SpringBoot 2.0 整合sharding-jdbc中间件实现数据分库分表
一、水平分割
1、水平分库
1)、概念:
以字段为依据,按照一定策略,将一个库中的数据拆分到多个库中。
2)、结果
每个库的结构都一样;数据都不一样;
所有库的并集是全量数据;
2、水平分表
1)、概念
以字段为依据,按照一定策略,将一个表中的数据拆分到多个表中。
2)、结果
每个表的结构都一样;数据都不一样;
所有表的并集是全量数据;
二、Shard-jdbc 中间件
1、架构图

2、特点
1)、Sharding-JDBC直接封装JDBC API,旧代码迁移成本几乎为零。
2)、适用于任何基于Java的ORM框架,如Hibernate、Mybatis等 。
3)、可基于任何第三方的数据库连接池,如DBCP、C3P0、 BoneCP、Druid等。
4)、以jar包形式提供服务,无proxy代理层,无需额外部署,无其他依赖。
5)、分片策略灵活,可支持等号、between、in等多维度分片,也可支持多分片键。
6)、SQL解析功能完善,支持聚合、分组、排序、limit、or等查询。
三、项目演示
1、项目结构
springboot 2.0 版本
druid 1.1.13 版本
sharding-jdbc 3.1 版本
2、数据库配置


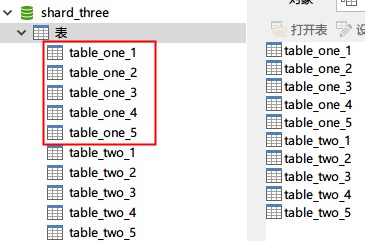
一台基础库映射(shard_one)
两台库做分库分表(shard_two,shard_three)。
表使用:table_one,table_two
3、核心代码块
数据源配置文件
spring:
datasource:
# 数据源:shard_one
dataOne:
type: com.alibaba.druid.pool.DruidDataSource
druid:
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/shard_one?useUnicode=true&characterEncoding=UTF8&zeroDateTimeBehavior=convertToNull&useSSL=false
username: root
password: 123
initial-size: 10
max-active: 100
min-idle: 10
max-wait: 60000
pool-prepared-statements: true
max-pool-prepared-statement-per-connection-size: 20
time-between-eviction-runs-millis: 60000
min-evictable-idle-time-millis: 300000
max-evictable-idle-time-millis: 60000
validation-query: SELECT 1 FROM DUAL
# validation-query-timeout: 5000
test-on-borrow: false
test-on-return: false
test-while-idle: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
# 数据源:shard_two
dataTwo:
type: com.alibaba.druid.pool.DruidDataSource
druid:
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/shard_two?useUnicode=true&characterEncoding=UTF8&zeroDateTimeBehavior=convertToNull&useSSL=false
username: root
password: 123
initial-size: 10
max-active: 100
min-idle: 10
max-wait: 60000
pool-prepared-statements: true
max-pool-prepared-statement-per-connection-size: 20
time-between-eviction-runs-millis: 60000
min-evictable-idle-time-millis: 300000
max-evictable-idle-time-millis: 60000
validation-query: SELECT 1 FROM DUAL
# validation-query-timeout: 5000
test-on-borrow: false
test-on-return: false
test-while-idle: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
# 数据源:shard_three
dataThree:
type: com.alibaba.druid.pool.DruidDataSource
druid:
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/shard_three?useUnicode=true&characterEncoding=UTF8&zeroDateTimeBehavior=convertToNull&useSSL=false
username: root
password: 123
initial-size: 10
max-active: 100
min-idle: 10
max-wait: 60000
pool-prepared-statements: true
max-pool-prepared-statement-per-connection-size: 20
time-between-eviction-runs-millis: 60000
