python实现kmp算法的实例代码
kmp算法
kmp算法用于字符串的模式匹配,也就是找到模式字符串在目标字符串的第一次出现的位置
比如
abababc
那么bab在其位置1处,bc在其位置5处
我们首先想到的最简单的办法就是蛮力的一个字符一个字符的匹配,但那样的时间复杂度会是O(m*n)
kmp算法保证了时间复杂度为O(m+n)
基本原理
举个例子:

发现x与c不同后,进行移动
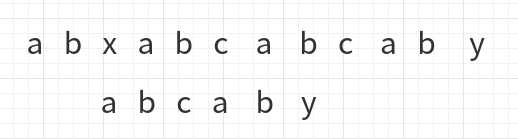
a与x不同,再次移动
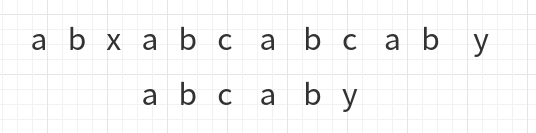
此时比较到了c与y,
于是下一步移动成了下面这样
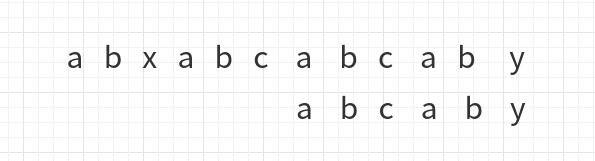
这一次的移动与前两次的移动不同,之前每次比较到上面长字符串的字符位置后,直接把模式字符串的首字符与它对齐,这次并没有,原因是这次移动之前,y与c对齐,但是y前边的ab是与自己的前缀ab一样,于是ab并不用再比较,直接从第三个位置开始比较,如图:

所以说kmp算法对于这种情况就直接使用当前比较字符之前的最长相同的前后缀,然后将前缀与上面的长字符串对齐,继续比
较后面的字符串。
这里kmp算法中的一个重要点就来了,如何找到模式字符串中每位字符之前的最长相同前后缀呢
这里继续用一个例子举例:

下面的数字记录以该字符为结尾的最长前后缀相同子串的长度,先初始化为0,并且第一个字符下的数字确认为0
然后开始比较:

a与b不同,那么b下的数字也为0同理a与c不同,c下的数字也为0,接下来a与a对齐,如下

此时a与a相同,那么a下面的数字为1,也就是第二排字符串中当前比对的字符索引+1
接下来b与b相同,c与a不相同,那么此时上面的字符串不动,下面的字符串移动到当前比对位置即c的前一位的下方的数字的位置,如图:
移动前
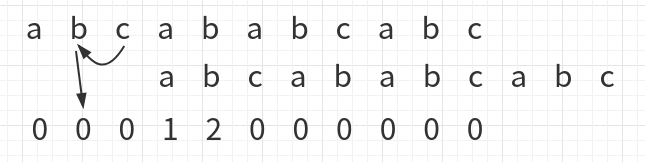
c的前一位是b,b下方的数字是0,所以将下面字符串的第0位与之前的比对位置对其,即:
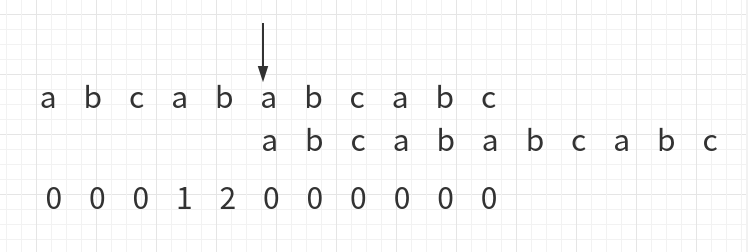
当前比对位置如箭头所示,然后继续向后比较,一直比到c与a:

