Python实现语音识别和语音合成功能
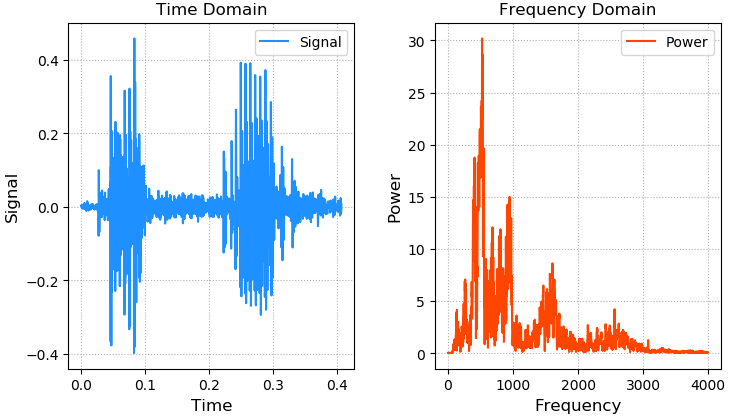
声音的本质是震动,震动的本质是位移关于时间的函数,波形文件(.wav)中记录了不同采样时刻的位移。
通过傅里叶变换,可以将时间域的声音函数分解为一系列不同频率的正弦函数的叠加,通过频率谱线的特殊分布,建立音频内容和文本的对应关系,以此作为模型训练的基础。
案例:画出语音信号的波形和频率分布,(freq.wav数据地址)
# -*- encoding:utf-8 -*-
import numpy as np
import numpy.fft as nf
import scipy.io.wavfile as wf
import matplotlib.pyplot as plt
sample_rate, sigs = wf.read('../machine_learning_date/freq.wav')
print(sample_rate) # 8000采样率
print(sigs.shape) # (3251,)
sigs = sigs / (2 ** 15) # 归一化
times = np.arange(len(sigs)) / sample_rate
freqs = nf.fftfreq(sigs.size, 1 / sample_rate)
ffts = nf.fft(sigs)
pows = np.abs(ffts)
plt.figure('Audio')
plt.subplot(121)
plt.title('Time Domain')
plt.xlabel('Time', fontsize=12)
plt.ylabel('Signal', fontsize=12)
plt.tick_params(labelsize=10)
plt.grid(linestyle=':')
plt.plot(times, sigs, c='dodgerblue', label='Signal')
plt.legend()
plt.subplot(122)
plt.title('Frequency Domain')
plt.xlabel('Frequency', fontsize=12)
plt.ylabel('Power', fontsize=12)
plt.tick_params(labelsize=10)
plt.grid(linestyle=':')
plt.plot(freqs[freqs >= 0], pows[freqs >= 0], c='orangered', label='Power')
plt.legend()
plt.tight_layout()
plt.show()
语音识别
梅尔频率倒谱系数(MFCC)通过与声音内容密切相关的13个特殊频率所对应的能量分布,可以使用梅尔频率倒谱系数矩阵作为语音识别的特征。基于隐马尔科夫模型进行模式识别,找到测试样本最匹配的声音模型,从而识别语音内容。
MFCC
梅尔频率倒谱系数相关API:
import scipy.io.wavfile as wf
import python_speech_features as sf
sample_rate, sigs = wf.read('../data/freq.wav')
mfcc = sf.mfcc(sigs, sample_rate)
案例:画出MFCC矩阵:
python -m pip install python_speech_features import scipy.io.wavfile as wf import python_speech_features as sf import matplotlib.pyplot as mp sample_rate, sigs = wf.read( '../ml_data/speeches/training/banana/banana01.wav') mfcc = sf.mfcc(sigs, sample_rate) mp.matshow(mfcc.T, cmap='gist_rainbow') mp.show()

隐马尔科夫模型
隐马尔科夫模型相关API:
import hmmlearn.hmm as hl model = hl.GaussianHMM(n_components=4, covariance_type='diag', n_iter=1000) # n_components: 用几个高斯分布函数拟合样本数据 # covariance_type: 相关矩阵的辅对角线进行相关性比较 # n_iter: 最大迭代上限 model.fit(mfccs) # 使用模型匹配测试mfcc矩阵的分值 score = model.score(test_mfccs)
案例:训练training文件夹下的音频,对testing文件夹下的音频文件做分类
1、读取training文件夹中的训练音频样本,每个音频对应一个mfcc矩阵,每个mfcc都有一个类别(apple)。
2、把所有类别为apple的mfcc合并在一起,形成训练集。
| mfcc | |
| mfcc | apple |
| mfcc | |
.....
