C#数据结构之最小堆的实现方法
最小堆
基本思想:堆对应一棵完全二叉树,且所有非叶结点的值均不大于(或不小于)其子女的值,根结点(堆顶元素)的值是最小(或最大)的,每次都取堆顶的元素,将其放在序列最后面,然后将剩余的元素重新调整为最小(大)堆,依次类推,最终得到排序的序列。
堆排序分为大顶堆和小顶堆排序。大顶堆:堆对应一棵完全二叉树,且所有非叶结点的值均不小于其子女的值,根结点(堆顶元素)的值是最大的。而小顶堆正好相反,小顶堆:堆对应一棵完全二叉树,且所有非叶结点的值均不大于其子女的值,根结点(堆顶元素)的值是最小的。
举个例子:
(a)大顶堆序列:(96, 83,27,38,11,09)
(b)小顶堆序列:(12,36,24,85,47,30,53,91)
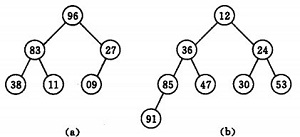
实现堆排序需解决两个问题:
1. 如何将n 个待排序的数建成堆?
2. 输出堆顶元素后,怎样调整剩余n-1 个元素,使其成为一个新堆?
首先讨论第二个问题:输出堆顶元素后,怎样对剩余n-1元素重新建成堆?
调整小顶堆的方法:
1)设有m 个元素的堆,输出堆顶元素后,剩下m-1 个元素。将堆底元素送入堆顶((最后一个元素与堆顶进行交换),堆被破坏,其原因仅是根结点不满足堆的性质。
2)将根结点与左、右子树中较小元素的进行交换。
3)若与左子树交换:如果左子树堆被破坏,即左子树的根结点不满足堆的性质,则重复方法 (2).
4)若与右子树交换,如果右子树堆被破坏,即右子树的根结点不满足堆的性质。则重复方法 (2).
5)继续对不满足堆性质的子树进行上述交换操作,直到叶子结点,堆被建成。
称这个自根结点到叶子结点的调整过程为筛选。如图:

再讨论第一个问题,如何将n 个待排序元素初始建堆?
建堆方法:对初始序列建堆的过程,就是一个反复进行筛选的过程。
1)n 个结点的完全二叉树,则最后一个结点是第n/2个结点的子树。
2)筛选从第n/2个结点为根的子树开始,该子树成为堆。
3)之后向前依次对各结点为根的子树进行筛选,使之成为堆,直到根结点。
如图建堆初始过程:无序序列:(49,38,65,97,76,13,27,49)


C#算法实现:
using System;
using System.Collections.Generic;
namespace StructScript
{
/// <summary>
/// 最小堆实现
/// </summary>
/// <typeparam name="T"></typeparam>
public class BinaryHeap<T>
{
//默认容量为6
private const int DEFAULT_CAPACITY = 6;
private int mCount;
private T[] mItems;
private Comparer<T> mComparer;
public BinaryHeap() : this(DEFAULT_CAPACITY) { }
public BinaryHeap(int capacity)
{
if (capacity < 0)
{
throw new IndexOutOfRangeException();
}
mItems = new T[capacity];
mComparer = Comparer<T>.Default;
}
/// <summary>
/// 增加元素到堆,并从后往前依次对各结点为根的子树进行筛选,使之成为堆,直到根结点
/// </summary>
/// <param name="value"></param>
/// <returns></returns>
public bool Enqueue(T value)
{
if (mCount == mItems.Length)
{
ResizeItemStore(mItems.Length * 2);
}
mItems[mCount++] = value;
int position = BubbleUp(mCount - 1);
return (position == 0);
}
/// <summary>
/// 取出堆的最小值
/// </summary>
/// <returns></returns>
public T Dequeue()
{
return Dequeue(true);
}
private T Dequeue(bool shrink)
{
if (mCount == 0)
{
throw new InvalidOperationException();
}
T result = mItems[0];
if (mCount == 1)
{
mCount = 0;
mItems[0] = default(T);
}
else
{
--mCount;
//取序列最后的元素放在堆顶
mItems[0] = mItems[mCount];
mItems[mCount] = default(T);
