Apache Hudi结合Flink的亿级数据入湖实践解析
目录
- 1. 实时数据落地需求演进
- 2. 基于Spark+Hudi的实时数据落地应用实践
- 3. 基于Flink自定义实时数据落地实践
- 4. 基于Flink + Hudi的落地数据实践
- 5. 后续应用规划及展望
- 5.1 取代离线报表,提高报表实时性及稳定性
- 5.2 完善监控体系,提升落数据任务稳定性
- 5.3 落数据中间过程可视化探索
本次分享分为5个部分介绍Apache Hudi的应用与实践

1. 实时数据落地需求演进
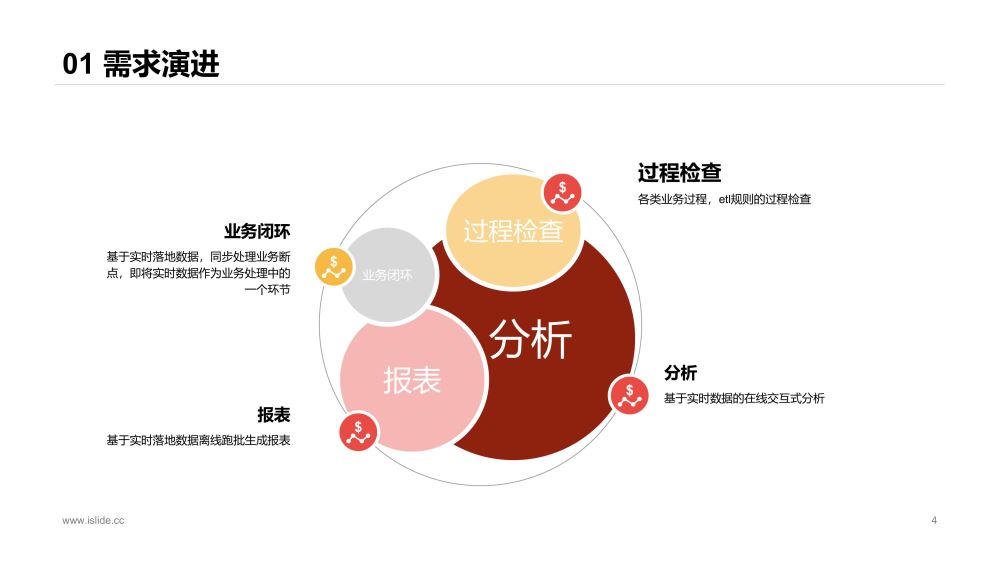
实时平台上线后,主要需求是开发实时报表,即抽取各类数据源做实时etl后,吐出实时指标到oracle库中供展示查询。
随着实时平台的稳定及推广开放,各种使用人员有了更广发的需求:
- 对实时开发来说,需要将实时sql数据落地做一些etl调试,数据取样等过程检查;
- 数据分析、业务等希望能结合数仓已有数据体系,对实时数据进行分析和洞察,比如用户行为实时埋点数据结合数仓已有一些模型进行分析,而不是仅仅看一些高度聚合化的报表;
- 业务希望将实时数据作为业务过程的一环进行业务驱动,实现业务闭环;
- 针对部分需求,需要将实时数据落地后,结合其他数仓数据,T - 1离线跑批出报表;
>
除了上述列举的主要的需求,还有一些零碎的需求。
总的来说,实时平台输出高度聚合后的数据给用户,已经满足不了需求,用户渴求更细致,更原始,更自主,更多可能的数据
而这需要平台能将实时数据落地至离线数仓体系中,因此,基于这些需求演进,实时平台开始了实时数据落地的探索实践
2. 基于Spark+Hudi的实时数据落地应用实践
最早开始选型的是比较流行的Spark + Hudi体系,整体落地架构如下:

这套主要基于以下考虑:
- 数仓开发不需写Scala/Java打Jar包做任务开发
- ETL逻辑能够嵌入落数据任务中
- 开发入口统一
我们当时做了通用的落数据通道,通道由Spark任务Jar包和Shell脚本组成,数仓开发入口为统一调度平台,将落数据的需求转化为对应的Shell参数,启动脚本后完成数据的落地。
3. 基于Flink自定义实时数据落地实践
由于我们当时实时平台是基于Flink,同时Spark+Hudi对于大流量任务的支持有一些问题,比如落埋点数据时,延迟升高,任务经常OOM等,因此决定探索Flink落数据的路径。