min-evictable-idle-time-millis: 300000
max-evictable-idle-time-millis: 60000
validation-query: SELECT 1 FROM DUAL
# validation-query-timeout: 5000
test-on-borrow: false
test-on-return: false
test-while-idle: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
数据库分库策略
/**
* 数据库映射计算
*/
public class DataSourceAlg implements PreciseShardingAlgorithm<String> {
private static Logger LOG = LoggerFactory.getLogger(DataSourceAlg.class);
@Override
public String doSharding(Collection<String> names, PreciseShardingValue<String> value) {
LOG.debug("分库算法参数 {},{}",names,value);
int hash = HashUtil.rsHash(String.valueOf(value.getValue()));
return "ds_" + ((hash % 2) + 2) ;
}
}
数据表1分表策略
/**
* 分表算法
*/
public class TableOneAlg implements PreciseShardingAlgorithm<String> {
private static Logger LOG = LoggerFactory.getLogger(TableOneAlg.class);
/**
* 该表每个库分5张表
*/
@Override
public String doSharding(Collection<String> names, PreciseShardingValue<String> value) {
LOG.debug("分表算法参数 {},{}",names,value);
int hash = HashUtil.rsHash(String.valueOf(value.getValue()));
return "table_one_" + (hash % 5+1);
}
}
数据表2分表策略
/**
* 分表算法
*/
public class TableTwoAlg implements PreciseShardingAlgorithm<String> {
private static Logger LOG = LoggerFactory.getLogger(TableTwoAlg.class);
/**
* 该表每个库分5张表
*/
@Override
public String doSharding(Collection<String> names, PreciseShardingValue<String> value) {
LOG.debug("分表算法参数 {},{}",names,value);
int hash = HashUtil.rsHash(String.valueOf(value.getValue()));
return "table_two_" + (hash % 5+1);
}
}
数据源集成配置
/**
* 数据库分库分表配置
*/
@Configuration
public class ShardJdbcConfig {
// 省略了 druid 配置,源码中有
/**
* Shard-JDBC 分库配置
*/
@Bean
public DataSource dataSource (@Autowired DruidDataSource dataOneSource,
@Autowired DruidDataSource dataTwoSource,
@Autowired DruidDataSource dataThreeSource) throws Exception {
ShardingRuleConfiguration shardJdbcConfig = new ShardingRuleConfiguration();
shardJdbcConfig.getTableRuleConfigs().add(getTableRule01());
shardJdbcConfig.getTableRuleConfigs().add(getTableRule02());
shardJdbcConfig.setDefaultDataSourceName("ds_0");
Map<String,DataSource> dataMap = new LinkedHashMap<>() ;
dataMap.put("ds_0",dataOneSource) ;
dataMap.put("ds_2",dataTwoSource) ;
dataMap.put("ds_3",dataThreeSource) ;
Properties prop = new Properties();
return ShardingDataSourceFactory.createDataSource(dataMap, shardJdbcConfig, new HashMap<>(), prop);
}
/**
* Shard-JDBC 分表配置
*/
private static TableRuleConfiguration getTableRule01() {
TableRuleConfiguration result = new TableRuleConfiguration();
result.setLogicTable("table_one");
result.setActualDataNodes("ds_${2..3}.table_one_${1..5}");
