基于NodeJS的前后端分离的思考与实践(五)多终端适配
前言
近年来各站点基于 Web 的多终端适配进行得如火如荼,行业间也发展出依赖各种技术的解决方案。有如基于浏览器原生 CSS3 Media Query 的响应式设计、基于云端智能重排的「云适配」方案等。本文则主要探讨在前后端分离基础下的多终端适配方案。
关于前后端分离
关于前后端分离的方案,在《基于NodeJS的前后端分离的思考与实践(一)》中有非常清晰的解释。我们在服务端接口和浏览器之间引入 NodeJS 作为渲染层,因为 NodeJS 层彻底与数据抽离,同时无需关心大量的业务逻辑,所以十分适合在这一层进行多终端的适配工作。
UA 探测
进行多终端适配首先要解决的是 UA 探测问题,对于一个过来的请求,我们需要知道这个设备的类型才能针对对它输出对应的内容。现在市面上已经有非常成熟的兼容大量设备的 User Agent 特征库和探测工具,这里有 Mozilla 整理的一个列表。其中,既有运行在浏览器端的,也有运行在服务端代码层的,甚至有些工具提供了 Nginx/Apache 的模块,负责解析每个请求的 UA 信息。
实际上我们推荐最后一种方式。基于前后端分离的方案决定了 UA 探测只能运行在服务器端,但如果把探测的代码和特征库耦合在业务代码里并不是一个足够友好的方案。我们把这个行为再往前挪,挂在 Nginx/Apache 上,它们负责解析每个请求的 UA 信息,再通过如 HTTP Header 的方式传递给业务代码。
这样做有几点好处:
我们的代码里面无需再去关注 UA 如何解析,直接从上层取出解析后的信息即可。如果在同一台服务器上有多个应用,则能够共同使用同一个 Nginx 解析后的 UA 信息,节省了不同应用间的解析损耗。

来自天猫分享的基于 Nginx 的 UA 探测方案
淘宝的 Tengine Web 服务器也提供了类似的模块 ngx_http_user_agent_module。
值得一提的是,选用 UA 探测工具时必须要考虑特征库的可维护性,因为市面上新增的设备类型越来越多,每个设备都会有独立的 User Agent,所以该特征库必须提供良好的更新和维护策略,以适应不断变化的设备。
建立在 MVC 模式中的几种适配方案
取得 UA 信息后,我们就要考虑如果根据指定的 UA 进行终端适配了。即使在 NodeJS 层,虽然没有了大部分的业务逻辑,但我们依然把内部区分为 Model / Controller / View 三个模型。

我们先利用上面的图,去解析一些已有的多终端适配方案。
建立在 Controller 上的适配方案

这种方案应该是最简单粗暴的处理方法。通过路由(Router)将相同的 URL 统一传递到同一个控制层(Controller)。控制层再通过 UA 信息将数据和模型(Model)逻辑派发到对应的展现(View)进行渲染,渲染层则按预先的约定提供了适配几个终端的模板。
这种方案的好处是,保持了数据和控制层的统一性,业务逻辑只需处理一次遍可以应用在所有终端上。但这种场景只适合如展示型页面等低交互型的应用,一旦业务比较复杂,各个终端的 Controller 可能有各自的处理逻辑,如果还是共用一个 Controller ,会导致 Controller 非常的臃肿而且难以维护,这无疑是一个错误的选择。
建立在 Router 上的适配方案
为了解决上面遇到的问题,我们可以在 Router 上就将设备区分,针对不同的终端分发到不同的 Controller 上:

这也是最常见的方案之一,大多表现在针对不同终端使用各自独立的一套应用。如 PC 淘宝首页和 WAP 版的淘宝首页,不同设备访问 www.taobao.com ,服务器会通过 Router 的控制,重定向到 WAP 版的淘宝首页或者 PC 版的淘宝首页,它们各自是完全独立的两套应用。
但这种方案无疑带来了数据和部分逻辑无法共用的问题,各种终端之间无法分享同一份数据和业务逻辑,产生大量重复性工作,效率低下。
为了缓解这个问题,有人提出了优化后的方案:依然是在同一套应用里面,各个数据来源抽象成各个 Model,提供给不同终端的 Controller 组合使用:
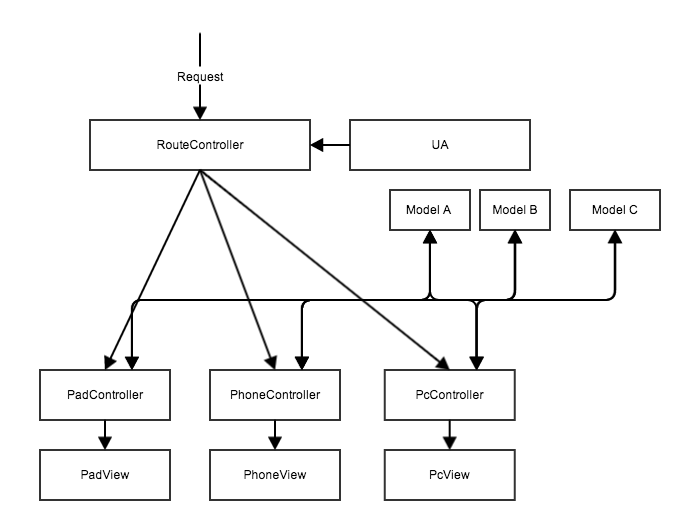
这个方案解决了前面数据无法共用的问题。在 Controller 上各个终端还是相互独立,但能共同使用同一批数据源,至少在数据上无需再针对终端类型开发独立的接口了。
以上两种基于 Router 的方案,由于 Controller 的独立,各个终端可以为自己的页面实现不同的交互逻辑,保证了各终端自身足够的灵活度,这也是为什么大部分应用采用这种方案的主要原因。
建立在 View 层的适配方案
这是淘宝下单页面使用的方案,不过区别是下单页将整体的渲染层放在了浏览器端,而不是 NodeJS 层。不过无论是浏览器还是 NodeJS,整体设计思路还是一致的:
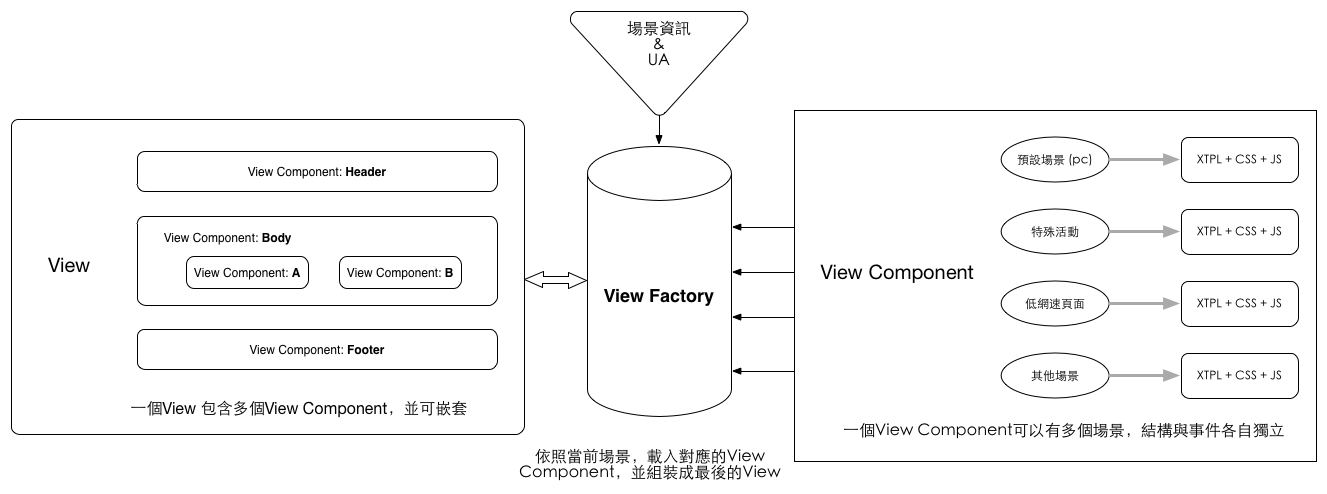
在这个方案里面,Router、Controller 和 Model 都无需关注设备信息,终端类型的判断完全交给展现层来处理。图中主要的模块是「View Factory」,Model 和 Controller 将数据和渲染逻辑传递过来之后,通过 View Factory 根据设备信息和其它状态(不仅仅是 UA 信息、也可以是网络环境、用户地区等等)从一堆预设好的组件(View Component)中抓取特定的组件,再组合成最终的页面。
这种方案有几个优势:
上层无需关注设备信息(UA),多终端的视频还是交由和最终展现最大关系的 View 层来处理;不仅仅是多终端适配,除了 UA 信息,各个 View Component 还可以根据用户状态决定自身输出何种模版,如低网速下默认隐藏图片、指定地区输出活动 Banner。每个 View Component 的不同模版间可以自行决定是否使用同一份数据、业务逻辑,提供十分灵活的实现方式。
但明显的是,这个方案也是最复杂的,尤其是要考虑一些富交互的应用场景时,Router 和 Controller 也许无法保持这么纯粹。特别对于一些整体性比较强的业务,本身无法被拆分成组件,这种方案也许并不适用;而且对于一些简单的业务,使用这种架构可能不是最佳的选择。
总结
以上几种方案,都各自体现在 MVC 模型中的一个或多个部分,在业务上如果一个方案不满足需求,更可以采取多个方案同时采用的方式。或是可以理解为,业务上的复杂度和交互属性决定了该产品更适合采用哪种多终端适配方案。
对比基于浏览器的响应式设计方案,因为绝大部分终端探测和渲染逻辑迁移到了服务端,所以在 NodeJS 层进行适配无疑带来了更好的性能和用户体验;另外,相对于一些所谓的「云适配」方案带来的转换质量问题,在基于前后端分离的「定制式」方案中也不会存在。前后端分离的适配方案在这些方面有着天然优势。
最后,为了适应更灵活的强大的适配需求,基于前后端分离的适配方案将会面临更多挑战!