此时c与a不相同,那么比较下面字符的前一个字符的下方数字的位置,如图
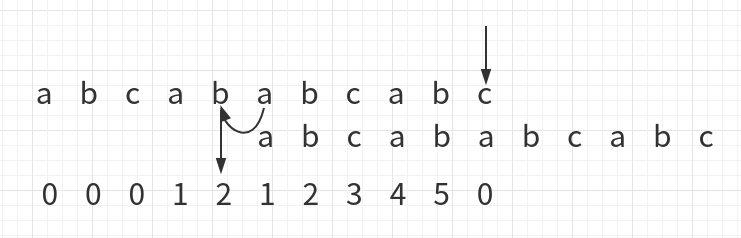
也就是位置为2的地方与上面比对位置对齐:
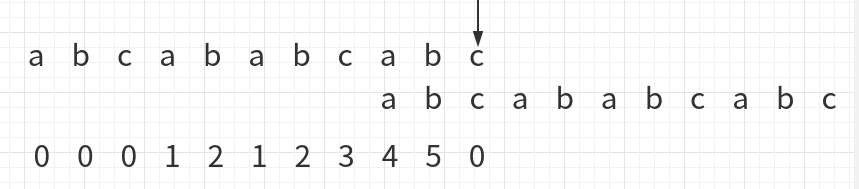
此时c与c相同,整个字符串自比对完成:
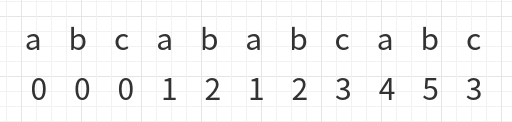
此时可能会没有理解为什么匹配不成功的时候要再比对其前一位字符下的数字的位置,那是因为这是要找到前一个字符位置下的最长相同前缀中的最长相同前缀,就举刚才的例子:
此时a前边是abcab,所以要找到abcab的最长相同前缀,就是ab,这时

然后再移动到ab与ab对其的位置继续比较即可
时间复杂度
简单来讲, 找到模式字符串中每位字符之前的最长相同前后缀的这个方法中,如果模式字符串的长度为m,那么上面的字符串的指向是一直向前移动的,下面字符串的整体也是一直向前移动的,最终移动的结果将会是长度为2m,所以比较次数也是最大为2m,时间复杂度为O(m)
kmp算法中,运用了找到模式字符串中每位字符之前的最长相同前后缀的这个方法的结果,然后使用类似的方法进行比较和移动,和上边的解释类似,如果这个要匹配的字符串长度为n,那最长的移动举例也超不过2n,所以总的时间复杂度为O(m+n)
具体代码
这里没有进行传入参数的验证,使用时还要注意。
def same_start_end(s):
"""最长前后缀相同的字符位数"""
n = len(s) #整个字符串长度
j = 0 # 前缀匹配指向
i = 1 # 后缀匹配指向
result_list=[0]*n
while i < n:
if j == 0 and s[j] != s[i]: # 比较不相等并且此时比较的已经是第一个字符了
result_list[i] = 0 # 值为0
i += 1 # 向后移动
elif s[j] != s[i] and j != 0: #比较不相等,将j值设置为j前一位的result_list中的值,为了在之前匹配到的子串中找到最长相同前后缀
j = result_list[j-1]
elif s[j] == s[i]: #相等则继续比较
result_list[i] = j+1
j = j+1
i = i+1
return result_list
def kmp(s,p):
"""kmp算法,s是字符串,p是模式字符串,返回值为匹配到的第一个字符串的第一个字符的索引,没匹配到返回-1"""
s_length = len(s)
p_length = len(p)
i = 0 # 指向s
j = 0 # 指向p
next = same_start_end(p)
while i < s_length:
if s[i] == p[j]: # 对应字符相同
i += 1
j += 1
if j >= p_length: # 完全匹配
return i-p_length
elif s[i] != p[j]: # 不相同
if j == 0: # 与模式比较的是模式的第一个字符
i += 1
else: # 取模式当前字符之前最长相同前后缀的前缀的后一个字符继续比较
j = next[j]
if i == s_length: # 没有找到完全匹配的子串
return -1
总结
以上所述是小编给大家介绍的python实现kmp算法的实例代码,希望对大家有所帮助,如果大家有任何疑问欢迎给我留言,小编会及时回复大家的!
相关推荐
-
Python将列表数据写入文件(txt, csv,excel)
写入txt文件 def text_save(filename, data):#filename为写入CSV文件的路径,data为要写入数据列表. file = open(filename,'a') for i in range(len(data)): s = str(data[i]).replace('[','').replace(']','')#去除[],这两行按数据不同,可以选择 s = s.replace("'",'').replace(',','') +'\n' #去除单引号,
-
python爬虫简单的添加代理进行访问的实现代码
在使用python对网页进行多次快速爬取的时候,访问次数过于频繁,服务器不会考虑User-Agent的信息,会直接把你视为爬虫,从而过滤掉,拒绝你的访问,在这种时候就需要设置代理,我们可以给proxies属性设置一个代理的IP地址,代码如下: import requests from lxml import etree url = "https://www.ip.cn" headers = {"User-Agent": "Mozilla/5.0 (Wind
-
详解python项目实战:模拟登陆CSDN
前言 今天为大家介绍一个利用Python模拟登陆CSDN的案例,虽然看起来很鸡肋,有时候确会有大用处,在这里就当做是一个案例练习吧,提高自己的代码水平,也了解Python如何做到模拟登陆的, 下面来看代码 导入库 获取头部信息 解析网页 返回登录过后的session 检测是否登陆正常 运行结果 以上所述是小编给大家介绍的python项目实战:模拟登陆CSDN详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的.在此也非常感谢大家对我们网站的支持!
-
Python选择网卡发包及接收数据包
当一台计算机上有多个网卡时,需要选择对应IP地址的网卡进行发送数据包或者接受数据包. 1.选择网卡发包(应用scapy): plface=conf.route.route("××.××.××.××")[0] #××.××.××.××为对应网卡网络中存在设备的IP地址.不能是需要发送数据包的网卡的IP地址(会报"result too large") pkt=conf.L2socket(plface) pack_ip,pack_udp,pack_ether=self.u
-