// 维护堆的结构
BubbleDown();
}
if (shrink)
{
ShrinkStore();
}
return result;
}
private void ShrinkStore()
{
// 如果容量不足一半以上,默认容量会下降。
if (mItems.Length > DEFAULT_CAPACITY && mCount < (mItems.Length >> 1))
{
int newSize = Math.Max(
DEFAULT_CAPACITY, (((mCount / DEFAULT_CAPACITY) + 1) * DEFAULT_CAPACITY));
ResizeItemStore(newSize);
}
}
private void ResizeItemStore(int newSize)
{
if (mCount < newSize || DEFAULT_CAPACITY <= newSize)
{
return;
}
T[] temp = new T[newSize];
Array.Copy(mItems, 0, temp, 0, mCount);
mItems = temp;
}
public void Clear()
{
mCount = 0;
mItems = new T[DEFAULT_CAPACITY];
}
/// <summary>
/// 从前往后依次对各结点为根的子树进行筛选,使之成为堆,直到序列最后的节点
/// </summary>
private void BubbleDown()
{
int parent = 0;
int leftChild = (parent * 2) + 1;
while (leftChild < mCount)
{
// 找到子节点中较小的那个
int rightChild = leftChild + 1;
int bestChild = (rightChild < mCount && mComparer.Compare(mItems[rightChild], mItems[leftChild]) < 0) ?
rightChild : leftChild;
if (mComparer.Compare(mItems[bestChild], mItems[parent]) < 0)
{
// 如果子节点小于父节点, 交换子节点和父节点
T temp = mItems[parent];
mItems[parent] = mItems[bestChild];
mItems[bestChild] = temp;
parent = bestChild;
leftChild = (parent * 2) + 1;
}
else
{
break;
}
}
}
/// <summary>
/// 从后往前依次对各结点为根的子树进行筛选,使之成为堆,直到根结点
/// </summary>
/// <param name="startIndex"></param>
/// <returns></returns>
private int BubbleUp(int startIndex)
{
while (startIndex > 0)
{
int parent = (startIndex - 1) / 2;
//如果子节点小于父节点,交换子节点和父节点
if (mComparer.Compare(mItems[startIndex], mItems[parent]) < 0)
{
T temp = mItems[startIndex];
mItems[startIndex] = mItems[parent];
mItems[parent] = temp;
}
else
{
break;
}
startIndex = parent;
}
return startIndex;
}
}
}
附上,测试用例:
using System;
namespace StructScript
{
public class TestBinaryHeap
{
static void Main(string[] args)
{
BinaryHeap<int> heap = new BinaryHeap<int>();
heap.Enqueue(8);
heap.Enqueue(2);
heap.Enqueue(3);
heap.Enqueue(1);
heap.Enqueue(5);
Console.WriteLine(heap.Dequeue());
Console.WriteLine(heap.Dequeue());
Console.ReadLine();
}
}
}
测试用例,执行结果依次输出1,2。
总结
到此这篇关于C#数据结构之最小堆实现的文章就介绍到这了,更多相关C#数据结构最小堆实现内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

