python爬虫爬取微博评论案例详解
前几天,杨超越编程大赛火了,大家都在报名参加,而我也是其中的一员。
在我们的项目中,我负责的是数据爬取这块,我主要是把对于杨超越 的每一条评论的相关信息。
数据格式:{"name":评论人姓名,"comment_time":评论时间,"comment_info":评论内容,"comment_url":评论人的主页}
以上就是我们需要的信息。
爬虫前的分析:
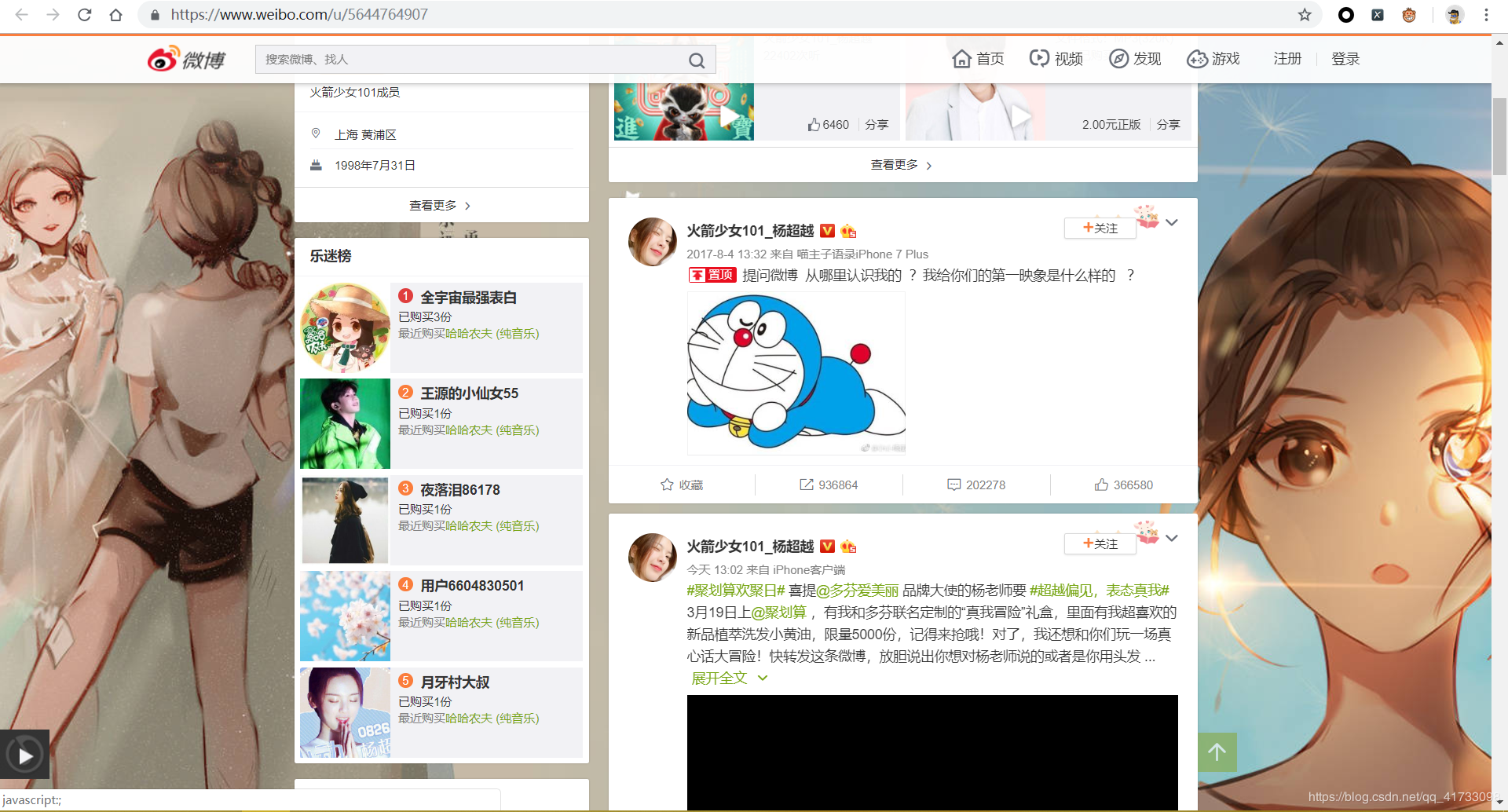
以上是杨超越的微博主页,这是我们首先需要获取到的内容。
因为我们需要等到这个主页内这些微博详情页 的链接,但是我们向下刷新,会发现微博的主页信息是ajax动态加载出来的,

这张图片就是我们向下刷新获取到 的新的链接,这个就是我们需要获取到的信息页面信息。
接下来 就是获取详情页面的信息,详情页中含有评论的相关信息,通过向下刷新,我们也会发现,相关的评论信息也是通过ajax加载出来的 ,

ok,以上就是我们针对整个流程大致的一个分析过程。
具体操作流程:
我们首相将主页获取完成以后,我们就会发现,其中 的内容带有相关的反爬措施,获取到的源码中的信息含有很多的转义符“\”,并且其中的相关“<”和“>”是通过html的语言直接编写的,这样会导致我们的页面解析出现一定的问题,我们可以用replace方法直接将这些转义符全部去掉,然后我们就可以对这个页面进行正则处理,同时我也尝试过用其他的解析方法,但是其中遇到了很多 的问题,所以我就不过多的介绍了。
当我们获取到了每一篇微博的链接以后,还需要获取一个很关键的值 id ,这个值有什么用呢,其主要的作用就是在评论页面的ajax页面的拼接地址上需要使用到。接下来就是需要寻找出我们找到的这两个ajax的url有什么特点或者是规律:
当我们从这些ajax中找到规律以后,不难发现,这个爬虫差不多大功告成了。
下面我就展示一下我的代码:
注意:请在headers中添加自己的cookie
# -*- coding: utf-8 -*-
# Created : 2018/8/26 18:33
# author :GuoLi
import requests
import json
import time
from lxml import etree
import html
import re
from bs4 import BeautifulSoup
class Weibospider:
def __init__(self):
# 获取首页的相关信息:
self.start_url = 'https://weibo.com/u/5644764907?page=1&is_all=1'
self.headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8",
"cache-control": "max-age=0",
"cookie": 使用自己本机的cookie,
"referer": "https://www.weibo.com/u/5644764907?topnav=1&wvr=6&topsug=1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.96 Safari/537.36",
}
self.proxy = {
'HTTP': 'HTTP://180.125.70.78:9999',
'HTTP': 'HTTP://117.90.4.230:9999',
'HTTP': 'HTTP://111.77.196.229:9999',
'HTTP': 'HTTP://111.177.183.57:9999',
'HTTP': 'HTTP://123.55.98.146:9999',
}
def parse_home_url(self, url): # 处理解析首页面的详细信息(不包括两个通过ajax获取到的页面)
res = requests.get(url, headers=self.headers)
response = res.content.decode().replace("\\", "")
# every_url = re.compile('target="_blank" href="(/\d+/\w+\?from=\w+&wvr=6&mod=weibotime)" rel="external nofollow" ', re.S).findall(response)
every_id = re.compile('name=(\d+)', re.S).findall(response) # 获取次级页面需要的id
