Pytorch BCELoss和BCEWithLogitsLoss的使用
BCELoss
在图片多标签分类时,如果3张图片分3类,会输出一个3*3的矩阵。

先用Sigmoid给这些值都搞到0~1之间:

假设Target是:


下面我们用BCELoss来验证一下Loss是不是0.7194!

emmm应该是我上面每次都保留4位小数,算到最后误差越来越大差了0.0001。不过也很厉害啦哈哈哈哈哈!
BCEWithLogitsLoss
BCEWithLogitsLoss就是把Sigmoid-BCELoss合成一步。我们直接用刚刚的input验证一下是不是0.7193:

嘻嘻,我可真是太厉害啦!
补充:Pytorch中BCELoss,BCEWithLogitsLoss和CrossEntropyLoss的区别
BCEWithLogitsLoss = Sigmoid+BCELoss
当网络最后一层使用nn.Sigmoid时,就用BCELoss,当网络最后一层不使用nn.Sigmoid时,就用BCEWithLogitsLoss。
(BCELoss)BCEWithLogitsLoss
用于单标签二分类或者多标签二分类,输出和目标的维度是(batch,C),batch是样本数量,C是类别数量,对于每一个batch的C个值,对每个值求sigmoid到0-1之间,所以每个batch的C个值之间是没有关系的,相互独立的,所以之和不一定为1。
每个C值代表属于一类标签的概率。如果是单标签二分类,那输出和目标的维度是(batch,1)即可。
CrossEntropyLoss用于多类别分类
输出和目标的维度是(batch,C),batch是样本数量,C是类别数量,每一个C之间是互斥的,相互关联的,对于每一个batch的C个值,一起求每个C的softmax,所以每个batch的所有C个值之和是1,哪个值大,代表其属于哪一类。如果用于二分类,那输出和目标的维度是(batch,2)。
补充:Pytorch踩坑记之交叉熵(nn.CrossEntropy,nn.NLLLoss,nn.BCELoss的区别和使用)
在Pytorch中的交叉熵函数的血泪史要从nn.CrossEntropyLoss()这个损失函数开始讲起。
从表面意义上看,这个函数好像是普通的交叉熵函数,但是如果你看过一些Pytorch的资料,会告诉你这个函数其实是softmax()和交叉熵的结合体。
然而如果去官方看这个函数的定义你会发现是这样子的:

哇,竟然是nn.LogSoftmax()和nn.NLLLoss()的结合体,这俩都是什么玩意儿啊。再看看你会发现甚至还有一个损失叫nn.Softmax()以及一个叫nn.nn.BCELoss()。我们来探究下这几个损失到底有何种关系。
nn.Softmax和nn.LogSoftmax
首先nn.Softmax()官网的定义是这样的:

嗯...就是我们认识的那个softmax。那nn.LogSoftmax()的定义也很直观了:
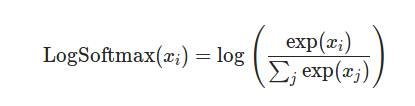
果不其然就是Softmax取了个log。可以写个代码测试一下:
import torch import torch.nn as nn a = torch.Tensor([1,2,3]) #定义Softmax softmax = nn.Softmax() sm_a = softmax=nn.Softmax() print(sm) #输出:tensor([0.0900, 0.2447, 0.6652]) #定义LogSoftmax logsoftmax = nn.LogSoftmax() lsm_a = logsoftmax(a) print(lsm_a) #输出tensor([-2.4076, -1.4076, -0.4076]),其中ln(0.0900)=-2.4076
nn.NLLLoss
上面说过nn.CrossEntropy()是nn.LogSoftmax()和nn.NLLLoss的结合,nn.NLLLoss官网给的定义是这样的:
The negative log likelihood loss. It is useful to train a classification problem with C classes

