Python 专题五 列表基础知识(二维list排序、获取下标和处理txt文本实例)
通常测试人员或公司实习人员需要处理一些txt文本内容,而此时使用Python是比较方便的语言。它不光在爬取网上资料上方便,还在NLP自然语言处理方面拥有独到的优势。这篇文章主要简单的介绍使用Python处理txt汉字文字、二维列表排序和获取list下标。希望文章对你有所帮助或提供一些见解~
一. list二维数组排序
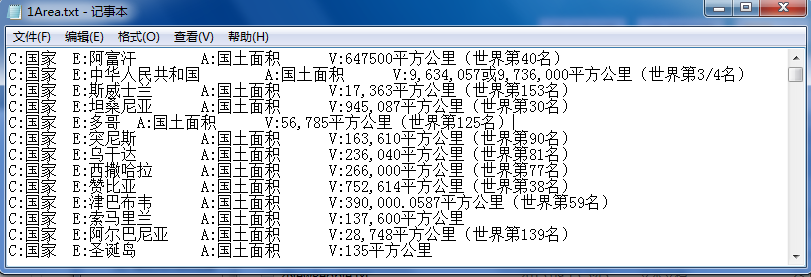
功能:已经通过Python从维基百科中获取了国家的国土面积和排名信息,此时需要获取国土面积并进行排序判断世界排名是否正确。
列表基础知识
列表类型同字符串一样也是序列式的数据类型,可以通过下标或切片操作来访问某一个或某一块连续的元素。它和字符串不同之处在于:字符串只能由字符组成而且不可变的(不能单独改变它的某个值),而列表是能保留任意数目的Python对象灵活容器。
总之,列表可以包含不同类型的对象(包括用户自定义的对象)作为元素,列表可以添加或删除元素,也可以合并或拆分列表,包括insert、update、remove、sprt、reverse等操作。
列表排序介绍
常用列表排序方法包括使用List内建函数list.sort()或序列类型函数sorted(list)排序
#list.sort(func=None, key=None, reverse=False) list = [4, 3, 9, 1, 5, 2] print list list.sort() print list #输出 [4, 3, 9, 1, 5, 2] [1, 2, 3, 4, 5, 9]
通过对比下面的代码,可以发现两种方法的区别是:list.sort()改变了原list的顺序,而sorted没有。
#sorted(list) list = ['h', 'a', 'p', 'd', 'i', 'b'] print list print sorted(list) print list #输出 ['h', 'a', 'p', 'd', 'i', 'b'] ['a', 'b', 'd', 'h', 'i', 'p'] ['h', 'a', 'p', 'd', 'i', 'b']
二维列表排序
通过lambda表达式实现二维列表排序,并且按照第二个关键字进行排序。参考文章
#list.sort(func=None, key=None, reverse=False)
list = [('Tom',4),('Jack',7),('Daly',9),('Mary',1),('God',5),('Yuri',3)]
print list
list.sort(lambda x,y:cmp(x[1],y[1]))
print list
#输出
[('Tom', 4), ('Jack', 7), ('Daly', 9), ('Mary', 1), ('God', 5), ('Yuri', 3)]
[('Mary', 1), ('Yuri', 3), ('Tom', 4), ('God', 5), ('Jack', 7), ('Daly', 9)]
题目中如果第一个数存储文件中读取的行号,第二个数存储人口数量,此时可对第二个数进行排序。需要注意的是它们一组(1,93)是tuple元组。
#list.sort(func=None, key=None, reverse=False) list = [(1,93),(2,71),(3,89),(4,93),(5,85),(6,77)] print list list.sort(key=lambda x:x[1]) print list #输出 [(1, 93), (2, 71), (3, 89), (4, 93), (5, 85), (6, 77)] [(2, 71), (6, 77), (5, 85), (3, 89), (1, 93), (4, 93)]
lambada表达式
在上述代码中,如果还不知道lambada是什么鬼东西的话?那我就来帮你回顾了。
python允许使用lambda关键字创造匿名函数,它不需要以标准的方式来声明,如def语句。然而作为函数,它们也能有参数。
lambda就是一个表达式,而不是一个代码块。而且这个表达是的定义必须和声明放在同一行,能在lambda中封装有限的逻辑进去,起到一个函数速写的作用。例如:
#lambda [arg1[, arg2, ..., argN]]:expression f = lambda x,y,z:x+y+z num = f(1,2,3) print 'lambda: ' + str(num) #等价于 def add(x,y,z): return x+y+z num = add(1,2,3) print 'function: ' + str(num) #输出 lambda: 6 function: 6
二. 处理txt文本
下面是通过txt文件按行读取,并获取面积进行排序。其中核心代码如下:
读取文件&列表添加
source = open("F:\\Student\\1Area.txt",'r')
lines = source.readlines()
L = [] #列表二维 国家行数 人口数
count = 1 #当前国家在文件中第count行
for line in lines:
line = line.rstrip('\n') #去除换行
.... #获取排名和面积
fNum = string.atof(number) #面积
L.append((count,ffNum)) #列表添加
count = count + 1
else:
print 'End While'
source.close()
列表排序
L.sort(lambda x,y:cmp(x[1],y[1]),reverse = True) #遍历过程 表示第i名 (文件第x行,面积y平方公里) #重点 L[i]输出列表 1 (46, 17075200.0) L[i][0]表示元组tuple第一个数 1 46 for i in range(len(L)): print (i+1), L[i]
获取面积字符串
line = line.rstrip('\n') #去除换行
start = line.find(r'V:')
end = line.find(r'平方公里')
number = line[start+2:end]
number = number.replace(',','') #去除','
#输出
line => C:国家 E:中华人民共和国 A:国土面积 V:9,634,057或9,736,000平方公里(世界第3/4名)
number => 9634057或9736000
最后同时需要处理各种字符串情况,如‘或'、‘万'要乘10000、删除‘[1]'等。更简单的方法是通过正则表达式或获取第一个非数字字符。
运行结果如下所示,排序后的txt和纠错txt:


代码如下:
# coding=utf-8
import time
import re
import os
import string
import sys
source = open("F:\\Student\\1Area.txt",'r')
lines = source.readlines()
count = 1
L = [] #列表二维 国家行数 人口数
'''''
第一部分 获取国土面积
'''
print 'Start!!!'
for line in lines:
line = line.rstrip('\n') #去除换行
start = line.find(r'V:')
end = line.find(r'平方公里')
number = line[start+2:end]
number = number.replace(',','') #去除','
fNum = 0.0
if '万' in number:
end = line.find(r'万')
newNum = line[start+2:end]
fNum = string.atof(newNum)*10000
else: #如何优化代码 全局变量
if '/' in number:
end = line.find(r'/')
newNum = line[start+2:end]
newNum = newNum.replace(',','')
fNum = string.atof(newNum)
elif '(' in number:
end = line.find(r'(')
newNum = line[start+2:end]
newNum = newNum.replace(',','')
fNum = string.atof(newNum)
elif '[' in number:
end = line.find(r'[')
newNum = line[start+2:end]
newNum = newNum.replace(',','')
fNum = string.atof(newNum)
elif '或' in number:
end = line.find(r'或')
newNum = line[start+2:end]
newNum = newNum.replace(',','')
fNum = string.atof(newNum)
elif ' ' in number:
end = line.find(r' ')
newNum = line[start+2:end]
newNum = newNum.replace(',','')
fNum = string.atof(newNum)
else:
fNum = string.atof(number)
#print line
#print number
#print fNum
L.append((count,fNum))
count = count + 1
else:
print 'End While'
source.close()
'''''
第二部分 从大到小排序
参看 http://blog.chinaunix.net/uid-20775448-id-4222915.html
'''
L.sort(lambda x,y:cmp(x[1],y[1]),reverse = True)
#print L
#遍历过程 表示第i名 (文件第x行,面积y平方公里)
#重点 L[i]输出列表 1 (46, 17075200.0) L[i][0]表示元组tuple第一个数 1 46
for i in range(len(L)):
print (i+1), L[i]
'''''
第三部分 读写文件
'''
source = open("F:\\Student\\1Area.txt",'r')
lines = source.readlines()
result = open("F:\\Student\\1NewArea.txt",'w')
count = 1
for line in lines:
line = line.rstrip('\n')
#获取列表L中排名位置pm
pm = 0
for i in range(len(L)):
if count==L[i][0]:
pm = i+1
break
#获取文件中名次
if '世界第' in line:
start = line.find(r'世界第')
end = line.find(r'名')
number = line[start+9:end]
if '/' in number: #防止中国第3/4名
end = line.find(r'/')
number = line[start+9:end]
if '包括海外' in number:
number = '41'
print number,pm,type(number),type(pm)
if string.atoi(number)==pm:
line = line + ' 【排名正确】 【世界第' + str(pm) + '名】'
result.write(line+'\n')
else:
line = line + ' 【排名错误】 【世界第' + str(pm) + '名】'
result.write(line+'\n')
else: #文件中没有排名
line = line + ' 【新加排名】 【世界第' + str(pm) + '名】'
result.write(line+'\n')
count = count + 1
else:
print 'End Sorted'
source.close()
result.close()
'''''
第四部分 输出一个排序好的文件 便于观察
'''
source = open("F:\\Student\\1Area.txt",'r')
lines = source.readlines()
result = open("F:\\Student\\1NewSortArea.txt",'w')
#i表示第i名 L[i][0]表示行数
pm = 0
for i in range(len(L)):
pm = L[i][0]
count = 1
for line in lines:
line = line.rstrip('\n')
if count==pm:
line = line + ' 【世界第' + str(i+1) + '名】'
result.write(line+'\n')
break
else:
count = count + 1
else:
print 'End Sorted Second'
source.close()
result.close()
最后希望文章对你有所帮助,文章主要通过讲述一个实际操作,帮你巩固学习liet列表的二维排序和字符串txt处理。如果文中有错误或不足之处,还请海涵~
以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,同时也希望多多支持我们!