home_url = []
for id in every_id:
base_url = 'https://weibo.com/aj/v6/comment/big?ajwvr=6&id={}&from=singleWeiBo'
url = base_url.format(id)
home_url.append(url)
return home_url
def parse_comment_info(self, url): # 爬取直接发表评论的人的相关信息(name,info,time,info_url)
res = requests.get(url, headers=self.headers)
response = res.json()
count = response['data']['count']
html = etree.HTML(response['data']['html'])
name = html.xpath("//div[@class='list_li S_line1 clearfix']/div[@class='WB_face W_fl']/a/img/@alt") # 评论人的姓名
info = html.xpath("//div[@node-type='replywrap']/div[@class='WB_text']/text()") # 评论信息
info = "".join(info).replace(" ", "").split("\n")
info.pop(0)
comment_time = html.xpath("//div[@class='WB_from S_txt2']/text()") # 评论时间
name_url = html.xpath("//div[@class='WB_face W_fl']/a/@href") # 评论人的url
name_url = ["https:" + i for i in name_url]
comment_info_list = []
for i in range(len(name)):
item = {}
item["name"] = name[i] # 存储评论人的网名
item["comment_info"] = info[i] # 存储评论的信息
item["comment_time"] = comment_time[i] # 存储评论时间
item["comment_url"] = name_url[i] # 存储评论人的相关主页
comment_info_list.append(item)
return count, comment_info_list
def write_file(self, path_name, content_list):
for content in content_list:
with open(path_name, "a", encoding="UTF-8") as f:
f.write(json.dumps(content, ensure_ascii=False))
f.write("\n")
def run(self):
start_url = 'https://weibo.com/u/5644764907?page={}&is_all=1'
start_ajax_url1 = 'https://weibo.com/p/aj/v6/mblog/mbloglist?ajwvr=6&domain=100406&is_all=1&page={0}&pagebar=0&pl_name=Pl_Official_MyProfileFeed__20&id=1004065644764907&script_uri=/u/5644764907&pre_page={0}'
start_ajax_url2 = 'https://weibo.com/p/aj/v6/mblog/mbloglist?ajwvr=6&domain=100406&is_all=1&page={0}&pagebar=1&pl_name=Pl_Official_MyProfileFeed__20&id=1004065644764907&script_uri=/u/5644764907&pre_page={0}'