相关推荐
-

基于NodeJS的前后端分离的思考与实践(一)全栈式开发
前言 为了解决传统Web开发模式带来的各种问题,我们进行了许多尝试,但由于前/后端的物理鸿沟,尝试的方案都大同小异.痛定思痛,今天我们重新思考了"前后端"的定义,引入前端同学都熟悉的NodeJS,试图探索一条全新的前后端分离模式. 随着不同终端(Pad/Mobile/PC)的兴起,对开发人员的要求越来越高,纯浏览器端的响应式已经不能满足用户体验的高要求,我们往往需要针对不同的终端开发定制的版本.为了提升开发效率,前后端分离的需求越来越被重视,后端负责业务/数据接口,前端负责展现/交互逻
-
基于NodeJS的前后端分离的思考与实践(四)安全问题解决方案
前言 在前后端分离的开发模式中,从开发的角色和职能上来讲,一个最明显的变化就是:以往传统中,只负责浏览器环境中开发的前端同学,需要涉猎到服务端层面,编写服务端代码.而摆在面前的一个基础性问题就是如何保障Web安全? 本文就在前后端分离模式的架构下,针对前端在Web开发中,所遇到的安全问题以及应对措施和注意事项,并提出解决方案. 跨站脚本攻击(XSS)的防御 问题及解决思路 跨站脚本攻击(XSS,Cross-site scripting)是最常见和基本的攻击Web网站的方法.攻击者可以在网页上发布
-
利用Node.js+Koa框架实现前后端交互的方法
前言 对于一个前端工程师来说不仅仅要会前端的内容,后端的技术也需要熟练掌握.今天我就要通过一个案例来描述一下前端是如何和后端进行数据交互的. koa 是由 Express 原班人马打造的,致力于成为一个更小.更富有表现力.更健壮的 Web 框架.使用 koa 编写 web 应用,通过组合不同的 generator,可以免除重复繁琐的回调函数嵌套,并极大地提升错误处理的效率.koa 不在内核方法中绑定任何中间件,它仅仅提供了一个轻量优雅的函数库,使得编写 Web 应用变得得心应手. 准备工作 首先
-
基于NodeJS的前后端分离的思考与实践(二)模版探索
前言 在做前后端分离时,第一个关注到的问题就是 渲染,也就是 View 这个层面的工作. 在传统的开发模式中,浏览器端与服务器端是由不同的前后端两个团队开发,但是模版却又在这两者中间的模糊地带.因此模版上面总不可避免的越来越多复杂逻辑,最终难以维护. 而我们选择了NodeJS,作为一个前后端的中间层.试图藉由NodeJS,来疏理 View 层面的工作. 使得前后端分工更明确,让专案更好维护,达成更好的用户体验. 本文 渲染这块工作,对于前端开发者的日常工作来说,佔了非常大的比例,也是最容易与后端
-
基于NodeJS的前后端分离的思考与实践(六)Nginx + Node.js + Java 的软件栈部署实践
淘宝网线上应用的传统软件栈结构为 Nginx + Velocity + Java,即: 在这个体系中,Nginx 将请求转发给 Java 应用,后者处理完事务,再将数据用 Velocity 模板渲染成最终的页面. 引入 Node.js 之后,我们势必要面临以下几个问题: 技术栈的拓扑结构该如何设计,部署方式该如何选择,才算是科学合理?项目完成后,该如何切分流量,对运维来说才算是方便快捷?遇到线上的问题,如何最快地解除险情,避免更大的损失?如何确保应用的健康情况,在负载均衡调度的层面加以管理?承系
-
基于 Node.js 实现前后端分离
基本介绍 首先从一个重要的概念"模板"说起. 广义上来说,web中的模板就是填充数据后可以生成文件的页面. 严格意义上来说,应该是模板引擎利用特定格式的文件和所提供的数据编译生成页面.模板大致分为前端模板(如ejs)和后端模板(如freemarker)分别在浏览器端和服务器端编译. 由于当场有一部分同学对node.js并不是很了解,这里补充一下node.js的相关知识.官网上的给他的定义事件驱动.异步什么的就不说了.这里借用朴灵书上的一张图来解释一下node.js这个玩意的结构.如果懂
-
Node.js的Koa框架上手及MySQL操作指南
