python爬虫爬取bilibili网页基本内容
用爬虫爬取bilibili网站排行榜游戏类的所有名称及链接:
导入requests、BeautifulSoup
import requests from bs4 import BeautifulSoup
然后我们需要插入网站链接并且要解析网站并打印出来:
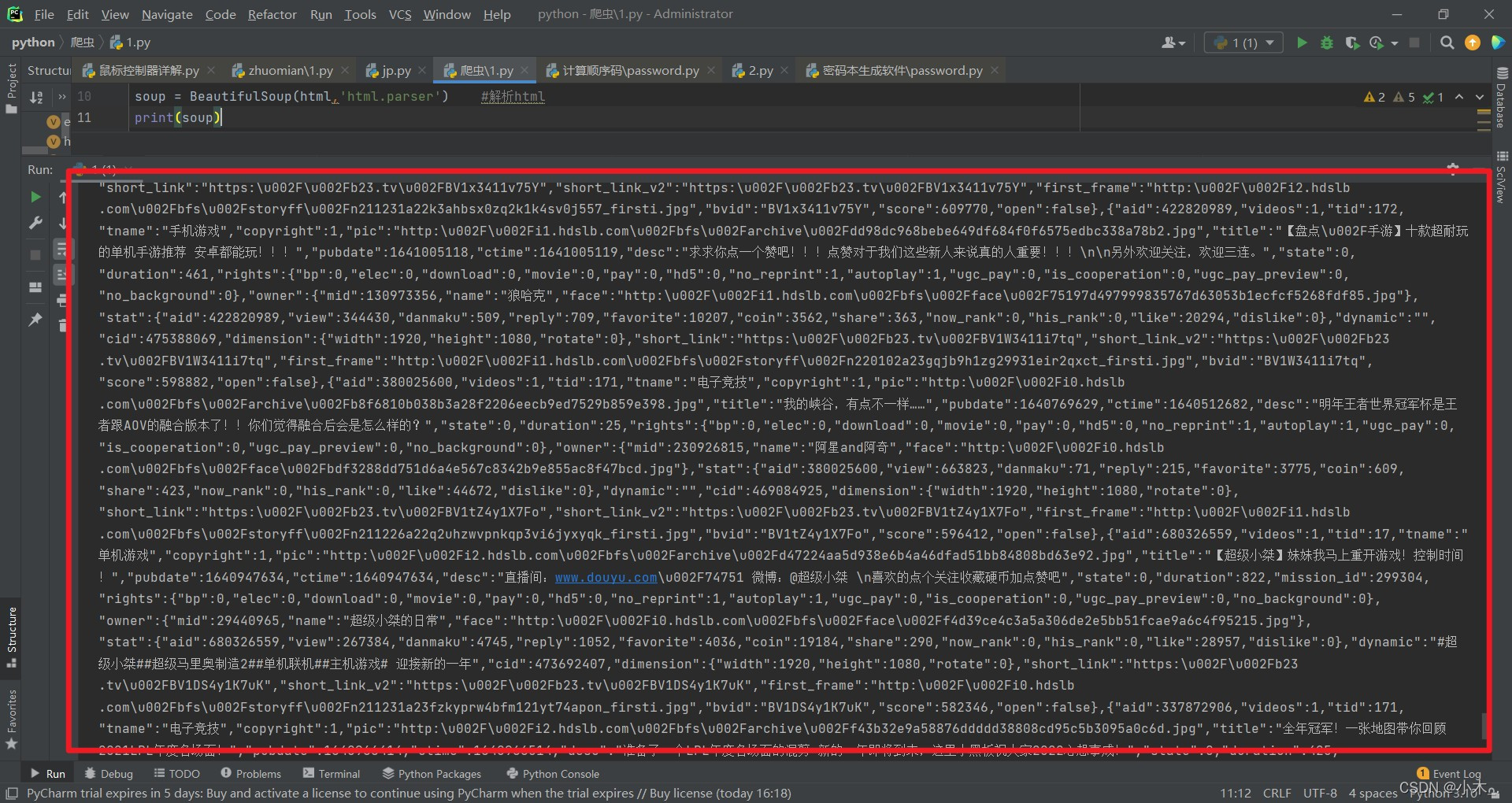
e = requests.get('https://www.bilibili.com/v/popular/rank/game') #当前网站链接
html = e.content
soup = BeautifulSoup(html,'html.parser') #解析html
print(soup)
我们可以看到密密麻麻的代码函数,但不太简洁明了,我们去优化一下
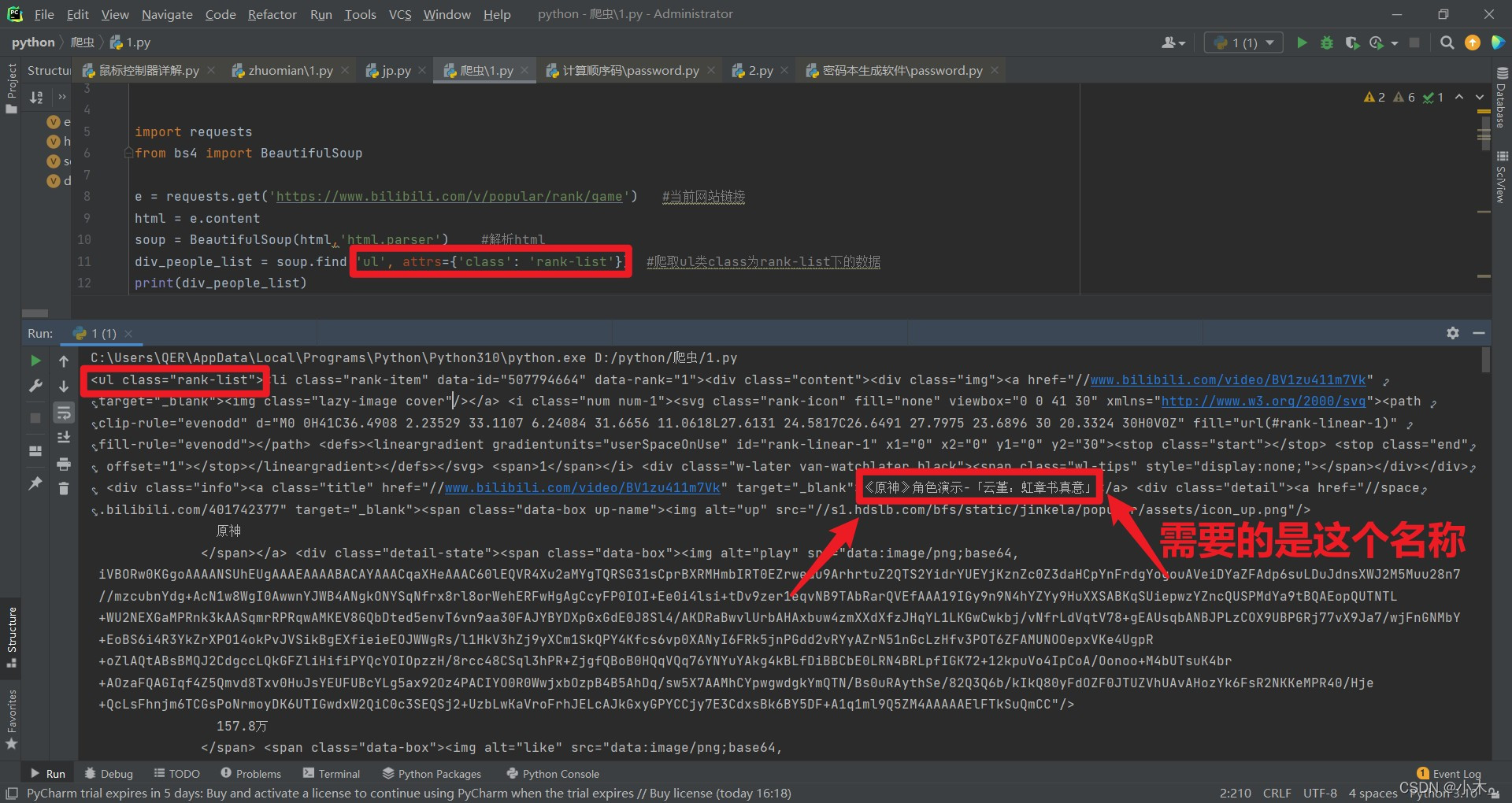
继续插入如下代码这个代码是可以爬取我们想要的类,可以更简介的简化代码
div_people_list = soup.find('ul', attrs={'class': 'rank-list'}) #爬取ul类class为rank-list下的数据
可以看到还是不够简介:
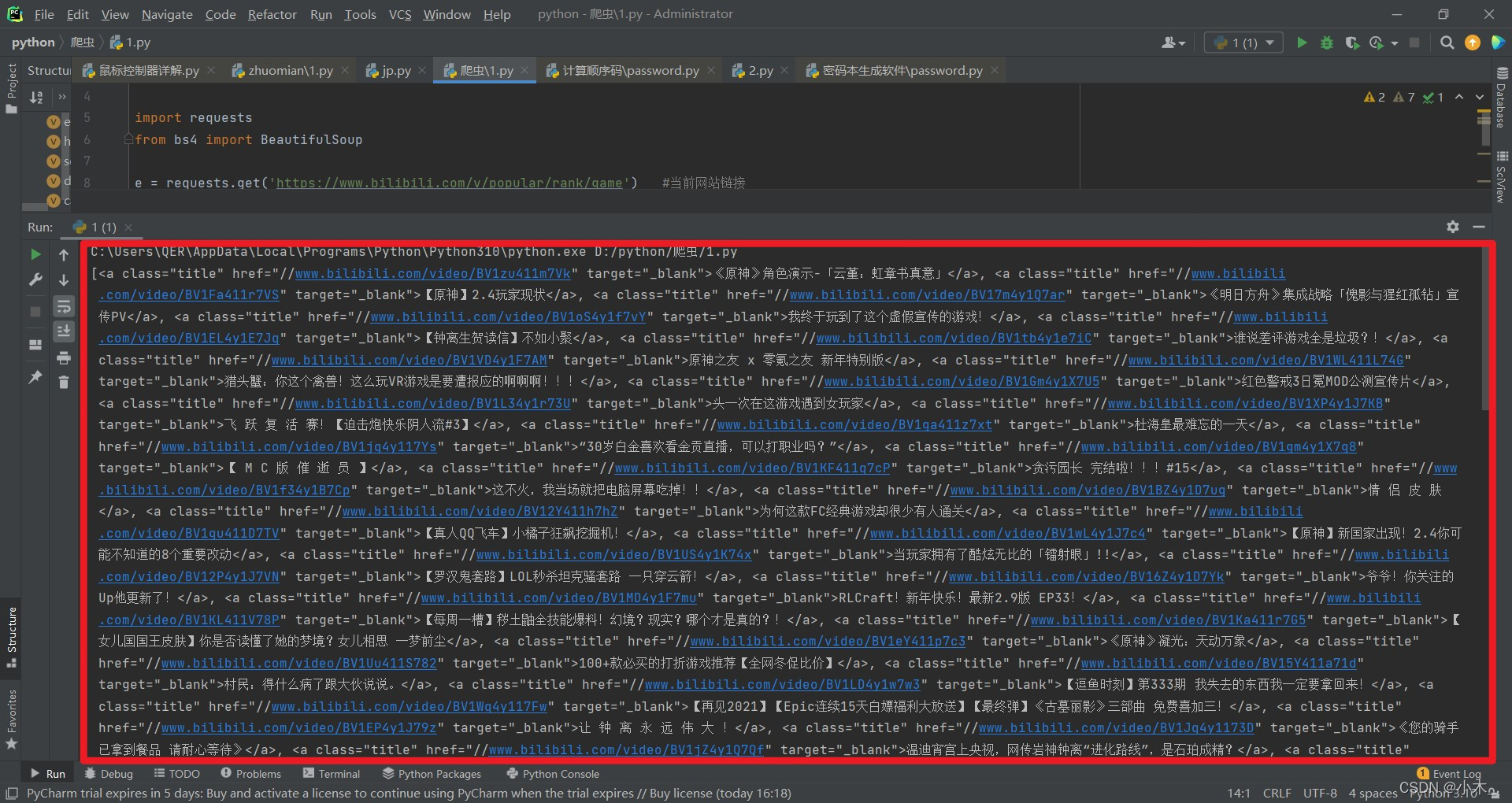
继续插入如下代码:
ca_s = div_people_list.find_all('a', attrs={'class': 'title'}) #爬取a类class为title下的数据
可以看到链接及主题都提取出来了,但还是有瑕疵:
我们加入这行代码挨个打印并提取标题及链接,由于链接提取出来的是//www.bilibili.com/video/BV1yZ4y1D7ef
前面没有http:点击进去会出现错误,所有我们需要在前面加入http:进行连接在一起打印
for t in ca_s:
url = t['href']
name = t.get_text()
print(name+'\t点击链接直接观看链接:'+f'http:{url}')
可以看到我们的标题及连接都爬取出来了
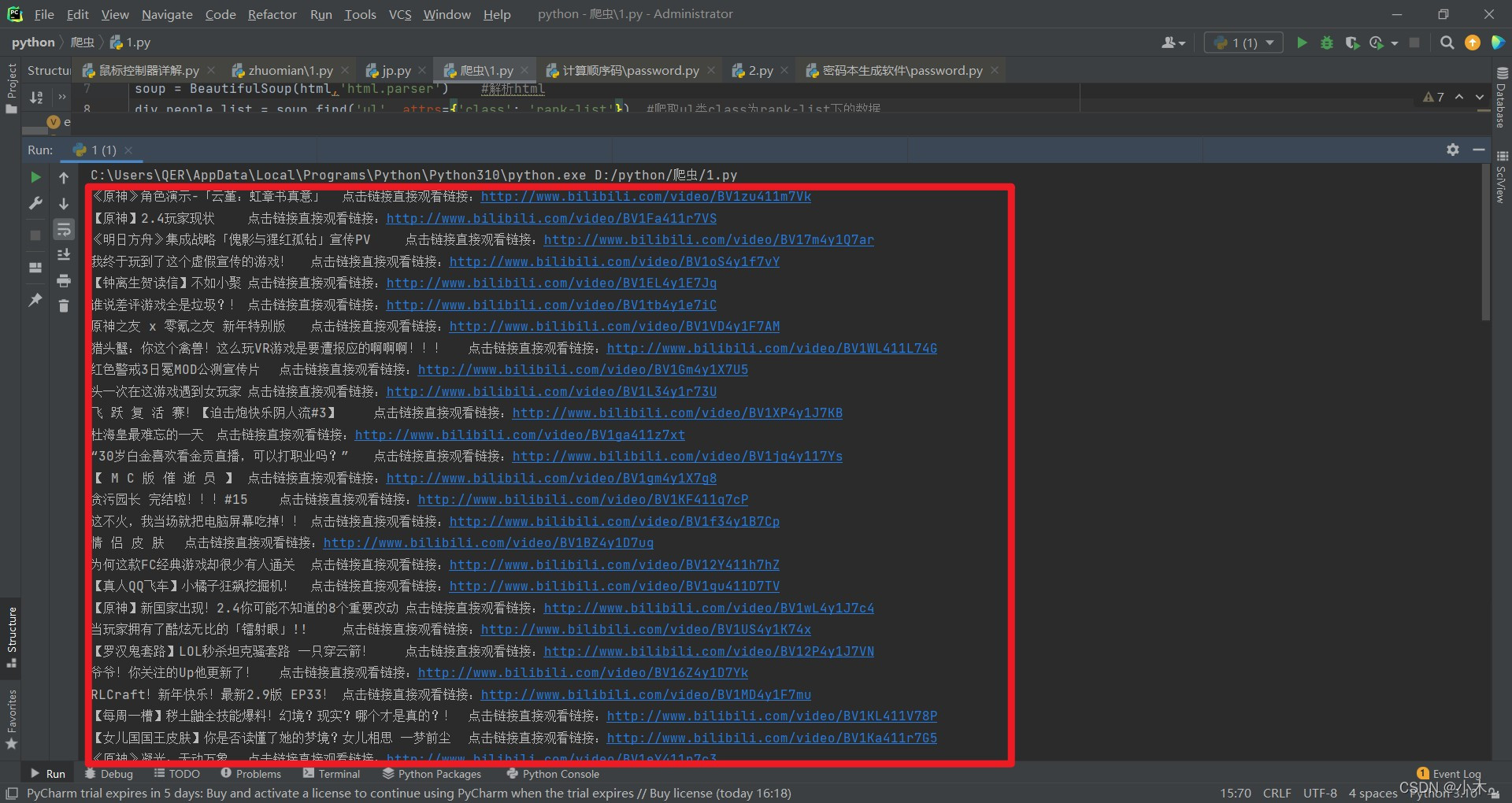
完整代码:
import requests
from bs4 import BeautifulSoup
e = requests.get('https://www.bilibili.com/v/popular/rank/game') #当前网站链接
html = e.content
soup = BeautifulSoup(html,'html.parser') #解析html
div_people_list = soup.find('ul', attrs={'class': 'rank-list'}) #爬取ul类class为rank-list下的数据
ca_s = div_people_list.find_all('a', attrs={'class': 'title'}) #爬取a类class为title下的数据
#挨个传输到t,然后打印数据
for t in ca_s:
url = t['href']
name = t.get_text()
print(name+'\t点击链接直接观看链接:'+f'http:{url}')
到此这篇关于python爬虫爬取bilibili网页基本内容的文章就介绍到这了,更多相关python爬取bilibili网页内容内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python爬取bilibili网页排名,视频,播放量,点赞量,链接等内容并存储csv文件中
