Java手写Redis服务端的实现
目录
- 零,起因
- 一,redis通讯与Netty
- 1,tcp
- 2,协议
- 3,编解码
- 4,命令处理
- 二,redis 的数据结构
- 1,底层主结构
- 2,key
- 3,list
- 4,set
- 5,hash
- 6,zset
- 三,redis AOF 持久化
- 1,aof线程与tcp线程解耦,即写缓冲
- 2,aof持久化协议
- 3,aof的加载与存储实现
- 4,内存文件映射与面向对象
- 四,redis 的集群特性
- 1,主从
- 2,主从复制
- 3,分片集群
- 五,redis 的压测与调优
- 1,aof内存泄漏
- 2,内存复用提升性能
- 3,0.05%消息延迟超200ms排查
- 4,性能表现
零,起因
我为什么要造redis这个轮子?
1,破除对redis神秘感。
2,“基础服务中台”的同事们在开会讨论redis云,以及redis代理。
3,开一个redis资源并不是容易事,为什么不可以不可以写成java直接推送到未来云上,简单方便。
以这个思路我开始使用业余时间研究了redis的tcp通讯原理与redis命令,出发点是写一个redis云代理之类的云管理软件,但是还是忍不住写成了java版的redis,本文章主要分享redis的编写心路历程
一,redis通讯与Netty
1,tcp
连到Redis服务器的客户端建立了一个到6379端口的TCP连接。
虽然RESP在技术上不特定于TCP,但是在Redis的上下文中,该协议仅用于TCP连接(或类似的面向流的连接,如unix套接字)。
使用netty作为通讯框架。
2,协议
Redis客户端和服务器端通信使用名为 RESP (REdis Serialization Protocol) 的协议。虽然这个协议是专门为Redis设计的,它也可以用在其它 client-server 通信模式的软件上。 RESP 协议在Redis1.2被引入,直到Redis2.0才成为和Redis服务器通信的标准。这个协议需要在你的Redis客户端实现。
RESP 是一个支持多种数据类型的序列化协议:简单字符串(Simple Strings),错误( Errors),整型( Integers), 大容量字符串(Bulk Strings)和数组(Arrays)。
RESP在Redis中作为一个请求-响应协议以如下方式使用:
客户端以大容量字符串RESP数组的方式发送命令给服务器端。 服务器端根据命令的具体实现返回某一种RESP数据类型。 在 RESP 中,数据的类型依赖于首字节:
单行字符串(Simple Strings): 响应的首字节是 "+" 错误(Errors): 响应的首字节是 "-" 整型(Integers): 响应的首字节是 ":" 多行字符串(Bulk Strings): 响应的首字节是"$" 数组(Arrays): 响应的首字节是 "*" 另外,RESP可以使用大容量字符串或者数组类型的特殊变量表示空值,下面会具体解释。RESP协议的不同部分总是以 "\r\n" (CRLF) 结束。 字符串 "foobar" 编码如下:
"$6\r\nfoobar\r\n"
实际redis命令是什么样的,比如 SET lhjljh lhjkjhkh
*3\r\n$3\r\nSET\r\n$6\r\nlhjljh\r\n$8\r\nlhjkjhkh
3,编解码
由于RESP天然是面向处理命令的,所以没办法直接把redis消息像grpc或者dubbo那样直接序列化和反序列化消息。并且每个内容限定了长度,很适合做成及时序列化、零拷贝,直接针对输入流做反序列化和序列化,这一点与Protostuff序列化协议的设计很类似。 所以序列化直接将服务端接收的流直接转成值。