由上述训练集样本可以训练一个用于匹配apple的HMM。
3、训练7个HMM分别对应每个水果类别。 保存在列表中。
4、读取testing文件夹中的测试样本,整理测试样本
| mfcc | apple |
| mfcc | lime |
5、针对每一个测试样本:
1、分别使用7个HMM模型,对测试样本计算score得分。
2、取7个模型中得分最高的模型所属类别作为预测类别。
import os
import numpy as np
import scipy.io.wavfile as wf
import python_speech_features as sf
import hmmlearn.hmm as hl
#1. 读取training文件夹中的训练音频样本,每个音频对应一个mfcc矩阵,每个mfcc都有一个类别(apple)。
def search_file(directory):
# 使传过来的directory匹配当前操作系统
# {'apple':[url, url, url ... ], 'banana':[...]}
directory = os.path.normpath(directory)
objects = {}
# curdir:当前目录
# subdirs: 当前目录下的所有子目录
# files: 当前目录下的所有文件名
for curdir, subdirs, files in os.walk(directory):
for file in files:
if file.endswith('.wav'):
label = curdir.split(os.path.sep)[-1]
if label not in objects:
objects[label] = []
# 把路径添加到label对应的列表中
path = os.path.join(curdir, file)
objects[label].append(path)
return objects
#读取训练集数据
train_samples = \
search_file('../ml_data/speeches/training')
'''
2. 把所有类别为apple的mfcc合并在一起,形成训练集。
| mfcc | |
| mfcc | apple |
| mfcc | |
.....
由上述训练集样本可以训练一个用于匹配apple的HMM。
'''
train_x, train_y = [], []
# 遍历7次 apple/banana/...
for label, filenames in train_samples.items():
mfccs = np.array([])
for filename in filenames:
sample_rate, sigs = wf.read(filename)
mfcc = sf.mfcc(sigs, sample_rate)
if len(mfccs)==0:
mfccs = mfcc
else:
mfccs = np.append(mfccs, mfcc, axis=0)
train_x.append(mfccs)
train_y.append(label)
'''
训练集:
train_x train_y
----------------
| mfcc | |
| mfcc | apple |
| mfcc | |
----------------
| mfcc | |
| mfcc | banana |
| mfcc | |
-----------------
| mfcc | |
| mfcc | lime |
| mfcc | |
-----------------
'''
# {'apple':object, 'banana':object ...}
models = {}
for mfccs, label in zip(train_x, train_y):
model = hl.GaussianHMM(n_components=4,
covariance_type='diag', n_iter=1000)
models[label] = model.fit(mfccs)
'''
4. 读取testing文件夹中的测试样本,针对每一个测试样本:
1. 分别使用7个HMM模型,对测试样本计算score得分。
2. 取7个模型中得分最高的模型所属类别作为预测类别。
'''
#读取测试集数据
test_samples = \
search_file('../ml_data/speeches/testing')
test_x, test_y = [], []
for label, filenames in test_samples.items():