首先要了解html标签,标签有主有次,大致了解以一下,主标签是根标签,也是所有要爬取的标签的结合体 先了解一下待会要使用代码属性: #获取属性 a.attrs 获取a所有的属性和属性值,返回一个字典 a.attrs['href'] 获取href属性 a['href'] 也可简写为这种形式 #获取内容 a.string 获取a标签的直系文本 注意:如果标签还有标签,那么string获取到的结果为None,而其它两个,可以获取文本内容 a.text 这是属性,获取a子类的所
-
python爬虫爬取bilibili网页基本内容
用爬虫爬取bilibili网站排行榜游戏类的所有名称及链接: 导入requests.BeautifulSoup import requests from bs4 import BeautifulSoup 然后我们需要插入网站链接并且要解析网站并打印出来: e = requests.get('https://www.bilibili.com/v/popular/rank/game') #当前网站链接 html = e.content soup = BeautifulSoup(html,'htm
-
Python爬虫爬取一个网页上的图片地址实例代码
本文实例主要是实现爬取一个网页上的图片地址,具体如下. 读取一个网页的源代码: import urllib.request def getHtml(url): html=urllib.request.urlopen(url).read() return html print(getHtml(http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%E5%A3%81%E7%BA%B8&ct=201326592&am
-
Python爬虫爬取Bilibili弹幕过程解析
先来思考一个问题,B站一个视频的弹幕最多会有多少? 比较多的会有2000条吧,这么多数据,B站肯定是不会直接把弹幕和这个视频绑在一起的. 也就是说,有一个视频地址为https://www.bilibili.com/video/av67946325,你如果直接去requests.get这个地址,里面是不会有弹幕的,回想第一篇说到的携程异步加载数据的方式,B站的弹幕也一定是先加载当前视频的界面,然后再异步填充弹幕的. 接下来我们就可以打开火狐浏览器(平常可以火狐谷歌控制台都使用,因为谷歌里面因为插件