for i in range(12): # 微博共有12页
home_url = self.parse_home_url(start_url.format(i + 1)) # 获取每一页的微博
ajax_url1 = self.parse_home_url(start_ajax_url1.format(i + 1)) # ajax加载页面的微博
ajax_url2 = self.parse_home_url(start_ajax_url2.format(i + 1)) # ajax第二页加载页面的微博
all_url = home_url + ajax_url1 + ajax_url2
for j in range(len(all_url)):
print(all_url[j])
path_name = "第{}条微博相关评论.txt".format(i * 45 + j + 1)
all_count, comment_info_list = self.parse_comment_info(all_url[j])
self.write_file(path_name, comment_info_list)
for num in range(1, 10000):
if num * 15 < int(all_count) + 15:
comment_url = all_url[j] + "&page={}".format(num + 1)
print(comment_url)
try:
count, comment_info_list = self.parse_comment_info(comment_url)
self.write_file(path_name, comment_info_list)
except Exception as e:
print("Error:", e)
time.sleep(60)
count, comment_info_list = self.parse_comment_info(comment_url)
self.write_file(path_name, comment_info_list)
del count
time.sleep(0.2)
print("第{}微博信息获取完成!".format(i * 45 + j + 1))
if __name__ == '__main__':
weibo = Weibospider()
weibo.run()
以上所述是小编给大家介绍的python爬虫爬取微博评论详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-

Python爬虫 批量爬取下载抖音视频代码实例
这篇文章主要为大家详细介绍了python批量爬取下载抖音视频,具有一定的参考价值,感兴趣的小伙伴们可以参考一下 项目源码展示: ''' 在学习过程中有什么不懂得可以加我的 python学习交流扣扣qun,934109170 群里有不错的学习教程.开发工具与电子书籍. 与你分享python企业当下人才需求及怎么从零基础学习好python,和学习什么内容. ''' # -*- coding:utf-8 -*- from contextlib import closing import request
-
Python3简单爬虫抓取网页图片代码实例
现在网上有很多python2写的爬虫抓取网页图片的实例,但不适用新手(新手都使用python3环境,不兼容python2), 所以我用Python3的语法写了一个简单抓取网页图片的实例,希望能够帮助到大家,并希望大家批评指正. import urllib.request import re import os import urllib #根据给定的网址来获取网页详细信息,得到的html就是网页的源代码 def getHtml(url): page = urllib.request.urlope
-
33个Python爬虫项目实战(推荐)
今天为大家整理了32个Python爬虫项目. 整理的原因是,爬虫入门简单快速,也非常适合新入门的小伙伴培养信心.所有链接指向GitHub,祝大家玩的愉快~O(∩_∩)O WechatSogou [1]- 微信公众号爬虫.基于搜狗微信搜索的微信公众号爬虫接口,可以扩展成基于搜狗搜索的爬虫,返回结果是列表,每一项均是公众号具体信息字典. DouBanSpider [2]- 豆瓣读书爬虫.可以爬下豆瓣读书标签下的所有图书,按评分排名依次存储,存储到Excel中,可方便大家筛选搜罗,比如筛选评价人数>1
