浅谈一种让小程序支持JSX语法的新思路
React社区一直在探寻使用React语法开发小程序的方式,其中比较著名的项目有Taro,nanachi。而使用React语法开发小程序的难点主要就是在JSX语法上,JSX本质上是JS,相比于小程序静态模版来说太灵活。本文所说的新思路就是在处理JSX语法上的新思路,这是一种更加动态的处理思路,相比于现有方案,基本上不会限制任何JSX的写法,让你以真正的React方式处理小程序,希望这个新思路可以给任何有志于用React开发小程序的人带来启发。
现有思路的局限
在介绍新的思路之前,我们先来看下Taro(最新版1.3),nanachi是怎么在小程序端处理JSX语法的。简单来说,主要是通过在编译阶段把JSX转化为等效的小程序wxml来把React代码运行在小程序端的。
举个例子,比如React逻辑表达式:
xx && <Text>Hello</Text>
将会被转化为等效的小程序wx:if指令:
<Text wx:if="{{xx}}">Hello</Text>
这种方式把对JSX的处理,主要放在了编译阶段,他依赖于编译阶段的信息收集,以上面为例,它必须识别出逻辑表达式,然后做对应的wx:if转换处理。
那编译阶段有什么问题和局限呢?我们以下面的例子说明:
class App extends React.Component {
render () {
const a = <Text>Hello</Text>
const b = a
return (
<View>
{b}
</View>
)
}
}
首先我们声明 const a = <Text>Hello</Text>,然后把a赋值给了b,我们看下最新版本Taro 1.3的转换,如下图:

这个例子不是特别复杂,却报错了。
要想理解上面的代码为什么报错,我们首先要理解编译阶段。本质上来说在编译阶段,代码其实就是‘字符串',而编译阶段处理方案,就需要从这个‘字符串'中分析出必要的信息(通过AST,正则等方式)然后做对应的等效转换处理。
而对于上面的例子,需要做什么等效处理呢?需要我们在编译阶段分析出b是JSX片段:b = a = <Text>Hello</Text>,然后把<View>{b}</View>中的{b}等效替换为<Text>Hello</Text>。然而在编译阶段要想确定b的值是很困难的,有人说可以往前追溯来确定b的值,也不是不可以,但是考虑一下 由于b = a,那么就先要确定a的值,这个a的值怎么确定呢?需要在b可以访问到的作用域链中确定a,然而a可能又是由其他变量赋值而来,循环往复,期间一旦出现不是简单赋值的情况,比如函数调用,三元判断等运行时信息,追溯就宣告失败,要是a本身就是挂在全局对象上的变量,追溯就更加无从谈起。
所以在编译阶段 是无法简单确定b的值的。
我们再仔细看下上图的报错信息:a is not defined。

为什么说a未定义呢?这是涉及到另外一个问题,我们知道<Text>Hello</Text>,其实等效于React.createElement(Text, null, 'Hello'),而React.createElement方法的返回值就是一个普通JS对象,形如
// ReactElement对象
{
tag: Text,
props: null,
children: 'Hello'
...
}
所以上面那一段代码在JS环境真正运行的时候,大概等效如下:
class App extends React.Component {
render () {
const a = {
tag: Text,
props: null,
children: 'Hello'
...
}
const b = a
return {
tag: View,
props: null,
children: b
...