mfccs = np.array([])
for filename in filenames:
sample_rate, sigs = wf.read(filename)
mfcc = sf.mfcc(sigs, sample_rate)
if len(mfccs)==0:
mfccs = mfcc
else:
mfccs = np.append(mfccs, mfcc, axis=0)
test_x.append(mfccs)
test_y.append(label)
'''测试集:
test_x test_y
-----------------
| mfcc | apple |
-----------------
| mfcc | banana |
-----------------
| mfcc | lime |
-----------------
'''
pred_test_y = []
for mfccs in test_x:
# 判断mfccs与哪一个HMM模型更加匹配
best_score, best_label = None, None
for label, model in models.items():
score = model.score(mfccs)
if (best_score is None) or (best_score<score):
best_score = score
best_label = label
pred_test_y.append(best_label)
print(test_y)
print(pred_test_y)
声音合成
根据需求获取某个声音的模型频域数据,根据业务需要可以修改模型数据,逆向生成时域数据,完成声音的合成。
案例:
import json
import numpy as np
import scipy.io.wavfile as wf
with open('../data/12.json', 'r') as f:
freqs = json.loads(f.read())
tones = [
('G5', 1.5),
('A5', 0.5),
('G5', 1.5),
('E5', 0.5),
('D5', 0.5),
('E5', 0.25),
('D5', 0.25),
('C5', 0.5),
('A4', 0.5),
('C5', 0.75)]
sample_rate = 44100
music = np.empty(shape=1)
for tone, duration in tones:
times = np.linspace(0, duration, duration * sample_rate)
sound = np.sin(2 * np.pi * freqs[tone] * times)
music = np.append(music, sound)
music *= 2 ** 15
music = music.astype(np.int16)
wf.write('../data/music.wav', sample_rate, music)
总结
以上所述是小编给大家介绍的Python实现语音识别和语音合成功能,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-

Python Web版语音合成实例详解
前言 语音合成技术能将用户输入的文字,转换成流畅自然的语音输出,并且可以支持语速.音调.音量设置,打破传统文字式人机交互的方式,让人机沟通更自然. 应用场景 将游戏场景中的公告.任务或派单信息通过语音播报,让玩家玩游戏或配送员送货的同时,也可接听新任务. 文学小说类软件,可以利用百度语音合成技术将文学小说作品进行高质量的朗读,流畅清晰,解放双眼,畅听世界. 软件架构 Python3.7.2.Django2.1.7.baidu-aip(百度语音API) 案例 这里只展示部分代码,有兴趣的同学可以自
-
python实现百度语音识别api
本文实例为大家分享了ython实现百度语音识别的具体代码,供大家参考,具体内容如下 详细百度语音识别api文档 先下载python用SDK,可以用python setup.py install安装 # 引入Speech SDK from aip import AipSpeech # 定义常量 APP_ID = '你的 App ID' API_KEY = '你的 API Key' SECRET_KEY = '你的 Secret Key' # 初始化AipSpeech对象 aipSpeech = A
-
python腾讯语音合成实现过程解析