-
Python爬虫 12306抢票开源代码过程详解
今天就和大家一起来讨论一下python实现12306余票查询(pycharm+python3.7),一起来感受一下python爬虫的简单实践 我们说先在浏览器中打开开发者工具(F12),尝试一次余票的查询,通过开发者工具查看发出请求的包 可以看到红框框中的URL就是我们向12306服务器发出的请求,那么具体是什么呢?我们来看看 https://kyfw.12306.cn/otn/leftTicket/queryZ?leftTicketDTO.train_date=2019-01-21&leftT
-
Python代理IP爬虫的新手使用教程
前言 Python爬虫要经历爬虫.爬虫被限制.爬虫反限制的过程.当然后续还要网页爬虫限制优化,爬虫再反限制的一系列道高一尺魔高一丈的过程.爬虫的初级阶段,添加headers和ip代理可以解决很多问题. 本人自己在爬取豆瓣读书的时候,就以为爬取次数过多,直接被封了IP.后来就研究了代理IP的问题. (当时不知道什么情况,差点心态就崩了...),下面给大家介绍一下我自己代理IP爬取数据的问题,请大家指出不足之处. 问题 这是我的IP被封了,一开始好好的,我还以为是我的代码问题了 思路: 从网上查找了
-
通过python爬虫赚钱的方法
(1)在校大学生.最好是数学或计算机相关专业,编程能力还可以的话,稍微看一下爬虫知识,主要涉及一门语言的爬虫库.html解析.内容存储等,复杂的还需要了解URL排重.模拟登录.验证码识别.多线程.代理.移动端抓取等.由于在校学生的工程经验比较少,建议找一些少量数据抓取的项目,而不要去接一些监控类的项目.或大规模抓取的项目.慢慢来,步子不要迈太大. (2)在职人员.如果你本身就是爬虫工程师,挣钱很简单.如果你不是,也不要紧.只要是做IT的,稍微学习一下爬虫应该不难.在职人员的优势是熟悉项目开发流程
-
python爬虫-模拟微博登录功能
微博模拟登录 这是本次爬取的网址:https://weibo.com/ 一.请求分析 找到登录的位置,填写用户名密码进行登录操作 看看这次请求响应的数据是什么 这是响应得到的数据,保存下来 exectime: 8 nonce: "HW9VSX" pcid: "gz-4ede4c6269a09f5b7a6490f790b4aa944eec" pubkey: "EB2A38568661887FA180BDDB5CABD5F21C7BFD59C090CB2D24
-
python爬虫爬取微博评论案例详解
前几天,杨超越编程大赛火了,大家都在报名参加,而我也是其中的一员. 在我们的项目中,我负责的是数据爬取这块,我主要是把对于杨超越 的每一条评论的相关信息. 数据格式:{"name":评论人姓名,"comment_time":评论时间,"comment_info":评论内容,"comment_url":评论人的主页} 以上就是我们需要的信息. 爬虫前的分析: 以上是杨超越的微博主页,这是我们首先需要获取到的内容. 因为我们需要等
-
Python爬虫爬取新闻资讯案例详解
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 一个简单的Python资讯采集案例,列表页到详情页,到数据保存,保存为txt文档,网站网页结构算是比较规整,简单清晰明了,资讯新闻内容的采集和保存! 应用到的库 requests,time,re,UserAgent,etree import requests,time,re from fake_useragent import UserAgent from lxml im
-
Python scrapy爬取小说代码案例详解
scrapy是目前python使用的最广泛的爬虫框架 架构图如下 解释: Scrapy Engine(引擎): 负责Spider.ItemPipeline.Downloader.Scheduler中间的通讯,信号.数据传递等. Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎. Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Respon
