python数据分析近年比特币价格涨幅趋势分布
目录
- 使用技术点:
- 使用工具:
- 导入第三方库
大家好,我是辣条。
曾经有一个真挚的机会,摆在我面前,但是我没有珍惜,等到失去的时候才后悔莫及,尘世间最痛苦的事莫过于此,如果老天可以再给我一个再来一次机会的话,我会买下那个比特币,哪怕付出所有零花钱,如果非要在这个机会加上一个期限的话,我希望是十年前。
看着这份台词是不是很眼熟,我稍稍改了一下,曾经差一点点点就购买比特币了,肠子都悔青了现在,今天对比特币做一个简单的数据分析。
# 安装对应的第三方库 !pip install pandas !pip install numpy !pip install seaborn !pip install matplotlib !pip install sklearn !pip install tensorflow
使用技术点:
1. 数据处理 - pandas
2. 科学运算 - numpy
3. 数据可视化 - seaborn matplotlib
使用工具:
1. anaconda
2. notebook
3. python3.7版本
导入第三方库
#a|T + enter notebook运行方式
import pandas as pd # 数据处理
import numpy as np # 科学运算
import seaborn as sns # 数据可视化
import matplotlib.pyplot as plt # 数据可视化
import warnings
import warnings
warnings.filterwarnings('ignore')
如遇到导包报错 可以看看是不是自己的第三方库的版本问题
# 设置图表与 线格式
plt.rcParams['figure.figsize'] = (10, 10)
plt.rcParams['lines.linewidth'] = 2
plt.style.use('ggplot')
# 读取数据集
df = pd.read_csv('./DOGE-USD.csv')
df.head() # 查看前5行
| Date | Open | High | Low | Close | Adj Close | Volume | |
|---|---|---|---|---|---|---|---|
| 0 | 2014-09-17 | 0.000293 | 0.000299 | 0.000260 | 0.000268 | 0.000268 | 1463600.0 |
| 1 | 2014-09-18 | 0.000268 | 0.000325 | 0.000267 | 0.000298 | 0.000298 | 2215910.0 |
| 2 | 2014-09-19 | 0.000298 | 0.000307 | 0.000275 | 0.000277 | 0.000277 | 883563.0 |
| 3 | 2014-09-20 | 0.000276 | 0.000310 | 0.000267 | 0.000292 | 0.000292 | 993004.0 |
| 4 | 2014-09-21 | 0.000293 | 0.000299 | 0.000284 | 0.000288 | 0.000288 | 539140.0 |