}
}
}
但是,我们刚说了编译阶段需要对JSX做等效处理,需要把JSX转换为wxml,所以<Text>Hello</Text>这个JSX片段被特殊处理了,a不再是一个普通js对象,这里我们看到a变量甚至丢失了,这里暴露了一个很严重的问题:代码语义被破坏了,也就是说由于编译时方案对JSX的特殊处理,真正运行在小程序上的代码语义并不是你的预期。这个是比较头疼。
新的思路
正因为编译时方案,有如上的限制,在使用的时候常常让你有“我还是在写React吗?”这种感觉。
下面我们介绍一种全新的处理思路,这种思路在小程序运行期间和真正的React几无区别,不会改变任何代码语义,JSX表达式只会被处理为React.createElement方法调用,实际运行的时候就是普通js对象,最终通过其他方式渲染出小程序视图。下面我们仔细说明一下这个思路的具体内容。
第一步:给每个独立的JSX片段打上唯一标识uuid,假定我们有如下代码:
const a = <Text uuid="000001">Hello</Text> const y = <View uuid="000002"> <Image/> <Text/> </View>
我们给a片段,y片段 添加了uuid属性
第二步:把React代码通过babel转义为小程序可以识别的代码,例如JSX片段用等效的React.createElement替换等
const a = React.createElement(Text, {
uuid: "000001"
}, "Hello");
第三步:提取每个独立的JSX片段,用小程序template包裹,生成wxml文件
<template name="000001">
<Text>Hello</Text>
</template>
<template name="000002">
<View uuid="000002">
<Image/>
<Text/>
</View>
</template>
<!--占位template-->
<template is="{{uiDes.name}}" data="{{...uiDes}}"/>
注意这里每一个template 的name标识和 JSX片段的唯一标识uuid是一样的。最后,需要在结尾生成一个占位模版:<template is="{{uiDes.name}}" data="{{...uiDes}}"/>。
第四步:修改ReactDOM.render的递归(React 16.x之后,不在是递归的方式)过程,递归执行阶段,聚合JSX片段的uuid属性,生成并返回uiDes数据结构。
第五步:把第四步生成的uiDes,传递给小程序环境,小程序把uiDes 设置给占位模版<template is="{{uiDes.name}}" data="{{...uiDes}}"/>,渲染出最终的视图。
我们以上面的App组件的例子来说明整个过程,首先js代码会被转义为:
class App extends React.Component {
render () {
const a = React.createElement(Text, {uuid: "000001"}, "Hello");
const b = a
return (
React.createElement(View, {uuid: "000002"} , b);
)
}
}
同时生成wxml文件:
<template name="000001">
<Text>Hello</Text>
</template>
<template name="000002">
<View>
<template is="{{child0001.name}}" data="{{...child0001}}"/>
</View>
</template>
<!--占位template-->
<template is="{{uiDes.name}}" data="{{...uiDes}}"/>
使用我们定制之后render执行ReactDOM.render(<App/>, parent)。在render的递归过程中,除了会执行常规的创建组件实例,执行生命周期之外,还会额外的收集执行过程中组件的uuid标识,最终生成 uiDes 对象
const uiDes = {
name: "000002",
child0001: {
name: 000001,
...
}
...
}
小程序获取到这个uiDes,设置给占位模版<template is="{{uiDes.name}}" data="{{...uiDes}}"/>。 最终渲染出小程序视图。
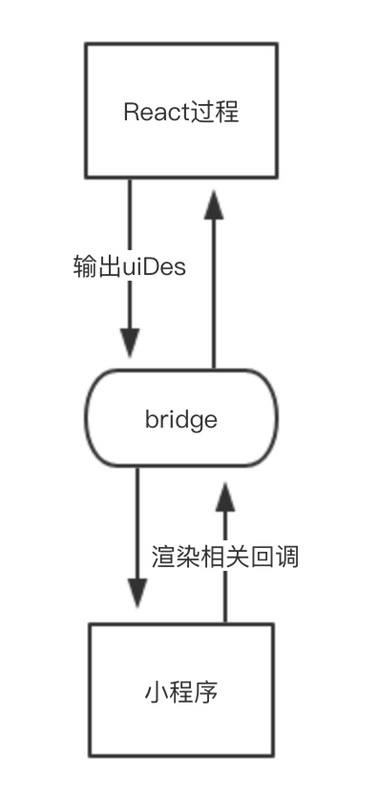
在这整个过程中,你的所有JS代码都是运行在React过程中的,语义完全一致,JSX片段也不会被任何特殊处理,只是简单的React.createElement调用,另外由于这里的React过程只是纯js运算,执行是非常迅速的,通常只有几ms。最终会输出一个uiDes数据到小程序,小程序通过这个uiDes渲染出视图。
现在我们在看之前的赋值const b = a,就不会有任何问题了,因为a 不过是普通对象。另外对于常见的编译时方案的限制,比如任意函数返回JSX片段,动态生成JSX片段,for循环使用JSX片段等等,都可以完全解除了,因为JSX片段只是js对象,你可以做任何操作,最终ReactDOM.render会搜集所有执行结果的片段的uuid标识,生成uiDes,而小程序会根据这个uiDes数据结构渲染出最终视图。
可以看出这种新的思路和以前编译时方案还是有很大的区别的,对JSX片段的处理是动态的,你可以在任何地方,任何函数出现任何JSX片段, 最终执行结果会确定渲染哪一个片段,只有执行结果的片段的uuid会被写入uiDes。这和编译时方案的静态识别有着本质的区别。
结语
"Talk is cheap. Show me your code!" 这仅仅是一个思路?还是已经有落地完整的实现呢?