C#数据结构与算法揭秘二
上文对数据结构与算法,有了一个简单的概述与介绍,这篇文章,我们介绍一中典型数据结构--线性结构. 什么是线性结构,线性结构是最简单.最基本.最常用的数据结构.线性表是线性结构的抽象(Abstract), 线性结构的特点是结构中的数据元素之间存在一对一的线性关系. 这 种一对一的关系指的是数据元素之间的位置关系,即: (1)除第一个位置的数据元素外,其它数据元素位置的前面都只有一个数据元素: (2)除最后一个位置的数据元素外,其它数据元素位置的后面都只有一个元素.也就是说,数据元素是一个接一个的排
-
C#数据结构揭秘一
这里,我们 来说一说C#的数据结构了. ①什么是数据结构.数据结构,字面意思就是研究数据的方法,就是研究数据如何在程序中组织的一种方法.数据结构就是相互之间存在一种或多种特定关系的数据元素的集合. 程序界有一点很经典的话,程序设计=数据结构+算法.用源代码来体现,数据结构,就是编程.他有哪些具体的关系了, (1) 集合(Set):如图 1.1(a)所示,该结构中的数据元素除了存在"同属于一个集合"的关系外,不存在任何其它关系. 集合与数学的集合类似,有无序性,唯一性,确定性. (2)
-
C#构建树形结构数据(全部构建,查找构建)
摘要: 最近在做任务管理,任务可以无限派生子任务且没有数量限制,前端采用Easyui的Treegrid树形展示控件. 一.遇到的问题 获取全部任务拼接树形速度过慢(数据量大约在900条左右)且查询速度也并不快: 二.解决方法 1.Tree转化的JSON数据格式 a.JSON数据格式: [ { "children":[ { "children":[ ], "username":"username2", "passwor
-
C#常用数据结构和算法总结
1.数据 数据(Data)是外部世界信息的载体, 是能够被计算机识别,加工,存储的.在现实生活中也就是我们的产品原材料. 计算机中的数据包括数值数据,图片,影音资料等. 2. 数据元素和数据项 数据元素(Data Element)是数据的基本单位,在计算机处理的过程中通常是作为一个整体来作为处理的. 数据项(Data Item):一个数据元素通常由一个或多个数据项组成. 比如数据库表:(Student),它有Id,Name,Sex,Age,Address等字段,而这张表又有多行数据.我们通常将这
-
C#数据结构之单链表(LinkList)实例详解
本文实例讲述了C#数据结构之单链表(LinkList)实现方法.分享给大家供大家参考,具体如下: 这里我们来看下"单链表(LinkList)".在上一篇<C#数据结构之顺序表(SeqList)实例详解>的最后,我们指出了:顺序表要求开辟一组连续的内存空间,而且插入/删除元素时,为了保证元素的顺序性,必须对后面的元素进行移动.如果你的应用中需要频繁对元素进行插入/删除,那么开销会很大. 而链表结构正好相反,先来看下结构: 每个元素至少具有二个属性:data和next.data
-
C#数据结构与算法揭秘五 栈和队列
这节我们讨论了两种好玩的数据结构,栈和队列. 老样子,什么是栈, 所谓的栈是栈(Stack)是操作限定在表的尾端进行的线性表.表尾由于要进行插入.删除等操作,所以,它具有特殊的含义,把表尾称为栈顶(Top) ,另一端是固定的,叫栈底(Bottom) .当栈中没有数据元素时叫空栈(Empty Stack).这个类似于送饭的饭盒子,上层放的是红烧肉,中层放的水煮鱼,下层放的鸡腿.你要把这些菜取出来,这就引出来了栈的特点先进后出(First in last out). 具体叙述,加下图. 栈通常记
-
C#数据结构之最小堆的实现方法
最小堆 基本思想:堆对应一棵完全二叉树,且所有非叶结点的值均不大于(或不小于)其子女的值,根结点(堆顶元素)的值是最小(或最大)的,每次都取堆顶的元素,将其放在序列最后面,然后将剩余的元素重新调整为最小(大)堆,依次类推,最终得到排序的序列. 堆排序分为大顶堆和小顶堆排序.大顶堆:堆对应一棵完全二叉树,且所有非叶结点的值均不小于其子女的值,根结点(堆顶元素)的值是最大的.而小顶堆正好相反,小顶堆:堆对应一棵完全二叉树,且所有非叶结点的值均不大于其子女的值,根结点(堆顶元素)的值是最小的. 举个例
-
Java数据结构之最小堆和最大堆的原理及实现详解
目录 一.前言 二.堆的数据结构 三.堆的代码实现 1. 实现介绍 2. 入堆实现 3. 出堆实现 4. 小堆实现 5. 大堆实现 一.前言 堆的历史 堆的数据结构有很多种体现形式,包括:2-3堆.B堆.斐波那契堆,而在 Java API 中最常用的是用于实现优先队列的二叉堆,它是由 JWJ Williams 在 1964 年引入的,作为堆排序算法的数据结构.另外在 Dijkstra 算法等几种高效的图算法中,堆也是非常重要的. 二.堆的数据结构 在计算机科学中,堆(heap) 的实现是一种基于
-
Python数据结构与算法之完全树与最小堆实例