df.isnull().sum() # 统计缺失值的总和(sum())
Date 0
Open 5
High 5
Low 5
Close 5
Adj Close 5
Volume 5
dtype: int64
df.duplicated().sum() # 查看重复值
0
# 数据类型 分布基本情况
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2591 entries, 0 to 2590
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Date 2591 non-null object
1 Open 2586 non-null float64
2 High 2586 non-null float64
3 Low 2586 non-null float64
4 Close 2586 non-null float64
5 Adj Close 2586 non-null float64
6 Volume 2586 non-null float64
dtypes: float64(6), object(1)
memory usage: 141.8+ KB
# 转换 Date的类型
df['Date'] = pd.to_datetime(df.Date, dayfirst=True)
# 索引重置 让Date时间格式成为 索引 inplace新建对象
df.set_index('Date', inplace=True)
df
| Open | High | Low | Close | Adj Close | Volume | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 2014-09-17 | 0.000293 | 0.000299 | 0.000260 | 0.000268 | 0.000268 | 1.463600e+06 |
| 2014-09-18 | 0.000268 | 0.000325 | 0.000267 | 0.000298 | 0.000298 | 2.215910e+06 |
| 2014-09-19 | 0.000298 | 0.000307 | 0.000275 | 0.000277 | 0.000277 | 8.835630e+05 |
| 2014-09-20 | 0.000276 | 0.000310 | 0.000267 | 0.000292 | 0.000292 | 9.930040e+05 |
| 2014-09-21 | 0.000293 | 0.000299 | 0.000284 | 0.000288 | 0.000288 | 5.391400e+05 |
| ... | ... | ... | ... | ... | ... | ... |
| 2021-10-16 | 0.233881 | 0.244447 | 0.233683 | 0.237292 | 0.237292 | 1.541851e+09 |
| 2021-10-17 | 0.237193 | 0.241973 | 0.226380 | 0.237898 | 0.237898 | 1.397143e+09 |