当时Flink+Hudi社区还没有实现,我们参考Flink+ORC的落数据的过程,做了实时数据落地的实现,主要是做了落数据Schema的参数化定义,使数据开发同事能shell化实现数据落地。

4. 基于Flink + Hudi的落地数据实践
Hudi整合Flink版本出来后,实时平台就着手准备做兼容,把Hudi纳入了实时平台开发内容。
先看下接入后整体架构

实时平台对各类数据源及Sink端都以各类插件接入,我们参考了HudiFlinkTable的Sink流程,将Hudi接入了我们的实时开发平台。
为了提高可用性,我们主要做了以下辅助功能;
- Hive表元数据自动同步、更新;
- Hudi schema自动拼接;
- 任务监控、Metrics数据接入等
实际使用过程如下

整套体系上线后,各业务线报表开发,实时在线分析等方面都有使用,比较好的赋能了业务,上线链路共26条,单日数据落入约3亿条左右
5. 后续应用规划及展望
后续主要围绕如下几个方面做探索
5.1 取代离线报表,提高报表实时性及稳定性
离线报表特点是 T - 1,凌晨跑数,以及报表整体依赖链路长。两个特点导致时效性不高是一个方面,另一个方面是,数据依赖链路长的情况下,中间数据出问题容易导致后续整体依赖延时,而很多异常需要等到报表任务实际跑的时候,才能暴露出来。并且跑批问题凌晨暴露,解决的时效与资源协调都是要降低一个等级的,这对稳定性准时性要求的报表是不可接受的,特别是金融公司来说,通过把报表迁移至实时平台,不仅仅是提升了报表的时效性,由于抽数及报表etl是一直再实时跑的,报表数据给出的稳定性能有一个较大的提升。这是我们Hudi实时落数据要应用的规划之一
5.2 完善监控体系,提升落数据任务稳定性
目前仅仅做到落数据任务的监控,即任务是否正常运行,有没有抛异常等等。但实际使用者更关心数据由上游到Hive整条链路的监控情况。比如数据是否有延迟,是否有背压,数据源消费情况,落数据是否有丢失,各个task是否有瓶颈等情况,总的来说,用户希望能更全面细致的了解到任务的运行情况,这也是后面的监控需要完善的目标
5.3 落数据中间过程可视化探索
这个是和上面的监控有类似的地方,用户希望确定,一条数据从数据源接进来,经过各个算子的处理,它的一些详细情况。比如这个数据是否应该被过滤,处于哪个窗口,各个算子的处理时间等等,否则对于用户,整个数据SQL处理流程是一个黑盒。
以上就是Apache Hudi结合Flink的亿级数据入湖实践解析的详细内容,更多关于Apache Hudi结合Flink的亿级数据的资料请关注我们其它相关文章!