编解码的实体类直接加入redis server 的处理某一个长连接tcp客户端的管道上。
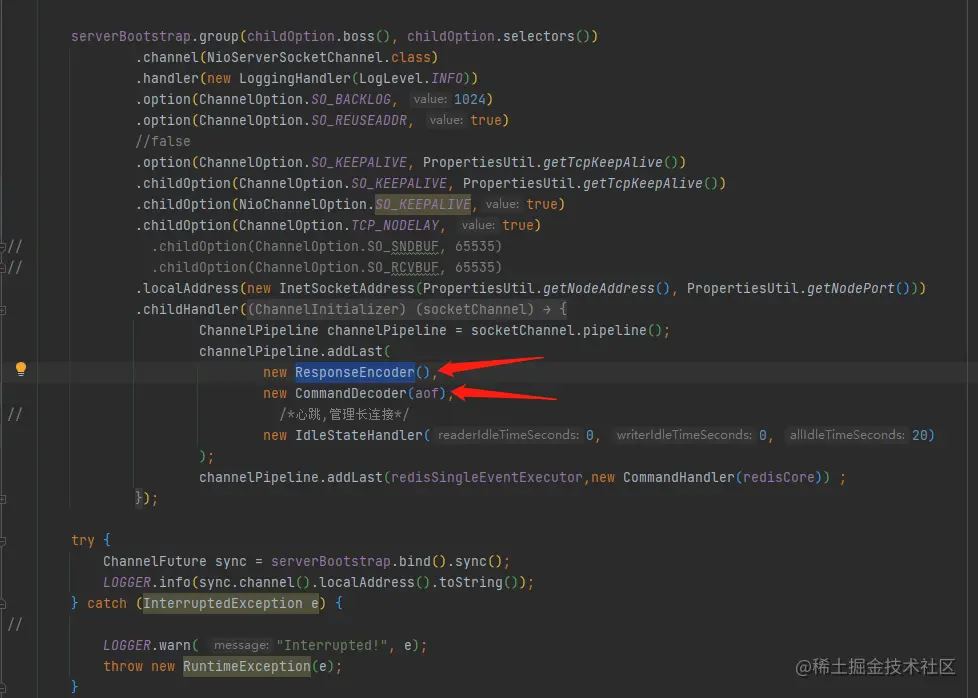
4,命令处理
将消息解码成RESP,还需要将RESP转为Command对象,这里因为是java语言,方法与类绑定,编写上和理解上会更加容易。但是会增加一些开销。

二,redis 的数据结构
1,底层主结构
底层主树使用跳表ConcurrentSkipListMap实现,没用hash类map的原因是服务端是集群后,客户端可能使用hash路由,会导致服务端严重的hash冲突,性能大打折扣

key为封装的“String”,重写了equals方法避免相同的key但是在jvm中指针不同
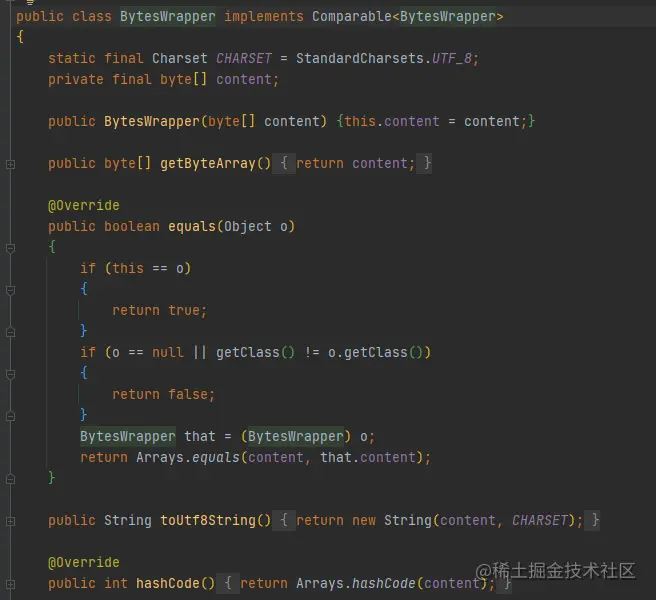
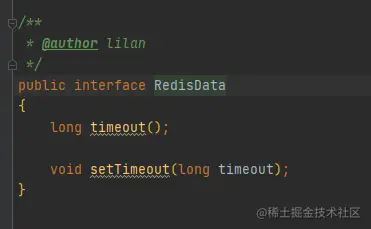
value是一个接口,实现类是redis的五大基本类型,所有数据类型都包含超时时间
2,key
用封装的值做value的原因是方便统一管理