负对数似然损失 ,看起来好像有点晦涩难懂,写个代码测试一下:
import torch import torch.nn a = torch.Tensor([[1,2,3]]) nll = nn.NLLLoss() target1 = torch.Tensor([0]).long() target2 = torch.Tensor([1]).long() target3 = torch.Tensor([2]).long() #测试 n1 = nll(a,target1) #输出:tensor(-1.) n2 = nll(a,target2) #输出:tensor(-2.) n3 = nll(a,target3) #输出:tensor(-3.)
看起来nn.NLLLoss做的事情是取出a中对应target位置的值并取负号,比如target1=0,就取a中index=0位置上的值再取负号为-1,那这样做有什么意义呢,要结合nn.CrossEntropy往下看。
nn.CrossEntropy
看下官网给的nn.CrossEntropy()的表达式:

看起来应该是softmax之后取了个对数,写个简单代码测试一下:
import torch import torch.nn as nn a = torch.Tensor([[1,2,3]]) target = torch.Tensor([2]).long() logsoftmax = nn.LogSoftmax() ce = nn.CrossEntropyLoss() nll = nn.NLLLoss() #测试CrossEntropyLoss cel = ce(a,target) print(cel) #输出:tensor(0.4076) #测试LogSoftmax+NLLLoss lsm_a = logsoftmax(a) nll_lsm_a = nll(lsm_a,target) #输出tensor(0.4076)
看来直接用nn.CrossEntropy和nn.LogSoftmax+nn.NLLLoss是一样的结果。为什么这样呢,回想下交叉熵的表达式:
其中y是label,x是prediction的结果,所以其实交叉熵损失就是负的target对应位置的输出结果x再取-log。这个计算过程刚好就是先LogSoftmax()再NLLLoss()。
------------------------------------
所以我认为nn.CrossEntropyLoss其实应该叫做softmaxloss更为合理一些,这样就不会误解了。
nn.BCELoss
你以为这就完了吗,其实并没有。还有一类损失叫做BCELoss,写全了的话就是Binary Cross Entropy Loss,就是交叉熵应用于二分类时候的特殊形式,一般都和sigmoid一起用,表达式就是二分类交叉熵:

直觉上和多酚类交叉熵的区别在于,不仅考虑了的样本,也考虑了
的样本的损失。
总结
nn.LogSoftmax是在softmax的基础上取自然对数nn.NLLLoss是负的似然对数损失,但Pytorch的实现就是把对应target上的数取出来再加个负号,要在CrossEntropy中结合LogSoftmax来用BCELoss是二分类的交叉熵损失,Pytorch实现中和多分类有区别
Pytorch是个深坑,让我们一起扎根使用手册,结合实践踏平这些坑吧暴风哭泣。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