一.腾讯语音合成介绍 腾讯云语音合成技术(TTS)可以将任意文本转化为语音,实现让机器和应用张口说话. 腾讯TTS技术可以应用到很多场景,比如,移动APP语音播报新闻:智能设备语音提醒:依靠网上现有节目或少量录音,快速合成明星语音,降低邀约成本:支持车载导航语音合成的个性化语音播报.(废话一大堆)... 二.腾讯语音合成python SDK文档 安装 Python SDK 前,先获取安全凭证.在第一次使用云 API 之前,用户首先需要在腾讯云控制台上申请安全凭证,安全凭证包括 SecretID
-
Python语言实现百度语音识别API的使用实例
未来的一段时间,人工智能在市场上占有很重的位置,Python语言则是研究人工智能的最佳编程语言,下面,就让我们来感受一下它的魅力吧! 百度给的样例程序,不论C还是Java版,都分为method1和method2两种 前者称为隐式(post的是json串,音频数据编码到json里),后者称为显式(post的就是音频数据) 一开始考虑到pythonwave包处理的都是"字符串",担心跟C语言的数组不一致,所以选择低效但保险的method1, 即先将音频数据base64编码,再加上采样率.通
-
python语音识别实践之百度语音API
百度语音对上传的语音要求目前必须是单声道,16K采样率,采样深度可以是16位或者8位的PCM编码.其他编码输出的语音识别不出来. 语音的处理技巧: 录制为MP3的语音(通常采样率为44100),要分两步才能正确处理.第一步:使用诸如GoldWave的软件,先保存为16K采样率的MP3:第二步,打开16K采样率的MP3,另存为Wav格式,参数选择PCM,单声道即可. 另外,也可以使用ffmpeg将MP3处理为PCM.后文的程序即采用这种方法. 由于PCM编码的语音没有压缩,文件体积与语音长度成正比
-
python调用百度语音识别实现大音频文件语音识别功能
本文为大家分享了python实现大音频文件语音识别功能的具体代码,供大家参考,具体内容如下 实现思路:先用ffmpeg将其他非wav格式的音频转换为wav格式,并转换音频的声道(百度支持声道为1),采样率(值为8000),格式转换完成后,再用ffmpeg将音频切成百度. 支持的时长(30秒和60秒2种,本程序用的是30秒). # coding: utf-8 import json import time import base64 from inc import rtysdb import ur
-
Python实现简单的语音识别系统
最近认识了一个做Python语音识别的朋友,聊天时候说到,未来五到十年,Python人工智能会在国内掀起一股狂潮,对各种应用的冲击,不下于淘宝对实体经济的冲击.在本地(江苏某三线城市)做这一行,短期可能显不出效果,但从长远来看,绝对是一个高明的选择.朋友老家山东的,毕业来这里创业,也是十分有想法啊. 将AI课上学习的知识进行简单的整理,可以识别简单的0-9的单个语音.基本方法就是利用库函数提取mfcc,然后计算误差矩阵,再利用动态规划计算累积矩阵.并且限制了匹配路径的范围.具体的技术网上很多,不
-
Python实现语音识别和语音合成功能
声音的本质是震动,震动的本质是位移关于时间的函数,波形文件(.wav)中记录了不同采样时刻的位移. 通过傅里叶变换,可以将时间域的声音函数分解为一系列不同频率的正弦函数的叠加,通过频率谱线的特殊分布,建立音频内容和文本的对应关系,以此作为模型训练的基础. 案例:画出语音信号的波形和频率分布,(freq.wav数据地址) # -*- encoding:utf-8 -*- import numpy as np import numpy.fft as nf import scipy.io.wavfil
-
Python实现语音合成功能详解
目录 导语 1.直接使用 2. 获取权限 2.1 环境准备: 2.2 获取权限 3. 代码实现 3.1 获取access_token 3.2 获取转换后音频 3.3 配置接口参数 3.4 完整demo 3.5 执行 导语 今天就给大家带来个语言识别跟语言赚文字的小工具感兴趣的铁汁萌可以往下滑了 1.直接使用 在1.2官网注册后拿到APISecret和APIKey,直接复制文章2.4demo代码,保存为online_tts.py,在命令行执行 python online_tts.py -clien
-
Linux下利用python实现语音识别详细教程
目录 语音识别工作原理简介 选择合适的python语音识别包 安装SpeechRecognition 识别器类 音频文件的使用 英文的语音识别 噪音对语音识别的影响 麦克风的使用 中文的语音识别 小范围中文识别 语音合成 语音识别工作原理简介 语音识别源于 20 世纪 50 年代早期在贝尔实验室所做的研究.早期语音识别系统仅能识别单个讲话者以及只有约十几个单词的词汇量.现代语音识别系统已经取得了很大进步,可以识别多个讲话者,并且拥有识别多种语言的庞大词汇表.语音识别的首要部分当然是语音.通过麦克
