Python网络爬虫之爬取微博热搜
微博热搜的爬取较为简单,我只是用了lxml和requests两个库
url= https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6
1.分析网页的源代码:右键--查看网页源代码.
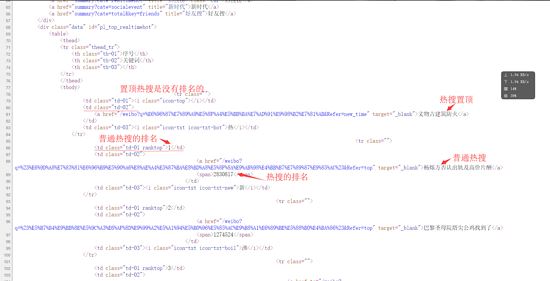
从网页代码中可以获取到信息
(1)热搜的名字都在<td class="td-02">的子节点<a>里
(2)热搜的排名都在<td class=td-01 ranktop>的里(注意置顶微博是没有排名的!)
(3)热搜的访问量都在<td class="td-02">的子节点<span>里
2.requests获取网页
(1)先设置url地址,然后模拟浏览器(这一步可以不用)防止被认出是爬虫程序。
###网址
url="https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6"
###模拟浏览器,这个请求头windows下都能用
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'}
(2)利用req uests库的get()和lxml的etr ee()来获 取网页代码
###获取html页面 html=etree.HTML(requests.get(url,headers=header).text)
3.构造xpath路径
上面第一步中三个xath路径分别是:
affair=html.xpath('//td[@class="td-02"]/a/text()')
rank=html.xpath('//td[@class="td-01 ranktop"]/text()')
view=html.xpath('//td[@class="td-02"]/span/text()')
xpath的返回结果是列表,所以affair、rank、view都是字符串列表
4.格式化输出
需要注意的是affair中多了一个置顶热搜,我们先将他分离出来。
top=affair[0] affair=affair[1:]
这里利用了python的切片。
print('{0:<10}\t{1:<40}'.format("top",top))
for i in range(0, len(affair)):
print("{0:<10}\t{1:{3}<30}\t{2:{3}>20}".format(rank[i],affair[i],view[i],chr(12288)))
这里还是没能做到完全对齐。。。
5.全部代码
###导入模块
import requests
from lxml import etree
###网址
url="https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6"
###模拟浏览器
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'}
###主函数
def main():
###获取html页面
html=etree.HTML(requests.get(url,headers=header).text)
rank=html.xpath('//td[@class="td-01 ranktop"]/text()')
affair=html.xpath('//td[@class="td-02"]/a/text()')
view = html.xpath('//td[@class="td-02"]/span/text()')
top=affair[0]
affair=affair[1:]
print('{0:<10}\t{1:<40}'.format("top",top))
for i in range(0, len(affair)):
print("{0:<10}\t{1:{3}<30}\t{2:{3}>20}".format(rank[i],affair[i],view[i],chr(12288)))
main()
结果展示:

总结
以上所述是小编给大家介绍的Python网络爬虫之爬取微博热搜,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-
Python实现爬虫从网络上下载文档的实例代码
最近在学习Python,自然接触到了爬虫,写了一个小型爬虫软件,从初始Url解析网页,使用正则获取待爬取链接,使用beautifulsoup解析获取文本,使用自己写的输出器可以将文本输出保存,具体代码如下: Spider_main.py # coding:utf8 from baike_spider import url_manager, html_downloader, html_parser, html_outputer class SpiderMain(object): def __ini
-
python网络爬虫 CrawlSpider使用详解
CrawlSpider 作用:用于进行全站数据爬取 CrawlSpider就是Spider的一个子类 如何新建一个基于CrawlSpider的爬虫文件 scrapy genspider -t crawl xxx www.xxx.com 例:choutiPro LinkExtractor连接提取器:根据指定规则(正则)进行连接的提取 Rule规则解析器:将连接提取器提取到的连接进行请求发送,然后对获取的页面进行指定规则[callback]的解析 一个链接提取器对应唯一一个规则解析器 例:crawl
-

选择Python写网络爬虫的优势和理由
什么是网络爬虫? 网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成.传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件 爬虫有什么用? 做为通用搜索引擎网页收集器.(google,baidu) 做垂直搜索引擎. 科学研究:在线人类行为,在线社群演化,人类动力学研究,计量社会学,复杂网络,数据挖掘,等领域的实证研究都需要大量数据,网络爬虫是收集相关数据的利器.
