distance=
-
使用python实现knn算法
本文实例为大家分享了python实现knn算法的具体代码,供大家参考,具体内容如下 knn算法描述 对需要分类的点依次执行以下操作: 1.计算已知类别数据集中每个点与该点之间的距离 2.按照距离递增顺序排序 3.选取与该点距离最近的k个点 4.确定前k个点所在类别出现的频率 5.返回前k个点出现频率最高的类别作为该点的预测分类 knn算法实现 数据处理 #从文件中读取数据,返回的数据和分类均为二维数组 def loadDataSet(filename): dataSet = [] labels
-
python使用KNN算法识别手写数字
本文实例为大家分享了python使用KNN算法识别手写数字的具体代码,供大家参考,具体内容如下 # -*- coding: utf-8 -*- #pip install numpy import os import os.path from numpy import * import operator import time from os import listdir """ 描述: KNN算法实现分类器 参数: inputPoint:测试集 dataSet:训练集 lab
-
python实现kNN算法识别手写体数字的示例代码
1.总体概要 kNN算法已经在上一篇博客中说明.对于要处理手写体数字,需要处理的点主要包括: (1)图片的预处理:将png,jpg等格式的图片转换成文本数据,本博客的思想是,利用图片的rgb16进制编码(255,255,255)为白色,(0,0,0)为黑色,获取图片大小后,逐个像素进行判断分析,当此像素为空白时,在文本数据中使用0来替换,反之使用1来替换. from PIL import Image '''将图片转换成文档,使用0,1分别替代空白和数字''' pic = Image.open('
-
python使用KNN算法手写体识别
本文实例为大家分享了用KNN算法手写体识别的具体代码,供大家参考,具体内容如下 #!/usr/bin/python #coding:utf-8 import numpy as np import operator import matplotlib import matplotlib.pyplot as plt import os ''''' KNN算法 1. 计算已知类别数据集中的每个点依次执行与当前点的距离. 2. 按照距离递增排序. 3. 选取与当前点距离最小的k个点 4. 确定前k个点所
-
利用Python实现kNN算法的代码
邻近算法(k-NearestNeighbor) 是机器学习中的一种分类(classification)算法,也是机器学习中最简单的算法之一了.虽然很简单,但在解决特定问题时却能发挥很好的效果.因此,学习kNN算法是机器学习入门的一个很好的途径. kNN算法的思想非常的朴素,它选取k个离测试点最近的样本点,输出在这k个样本点中数量最多的标签(label).我们假设每一个样本有m个特征值(property),则一个样本的可以用一个m维向量表示: X =( x1,x2,... , xm ), 同样地
-
纯python实现机器学习之kNN算法示例
前面文章分别简单介绍了线性回归,逻辑回归,贝叶斯分类,并且用python简单实现.这篇文章介绍更简单的 knn, k-近邻算法(kNN,k-NearestNeighbor). k-近邻算法(kNN,k-NearestNeighbor),是最简单的机器学习分类算法之一,其核心思想在于用距离目标最近的k个样本数据的分类来代表目标的分类(这k个样本数据和目标数据最为相似). 原理 kNN算法的核心思想是用距离最近(多种衡量距离的方式)的k个样本数据来代表目标数据的分类. 具体讲,存在训练样本集, 每个
-
使用python实现kNN分类算法
k-近邻算法是基本的机器学习算法,算法的原理非常简单: 输入样本数据后,计算输入样本和参考样本之间的距离,找出离输入样本距离最近的k个样本,找出这k个样本中出现频率最高的类标签作为输入样本的类标签,很直观也很简单,就是和参考样本集中的样本做对比.下面讲一讲用python实现kNN算法的方法,这里主要用了python中常用的numpy模块,采用的数据集是来自UCI的一个数据集,总共包含1055个样本,每个样本有41个real的属性和一个类标签,包含两类(RB和NRB).我选取800条样本作为参考样
-
python KNN算法实现鸢尾花数据集分类
一.knn算法描述 1.基本概述 knn算法,又叫k-近邻算法.属于一个分类算法,主要思想如下: 一个样本在特征空间中的k个最近邻的样本中的大多数都属于某一个类别,则该样本也属于这个类别.其中k表示最近邻居的个数. 用二维的图例,说明knn算法,如下: 二维空间下数据之间的距离计算: 在n维空间两个数据之间: 2.具体步骤: (1)计算待测试数据与各训练数据的距离 (2)将计算的距离进行由小到大排序 (3)找出距离最小的k个值 (4)计算找出的值中每个类别的频次 (5)返回频次最高的类别 二.鸢
-
Python机器学习之手写KNN算法预测城市空气质量
目录 一.KNN算法简介 二.KNN算法实现思路 三.KNN算法预测城市空气质量 1. 获取数据 2. 生成测试集和训练集 3. 实现KNN算法 一.KNN算法简介 KNN(K-Nearest Neighbor)最邻近分类算法是数据挖掘分类(classification)技术中常用算法之一,其指导思想是"近朱者赤,近墨者黑",即由你的邻居来推断出你的类别. KNN最邻近分类算法的实现原理:为了判断未知样本的类别,以所有已知类别的样本作为参照,计算未知样本与所有已知样本的距离,从中选取与