-
Python实现变声器功能(萝莉音御姐音)
登录百度AL开发平台 在控制台选择语音合成 创建应用 填写应用信息 在应用列表获取(Appid.API Key.Secret Key) 6. 安装pythonsdk 安装使用Python SDK有如下方式: 安装使用Python SDK有如下方式: 如果已安装pip,执行pip install baidu-aip即可. 如果已安装setuptools,执行python setup.py instal即可. 7. 书写代码 from aip import AipSpeech ""&q
-
python之语音识别speech模块
1.原理 语音操控分为 语音识别和语音朗读两部分. 这两部分本来是需要自然语言处理技能相关知识以及一系列极其复杂的算法才能搞定,可是这篇文章将会跳过此处,如果你只是对算法和自然语言学感兴趣的话,就只有请您移步了,下面没有一个字会讲述到这些内容. 早在上世纪90年代的时候,IBM就推出了一款极为强大的语音识别系统-vio voice , 而其后相关产品层出不穷,不断的进化和演变着. 我们这里将会使用SAPI实现语音模块. 2. 什么是SAPI? SAPI是微软Speech API , 是微软公司推
-
基于Python创建语音识别控制系统
下面附上参考文章,这篇文章是通过识别出来的文字来打开浏览器中的默认网站.python通过调用百度api实现语音识别 题目很简单,利用语音识别识别说出来的文字,根据文字的内容来控制图形移动,例如说向上,识别出文字后,画布上的图形就会向上移动.本文使用的是百度识别API(因为免费),自己做的流程图: 不多说,直接开始程序设计,首先登录百度云,创建应用 注意这里的API Key和Secret Key,要用自己的才能生效 百度语音识别有对应的文档,具体调用方法说的很清晰,如果想学习一下可以查看REST
-
基于Python实现语音识别和语音转文字
目录 前言 直接使用 获取权限 1.环境准备 2.获取权限 代码实现 1.获取access_token 2.获取转换后音频 3.配置接口参数 4.完整demo 5.执行 前言 嗨嗨,大家好呀 ~ 今天给你们分享一个有趣的东西 ~ 是一个语音识别跟语音转文字的小工具 感兴趣的朋友可以继续往下滑咯 直接使用 在1.2官网注册后拿到APISecret和APIKey, 直接复制文章2.4demo代码, 保存为online_tts.py, 在命令行执行 python online_tts.py -clie
-
Python爬虫爬验证码实现功能详解
主要实现功能: - 登陆网页 - 动态等待网页加载 - 验证码下载 很早就有一个想法,就是自动按照脚本执行一个功能,节省大量的人力--个人比较懒.花了几天写了写,本着想完成验证码的识别,从根本上解决问题,只是难度太高,识别的准确率又太低,计划再次告一段落. 希望这次经历可以与大家进行分享和交流. Python打开浏览器 相比与自带的urllib2模块,操作比较麻烦,针对于一部分网页还需要对cookie进行保存,很不方便.于是,我这里使用的是Python2.7下的selenium模块进行网页上的操
-
利用Python实现Windows定时关机功能
是最初的几个爬虫,让我认识了Python这个新朋友,虽然才刚认识了几天,但感觉有种莫名的默契感.每当在别的地方找不到思路,总能在Python找到解决的办法.自动关机,在平时下载大文件,以及跑程序的时候能用到的,刚才写了个windows自动关机的小程序,程序过于简单,就当是玩玩吧,当然还有很多可改进的地方.下面正文: #ui制作: 照旧,笔者由Qt制作完成需要的ui,包括label,label_2,label_3,lable_4,lineEdit,lineEdit_2,pushButton组件.
-
使用Python实现简单的服务器功能
socket接口是实际上是操作系统提供的系统调用.socket的使用并不局限于Python语言,你可以用C或者Java来写出同样的socket服务器,而所有语言使用socket的方式都类似(Apache就是使用C实现的服务器) Web框架就是提前写好了服务器.不能跨语言的使用框架.框架的好处在于帮你处理了一些细节,从而实现快速开发,但同时受到python本身性能的限制.我们已经看到,许多成功的网站都是利用动态语言(比如Python, Ruby或者PHP,比如twitter和facebook)快速