-
详解用python写网络爬虫-爬取新浪微博评论
新浪微博需要登录才能爬取,这里使用m.weibo.cn这个移动端网站即可实现简化操作,用这个访问可以直接得到的微博id. 分析新浪微博的评论获取方式得知,其采用动态加载.所以使用json模块解析json代码 单独编写了字符优化函数,解决微博评论中的嘈杂干扰字符 本函数是用python写网络爬虫的终极目的,所以采用函数化方式编写,方便后期优化和添加各种功能 # -*- coding:gbk -*- import re import requests import json from lxml im
-
Python3网络爬虫中的requests高级用法详解
本节我们再来了解下 Requests 的一些高级用法,如文件上传,代理设置,Cookies 设置等等. 1. 文件上传 我们知道 Reqeuests 可以模拟提交一些数据,假如有的网站需要我们上传文件,我们同样可以利用它来上传,实现非常简单,实例如下: import requests files = {'file': open('favicon.ico', 'rb')} r = requests.post('http://httpbin.org/post', files=files) print
-
Python3网络爬虫开发实战之极验滑动验证码的识别
上节我们了解了图形验证码的识别,简单的图形验证码我们可以直接利用 Tesserocr 来识别,但是近几年又出现了一些新型验证码,如滑动验证码,比较有代表性的就是极验验证码,它需要拖动拼合滑块才可以完成验证,相对图形验证码来说识别难度上升了几个等级,本节来讲解下极验验证码的识别过程. 1. 本节目标 本节我们的目标是用程序来识别并通过极验验证码的验证,其步骤有分析识别思路.识别缺口位置.生成滑块拖动路径,最后模拟实现滑块拼合通过验证. 2. 准备工作 本次我们使用的 Python 库是 Selen
-
Python爬虫实例_城市公交网络站点数据的爬取方法
爬取的站点:http://beijing.8684.cn/ (1)环境配置,直接上代码: # -*- coding: utf-8 -*- import requests ##导入requests from bs4 import BeautifulSoup ##导入bs4中的BeautifulSoup import os headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML,
-
Python实现可获取网易页面所有文本信息的网易网络爬虫功能示例
本文实例讲述了Python实现可获取网易页面所有文本信息的网易网络爬虫功能.分享给大家供大家参考,具体如下: #coding=utf-8 #--------------------------------------- # 程序:网易爬虫 # 作者:ewang # 日期:2016-7-6 # 语言:Python 2.7 # 功能:获取网易页面中的文本信息并保存到TXT文件中. #--------------------------------------- import string impor
-
Python网络爬虫之爬取微博热搜
微博热搜的爬取较为简单,我只是用了lxml和requests两个库 url= https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6 1.分析网页的源代码:右键--查看网页源代码. 从网页代码中可以获取到信息 (1)热搜的名字都在<td class="td-02">的子节点<a>里 (2)热搜的排名都在<td class=td-01 ranktop>的里(注意置顶微博是
-
Python爬虫爬取微博热搜保存为 Markdown 文件的源码
什么是爬虫? 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用的名字还有蚂蚁.自动索引.模拟程序或者蠕虫. 其实通俗的讲就是通过程序去获取web页面上自己想要的数据,也就是自动抓取数据 爬虫可以做什么? 你可以爬取小姐姐的图片,爬取自己有兴趣的岛国视频,或者其他任何你想要的东西,前提是,你想要的资源必须可以通过浏览器访问的到. 爬虫的本质是什么? 上面关于爬虫可以做什么,定义了一个前提
-
python实战之Scrapy框架爬虫爬取微博热搜
前言:大概一年前写的,前段时间跑了下,发现还能用,就分享出来了供大家学习,代码的很多细节不太记得了,也尽力做了优化. 因为毕竟是微博,反爬技术手段还是很周全的,怎么绕过反爬的话要在这说都可以单独写几篇文章了(包括网页动态加载,ajax动态请求,token密钥等等,特别是二级评论,藏得很深,记得当时想了很久才成功拿到),直接上代码. 主要实现的功能: 0.理所应当的,绕过了各种反爬. 1.爬取全部的热搜主要内容. 2.爬取每条热搜的相关微博. 3.爬取每条相关微博的评论,评论用户的各种详细信息.