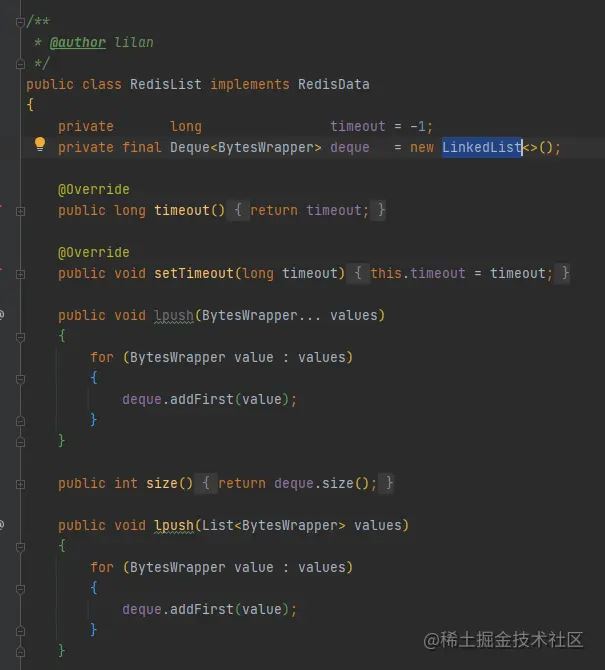
3,list
底层使用LinkedList的原因是LinkedList实现了多种接口,实现各种命令直接调用其现成实现的方法即可

4,set
底层使用HashSet,redis里的set没有多特殊

5,hash
底层使用HashMap,这里和开头说的HashMap不冲突。为什么不用跳表?压缩列表很巧妙,大抵的意思就是将通信收到的数组直接填充到list中,将list直接按照次序直接当map使用,主要是0拷贝的思想,无需创建新资源,性能极高,但注意压缩列表与压缩无关。

6,zset
首先需要封装一个带有值和分值的对象

再用TreeMap重写compare方法即可,使用TreeMap原因是他天然有良好的排序功能,很多hash一致路由的算法都用的TreeMap二开。

三,redis AOF 持久化
1,aof线程与tcp线程解耦,即写缓冲
再解析redis命令时,将redis写命令添加到写aof日志的队列中
这里自己封装了一个堵塞队列,单线程吞吐量可以达到3000W /s是LinkedBlockingQueue的6到10倍,完全可以胜任此场景


RingBlockingQueue吞吐量非常高的原因是使用了内存连续页的机制。

2,aof持久化协议
aof协议一句话概括就是将写命令,追加到日志中,开始时将命令读取,当作收到网络的命令执行即可。由于协议过于简单,这里就不贴链接了。 aof之日格式如下图:

3,aof的加载与存储实现
这里读写内存都是用的内存文件映射,好处是读写性能好,坏处是可能会出现内存泄漏,调试期间比较麻烦。
4,内存文件映射与面向对象
这里存储和加载aof文件的代码都是面向过程的,看起来非常复杂。实际上之前是按照面向对象写的,封装成了行对象,调用落盘符和拾起方法就可以写入和读取aof中的命令,但是TPS仅为10w/s,后来权衡后改为面向过程,吞吐量提升到了100W的TPS以上。
四,redis 的集群特性
1,主从
这里很容易联想到mysql的只从,很多场景下会使用基于mysql主从的读写分离,或者zk的主从。 但实际上redis的主从是不保证一致性的,个人认为redist的主从主要考虑的是cap的分布式容错性。 因为redis主从不保证一致性,所以使用redis读写分离,可能造成一些不一致的问题,写写是一致的,但是读是不一致的,可以根据项目需要做取舍。
2,主从复制
redis的主从复制这里作者没看懂(可能也是一致性上有坑没动力去看),所以没写出来。
3,分片集群
redis集群主要分为几个唯独: 主从、分区集群、代理。 一般在redis客户端的视角下,主要是分区集群,根据发送给redis的key做hash、md5等操作,取一个所有客户端的共识值,将key和value发送,也就是客户端路由分布式软件的集群实现方式京东的redis集群设计到redis具体一个分片。
五,redis 的压测与调优
1,aof内存泄漏
开启aof压测发现出现了内存泄漏,后来发现是频繁新建内存池而造成的,所以将内存池池化,即aof对象中仅存在一个bytebuff内存池。
2,内存复用提升性能
这里编解码没有单独开辟byte数据接收bytebuff的数据进行编解码,编解码直接读取bytebuff进行编解码,没有出现内存拷贝,唯独新建了BytesWrapper对象,但存储的数据都是使用BytesWrapper对象,对内存新建/销毁的开销很少。
3,0.05%消息延迟超200ms排查
下图为c语言版的redis压测数据:

下图为java语言版的redis压测数据:
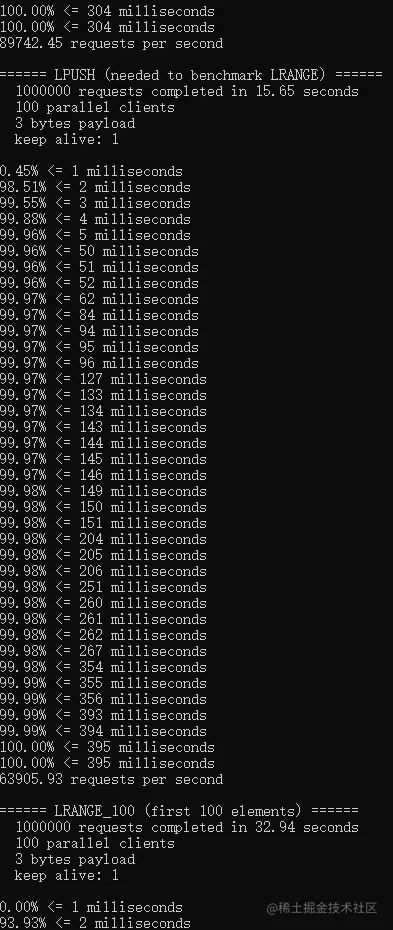
4,性能表现
redis原版的性能大概是E5系列CPU 4-5w左右,上图中是使用amd芯片测试的数据。 使用redis自带的压测工具,维持100个客户端连接,java版性能是c语言原版性能的75-90%左右,性能依然强悍。
到此这篇关于Java手写Redis服务端的实现的文章就介绍到这了,更多相关Java手写Redis服务端内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