| 2021-10-18 | 0.237806 | 0.271394 | 0.237488 | 0.247281 | 0.247281 | 5.003366e+09 |
| 2021-10-19 | NaN | NaN | NaN | NaN | NaN | NaN |
| 2021-10-20 | 0.245199 | 0.246838 | 0.242384 | 0.246078 | 0.246078 | 1.187871e+09 |
2591 rows × 6 columns
df = df.asfreq('d') # 按照天数采集数据
df = df.fillna(method='bfill') # 缺失值填充 下一条数据填充
df
| Open | High | Low | Close | Adj Close | Volume | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 2014-09-17 | 0.000293 | 0.000299 | 0.000260 | 0.000268 | 0.000268 | 1.463600e+06 |
| 2014-09-18 | 0.000268 | 0.000325 | 0.000267 | 0.000298 | 0.000298 | 2.215910e+06 |
| 2014-09-19 | 0.000298 | 0.000307 | 0.000275 | 0.000277 | 0.000277 | 8.835630e+05 |
| 2014-09-20 | 0.000276 | 0.000310 | 0.000267 | 0.000292 | 0.000292 | 9.930040e+05 |
| 2014-09-21 | 0.000293 | 0.000299 | 0.000284 | 0.000288 | 0.000288 | 5.391400e+05 |
| ... | ... | ... | ... | ... | ... | ... |
| 2021-10-16 | 0.233881 | 0.244447 | 0.233683 | 0.237292 | 0.237292 | 1.541851e+09 |
| 2021-10-17 | 0.237193 | 0.241973 | 0.226380 | 0.237898 | 0.237898 | 1.397143e+09 |
| 2021-10-18 | 0.237806 | 0.271394 | 0.237488 | 0.247281 | 0.247281 | 5.003366e+09 |
| 2021-10-19 | 0.245199 | 0.246838 | 0.242384 | 0.246078 | 0.246078 | 1.187871e+09 |
| 2021-10-20 | 0.245199 | 0.246838 | 0.242384 | 0.246078 | 0.246078 | 1.187871e+09 |
2591 rows × 6 columns
In [14]:
# 开盘价的分布情况 df['Open'].plot(figsize=(12, 8))

结论:从上图可以看出 BTB是在2021年份开始爆发式的增长 在2015 到 2021 一直都是没有较大波动