-
Python爬虫爬取微博热搜保存为 Markdown 文件的源码
什么是爬虫? 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用的名字还有蚂蚁.自动索引.模拟程序或者蠕虫. 其实通俗的讲就是通过程序去获取web页面上自己想要的数据,也就是自动抓取数据 爬虫可以做什么? 你可以爬取小姐姐的图片,爬取自己有兴趣的岛国视频,或者其他任何你想要的东西,前提是,你想要的资源必须可以通过浏览器访问的到. 爬虫的本质是什么? 上面关于爬虫可以做什么,定义了一个前提
-
python爬取微博评论的实例讲解
python爬虫是程序员们一定会掌握的知识,练习python爬虫时,很多人会选择爬取微博练手.python爬虫微博根据微博存在于不同媒介上,所爬取的难度有差异,无论是python新入手的小白,还是已经熟练掌握的程序员,可以拿来练手.本文介绍python爬取微博评论的代码实例. 一.爬虫微博 与QQ空间爬虫类似,可以爬取新浪微博用户的个人信息.微博信息.粉丝.关注和评论等. 爬虫抓取微博的速度可以达到 1300万/天 以上,具体要视网络情况. 难度程度排序:网页端>手机端>移动端.微博端就是最好
-
python实战之Scrapy框架爬虫爬取微博热搜
前言:大概一年前写的,前段时间跑了下,发现还能用,就分享出来了供大家学习,代码的很多细节不太记得了,也尽力做了优化. 因为毕竟是微博,反爬技术手段还是很周全的,怎么绕过反爬的话要在这说都可以单独写几篇文章了(包括网页动态加载,ajax动态请求,token密钥等等,特别是二级评论,藏得很深,记得当时想了很久才成功拿到),直接上代码. 主要实现的功能: 0.理所应当的,绕过了各种反爬. 1.爬取全部的热搜主要内容. 2.爬取每条热搜的相关微博. 3.爬取每条相关微博的评论,评论用户的各种详细信息.
-
python爬虫爬取监控教务系统的思路详解
这几天考了大大小小几门课,教务系统又没有成绩通知功能,为了急切想知道自己挂了多少门,于是我写下这个脚本. 设计思路: 设计思路很简单,首先对已有的成绩进行处理,变为list集合,然后定时爬取教务系统查成绩的页面,对爬取的成绩也处理成list集合,如果newList的长度增加了,就找出增加的部分,并通过邮件通知我. 脚本运行效果: 服务器: 发送邮件通知: 代码如下: import datetime import time from email.header import Header impor
-
Python爬虫之爬取淘女郎照片示例详解
本篇目标 抓取淘宝MM的姓名,头像,年龄 抓取每一个MM的资料简介以及写真图片 把每一个MM的写真图片按照文件夹保存到本地 熟悉文件保存的过程 1.URL的格式 在这里我们用到的URL是 http://mm.taobao.com/json/request_top_list.htm?page=1,问号前面是基地址,后面的参数page是代表第几页,可以随意更换地址.点击开之后,会发现有一些淘宝MM的简介,并附有超链接链接到个人详情页面. 我们需要抓取本页面的头像地址,MM姓名,MM年龄,MM居住地,
-
详解Python爬虫爬取博客园问题列表所有的问题
一.准备工作 首先,本文使用的技术为 python+requests+bs4,没有了解过可以先去了解一下. 我们的需求是将博客园问题列表中的所有问题的题目爬取下来. 二.分析: 首先博客园问题列表页面右键点击检查 通过Element查找问题所对应的属性或标签 可以发现在div class ="one_entity"中存在页面中分别对应每一个问题 接着div class ="news_item"中h2标签下是我们想要拿到的数据 三.代码实现 首先导入requests和
-
利用Python爬虫爬取金融期货数据的案例分析
目录 任务简介 解决步骤 代码实现 总结 大家好 我是政胤今天教大家爬取金融期货数据 任务简介 首先,客户原需求是获取https://hq.smm.cn/copper网站上的价格数据(注:获取的是网站上的公开数据),如下图所示: 如果以该网站为目标,则需要解决的问题是“登录”用户,再将价格解析为表格进行输出即可.但是,实际上客户核心目标是获取“沪铜CU2206”的历史价格,虽然该网站也有提供数据,但是需要“会员”才可以访问,而会员需要氪金...... 数据的价值!!! 鉴于,客户需求仅仅是“沪铜