java获取redis日志信息与动态监控信息的方法
效果展示如下所示: 实时监控 redis环境信息和日志列表 Redis配置 在windows下安装的redis,在安装目录找到redis.windows.conf文件,修改以下字段(按实际情况设置): slowlog-log-slower-than 100 slowlog-max-len 1000000 slowlog-log-slower-than:是配置需要日志记录的命令执行时间,单位是微秒,也就是说配置为100,会记录命令执行时间为0.1ms以上的记录.如果设置为0,就会记录所有执行过的命
-
Java操作Redis详细介绍
1. 简介 Redis 是一个开源(BSD许可)的,内存中的key-value存储系统,它可以用作数据库.缓存和消息中间件. 2. 对key的操作 首先要建立连接Jedis jedis = new Jedis("127.0.0.1", 6379),然后就可以对string,set,zset,hash进行操作了. //对key的测试 public void keyTest() { System.out.println(jedis.flushDB()); //清空数据 System.out
-
Java简单实现session保存到redis的方法示例
本文实例讲述了Java简单实现session保存到redis的方法.分享给大家供大家参考,具体如下: 在负载均衡情况下,如果用户访问不同的机器,如果没有做session同步,用户就会被提出,这样用户体验非常不好,所以我们很有必要做session同步,把session放到reids缓存服务器就能很好的解决问题.下面是代码简单的实现. 一.配置web.xml过滤器: <filter> <filter-name>sessionFilter</filter-name> <
-
java 连接Redis的小例子
需要相应API (jedis-2.1.0.jar) 复制代码 代码如下: package com.redis; import redis.clients.jedis.Jedis; public class Client { public void getCache(String key){ Jedis jedis = new Jedis("127.0.0.1",6379); for (int i = 0; i < 100000; i++){
-
Java自定义注解实现Redis自动缓存的方法
在实际开发中,可能经常会有这样的需要:从MySQL中查询一条数据(比如用户信息),此时需要将用户信息保存至Redis. 刚开始我们可能会在查询的业务逻辑之后再写一段Redis相关操作的代码,时间长了后发现这部分代码实际上仅仅做了Redis的写入动作,跟业务逻辑没有实质的联系,那么有没有什么方法能让我们省略这些重复劳动呢? 首先想到用AOP,在查询到某些数据这一切入点(Pointcut)完成我们的切面相关处理(也就是写入Redis).那么,如何知道什么地方需要进行缓存呢,也就是什么地方需要用到AO
-
java操作Redis缓存设置过期时间的方法
关于Redis的概念和应用本文就不再详解了,说一下怎么在java应用中设置过期时间. 在应用中我们会需要使用redis设置过期时间,比如单点登录中我们需要随机生成一个token作为key,将用户的信息转为json串作为value保存在redis中,通常做法是: //生成token String token = UUID.randomUUID().toString(); //把用户信息写入redis jedisClient.set(REDIS_USER_SESSION_KEY + ":"
-
Java利用Redis实现消息队列的示例代码
本文介绍了Java利用Redis实现消息队列的示例代码,分享给大家,具体如下: 应用场景 为什么要用redis? 二进制存储.java序列化传输.IO连接数高.连接频繁 一.序列化 这里编写了一个java序列化的工具,主要是将对象转化为byte数组,和根据byte数组反序列化成java对象; 主要是用到了ByteArrayOutputStream和ByteArrayInputStream; 注意:每个需要序列化的对象都要实现Serializable接口; 其代码如下: package Utils
-
redis中使用java脚本实现分布式锁
redis被大量用在分布式的环境中,自然而然分布式环境下的锁如何解决,立马成为一个问题.例如我们当前的手游项目,服务器端是按业务模块划分服务器的,有应用服,战斗服等,但是这两个vm都有可能同时改变玩家的属性,这如果在同一个vm下面,就很容易加锁,但如果在分布式环境下就没那么容易了,当然利用redis现有的功能也有解决办法,比如redis的脚本. redis在2.6以后的版本中增加了Lua脚本的功能,可以通过eval命令,直接在RedisServer环境中执行Lua脚本,并且可以在Lua脚本中调用
-
Java中使用Jedis操作Redis的示例代码
使用Java操作Redis需要jedis-2.1.0.jar,下载地址:jedis-2.1.0.jar 如果需要使用Redis连接池的话,还需commons-pool-1.5.4.jar,下载地址:commons-pool-1.5.4.jar package com.test; import java.util.HashMap; import java.util.Iterator; import java.util.List; import java.util.Map; import org.j
-
Java手写Redis服务端的实现
目录 零,起因 一,redis通讯与Netty 1,tcp 2,协议 3,编解码 4,命令处理 二,redis 的数据结构 1,底层主结构 2,key 3,list 4,set 5,hash 6,zset 三,redis AOF 持久化 1,aof线程与tcp线程解耦,即写缓冲 2,aof持久化协议 3,aof的加载与存储实现 4,内存文件映射与面向对象 四,redis 的集群特性 1,主从 2,主从复制 3,分片集群 五,redis 的压测与调优 1,aof内存泄漏 2,内存复用提升性能 3,