# 成交情况 df['Volume'].plot(figsize=(12, 8))
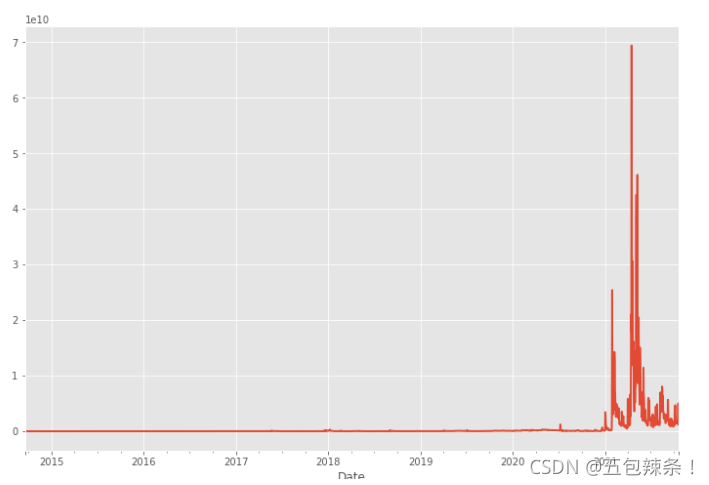
# 投资价值 df['Total Pos'] = df.sum(axis=1) df['Total Pos'].plot(figsize=(10, 8))
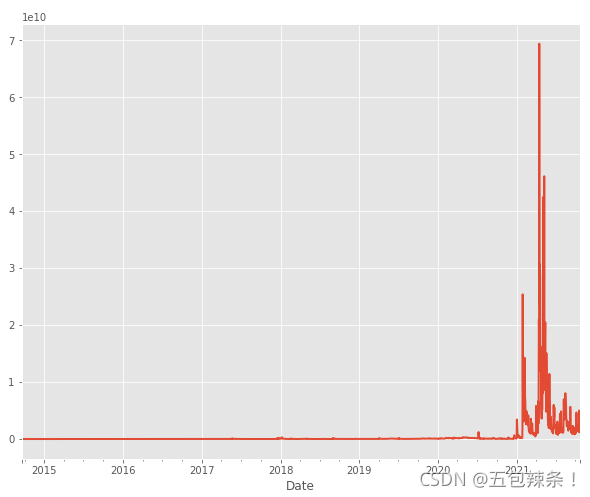
结论:开盘价高 投资价值搞 比较合适做卖出操作 实现一夜暴富(开玩笑的)
# 当前元素与先前元素的相差百分比 df['Daily Reture'] = df['Total Pos'].pct_change(1) # 日收益率的平均 df['Daily Reture'].mean() df['Daily Reture'].plot(kind='kde')
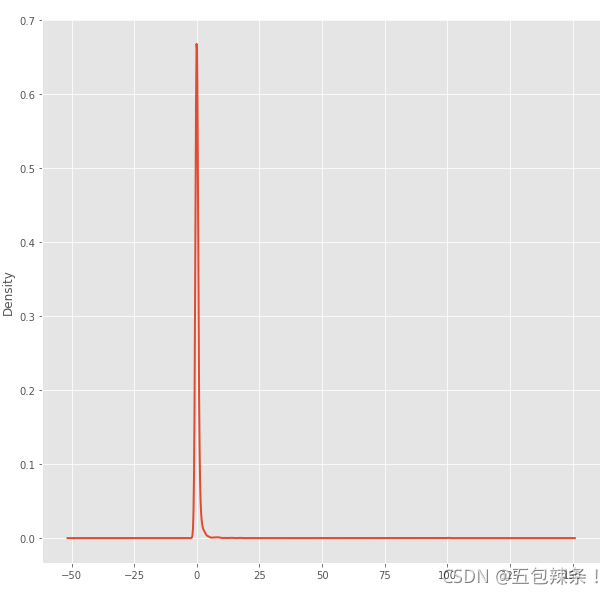
SR = df['Daily Reture'].mean() / df['Daily Reture'].std() all_plot = df/df.iloc[0] all_plot.plot(figsize=(24, 16))
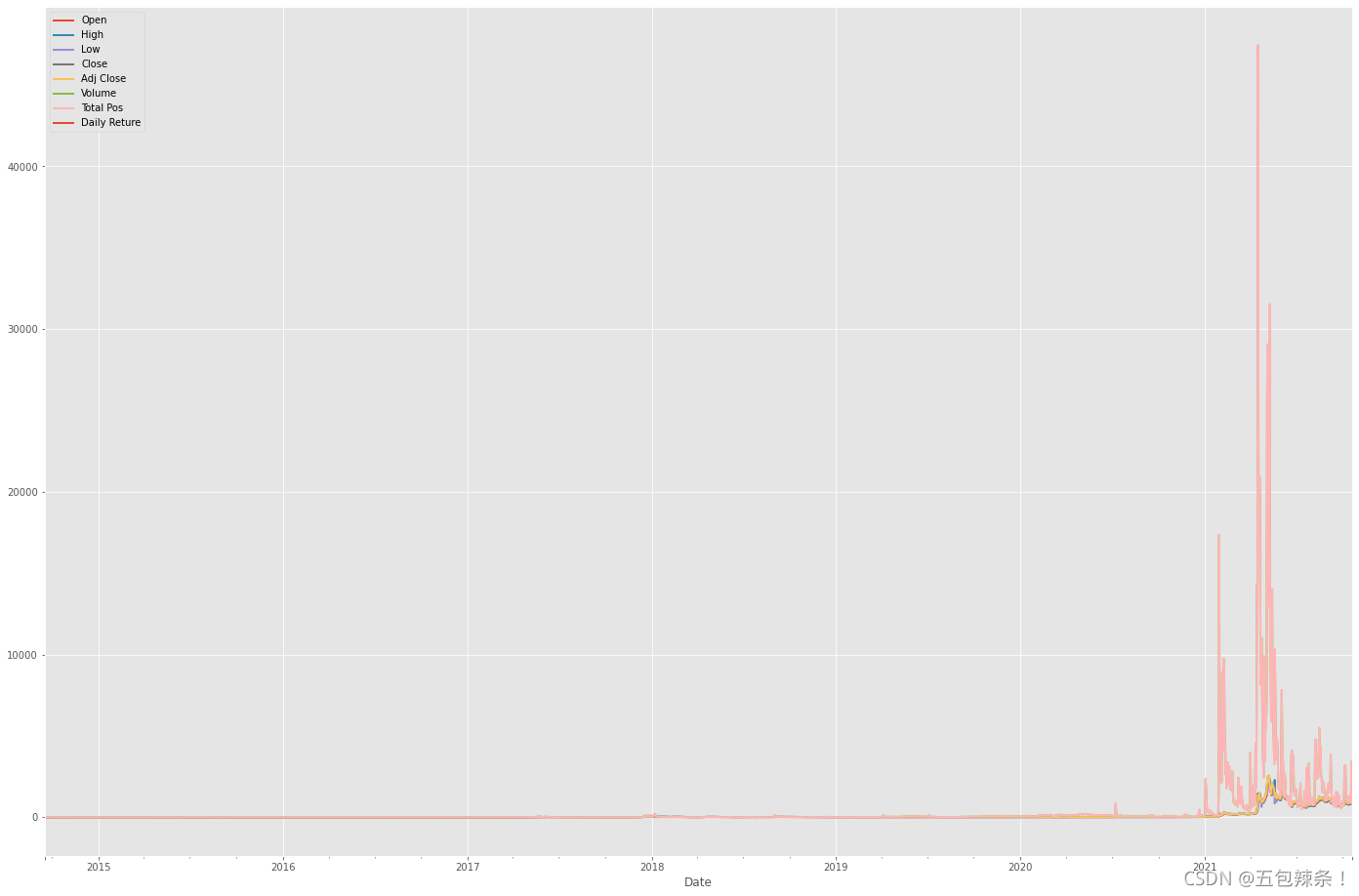
df.hist(bins=100, figsize=(12, 6))
# 按照年份进行采样 df.resample(rule='A').mean()
| Open | High | Low | Close | Adj Close | Volume | Total Pos | Daily Reture | |
|---|---|---|---|---|---|---|---|---|
| Date | ||||||||
| 2014-12-31 | 0.000249 | 0.000259 | 0.000240 | 0.000248 | 0.000248 | 8.059213e+05 | 8.059213e+05 | 1.028630 |
| 2015-12-31 | 0.000143 | 0.000147 | 0.000139 | 0.000143 | 0.000143 | 1.685476e+05 | 1.685476e+05 | 0.139461 |
| 2016-12-31 | 0.000235 | 0.000242 | 0.000229 | 0.000235 | 0.000235 | 2.564834e+05 | 2.564834e+05 | 0.259038 |
| 2017-12-31 | 0.001576 | 0.001708 | 0.001468 | 0.001601 | 0.001601 | 1.118996e+07 | 1.118996e+07 | 0.225833 |
| 2018-12-31 | 0.004368 | 0.004577 | 0.004125 | 0.004350 | 0.004350 | 2.172325e+07 | 2.172325e+07 | 0.109586 |