result.setDatabaseShardingStrategyConfig(new StandardShardingStrategyConfiguration("phone", new DataSourceAlg()));
result.setTableShardingStrategyConfig(new StandardShardingStrategyConfiguration("phone", new TableOneAlg()));
return result;
}
private static TableRuleConfiguration getTableRule02() {
TableRuleConfiguration result = new TableRuleConfiguration();
result.setLogicTable("table_two");
result.setActualDataNodes("ds_${2..3}.table_two_${1..5}");
result.setDatabaseShardingStrategyConfig(new StandardShardingStrategyConfiguration("phone", new DataSourceAlg()));
result.setTableShardingStrategyConfig(new StandardShardingStrategyConfiguration("phone", new TableTwoAlg()));
return result;
}
}
测试代码执行流程
@RestController
public class ShardController {
@Resource
private ShardService shardService ;
/**
* 1、建表流程
*/
@RequestMapping("/createTable")
public String createTable (){
shardService.createTable();
return "success" ;
}
/**
* 2、生成表 table_one 数据
*/
@RequestMapping("/insertOne")
public String insertOne (){
shardService.insertOne();
return "SUCCESS" ;
}
/**
* 3、生成表 table_two 数据
*/
@RequestMapping("/insertTwo")
public String insertTwo (){
shardService.insertTwo();
return "SUCCESS" ;
}
/**
* 4、查询表 table_one 数据
*/
@RequestMapping("/selectOneByPhone/{phone}")
public TableOne selectOneByPhone (@PathVariable("phone") String phone){
return shardService.selectOneByPhone(phone);
}
/**
* 5、查询表 table_one 数据
*/
@RequestMapping("/selectTwoByPhone/{phone}")
public TableTwo selectTwoByPhone (@PathVariable("phone") String phone){
return shardService.selectTwoByPhone(phone);
}
}
四、项目源码
GitHub:知了一笑
https://github.com/cicadasmile/middle-ware-parent
总结
以上所述是小编给大家介绍的SpringBoot 2.0 整合sharding-jdbc中间件实现数据分库分表,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-
详解Spring Boot中整合Sharding-JDBC读写分离示例
在我<Spring Cloud微服务-全栈技术与案例解析>书中,第18章节分库分表解决方案里有对Sharding-JDBC的使用进行详细的讲解. 之前是通过XML方式来配置数据源,读写分离策略,分库分表策略等,之前有朋友也问过我,有没有Spring Boot的方式来配置,既然已经用Spring Boot还用XML来配置感觉有点不协调. 其实吧我个人觉得只要能用,方便看,看的懂就行了,mybatis的SQL不也是写在XML中嘛. 今天就给大家介绍下Spring Boot方式的使用,主要讲解读写分
-
spring boot使用sharding jdbc的配置方式
本文介绍了spring boot使用sharding jdbc的配置方式,分享给大家,具体如下: 说明 要排除DataSourceAutoConfiguration,否则多数据源无法配置 @SpringBootApplication @EnableAutoConfiguration(exclude={DataSourceAutoConfiguration.class}) public class Application { public static void main(String[] arg
-
利用Sharding-Jdbc组件实现分表
看到了当当开源的Sharding-JDBC组件,它可以在几乎不修改代码的情况下完成分库分表的实现.摘抄其中一段介绍: Sharding-JDBC直接封装JDBC API,可以理解为增强版的JDBC驱动,旧代码迁移成本几乎为零: 可适用于任何基于java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC. 可基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid等. 理论上可支持任意实现JDB
