一次性彻底讲透Python中pd.concat与pd.merge
目录
- 数据拼接:pd.concat
- 数据关联:pd.merge
- 两者区别
数据的合并与关联是数据处理过程中经常遇到的问题,在SQL、HQL中大家可能都有用到 join、uion all 等 ,在 Pandas 中也有同样的功能,来满足数据处理需求,个人感觉 Pandas 处理数据还是非常方便,数据处理效率比较高,能满足不同的业务需求
数据拼接:pd.concat
concat 是pandas级的函数,用来拼接或合并数据,其根据不同的轴既可以横向拼接,又可以纵向拼接
函数参数
pd.concat(
objs: 'Iterable[NDFrame] | Mapping[Hashable, NDFrame]',
axis=0,
join='outer',
ignore_index: 'bool' = False,
keys=None,
levels=None,
names=None,
verify_integrity: 'bool' = False,
sort: 'bool' = False,
copy: 'bool' = True,
) -> 'FrameOrSeriesUnion'
objs:合并的数据集,一般用列表传入,例如:[df1,df2,df3]axis:指定数据拼接时的轴,0是行,在行方向上拼接;1是列,在列方向上拼接join:拼接的方式有 inner,或者outer,与sql中的意思一样
以上三个参数在实际工作中经常使用,其他参数不再做介绍
案例:
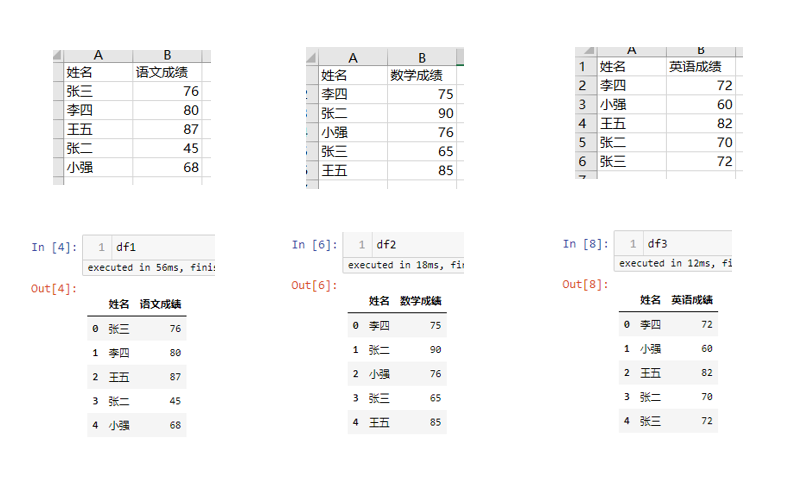
模拟数据
横向拼接

横向拼接-1
字段相同的列进行堆叠,字段不同的列分列存放,缺失值用NAN来填充,下面对模拟数据进行变换用相同的字段,进行演示
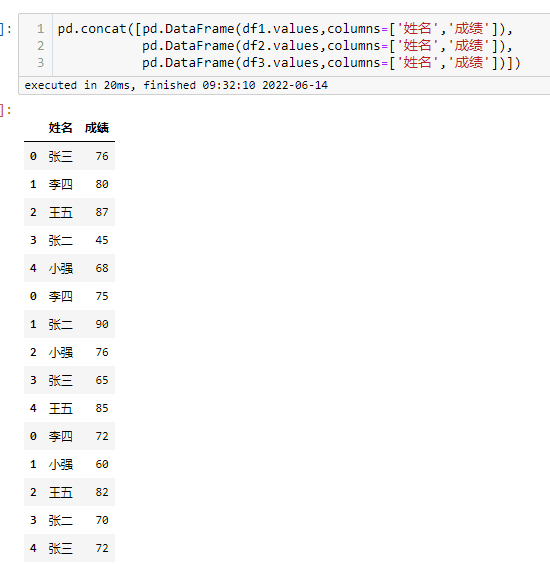
横向拼接-2
纵向拼接
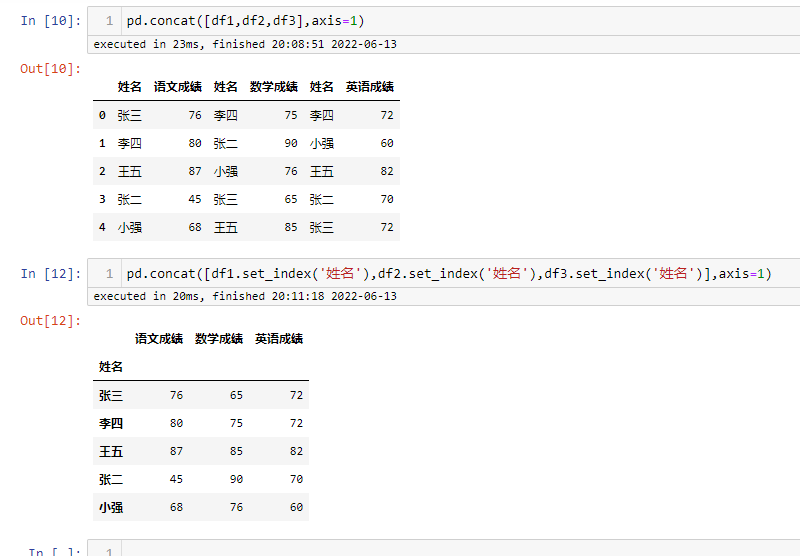
纵向拼接
可以看出在纵向拼接的时候,会按索引进行关联,使相同名字的成绩放在一起,而不是简单的堆叠
数据关联:pd.merge
数据关联与SQL中的join基本一样,一次可以关联两个数据表,有左表、右表的区分,需要可以指定关联的字段
函数参数
pd.merge(
left: 'DataFrame | Series',
right: 'DataFrame | Series',
how: 'str' = 'inner',
on: 'IndexLabel | None' = None,
left_on: 'IndexLabel | None' = None,
right_on: 'IndexLabel | None' = None,
left_index: 'bool' = False,
right_index: 'bool' = False,
sort: 'bool' = False,
suffixes: 'Suffixes' = ('_x', '_y'),
copy: 'bool' = True,
indicator: 'bool' = False,
validate: 'str | None' = None,
) -> 'DataFrame'
left:左表right:右表how:关联的方式,{‘left’, ‘right’, ‘outer’, ‘inner’, ‘cross’}, 默认关联方式为 ‘inner’on:关联时指定的字段,两个表共有的left_on:关联时用到左表中的字段,在两个表不共有关联字段时使用right_on:关联时用到右表中的字段,在两个表不共有关联字段时使用
以上参数在实际工作中经常使用,其他参数不再做介绍
案例:
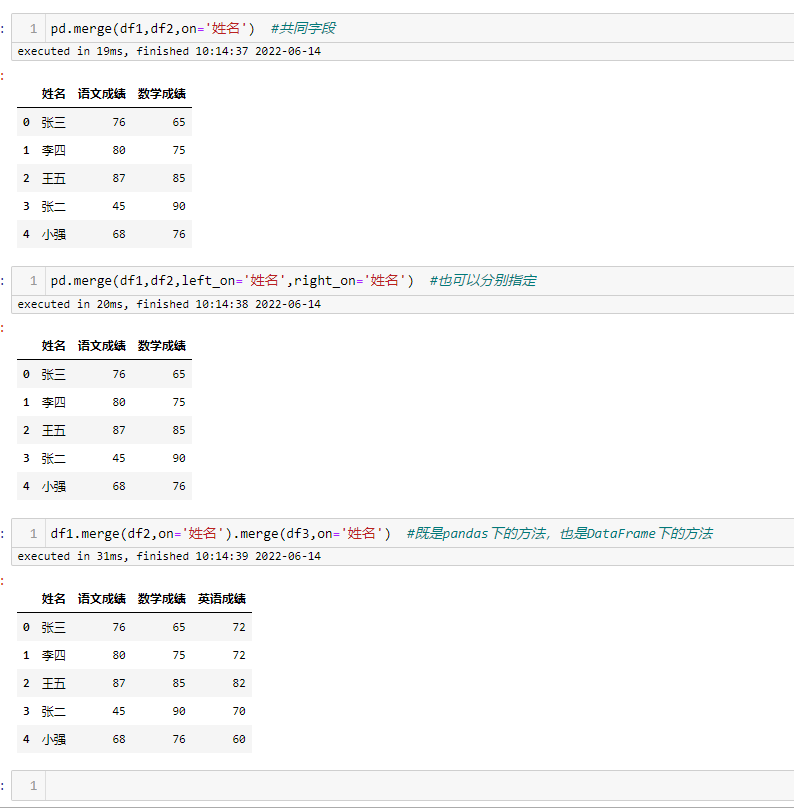