| 2019-12-31 | 0.002564 | 0.002631 | 0.002499 | 0.002563 | 0.002563 | 4.463969e+07 | 4.463969e+07 | 0.027981 |
| 2020-12-31 | 0.002736 | 0.002822 | 0.002660 | 0.002744 | 0.002744 | 1.290465e+08 | 1.290465e+08 | 0.052314 |
| 2021-12-31 | 0.200410 | 0.215775 | 0.185770 | 0.201272 | 0.201272 | 4.620961e+09 | 4.620961e+09 | 0.260782 |
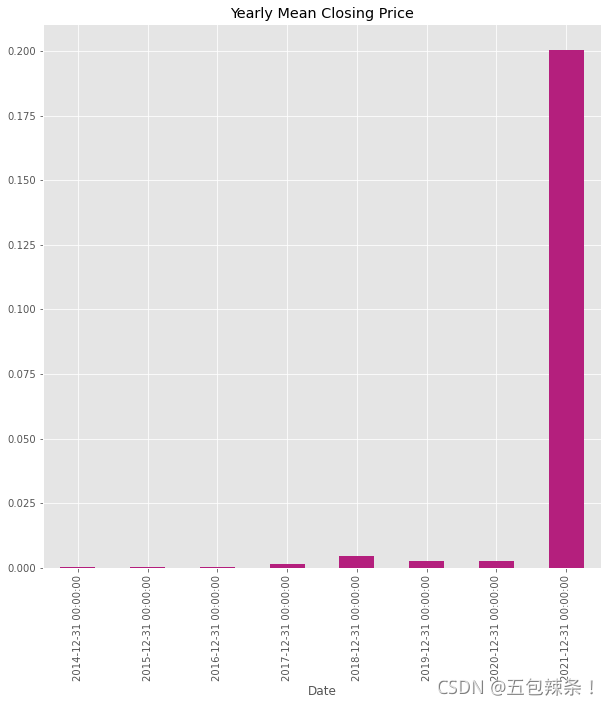
# 年平均收盘价
df['Open'].resample('A').mean().plot.bar(title='Yearly Mean Closing Price', color=['#b41f7d'])
# 月度
df['Open'].resample('M').mean().plot.bar(figsize=(18, 12), color='red')

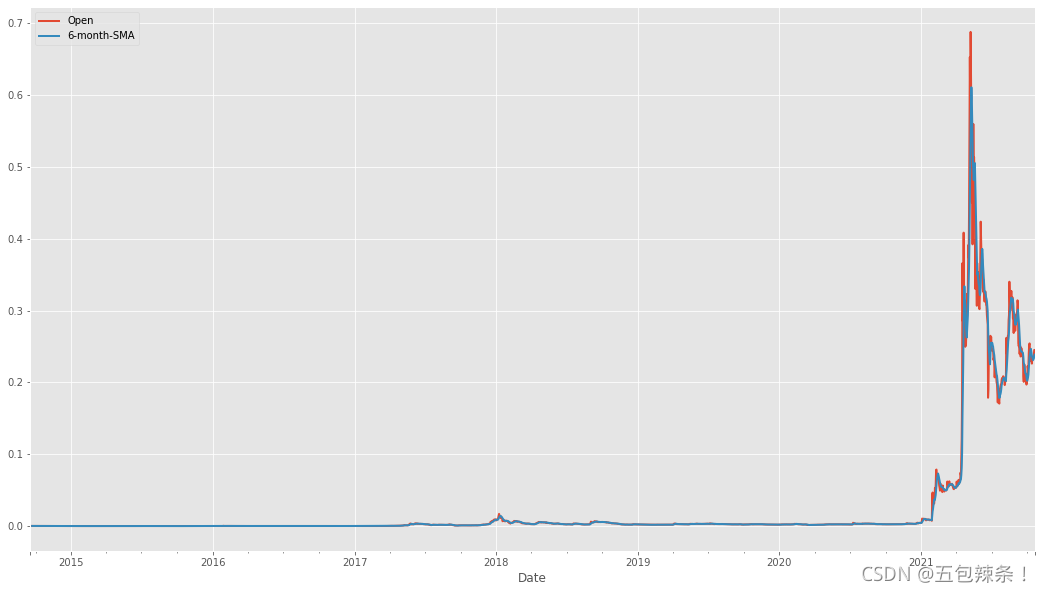
# 分别获取对应时间窗口 6 12 2 均值 df['6-month-SMA'] = df['Open'].rolling(window=6).mean() df['12-month-SMA'] = df['Open'].rolling(window=12).mean() df['2-month-SMA'] = df['Open'].rolling(window=2).mean() df.head(10)
| Open | High | Low | Close | Adj Close | Volume | Total Pos | Daily Reture | 6-month-SMA | 12-month-SMA | 2-month-SMA | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Date | |||||||||||
| 2014-09-17 | 0.000293 | 0.000299 | 0.000260 | 0.000268 | 0.000268 | 1463600.0 | 1.463600e+06 | NaN | NaN | NaN | NaN |
| 2014-09-18 | 0.000268 | 0.000325 | 0.000267 | 0.000298 | 0.000298 | 2215910.0 | 2.215910e+06 | 0.514013 | NaN | NaN | 0.000281 |
| 2014-09-19 | 0.000298 | 0.000307 | 0.000275 | 0.000277 | 0.000277 | 883563.0 | 8.835630e+05 | -0.601264 | NaN | NaN | 0.000283 |
| 2014-09-20 | 0.000276 | 0.000310 | 0.000267 | 0.000292 | 0.000292 | 993004.0 | 9.930040e+05 | 0.123863 | NaN | NaN | 0.000287 |