相关推荐
-

Python读写txt文本文件的操作方法全解析
一.文件的打开和创建 >>> f = open('/tmp/test.txt') >>> f.read() 'hello python!\nhello world!\n' >>> f <open file '/tmp/test.txt', mode 'r' at 0x7fb2255efc00> 二.文件的读取 步骤:打开 -- 读取 -- 关闭 >>> f = open('/tmp/test.txt') >>&
-
Python实现的文本简单可逆加密算法示例
本文实例讲述了Python实现的文本简单可逆加密算法.分享给大家供大家参考,具体如下: 其实很简单,就是把一段文本每个字符都通过某种方式改变(比如加1) 这样就实现了文本的加密操作,解密就是其逆运算 # -*-coding:utf-8 -*- import sys reload(sys) sys.setdefaultencoding('utf8') #加密 def jiami(): filename=raw_input('please input file:\n') while True: tr
-
详解Python文本操作相关模块
详解Python文本操作相关模块 linecache--通过使用缓存在内部尝试优化以达到高效从任何文件中读出任何行. 主要方法: linecache.getline(filename, lineno[, module_globals]):获取指定行的内容 linecache.clearcache():清除缓存 linecache.checkcache([filename]):检查缓存的有效性 dircache--定义了一个函数,使用缓存读取目录列表.使用目录的mtime来实现缓存失效.此外还定义
-
Python如何实现文本转语音
准备 我测试使用的Python版本为2.7.10,如果你的版本是Python3.5的话,这里就不太适合了. 使用Speech API 原理 我们的想法是借助微软的语音接口,所以我们肯定是要进行调用 相关的接口.所以我们需要安装pywin32来帮助我们完成这一个底层的交互. 示例代码 import win32com.client speaker = win32com.client.Dispatch("SAPI.SpVoice") speaker.Speak("Hello, it
-
Python批量修改文本文件内容的方法
Python批量替换文件内容,支持嵌套文件夹 import os path="./" for root,dirs,files in os.walk(path): for name in files: #print name if name.endswith(".html"): #print root,dirs,name filename=root+"/"+name f=open(filename,"r") fileconten
-
Python实现统计文本文件字数的方法
本文实例讲述了Python实现统计文本文件字数的方法.分享给大家供大家参考,具体如下: 统计文本文件的字数,从当前目录下的file.txt取文件 # -*- coding: GBK -*- import string import sys reload(sys) def compareItems((w1,c1), (w2,c2)): if c1 > c2: return - 1 elif c1 == c2: return cmp(w1, w2) else: return 1 def main()
-
Python实现简单过滤文本段的方法
本文实例讲述了Python实现简单过滤文本段的方法.分享给大家供大家参考,具体如下: 一.问题: 如下文本: ## Alignment 0: score=397.0 e_value=8.2e-18 N=9 scaffold1&scaffold106 minus 0- 0: 10026549 10007782 2e-75 0- 1: 10026550 10007781 8e-150 0- 2: 10026552 10007780 1e-116 0- 3: 10026555 10007778 0 0
-
Python文件操作,open读写文件,追加文本内容实例
1.open使用open打开文件后一定要记得调用文件对象的close()方法.比如可以用try/finally语句来确保最后能关闭文件. file_object = open('thefile.txt') try: all_the_text = file_object.read( ) finally: file_object.close( ) 注:不能把open语句放在try块里,因为当打开文件出现异常时,文件对象file_object无法执行close()方法. 2.读文件读文本文件input
-
Python 专题五 列表基础知识(二维list排序、获取下标和处理txt文本实例)
通常测试人员或公司实习人员需要处理一些txt文本内容,而此时使用Python是比较方便的语言.它不光在爬取网上资料上方便,还在NLP自然语言处理方面拥有独到的优势.这篇文章主要简单的介绍使用Python处理txt汉字文字.二维列表排序和获取list下标.希望文章对你有所帮助或提供一些见解~ 一. list二维数组排序 功能:已经通过Python从维基百科中获取了国家的国土面积和排名信息,此时需要获取国土面积并进行排序判断世界排名是否正确. 列表基础知识 列表类型同字符串一样也是序列式的数据类型,