数据关联
merge 的使用与SQL中的 join 很像,使用方式基本一致,既有内连接,也有外连接,用起来基本没有什么难度
两者区别
- concat 只是 pandas 下的方法,而 merge 即是 pandas 下的方法,又是DataFrame 下的方法
- concat 可以横向、纵向拼接,又起到关联的作用
- merge 只能进行关联,也就是纵向拼接
- concat 可以同时处理多个数据框DataFrame,而 merge 只能同时处理 2 个数据框
到此这篇关于一次性彻底讲透Python中pd.concat与pd.merge的文章就介绍到这了,更多相关Python pd.concat与pd.merge内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
详解pandas数据合并与重塑(pd.concat篇)
1 concat concat函数是在pandas底下的方法,可以将数据根据不同的轴作简单的融合 pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False) 参数说明 objs: series,dataframe或者是panel构成的序列lsit axis: 需要合并链接的轴,0是行,1是列
-

一次性彻底讲透Python中pd.concat与pd.merge
目录 数据拼接:pd.concat 数据关联:pd.merge 两者区别 数据的合并与关联是数据处理过程中经常遇到的问题,在SQL.HQL中大家可能都有用到 join.uion all 等 ,在 Pandas 中也有同样的功能,来满足数据处理需求,个人感觉 Pandas 处理数据还是非常方便,数据处理效率比较高,能满足不同的业务需求 数据拼接:pd.concat concat 是pandas级的函数,用来拼接或合并数据,其根据不同的轴既可以横向拼接,又可以纵向拼接 函数参数 pd.concat(
-
Python数据合并的concat函数与merge函数详解
目录 一.concat函数 1)横向堆叠与外连接 2) 纵向堆叠与内链接 二.merge()函数 1)根据行索引合并数据 2)合并重叠数据 一.concat函数 1.concat()函数可以沿着一条轴将多个对象进行堆叠,其使用方式类似数据库中的数据表合并pandas.concat(objs, axis=0, join=’outer’, join_axes=None, ignore_index=False, keys=None, levels=None, verify_integrity=Fals
-
解析Python中的变量、引用、拷贝和作用域的问题
在Python中,变量是没有类型的,这和以往看到的大部分编辑语言都不一样.在使用变量的时候,不需要提前声明,只需要给这个变量赋值即可.但是,当用变量的时候,必须要给这个变量赋值:如果只写一个变量,而没有赋值,那么Python认为这个变量没有定义.如下: >>> a Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'a'
-
python中多个装饰器的执行顺序详解
装饰器是程序开发中经常会用到的一个功能,也是python语言开发的基础知识,如果能够在程序中合理的使用装饰器,不仅可以提高开发效率,而且可以让写的代码看上去显的高大上^_^ 使用场景 可以用到装饰器的地方有很多,简单的举例如以下场景 引入日志 函数执行时间统计 执行函数前预备处理 执行函数后清理功能 权限校验等场景 缓存 今天讲一下python中装饰器的执行顺序,以两个装饰器为例. 装饰器代码如下: def wrapper_out1(func): print('--out11--') def i
-
带你从内存的角度看Python中的变量