是有完整的实现的,alita项目在处理JSX语法的时候,采用的就是这个思路,这也是alita基本不限制写法却可以转化整个React Native项目的原因,另外alita在这个思路上做了很多优化。如果对这个思路的具体实现有兴趣,可以去研读一下alita源码,它完全是开源的https://github.com/areslabs/alita。
当然,你也可以基于这个思路,构造出自己的React小程序开发方案。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
详解小程序原生使用ES7 async/await语法
小程序原生使用ES7 async / await 语法 小程序开发工具-详情-开启ES6转ES5 下载 regenerator 库 https://github.com/facebook/regenerator 将库中packages文件夹下 regenerator-runtime 文件夹全部复制到小程序项目中 小程序项目全局引入 regenerator 库 在app.js中引入 const regeneratorRuntime = require('./libs/runtime-module.
-
微信小程序 Mustache语法详细介绍
微信小程序 Mustache语法详解 最近微信小程序非常火,对于前端开发的程序员是个利好的消息,这里主要记录下微信小程序 Mustache语法. 小程序开发的wxml里,用到了Mustache语法.所以,非常有必要把Mustache研究下. 什么是Mustache?Mustache是一个logic-less(轻逻辑)模板解析引擎,它是为了使用户界面与业务数据(内容)分离而产生的,它可以生成特定格式的文档,通常是标准的HTML文档.比如小程序的wxml中的代码: {{userInfo.nick
-
浅谈一种让小程序支持JSX语法的新思路
React社区一直在探寻使用React语法开发小程序的方式,其中比较著名的项目有Taro,nanachi.而使用React语法开发小程序的难点主要就是在JSX语法上,JSX本质上是JS,相比于小程序静态模版来说太灵活.本文所说的新思路就是在处理JSX语法上的新思路,这是一种更加动态的处理思路,相比于现有方案,基本上不会限制任何JSX的写法,让你以真正的React方式处理小程序,希望这个新思路可以给任何有志于用React开发小程序的人带来启发. 现有思路的局限 在介绍新的思路之前,我们先来看下Ta
-
浅谈高大上的微信小程序中渲染html内容—技术分享
大部分Web应用的富文本内容都是以HTML字符串的形式存储的,通过HTML文档去展示HTML内容自然没有问题.但是,在微信小程序(下文简称为「小程序」)中,应当如何渲染这部分内容呢? 解决方案 wxParse 小程序刚上线那会儿,是无法直接渲染HTML内容的,于是就诞生了一个叫做「 wxParse 」的库.它的原理就是把HTML代码解析成树结构的数据,再通过小程序的模板把该数据渲染出来. rich-text 后来,小程序增加了「rich-text」组件用于展示富文本内容.然而,这个组件存在一个极
-
浅谈使用mpvue开发小程序需要注意和了解的知识点
一.实例生命周期 除了Vue本身的生命周期处,mpvue还兼容了小程序的生命周期,这部分生命周期的钩子来源于微信小程序的Page,除特殊情况外,不建议使用小程序的生命周期钩子. app 部分: onLaunch,初始化 onShow,当小程序启动,或从后台进入前台显示 onHide,当小程序从前台进入后台 page 部分: onLoad,监听页面加载 onShow,监听页面显示 onReady,监听页面初次渲染完成 onHide,监听页面隐藏 onUnload,监听页面卸载 onPullDown
-
浅谈linux kernel对于浮点运算的支持