-
Python 专题四 文件基础知识
前面讲述了函数.语句和字符串的基础知识,该篇文章主要讲述文件的基础知识(与其他语言非常类似). 一. 文件的基本操作 文件是指存储在外部介质(如磁盘)上数据的集合.文件的操作流程为: 打开文件(读方式\写方式)->读写文件(read\readline\readlines\write\writelines)->关闭文件 1.打开文件 调用函数open打开文件,其函数格式为: file_obj=open(filename[, mode[, buffering]]) 返回一个文件对象(file ob
-
Python 可视化matplotlib模块基础知识
目录 1. matplotlib 模块概述 2. matplotlib.pyplot 相关方法 3. matplotlib.pyplot 图表展示 前言: 互联网时代下,在网络中每天都会产生很多数据,通过对数据分析之后,如何更好的诠释数据背后的意义,我们需要对数据进行可视化展示. 在数据可视化中,Python 也支持第三模块 matplotlib 模块:Python使用最多的可视化库 seaborn 模块:基于matplotlib的图形可视化 pycharts 模块:用于生成Echarts 图表
-
Python实现在图像中隐藏二维码的方法详解
目录 一.前言 二.隐写 三.位平面分解 3.1 图像 3.2 位平面 3.3 位平面分解 3.4 位平面合成 四.图像隐写 一.前言 在某个App中有一个加密水印的功能,当帖子的主人开启了之后.如果有人截图,那么这张截图中就是添加截图用户.帖子ID.截图时间等信息,而且我们无法用肉眼看出这些水印. 这可以通过今天要介绍的隐写技术来实现,我们会通过这种技术,借助Python语言和OpenCV模块来实现在图像中隐藏二维码的操作.而且这个二维码无法通过肉眼看出. 二.隐写 隐写是一种类似于加密却又不
-
IOS开发基础之二维数组详解
IOS开发基础之二维数组详解 首先我们知道OC中是没有二维数组的,二维数组是通过一位数组的嵌套实现的,但是别忘了我们有字面量,实际上可以和C/C++类似的简洁地创建和使用二维数组.这里总结了创建二维数组的两种方法以及数组的访问方式. 通过字面量创建和使用二维数组(推荐) // 1.字面量创建二维数组并访问(推荐) NSArray *array2d = @[ @[@11,@12,@13], @[@21,@22,@23], @[@31,@32,@33] ]; // 字面量访问方式(推荐) NSLog
-
Python之ReportLab绘制条形码和二维码的实例
条形码和二维码 #引入所需要的基本包 from reportlab.pdfgen import canvas from reportlab.graphics.barcode import code39, code128, code93 from reportlab.graphics.barcode import eanbc, qr, usps from reportlab.graphics.shapes import Drawing from reportlab.lib.units import
-
python+numpy按行求一个二维数组的最大值方法
问题描述: 给定一个二维数组,求每一行的最大值 返回一个列向量 如: 给定数组[1,2,3:4,5,3] 返回[3:5] import numpy as np x = np.array([[1,2,3],[4,5,3]]) # 先求每行最大值得下标 index_max = np.argmax(x, axis=1)# 其中,axis=1表示按行计算 print(index_max.shape) max = x[range(x.shape[0]), index_max] print(max) # 注
-
python将三维数组展开成二维数组的实现
以前写过一篇:python实现把两个二维array叠加成三维array示例 这篇文章尝试用"曲线救国"的方法来解决二维数组叠加成三维数组的问题. 但天道有轮回,苍天绕过谁.好不容易把数组叠加在一块儿了,新的需求又出现了:将三维数组展开成二维数组.有借有还,再借不难.今天就来解决把三维数组展开成二维数组的问题. 相对于叠加三维数组,numpy对展开数组支持得很好,只需要用好np.reshape(A,(a,b)) 函数即可. 用到的参数: A:需要被重新组合的数组 (a,b): 各个维度的
-
PHP中遍历二维数组_以不同形式的输出操作实例
如下所示: <body> <?php //定义二维索引数组 $arr = array( array("101","李军","男","1976-02-20","95033"), array("103","陆君","男","1974-06-03","95031"), array("10
-
Python提取支付宝和微信支付二维码的示例代码
支付宝或者微信支付导出的收款二维码,除了二维码部分,还有很大一块背景图案,例如下面就是微信支付的收款二维码: 有时候我们仅仅只想要图片中间的方形二维码部分,为了提取出中间部分,我们可以使用图片处理软件,但图片处理软件不利于批处理,且学习也需要一定成本.本文将教你使用 Python 的图像处理库 pillow,轻松批量提取图片中间的方形二维码部分. 提取思路 以微信支付收款码图片为例: 分析图片我们可以看到,二维码位于白色背景中,而白色背景又位于绿色背景上.我们以图片左上角为坐标原点,横向为 x