-
SpringBoot 2.0 整合sharding-jdbc中间件实现数据分库分表
一.水平分割 1.水平分库 1).概念: 以字段为依据,按照一定策略,将一个库中的数据拆分到多个库中. 2).结果 每个库的结构都一样:数据都不一样: 所有库的并集是全量数据: 2.水平分表 1).概念 以字段为依据,按照一定策略,将一个表中的数据拆分到多个表中. 2).结果 每个表的结构都一样:数据都不一样: 所有表的并集是全量数据: 二.Shard-jdbc 中间件 1.架构图 2.特点 1).Sharding-JDBC直接封装JDBC API,旧代码迁移成本几乎为零. 2).适
-
SpringBoot+MybatisPlus+Mysql+Sharding-JDBC分库分表
目录 一.序言 1.组件及版本选择 2.预期目标 二.代码实现 (一)素材准备 1.实体类 2.Mapper类 3.全局配置文件 (二)增删查改 1.保存数据 2.查询列表数据 3.分页查询数据 4.查询详情 5.删除数据 6.修改数据 三.理论分析 1.选择分片列 2.扩容 一.序言 在实际业务中,单表数据增长较快,很容易达到数据瓶颈,比如单表百万级别数据量.当数据量继续增长时,数据的查询性能即使有索引的帮助下也不尽如意,这时可以引入数据分库分表技术. 本文将基于SpringBoot+Myba
-

SpringBoot 如何使用sharding jdbc进行分库分表
目录 基于4.0版本,Springboot2.1 在pom里确保有如下引用 里面我profiles.active了另一个 之后手工把表都建好 写个测试代码 需要注意一个坑 基于4.0版本,Springboot2.1 之前写过一篇使用sharding-jdbc进行分库分表的文章,不过当时的版本还比较早,现在已经不能用了.这一篇是基于最新版来写的. 新版已经变成了shardingsphere了,https://shardingsphere.apache.org/. 有点不同的是,这一篇,我们是采用多
-
springboot整合shardingjdbc实现分库分表最简单demo
一.概览 1.1 简介 ShardingSphere-JDBC定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务. 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架. 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC. 支持任何第三方的数据库连接池,如:DBCP,
-
SpringBoot整合sharding-jdbc实现自定义分库分表的实践
目录 一.前言 二.简介 1.分片键 2.分片算法 三.程序实现 一.前言 SpringBoot整合sharding-jdbc实现分库分表与读写分离 本文将通过自定义算法来实现定制化的分库分表来扩展相应业务 二.简介 1.分片键 用于数据库/表拆分的关键字段 ex: 用户表根据user_id取模拆分到不同的数据库中 2.分片算法 可参考:https://shardingsphere.apache.org/document/current/cn/user-manual/shardingsphere
-
SpringBoot整合sharding-jdbc实现分库分表与读写分离的示例
目录 一.前言 二.数据库表准备 三.整合 四.docker-compose部署mysql主从 五.本文案例demo源码 一.前言 本文将基于以下环境整合sharding-jdbc实现分库分表与读写分离 springboot2.4.0 mybatis-plus3.4.3.1 mysql5.7主从 https://github.com/apache/shardingsphere 二.数据库表准备 温馨小提示:此sql执行时,如果之前有存在相应库和表会进行自动删除后再创建! DROP DATABAS
-
springboot jpa分库分表项目实现过程详解
这篇文章主要介绍了springboot jpa分库分表项目实现过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 分库分表场景 关系型数据库本身比较容易成为系统瓶颈,单机存储容量.连接数.处理能力都有限.当单表的数据量达到1000W或100G以后,由于查询维度较多,即使添加从库.优化索引,做很多操作时性能仍下降严重.此时就要考虑对其进行切分了,切分的目的就在于减少数据库的负担,缩短查询时间. 分库分表用于应对当前互联网常见的两个场景--大数
-
SpringBoot实现分库分表
目录 一.statementHandler对象的定义 二.prepare方法 1.首先prepare方法是用来编译SQL 2.那就是之前说的那几个具体的StatementHandler对象 3.parameterize方法 4.query/update方法 方案:可以使用拦截器拦截mybatis框架,在执行SQL前对SQL语句根据路由字段进行分库分表操作,下例只做分表功能 @Intercepts:申明需要拦截的方法 拦截StatementHandler对象 一.statementHandler对
-
SpringBoot集成Sharding Jdbc使用复合分片的实践
目录 1.Sharing JDBC 简介 2.系统改造 2.1 对接外部系统的系统 2.2 内部系统间的调用 3.解决方案 4.代码实现 4.1 Sharding JDBC 配置 4.2 数据源操作类 4.3 分片测试类 4.4 测试结果 参考文章: 最近主要的工作重心是数据库的容量规划. 随着业务的逐渐增大,原有保存在单表的数据量也日益增强.数据库数据会随着业务的发展而不断增多,因此数据操作,如增删改查的开销也会越来越大.再加上物理服务器的资源有限(CPU.磁盘.内存.IO 等).最终数据库所