由 Express 原班人马打造的 koa,致力于成为一个更小.更健壮.更富有表现力的 Web 框架.使用 koa 编写 web 应用,通过组合不同的 generator,可以免除重复繁琐的回调函数嵌套,并极大地提升常用错误处理效率.Koa 不在内核方法中绑定任何中间件,它仅仅提供了一个轻量优雅的函数库,使得编写 Web 应用变得得心应手. 安装koa koa 依赖支持 generator 的 Node 环境,也就是说,node的版本要在 0.11.9 或者更高,否则将无法执行. 用npm: $
-
基于NodeJS的前后端分离的思考与实践(三)轻量级的接口配置建模框架
前言 使用Node做前后端分离的开发模式带来了一些性能及开发流程上的优势, 但同时也面临不少挑战.在淘宝复杂的业务及技术架构下,后端必须依赖Java搭建基础架构,同时提供相关业务接口供前端使用.Node在整个环境中最重要的工作之一就是代理这些业务接口,以方便前端(Node端和浏览器端)整合数据做页面渲染.如何做好代理工作,使得前后端开发分离之后,仍然可以在流程上无缝衔接,是我们需要考虑的问题.本文将就该问题做相关探讨,并提出解决方案. 由于后端提供的接口方式可能多种多样,同时开发人员在编写Nod
-
基于NodeJS的前后端分离的思考与实践(五)多终端适配
前言 近年来各站点基于 Web 的多终端适配进行得如火如荼,行业间也发展出依赖各种技术的解决方案.有如基于浏览器原生 CSS3 Media Query 的响应式设计.基于云端智能重排的「云适配」方案等.本文则主要探讨在前后端分离基础下的多终端适配方案. 关于前后端分离 关于前后端分离的方案,在<基于NodeJS的前后端分离的思考与实践(一)>中有非常清晰的解释.我们在服务端接口和浏览器之间引入 NodeJS 作为渲染层,因为 NodeJS 层彻底与数据抽离,同时无需关心大量的业务逻辑,所以十分
-
基于Spring Security前后端分离的权限控制系统问题
目录 1. 引入maven依赖 2. 建表并生成相应的实体类 3. 自定义UserDetails 4. 自定义各种Handler 5. Token处理 6. 访问控制 7. 配置WebSecurity 8. 看效果 9. 补充:手机号+短信验证码登录 前后端分离的项目,前端有菜单(menu),后端有API(backendApi),一个menu对应的页面有N个API接口来支持,本文介绍如何基于Spring Security前后端分离的权限控制系统问题. 话不多说,入正题.一个简单的权限控制系统需要
-
Nginx实现前后端分离
#user nobody; worker_processes 1; #error_log logs/error.log; #error_log logs/error.log notice; #error_log logs/error.log info; #pid logs/nginx.pid; events { worker_connections 1024; } http { include mime.types; default_type application/octet-stream;
-
nodeJS(express4.x)+vue(vue-cli)构建前后端分离实例(带跨域)
准备工作: 1.安装nodejs ---还用我教了? 2.安装依赖包express4.x 点这里>>>nodeJS搭建本地服务器 3.安装vue-cli脚手架 点这里>>>vue-cli构建vue项目 这里强调一下,express是后端服务器,它是一个独立的服务器,vue启动的是前端服务器,vue-cli中已经集成了一个小型的express,这两个服务器是分开放的,但是它们都是基于nodejs的. nodeJS部分:这里我已经认为你搭建好了express服务器,并且能
-
详解从NodeJS搭建中间层再谈前后端分离
之前在知道创宇的项目中有用到过nodejs作中间层,当时还不太理解其背后真正的原因:后来在和一位学长交谈的过程中,也了解到蚂蚁金服也在使用类似的方法,使用nodejs作为中间层去请求真实后台的数据:之后人到北京,也见到现在的公司也在往nodejs后端方向靠拢.随着知识的增加,加之自己查阅资料,慢慢总结出了一些原理. 为什么要前后端分离 1.开发效率高 前端开发人员不用苦苦地配置各种后端环境,安装各种莫名的插件,摆脱对后端开发环境的依赖,一门心思写前端代码就好,后端开发人员也不用时不时的跑去帮着前