相关推荐
-

Flink入门级应用域名处理示例
目录 概述 算子 FlatMap KeyBy Reduce 连接socket测试 连接kafka 正式 测试 打包上传服务器 概述 最近做了一个小任务,要使用Flink处理域名数据,在4GB的域名文档中求出每个域名的顶级域名,最后输出每个顶级域名下的前10个子级域名.一个比较简单的入门级Flink应用,代码很容易写,主要用到的算子有FlatMap.KeyBy.Reduce.但是由于Maven打包问题,总是提示找不到入口类,卡了好久,最后也是成功解决了. 主体代码如下: public class
-
Flink开发IDEA环境搭建与测试的方法
一.IDEA开发环境 1.pom文件设置 <properties> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> <encoding>UTF-8</encoding> <scala.version>2.11.12</scala.version>
-
解析Flink内核原理与实现核心抽象
目录 一.环境对象 1.1 执行环境 StreamExecutionEnvironment LocalStreamEnvironment RemoteStreamEnvironment StreamContextEnvironment StreamPlanEnvironment ScalaShellStreamEnvironment 1.2 运行时环境 RuntimeEnvironment SavepointEnvironment 1.3 运行时上下文 StreamingRuntimeConte
-
Apache FlinkCEP 实现超时状态监控的步骤详解
CEP - Complex Event Processing复杂事件处理. 订单下单后超过一定时间还未进行支付确认. 打车订单生成后超过一定时间没有确认上车. 外卖超过预定送达时间一定时限还没有确认送达. Apache FlinkCEP API CEPTimeoutEventJob FlinkCEP源码简析 DataStream和PatternStream DataStream 一般由相同类型事件或元素组成,一个DataStream可以通过一系列的转换操作如Filter.Map等转换为另一个Da
-
IDEA上运行Flink任务的实战教程
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS等: IDEA是常用的IDE,我们编写的flink任务代码如果能直接在IDEA运行,会给学习和开发带来很大便利,例如改完代码立即运行不用部署.断点.单步调试等: 环境信息 电脑:2019版13寸MacBook Pro,2.3 GHz 四核Intel Core i5,8 GB 2133 MHz LPD
-
Apache Hudi结合Flink的亿级数据入湖实践解析
目录 1. 实时数据落地需求演进 2. 基于Spark+Hudi的实时数据落地应用实践 3. 基于Flink自定义实时数据落地实践 4. 基于Flink + Hudi的落地数据实践 5. 后续应用规划及展望 5.1 取代离线报表,提高报表实时性及稳定性 5.2 完善监控体系,提升落数据任务稳定性 5.3 落数据中间过程可视化探索 本次分享分为5个部分介绍Apache Hudi的应用与实践 1. 实时数据落地需求演进 实时平台上线后,主要需求是开发实时报表,即抽取各类数据源做实时etl后,吐出实时
-
Apache Hudi异步Clustering部署操作的掌握
目录 1. 摘要 2. 介绍 3. Clustering策略 3.1 计划策略 3.2 执行策略 3.3 更新策略 4. 异步Clustering 4.1 HoodieClusteringJob 4.2 HoodieDeltaStreamer 4.3 Spark Structured Streaming 5. 总结和未来工作 1. 摘要 在之前的一篇博客中,我们介绍了Clustering(聚簇)的表服务来重新组织数据来提供更好的查询性能,而不用降低摄取速度,并且我们已经知道如何部署同步Clust
-
Apache Hudi基于华米科技应用湖仓一体化改造
目录 1. 应用背景及痛点介绍 2. 技术方案选型 3. 问题与解决方案 3.1.增量数据字段对齐问题 3.2 全球存储兼容性问题 3.3 云主机时区统一问题 3.4 升级新版本问题 3.5 多分区Upsert性能问题 3.6 数据特性适应问题 4. 上线收益 4.1 成本方面 4.2 效率方面 4.3 稳定性层面 4.4 查询性能层面 5. 总结与展望 1. 应用背景及痛点介绍 华米科技是一家基于云的健康服务提供商,拥有全球领先的智能可穿戴技术.在华米科技,数据建设主要围绕两类数据:设备数据和