| 2014-09-21 | 0.000293 | 0.000299 | 0.000284 | 0.000288 | 0.000288 | 539140.0 | 5.391400e+05 | -0.457062 | NaN | NaN | 0.000285 |
| 2014-09-22 | 0.000288 | 0.000301 | 0.000285 | 0.000298 | 0.000298 | 620222.0 | 6.202220e+05 | 0.150391 | 0.000286 | NaN | 0.000291 |
| 2014-09-23 | 0.000298 | 0.000318 | 0.000295 | 0.000313 | 0.000313 | 739197.0 | 7.391970e+05 | 0.191826 | 0.000287 | NaN | 0.000293 |
| 2014-09-24 | 0.000314 | 0.000353 | 0.000310 | 0.000348 | 0.000348 | 1277840.0 | 1.277840e+06 | 0.728687 | 0.000295 | NaN | 0.000306 |
| 2014-09-25 | 0.000347 | 0.000383 | 0.000332 | 0.000375 | 0.000375 | 2393610.0 | 2.393610e+06 | 0.873169 | 0.000303 | NaN | 0.000331 |
| 2014-09-26 | 0.000374 | 0.000467 | 0.000373 | 0.000451 | 0.000451 | 4722610.0 | 4.722610e+06 | 0.973007 | 0.000319 | NaN | 0.000361 |
进行可视化 查看对应分布情况
df[['Open', '6-month-SMA', '12-month-SMA', '2-month-SMA']].plot(figsize=(24, 10))

df[["Open","6-month-SMA"]].plot(figsize=(18,10))
df[['Open','6-month-SMA']].iloc[:100].plot(figsize=(12,6)).autoscale(axis='x',tight=True)

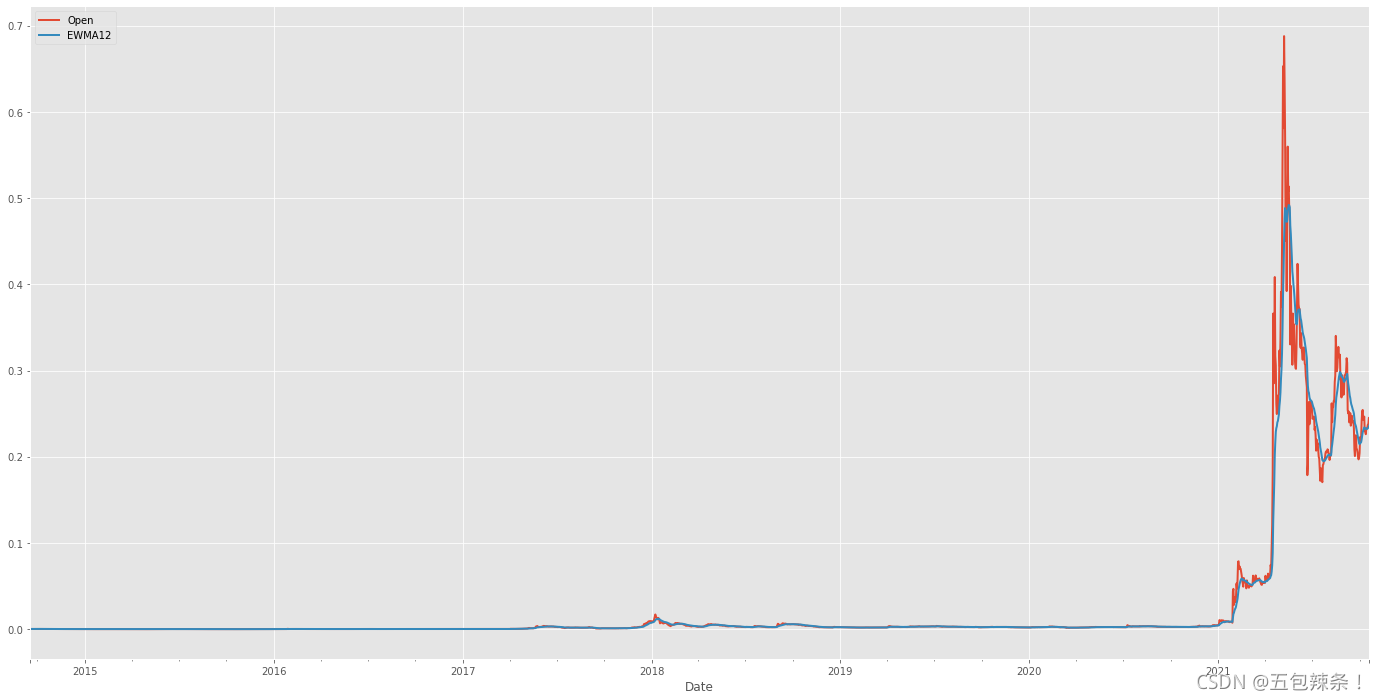
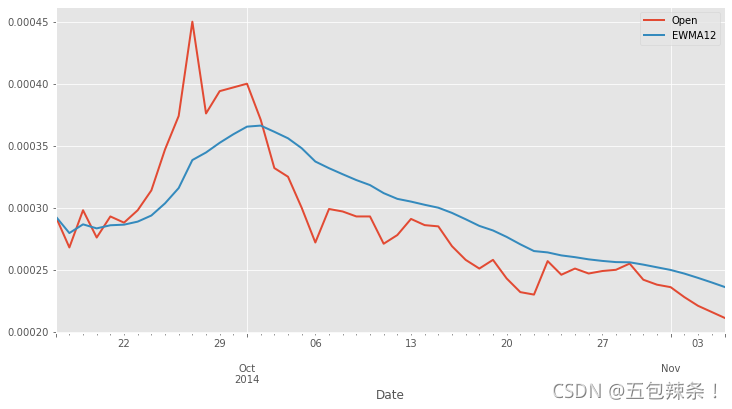
df['EWMA12'] = df['Open'].ewm(span=14,adjust=True).mean() df[['Open','EWMA12']].plot(figsize=(24,12))
df[['Open','EWMA12']].iloc[:50].plot(figsize=(12,6)).autoscale(axis='x',tight=True)
以上就是python数据分析近年比特币价格涨幅趋势分布的详细内容,更多关于python数据分析比特币价格涨幅的资料请关注我们其它相关文章!