基于BCEWithLogitsLoss样本不均衡的处理方案
最近在做deepfake检测任务(可以将其视为二分类问题,label为1和0),遇到了正负样本不均衡的问题,正样本数目是负样本的5倍,这样会导致FP率较高. 尝试将正样本的loss权重增高,看BCEWithLogitsLoss的源码 Examples:: >>> target = torch.ones([10, 64], dtype=torch.float32) # 64 classes, batch size = 10 >>> output = torch.full(
-
Pytorch BCELoss和BCEWithLogitsLoss的使用
BCELoss 在图片多标签分类时,如果3张图片分3类,会输出一个3*3的矩阵. 先用Sigmoid给这些值都搞到0~1之间: 假设Target是: 下面我们用BCELoss来验证一下Loss是不是0.7194! emmm应该是我上面每次都保留4位小数,算到最后误差越来越大差了0.0001.不过也很厉害啦哈哈哈哈哈! BCEWithLogitsLoss BCEWithLogitsLoss就是把Sigmoid-BCELoss合成一步.我们直接用刚刚的input验证一下是不是0.7193: 嘻嘻,我
-
Pytorch 的损失函数Loss function使用详解
1.损失函数 损失函数,又叫目标函数,是编译一个神经网络模型必须的两个要素之一.另一个必不可少的要素是优化器. 损失函数是指用于计算标签值和预测值之间差异的函数,在机器学习过程中,有多种损失函数可供选择,典型的有距离向量,绝对值向量等. 损失Loss必须是标量,因为向量无法比较大小(向量本身需要通过范数等标量来比较). 损失函数一般分为4种,平方损失函数,对数损失函数,HingeLoss 0-1 损失函数,绝对值损失函数. 我们先定义两个二维数组,然后用不同的损失函数计算其损失值. import
-
Pytorch十九种损失函数的使用详解
损失函数通过torch.nn包实现, 1 基本用法 criterion = LossCriterion() #构造函数有自己的参数 loss = criterion(x, y) #调用标准时也有参数 2 损失函数 2-1 L1范数损失 L1Loss 计算 output 和 target 之差的绝对值. torch.nn.L1Loss(reduction='mean') 参数: reduction-三个值,none: 不使用约简:mean:返回loss和的平均值: sum:返回loss的和.默认:
-
pytorch中常用的损失函数用法说明
1. pytorch中常用的损失函数列举 pytorch中的nn模块提供了很多可以直接使用的loss函数, 比如MSELoss(), CrossEntropyLoss(), NLLLoss() 等 官方链接: https://pytorch.org/docs/stable/_modules/torch/nn/modules/loss.html pytorch中常用的损失函数 损失函数 名称 适用场景 torch.nn.MSELoss() 均方误差损失 回归 torch.nn.L1Loss() 平
-
PyTorch线性回归和逻辑回归实战示例
线性回归实战 使用PyTorch定义线性回归模型一般分以下几步: 1.设计网络架构 2.构建损失函数(loss)和优化器(optimizer) 3.训练(包括前馈(forward).反向传播(backward).更新模型参数(update)) #author:yuquanle #data:2018.2.5 #Study of LinearRegression use PyTorch import torch from torch.autograd import Variable # train
-
pytorch实现用CNN和LSTM对文本进行分类方式
model.py: #!/usr/bin/python # -*- coding: utf-8 -*- import torch from torch import nn import numpy as np from torch.autograd import Variable import torch.nn.functional as F class TextRNN(nn.Module): """文本分类,RNN模型""" def __ini
-
Pytorch使用MNIST数据集实现基础GAN和DCGAN详解
原始生成对抗网络Generative Adversarial Networks GAN包含生成器Generator和判别器Discriminator,数据有真实数据groundtruth,还有需要网络生成的"fake"数据,目的是网络生成的fake数据可以"骗过"判别器,让判别器认不出来,就是让判别器分不清进入的数据是真实数据还是fake数据.总的来说是:判别器区分真实数据和fake数据的能力越强越好:生成器生成的数据骗过判别器的能力越强越好,这个是矛盾的,所以只能
-
Pytorch使用MNIST数据集实现CGAN和生成指定的数字方式
CGAN的全拼是Conditional Generative Adversarial Networks,条件生成对抗网络,在初始GAN的基础上增加了图片的相应信息. 这里用传统的卷积方式实现CGAN. import torch from torch.utils.data import DataLoader from torchvision.datasets import MNIST from torchvision import transforms from torch import opti
-
pytorch GAN伪造手写体mnist数据集方式
一,mnist数据集 形如上图的数字手写体就是mnist数据集. 二,GAN原理(生成对抗网络) GAN网络一共由两部分组成:一个是伪造器(Generator,简称G),一个是判别器(Discrimniator,简称D) 一开始,G由服从某几个分布(如高斯分布)的噪音组成,生成的图片不断送给D判断是否正确,直到G生成的图片连D都判断以为是真的.D每一轮除了看过G生成的假图片以外,还要见数据集中的真图片,以前者和后者得到的损失函数值为依据更新D网络中的权值.因此G和D都在不停地更新权值.以下图为例