-
Apache Hudi基于华米科技应用湖仓一体化改造
目录 1. 应用背景及痛点介绍 2. 技术方案选型 3. 问题与解决方案 3.1.增量数据字段对齐问题 3.2 全球存储兼容性问题 3.3 云主机时区统一问题 3.4 升级新版本问题 3.5 多分区Upsert性能问题 3.6 数据特性适应问题 4. 上线收益 4.1 成本方面 4.2 效率方面 4.3 稳定性层面 4.4 查询性能层面 5. 总结与展望 1. 应用背景及痛点介绍 华米科技是一家基于云的健康服务提供商,拥有全球领先的智能可穿戴技术.在华米科技,数据建设主要围绕两类数据:设备数据和
-
Apache Hudi异步Clustering部署操作的掌握
目录 1. 摘要 2. 介绍 3. Clustering策略 3.1 计划策略 3.2 执行策略 3.3 更新策略 4. 异步Clustering 4.1 HoodieClusteringJob 4.2 HoodieDeltaStreamer 4.3 Spark Structured Streaming 5. 总结和未来工作 1. 摘要 在之前的一篇博客中,我们介绍了Clustering(聚簇)的表服务来重新组织数据来提供更好的查询性能,而不用降低摄取速度,并且我们已经知道如何部署同步Clust
-
使用Apache Hudi 加速传统的批处理模式的方法
目录 1. 现状说明 1.1 数据湖摄取和计算过程 - 处理更新 1.2 当前批处理过程中的挑战 2. Hudi 数据湖 — 查询模式 2.1 面向分析师的表/OLAP(按 created_date 分区) 2.2 面向ETL(按更新日期分区) 1. “created_date”分区的挑战 2. “updated_date”分区的挑战 3. “新”重复数据删除策略 4. Apache Hudi 的优势 Apache Hudi(简称:Hudi)使得您能在hadoop兼容的存储之上存储大量数据,同时
-
mysql数据库如何实现亿级数据快速清理
今天收到磁盘报警异常,50G的磁盘被撑爆了,分析解决过程如下: 1. 进入linux服务器,查看mysql文件夹中各个数据库所占的磁盘空间大小 看到了吗,光olderdb就占了25G 2. 用SQLyog登录mysql数据库,查看数据库各个表的占用空间情况 SELECT CONCAT(table_schema,'.',table_name) AS 'aaa', table_rows AS 'Number of Rows', CONCAT(ROUND(data_length/(1024*1024*
-
浅谈MySQL 亿级数据分页的优化
背景 下班后愉快的坐在在回家的地铁上,心里想着周末的生活怎么安排. 突然电话响了起来,一看是我们的一个开发同学,顿时紧张了起来,本周的版本已经发布过了,这时候打电话一般来说是线上出问题了. 果然,沟通的情况是线上的一个查询数据的接口被疯狂的失去理智般的调用,这个操作直接导致线上的MySql集群被拖慢了. 好吧,这问题算是严重了,下了地铁匆匆赶到家,开电脑,跟同事把Pinpoint上的慢查询日志捞出来.看到一个很奇怪的查询,如下 POST domain/v1.0/module/method?ord
-
如何使用分区处理MySQL的亿级数据优化
mysql在查询上千万级数据的时候,通过索引可以解决大部分查询优化问题.但是在处理上亿数据的时候,索引就不那么友好了. 数据表(日志)是这样的: 表大小:1T,约24亿行: 表分区:按时间分区,每个月为一个分区,一个分区约2-3亿行数据(40-70G左右). 由于数据不需要全量处理,经过与需求方讨论后,我们按时间段抽样一部分数据,比如抽样一个月的数据,约3.5亿行. 数据处理的思路: 1)建表引擎选择Innodb.由于数据是按月分区的,我们将该月分区的数据单独copy出来,源表为myisam引擎
-
MySQL 亿级数据导入导出及迁移笔记
最近MySQL的笔记有点多了,主要是公司Oracle比较稳定维护较少,上周被安排做了一个MySQL亿级数据的迁移,趁此记录下学习笔记: 数据迁移,工作原理和技术支持数据导出.BI报表之类的相似,差异较大的地方是导入和导出数据量区别,一般报表数据量不会超过几百万,而做数据迁移,如果是互联网企业经常会涉及到千万级.亿级以上的数据量. 导入和导出是两个过程,即使做数据迁移我们也要分开来看,同时,导入/导出方式又分为: 1.MySQL自带导入/导出方式 2.各类客户端导入/导出方式 先总结下导出: 1.