Python GUI编程完整示例
本文实例讲述了Python GUI编程.分享给大家供大家参考,具体如下: import os from time import sleep from tkinter import * from tkinter.messagebox import showinfo class DirList(object): def __init__(self, initdir=None): self.top = Tk() self.label = Label(master=self.top, text='Dir
-
详解python多线程之间的同步(一)
引言: 线程之间经常需要协同工作,通过某种技术,让一个线程访问某些数据时,其它线程不能访问这些数据,直到该线程完成对数据的操作.这些技术包括临界区(Critical Section),互斥量(Mutex),信号量(Semaphore),事件Event等. Event threading库中的event对象通过使用内部一个flag标记,通过flag的True或者False的变化来进行操作. 名称 含义 set( )
-
详解Python的数据库操作(pymysql)
使用原生SQL语句进行对数据库操作,可完成数据库表的建立和删除,及数据表内容的增删改查操作等.其可操作性很强,如可以直接使用"show databases"."show tables"等语句进行表格之外的部分操作. Centos7远程操作数据库时需要关闭防火墙,否则会连接不上 安装: pip3 install pymysql 数据查询: import pymysql #建立数据库连接 conn=pymysql.connect(host="192.168.1
-
Python实现字符串匹配的KMP算法
kmp算法 KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt同时发现,因此人们称它为克努特--莫里斯--普拉特操作(简称KMP算法).KMP算法的关键是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的.具体实现就是实现一个next()函数,函数本身包含了模式串的局部匹配信息. #! /usr/bin/python # coding=utf-8 """ 基于这篇文章的python实现 http://bl
-
python dlib人脸识别代码实例
本文实例为大家分享了python dlib人脸识别的具体代码,供大家参考,具体内容如下 import matplotlib.pyplot as plt import dlib import numpy as np import glob import re #正脸检测器 detector=dlib.get_frontal_face_detector() #脸部关键形态检测器 sp=dlib.shape_predictor(r"D:\LB\JAVASCRIPT\shape_predictor_68
-
详解python读取image
python 读取image 在python中我们有两个库可以处理图像文件,scipy和matplotlib. 安装库 pip install matplotlib pillow scipy 用法 from scipy.misc import imread data = imread(image_root) #data是 ndarray对象 import matplotlib.image as mpimg data = mpimg.imread(image_root) #data是 ndarra