相关推荐
-

python使用dabl几行代码实现数据处理分析及ML自动化
目录 dabl 1.数据预处理 2.探索性数据分析 3.建模 结论 数据科学模型开发涉及各种组件,包括数据收集.数据处理.探索性数据分析.建模和部署.在训练机器学习或深度学习模型之前,必须清洗数据集并使其适合训练.通常这些过程是重复的,且占用了大部时间. 为了克服这个问题,今天我分享一个名为 dabl 的开源 Python 工具包,它可以自动化机器学习模型开发,包括数据预处理.特征可视化和分析.建模.欢迎收藏学习,喜欢点赞支持. dabl dabl 是一个数据分析基线库,可以让机器学习建模更容易
-
python数据挖掘使用Evidently创建机器学习模型仪表板
目录 1.安装包 2.导入所需的库 3.加载数据集 4.创建模型 5.创建仪表板 6.可用报告类型 1)数据漂移 2)数值目标漂移 3)分类目标漂移 4)回归模型性能 5)分类模型性能 6)概率分类模型性能 解释机器学习模型是一个困难的过程,因为通常大多数模型都是一个黑匣子,我们不知道模型内部发生了什么.创建不同类型的可视化有助于理解模型是如何执行的,但是很少有库可以用来解释模型是如何工作的. Evidently 是一个开源 Python 库,用于创建交互式可视化报告.仪表板和 JSON 配置文
-
pyhton学习与数据挖掘self原理及应用分析
目录 1. 什么是class,什么是instance,什么是object? 2. 什么是method,什么是function? 3. 重点SELF分析 总结 对,你没看错,这是我初学 python 时的灵魂发问. 我们总会在class里面看见self,但是感觉他好像也没什么用处,就是放在那里占个位子. 如果你也有同样的疑问,那么恭喜你,你的class没学明白. 所以,在解释self是谁之前,我们先明确几个问题: 什么是class,什么是instance? 什么是object? 什么是method
-
推荐一款高效的python数据框处理工具Sidetable
目录 安装 用法 1.freq() 2.Counts 3.missing() 4.subtotal() 结论 我们知道 Pandas 是数据科学社区中流行的 Python 包,它包含许多函数和方法来分析数据.尽管它的功能对于数据分析来说足够有效,但定制的库可以为 Pandas 增加更多的价值. Sidetable 就是一个开源 Python 库,它是一种可用于数据分析和探索的工具,作为 value_counts 和 crosstab 的功能组合使用的.在本文中,我们将更多地讨论和探索其功能.欢迎
-
python优化数据预处理方法Pandas pipe详解
我们知道现实中的数据通常是杂乱无章的,需要大量的预处理才能使用.Pandas 是应用最广泛的数据分析和处理库之一,它提供了多种对原始数据进行预处理的方法. import numpy as np import pandas as pd df = pd.DataFrame({ "id": [100, 100, 101, 102, 103, 104, 105, 106], "A": [1, 2, 3, 4, 5, 2, np.nan, 5], "B":
-
python学习与数据挖掘应知应会的十大终端命令
目录 1.wget 2.head 3.tail 4.wc 5.grep 6.cat 7.find 8.sort 9.nano 10.Variables IT界的每个人都应该知道终端(Terminal)的基本知识,数据科学家也不例外.有时,终端是你的全部,尤其是在将模型和数据管道部署到远程机器时. 让我们开始吧! 1.wget wget实用程序用于从远程服务器下载文件.你可以用它来下载数据集,只要你知道网址,可以使用wget命令下载它,我以如下url为例: https://raw.githubus
-
python数据分析近年比特币价格涨幅趋势分布
目录 使用技术点: 使用工具: 导入第三方库 大家好,我是辣条. 曾经有一个真挚的机会,摆在我面前,但是我没有珍惜,等到失去的时候才后悔莫及,尘世间最痛苦的事莫过于此,如果老天可以再给我一个再来一次机会的话,我会买下那个比特币,哪怕付出所有零花钱,如果非要在这个机会加上一个期限的话,我希望是十年前. 看着这份台词是不是很眼熟,我稍稍改了一下,曾经差一点点点就购买比特币了,肠子都悔青了现在,今天对比特币做一个简单的数据分析. # 安装对应的第三方库 !pip install pandas !pip
-
python数据分析之聚类分析(cluster analysis)
何为聚类分析 聚类分析或聚类是对一组对象进行分组的任务,使得同一组(称为聚类)中的对象(在某种意义上)与其他组(聚类)中的对象更相似(在某种意义上).它是探索性数据挖掘的主要任务,也是统计 数据分析的常用技术,用于许多领域,包括机器学习,模式识别,图像分析,信息检索,生物信息学,数据压缩和计算机图形学. 聚类分析本身不是一个特定的算法,而是要解决的一般任务.它可以通过各种算法来实现,这些算法在理解群集的构成以及如何有效地找到它们方面存在显着差异.流行的群集概念包括群集成员之间距离较小的群体,数据