-
如何用python爬取微博热搜数据并保存
主要用到requests和bf4两个库 将获得的信息保存在d://hotsearch.txt下 import requests; import bs4 mylist=[] r = requests.get(url='https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6',timeout=10) print(r.status_code) # 获取返回状态 r.encoding=r.apparent_encoding demo
-
Python定时爬取微博热搜示例介绍
目录 前言 页面分析 采集代码 设置定时运行 前言 相信大家在工作无聊时,总想掏出手机,看看微博热搜在讨论什么有趣的话题,但又不方便直接打开微博浏览,今天就和大家分享一个有趣的小爬虫,定时采集微博热搜榜&热评,下面让我们来看看具体的实现方法. 页面分析 热搜页 热榜首页:https://s.weibo.com/top/summary?cate=realtimehot 热榜首页的榜单中共五十条数据,在这个页面,我们需要获取排行.热度.标题,以及详情页的链接. 我们打开页面后要先 登录,之后使用 F
-
Python 爬取微博热搜页面
前期准备: fiddler 抓包工具Python3.6谷歌浏览器 分析: 1.清理浏览器缓存cookie以至于看到整个请求过程,因为Python代码开始请求的时候不带任何缓存.2.不考虑过多的header参数,先请求一次,看看返回结果 图中第一个链接是无缓存cookie直接访问的,状态码为302进行了重定向,用返回值.url会得到该url后面会用到(headers里的Referer参数值)2 ,3 链接没有用太大用处为第 4 个链接做铺垫但是都可以用固定参数可以不用访问 cb 和fp参数都是前两
-
Python 爬取微博热搜页面
前期准备: fiddler 抓包工具Python3.6谷歌浏览器 分析: 1.清理浏览器缓存cookie以至于看到整个请求过程,因为Python代码开始请求的时候不带任何缓存.2.不考虑过多的header参数,先请求一次,看看返回结果 图中第一个链接是无缓存cookie直接访问的,状态码为302进行了重定向,用返回值.url会得到该url后面会用到(headers里的Referer参数值)2 ,3 链接没有用太大用处为第 4 个链接做铺垫但是都可以用固定参数可以不用访问 访问https://pa
-
python+selenium爬取微博热搜存入Mysql的实现方法
最终的效果 废话不多少,直接上图 这里可以清楚的看到,数据库里包含了日期,内容,和网站link 下面我们来分析怎么实现 使用的库 import requests from selenium.webdriver import Chrome, ChromeOptions import time from sqlalchemy import create_engine import pandas as pd 目标分析 这是微博热搜的link:点我可以到目标网页 首先我们使用selenium对目标网页进
-
用Python实现爬取百度热搜信息
目录 前言 库函数准备 数据爬取 网页爬取 数据解析 数据保存 总结 前言 何为爬虫,其实就是利用计算机模拟人对网页的操作 例如 模拟人类浏览购物网站 使用爬虫前一定要看目标网站可刑不可刑 :-) 可以在目标网站添加/robots.txt 查看网页具体信息 例如对天猫 可输入 https://brita.tmall.com/robots.txt 进行查看 User-agent 代表发送请求的对象 星号*代表任何搜索引擎 Disallow 代表不允许访问的部分 /代表从根目录开始 Allow代
-
Python 通过xpath属性爬取豆瓣热映的电影信息
目录 前言 页面分析 实现过程 创建项目 Item定义 中间件操作定义 爬虫定义 数据管道定义 配置设置 执行验证 总结 前言 声明一下:本文主要是研究使用,没有别的用途. GitHub仓库地址:github项目仓库 页面分析 主要爬取页面为:https://movie.douban.com/cinema/nowplaying/nanjing/ 至于后面的地区,可以按照自己的需要改一下,不过多赘述了.页面需要点击一下展开全部影片,才能显示全部内容,不然只有15部.所以我们使用selenium的时