-
手写redis@Cacheable注解 参数java对象作为key值详解
目录 1.实现方式说明 1.1问题说明 1.2实现步骤 2.源代码 3.测试 1.实现方式说明 本文在---- 手写redis @ Cacheable注解支持过期时间设置 的基础之上进行扩展. 1.1问题说明 @ Cacheable(key = “'leader'+#p0 +#p1 +#p2” )一般用法,#p0表示方法的第一个参数,#p1表示第二个参数,以此类推. 目前方法的第一个参数为Java的对象,但是原注解只支持Java的的基本数据类型. 1.2实现步骤 1.在原注解中加入新的参数,
-
手写redis@Cacheable注解 支持过期时间设置方式
目录 原理解释 实现方法 源代码 原理解释 友情链接 手写redis @ Cacheable注解参数java对象作为键值 @Cacheable注解作用,将带有该注解方法的返回值存放到redis的的中; 使用方法在方法上使用@Cacheable(键=“测试+#P0 + P1#...”) 表示键值为测试+方法第一个参数+方法第二个参数,值为该方法的返回值. 以下源代码表示获取人员列表,Redis的中存放的关键值为'领袖'+ leaderGroupId + UUID + yearDetailId @
-
利用Java手写阻塞队列的示例代码
目录 前言 需求分析 阻塞队列实现原理 线程阻塞和唤醒 数组循环使用 代码实现 成员变量定义 构造函数 put函数 offer函数 add函数 take函数 重写toString函数 完整代码 总结 前言 在我们平时编程的时候一个很重要的工具就是容器,在本篇文章当中主要给大家介绍阻塞队列的原理,并且在了解原理之后自己动手实现一个低配版的阻塞队列. 需求分析 在前面的两篇文章ArrayDeque(JDK双端队列)源码深度剖析和深入剖析(JDK)ArrayQueue源码当中我们仔细介绍了队列的原理,
-
Java实现断点下载服务端与客户端的示例代码
目录 原理 扩展-大文件快速下载思路 代码 服务端 客户端 最近在研究断点下载(下载续传)的功能,此功能需要服务端和客户端进行对接编写,本篇也是记录一下关于贴上关于实现服务端(Spring Boot)与客户端(Android)是如何实现下载续传功能 断点下载功能(下载续传)解释: 客户端由于突然性网络中断等原因,导致的下载失败,这个时候重新下载,可以继续从上次的地方进行下载,而不是重新下载 原理 首先,我们先说明了断点续传的功能,实际上的原理比较简单 客户端和服务端规定好一个规则,客户端传递一个
-
Java利用TCP实现服务端向客户端消息群发的示例代码
目录 前言 代码 tcp服务端代码 ServerThread 线程类 TcpTool 消息群发工具类 Tcp客户端代码 前言 项目需要和第三方厂商的服务需要用TCP协议通讯,考虑到彼此双方可能都会有断网重连.宕机重启的情况,需要保证 发生上述情况后,服务之间能够自动实现重新通信.研究测试之后整理如下代码实现.因为发现客户端重启后,对于服务端来说原来的客户端和服务端进程进程已经关闭,启动又和服务端新开了一个进程.所以实现原理就可以通过服务端向客户端群发实现,断开重新连接通讯. 代码 tcp服务端代
-
基于Java手写一个好用的FTP操作工具类
目录 前言 windows服务器搭建FTP服务 工具类方法 代码展示 使用示例 前言 网上百度了很多FTP的java 工具类,发现文章代码都比较久远,且代码臃肿,即使搜到了代码写的还可以的,封装的常用操作方法不全面,于是自己花了半天实现一个好用的工具类.最初想用java自带的FTPClient 的jar 去封装,后来和apache的jar工具包对比后,发现易用性远不如apache,于是决定采用apache的ftp的jar 封装ftp操作类. windows服务器搭建FTP服务 打开控制版面,图示
-
Java手写线程池的实现方法
本文实例为大家分享了Java手写线程池的实现代码,供大家参考,具体内容如下 1.线程池是一种多线程处理形式,处理过程中将任务添加到队列,然后在创建线程后自动启动这些任务.线程池线程都是后台线程. 2.线程池简易架构 3.简易线程池代码(自行优化) import java.util.List; /** * 线程接口 * * @Author yjian * @Date 14:49 2017/10/14 **/ public interface IThreadPool { //加入任务 void ex
-
Java 手写LRU缓存淘汰算法
概述 LRU 算法全称为 Least Recently Used 是一种常见的页面缓存淘汰算法,当缓存空间达到达到预设空间的情况下会删除那些最久没有被使用的数据 . 常见的页面缓存淘汰算法主要有一下几种: LRU 最近最久未使用 FIFO 先进先出置换算法 类似队列 OPT 最佳置换算法 (理想中存在的) NRU Clock 置换算法 LFU 最少使用置换算法 PBA 页面缓冲算法 LRU 的原理 LRU 算法的设计原理其实就是计算机的 局部性原理(这个 局部性原理 包含了 空间局部性 和 时间
-
Java手写图书管理基本功能附代码
目录 1.book包 2.user包 3.operate包 Java中的最主要的语法之前基本都介绍完毕,本篇将使用之前的内容来写一个简单的图书管理系统,中间会展示部分代码来讲解,源码地址在这项目: 个人练习的项目 - Gitee.com 首先还是来看看运行的效果 我们来分析一下: Java中是通过对象之间的交互来解决事情的,所以我们来看看有哪些对象 首先显而易见的两个对象:用户和书,所以创建两个包book和user 通过上图可以看到:不同用户之间有相同的操作,也有不同的操作,所以不妨将所有的操作