目前大多数CPU都支持浮点运算单元FPU,FPU作为一个单独的协处理器放置在处理器核外,但是对于嵌入式处理器,浮点运算本来就少用,有些嵌入式处理器就会去掉浮点协处理器. X86处理器一般都是有FPU的.而ARM PPC MIPS处理器就会出现没有FPU的现象. linux kernel如何处理浮点运算,我们就分为带FPU的处理器和不带FPU的处理器来讨论. (以下为个人知识总结,研究不深,错误之处希望大家指正,共同学习) 一 对于带FPU的处理器 1 对于linux kernel来说,kerne
-
浅谈几种常用的JS类定义方法
// 方法1 对象直接量 var obj1 = { v1 : "", get_v1 : function() { return this.v1; }, set_v1 : function(v) { this.v1 = v; } }; // 方法2 定义函数对象 var Obj = function() { var v1 = ""; this.get_v1 = function() { return this.v1; }; this.set_v1 = function
-
浅谈七种常见的Hadoop和Spark项目案例
有一句古老的格言是这样说的,如果你向某人提供你的全部支持和金融支持去做一些不同的和创新的事情,他们最终却会做别人正在做的事情.如比较火爆的Hadoop.Spark和Storm,每个人都认为他们正在做一些与这些新的大数据技术相关的事情,但它不需要很长的时间遇到相同的模式.具体的实施可能有所不同,但根据我的经验,它们是最常见的七种项目. 项目一:数据整合 称之为"企业级数据中心"或"数据湖",这个想法是你有不同的数据源,你想对它们进行数据分析.这类项目包括从所有来源获得
-
浅谈三种配置linux环境变量的方法(以java为例)
1. 修改/etc/profile文件 如果你的计算机仅仅作为开发使用时推荐使用这种方法,因为所有用户的shell都有权使用这些环境变量,可能会给系统带来安全性问题. ·用文本编辑器打开/etc/profile ·在profile文件末尾加入: export JAVA_HOME=/usr/share/jdk1.6.0_14 export PATH=$JAVA_HOME/bin:$PATH export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/li
-

浅谈三种数据库的 SQL 注入
目录 SQL 注入原理 SQL 注入分类 1. 数字型注入 2. 字符型注入 3. 其他类型 常见数据库的注入 SQL Server MySQL Oracle SQL 注入原理 SQL注入攻击指的是通过构建特殊的输入作为参数传入Web应用程序,而这些输入大都是SQL语法里的一些组合,通过执行SQL语句进而执行攻击者所要的操作,其主要原因是程序没有细致地过滤用户输入的数据,致使非法数据侵入系统. SQL 注入分类 1. 数字型注入 当输入的参数为整型时,则有可能存在数字型注入漏洞. 假设存在一条
-
浅谈一种Laravel路由文件划分方式
最初,我想到了利用路由组方法可以接收文件,这就是 laravel 在 RouteServiceProvider 处拆分路由的方式. <?php namespace App\Providers; use Illuminate\Foundation\Support\Providers\RouteServiceProvider as ServiceProvider; use Illuminate\Support\Facades\Route; class RouteServiceProvider ext
-
详解Vue如何支持JSX语法
通常开发vue我们使用的是模板语法,其实还有和react相同的语法,那就是render函数,同样支持jsx语法. Vue 的模板实际是编译成了 render 函数. 1.传统的createElement方法 createElement( 'anchored-heading', { props: { level: 1 } }, [ createElement('span', 'Hello'), ' world!' ] ) 渲染成下面这样 <anchored-heading :level="1