-
Python数据分析之分析千万级淘宝数据
目录 1.项目背景与分析说明 2.导入相关库 4.模型构建 1)流量指标的处理 2)用户行为指标 3)漏斗分析 4)客户价值分析(RFM分析) 1.项目背景与分析说明 1)项目背景 网购已经成为人们生活不可或缺的一部分,本次项目基于淘宝app平台数据,通过相关指标对用户行为进行分析,从而探索用户相关行为模式. 2)数据和字段说明 本文使用的数据集包含了2014.11.18到2014.12.18之间,淘宝App移动端一个月内的用户行为数据.该数据有12256906天记录,共6列数据. user_i
-
Python数据分析应用之Matplotlib数据可视化详情
目录 简述 掌握绘图基础语法与基本参数 掌握pyplot基础语法 pyplot中的基础绘图语法 包含子图的基础语法 调节线条的rc参数 调节字体的rc参数 分析特征间的关系 绘制散点图 绘制2000-2017年个季度过敏生产总值散点图 绘制2000-2017年各季度国民生产总值散点图 绘制折线图 绘制2000-2017年各季度过敏生产总值折线图 2000~ 2017年各季度国民生产总值点线图 2000~ 2017年各季度国民生产总值折线散点图 任务实现 任务1 任务2 分析特征内部数据分布与分散
-
Python数据分析之Matplotlib数据可视化
目录 1.前言 2.Matplotlib概念 3.Matplotlib.pyplot基本使用 3.数据展示 3.1如何选择展示方式 3.2绘制折线图 3.3绘制柱状图 3.3.1普通柱状图 3.3.2堆叠柱状图 3.3.3分组柱状图 3.3.4饼图 4.绘制子图 1.前言 数据展示,即数据可视化,是数据分析的第五个步骤,大部分人对图形敏感度高于数字,好的数据展示方式能让人快速发现问题或规律,找到数据背后隐藏的价值. 2.Matplotlib概念 Matplotlib 是 Python 中常用的
-
python数据分析之时间序列分析详情
目录 前言 时间序列的相关检验 白噪声检验 平稳性检验 自相关和偏相关分析 移动平均算法 简单移动平均法 简单指数平滑法 霍尔特(Holt)线性趋势法 Holt-Winters季节性预测模型 ARIMA模型 ARMA模型 针对ARMA模型自动选择合适的参数 时序数据的异常值检测 前言 时间序列分析是基于随机过程理论和数理统计学方法: 每日的平均气温 每天的销售额 每月的降水量 时间序列分析主要通过statsmodel库的tsa模块完成: 根据时间序列的散点图,自相关函数和偏自相关函数图识别序列是
-
Python数据分析之双色球统计单个红和蓝球哪个比例高的方法
本文实例讲述了Python数据分析之双色球统计单个红和蓝球哪个比例高的方法.分享给大家供大家参考,具体如下: 统计单个红球和蓝球,哪个组合最多,显示前19组数据 #!/usr/bin/python # -*- coding:UTF-8 -*- import pandas as pd import numpy as np import matplotlib.pyplot as plt import operator df = pd.read_table('newdata.txt',header=N
-
Python数据分析:手把手教你用Pandas生成可视化图表的教程
大家都知道,Matplotlib 是众多 Python 可视化包的鼻祖,也是Python最常用的标准可视化库,其功能非常强大,同时也非常复杂,想要搞明白并非易事.但自从Python进入3.0时代以后,pandas的使用变得更加普及,它的身影经常见于市场分析.爬虫.金融分析以及科学计算中. 作为数据分析工具的集大成者,pandas作者曾说,pandas中的可视化功能比plt更加简便和功能强大.实际上,如果是对图表细节有极高要求,那么建议大家使用matplotlib通过底层图表模块进行编码.当然,我
-
基于Python数据分析之pandas统计分析
pandas模块为我们提供了非常多的描述性统计分析的指标函数,如总和.均值.最小值.最大值等,我们来具体看看这些函数: 1.随机生成三组数据 import numpy as np import pandas as pd np.random.seed(1234) d1 = pd.Series(2*np.random.normal(size = 100)+3) d2 = np.random.f(2,4,size = 100) d3 = np.random.randint(1,100,size = 1
-
python数据分析之用sklearn预测糖尿病
一.数据集描述 本数据集内含十个属性列 Pergnancies: 怀孕次数 Glucose:血糖浓度 BloodPressure:舒张压(毫米汞柱) SkinThickness:肱三头肌皮肤褶皱厚度(毫米) Insulin:两个小时血清胰岛素(μU/毫升) BMI:身体质量指数,体重除以身高的平方 Diabets Pedigree Function: 疾病血统指数 是否和遗传相关,Height:身高(厘米) Age:年龄 Outcome:0表示不患病,1表示患病. 任务:建立机器学习模型以准确预