-
python爬虫爬取某站上海租房图片
对于一个net开发这爬虫真真的以前没有写过.这段时间开始学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与BeautifulSoup.python 版本:python3.6 ,IDE :pycharm.其实就几行代码,但希望没有开发基础的人也能一下子看明白,所以大神请绕行. 第三方库首先安装 我是用的pycharm所以另为的脚本安装我这就不介绍了. 如上图打开默认设置选择Project Interprecter,双击pip或者点击加
-
python爬虫爬取淘宝商品信息(selenum+phontomjs)
本文实例为大家分享了python爬虫爬取淘宝商品的具体代码,供大家参考,具体内容如下 1.需求目标 : 进去淘宝页面,搜索耐克关键词,抓取 商品的标题,链接,价格,城市,旺旺号,付款人数,进去第二层,抓取商品的销售量,款号等. 2.结果展示 3.源代码 # encoding: utf-8 import sys reload(sys) sys.setdefaultencoding('utf-8') import time import pandas as pd time1=time.time()
-
python爬虫爬取网页表格数据
用python爬取网页表格数据,供大家参考,具体内容如下 from bs4 import BeautifulSoup import requests import csv import bs4 #检查url地址 def check_link(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: print('无法链接服务器!!!')
-
Python使用爬虫爬取静态网页图片的方法详解
本文实例讲述了Python使用爬虫爬取静态网页图片的方法.分享给大家供大家参考,具体如下: 爬虫理论基础 其实爬虫没有大家想象的那么复杂,有时候也就是几行代码的事儿,千万不要把自己吓倒了.这篇就清晰地讲解一下利用Python爬虫的理论基础. 首先说明爬虫分为三个步骤,也就需要用到三个工具. ① 利用网页下载器将网页的源码等资源下载. ② 利用URL管理器管理下载下来的URL ③ 利用网页解析器解析需要的URL,进而进行匹配. 网页下载器 网页下载器常用的有两个.一个是Python自带的urlli
-
python爬虫爬取网页数据并解析数据
1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序. 只要浏览器能够做的事情,原则上,爬虫都能够做到. 2.网络爬虫的功能 网络爬虫可以代替手工做很多事情,比如可以用于做搜索引擎,也可以爬取网站上面的图片,比如有些朋友将某些网站上的图片全部爬取下来,集中进行浏览,同时,网络爬虫也可以用于金融投资领域,比如可以自动爬取一些金融信息,并进行投资分析等. 有时,我们比较喜欢的新闻网站可能有几个,每次都要分别
-
python爬虫爬取指定内容的解决方法
目录 解决办法: 实列代码如下:(以我们学校为例) 爬取一些网站下指定的内容,一般来说可以用xpath来直接从网页上来获取,但是当我们获取的内容不唯一的时候我们无法选择,我们所需要的.所指定的内容. 解决办法: 可以使用for In 语句来判断如果我们所指定的内容在这段语句中我们就把这段内容爬取下来,反之就丢弃 实列代码如下:(以我们学校为例) import urllib.request from lxml import etree def creat_url(page): if(page==1