目录 1.前言 2.引用式变量 3.赋值.浅拷贝与深拷贝 4.is的用法和id()函数 5.函数传参机制 6.扩展阅读 总结 1.前言 由于笔者并未系统地学习过Python,对Python某些底层的实现细节一概不清楚,以至于在实际使用的时候会写出一些奇奇怪怪的Bug(没错,别人写代码,我写Bug),比如对象的某些属性莫名奇妙地改变.究其原因,是对Python中的变量机制存在一些误解,毕竟以前一直是用C语言居多.无奈,只能深入学习这一部分的知识,并总结成此文. 阅读本文,你可以: 了解Python
-
python中DataFrame数据合并merge()和concat()方法详解
目录 merge() 1.常规合并 ①方法1 ②方法2 重要参数 合并方式 left right outer inner 2.多对一合并 3.多对多合并 concat() 1.相同字段的表首位相连 2.横向表合并(行对齐) 3.交叉合并 总结 merge() 1.常规合并 ①方法1 指定一个参照列,以该列为准,合并其他列. import pandas as pd df1 = pd.DataFrame({'id': ['001', '002', '003'], 'num1': [120, 101,
-
python中pd.cut()与pd.qcut()的对比及示例
目录 1.pd.cut() 2.pd.qcut() 3.pd.cut() v.s. pd.qcut() 1.pd.cut() 用于将数据值按照值本身进行分段并排序到 bins 中.参数包含:x, bins, right, include_lowest, labels, retbins, precision x :被划分的数组bins :被划分的区间/区间数 - ① 当 bins 为整数时,表示数组 x 被划分为多少个等间距的区间: - ② 当 bins 为序列时,表示数组 x 将被划分在该指定序
-
Python中第三方库Faker的使用详解
目录 背景介绍 实战:模拟1w条数据写入Excel Python库讲解 1. 生成姓名 2. 生成详细地址 3. 生成所在省份 4. 生成手机号 5. 生成身份证号 6. 生成出生年月 7. 生成邮箱 补充 1. address 地址 2. person 人物 3. color 颜色 4. company 公司 5. credit_card 银行信用卡 6. date_time 时间日期 7. file 文件 8. internet 互联网 9. job 工作 10. lorem 乱数假文 11
-
浅谈python中的面向对象和类的基本语法
当我发现要写python的面向对象的时候,我是踌躇满面,坐立不安呀.我一直在想:这个坑应该怎么爬?因为python中关于面向对象的内容很多,如果要讲透,最好是用面向对象的思想重新学一遍前面的内容.这个坑是如此之大,犹豫再三,还是只捡一下重要的内容来讲吧,不足的内容只能靠大家自己去补充了. 惯例声明一下,我使用的版本是 python2.7,版本之间可能存在差异. 好,在开讲之前,我们先思考一个问题,看代码: 为什么我只创建是为 a 赋值,就可以使用一些我没写过的方法? 可能会有小伙伴说:因为 a
-
利用Python中的pandas库对cdn日志进行分析详解
前言 最近工作工作中遇到一个需求,是要根据CDN日志过滤一些数据,例如流量.状态码统计,TOP IP.URL.UA.Referer等.以前都是用 bash shell 实现的,但是当日志量较大,日志文件数G.行数达数千万亿级时,通过 shell 处理有些力不从心,处理时间过长.于是研究了下Python pandas这个数据处理库的使用.一千万行日志,处理完成在40s左右. 代码 #!/usr/bin/python # -*- coding: utf-8 -*- # sudo pip instal