本文实例讲述了Python数据结构与算法之完全树与最小堆.分享给大家供大家参考,具体如下: # 完全树 最小堆 class CompleteTree(list): def siftdown(self,i): """ 对一颗完全树进行向下调整,传入需要向下调整的节点编号i 当删除了最小的元素后,当新增加一个数被放置到堆顶时, 如果此时不符合最小堆的特性,则需要将这个数向下调整,直到找到合适的位置为止""" n = len(self) # 当 i 节
-
Java中PriorityQueue实现最小堆和最大堆的用法
一.基本介绍 1.介绍 学习很多算法知识,力争做到最优解的学习过程中,很多时候都会遇到PriorityQueue(优先队列).一个基于优先级堆的无界优先级队列.优先级队列的元素按照其自然顺序进行排序,或者根据构造队列时提供的 Comparator 进行排序,具体取决于所使用的构造方法.优先级队列不允许使用 null 元素.依靠自然顺序的优先级队列还不允许插入不可比较的对象,这样做可能导致 ClassCastException. 此队列的头是按指定排序方式确定的最小元素.如果多个元素都是最小值,则
-
React 之最小堆min heap图文详解
目录 二叉树 完全二叉树 二叉堆 最小堆 React 采用原因 React 函数实现 插入过程(push) >>> 1 删除过程(pop) halfLength peek 二叉树 二叉树(Binary tree),每个节点最多只有两个分支的树结构.通常分支被称作“左子树”或“右子树”.二叉树的分支具有左右次序,不能随意颠倒. 完全二叉树 在一颗二叉树中,若除最后一层外的其余层都是满的,并且最后一层要么是满的,要么在右边缺少连续若干节点,则此二叉树为完全二叉树(Complete Binar
-
Python使用min、max函数查找二维数据矩阵中最小、最大值的方法
本文实例讲述了Python使用min.max函数查找二维数据矩阵中最小.最大值的方法.分享给大家供大家参考,具体如下: 简单使用min.max函数来得到二维数据矩阵中的最大最小值,很简单,这是因为工作需要用到一个东西所以先简单来写了一下: #!usr/bin/env python #encoding:utf-8 ''''' __Author__:沂水寒城 功能:找出来随机生成矩阵中的最大.最小值 ''' import time import random def random_matrix_ge
-
C语言数据结构二叉树之堆的实现和堆排序详解
目录 一.本章重点 二.堆 2.1堆的介绍 2.2堆的接口实现 三.堆排序 一.本章重点 堆的介绍 堆的接口实现 堆排序 二.堆 2.1堆的介绍 一般来说,堆在物理结构上是连续的数组结构,在逻辑结构上是一颗完全二叉树. 但要满足 每个父亲节点的值都得大于孩子节点的值,这样的堆称为大堆. 每个父亲节点的值都得小于孩子节点的值,这样的堆称为小堆. 那么以下就是一个小堆. 百度百科: 堆的定义如下:n个元素的序列{k1,k2,ki,…,kn}当且仅当满足下关系时,称之为堆. 若将和此次序列对应的一维数
-
数据结构之数组翻转的实现方法
数据结构之数组翻转的实现方法 以下为实现数组翻转的方法: 1.用c语言实现的版本 #include<stdio.h> #define M 20 void fun(int *x,int n) { int *i, *j, *p, m=n/2; i = x; j = x+n-1; p = x+m; for( ; i<p; ++i,--j) { int t = *i; *i = *j; *j = t; } } void main() { int i,a[M],n; printf("En
-
在Docker容器中使用iptables时的最小权限的开启方法
在Docker容器中使用iptables时的最小权限的开启方法 Dcoker容器在使用的过程中,有的时候是需要使用在容器中使用iptables进行启动的,默认的docker run时都是以普通方式启动的,没有使用iptables的权限,那么怎样才能在容器中使用iptables呢?要如何开启权限呢? 那么在docker进行run的时候如何将此容器的权限进行配置呢?主要是使用--privileged或--cap-add.--cap-drop来对容器本身的能力的开放或限制.以下将举例来进行说明: 例如
-
正则表达式实现最小匹配功能的方法
本文实例讲述了正则表达式实现最小匹配功能的方法.分享给大家供大家参考,具体如下: 正则表达式默认情况下实现的是最大化匹配,这在有些情况下是非常不愿意出现的,比如下面这段代码: # starting IndiaInventoryAPP.exe" ~~DisplayVariableValues "parameterGroup,mailRecipients,ModuleArgs"~DisplayVariableValues "LogFolder"~$binary