详解R语言中的多项式回归、局部回归、核平滑和平滑样条回归模型
在标准线性模型中,我们假设 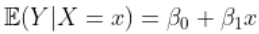 。当线性假设无法满足时,可以考虑使用其他方法。
。当线性假设无法满足时,可以考虑使用其他方法。
多项式回归
扩展可能是假设某些多项式函数,
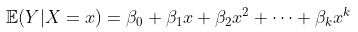
同样,在标准线性模型方法(使用GLM的条件正态分布)中,参数 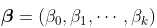 可以使用最小二乘法获得,其中
可以使用最小二乘法获得,其中 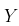 在
在 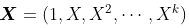 。
。
即使此多项式模型不是真正的多项式模型,也可能仍然是一个很好的近似值 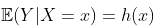 。实际上,根据 Stone-Weierstrass定理,如果
。实际上,根据 Stone-Weierstrass定理,如果 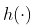 在某个区间上是连续的,则有一个统一的近似值
在某个区间上是连续的,则有一个统一的近似值 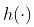 ,通过多项式函数。
,通过多项式函数。
仅作说明,请考虑以下数据集
db = data.frame(x=xr,y=yr) plot(db)
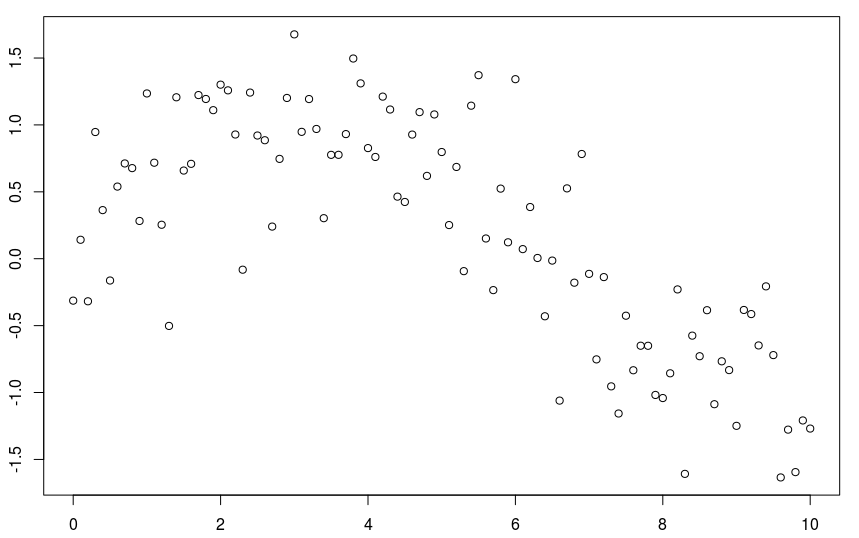
与标准回归线
reg = lm(y ~ x,data=db) abline(reg,col="red")
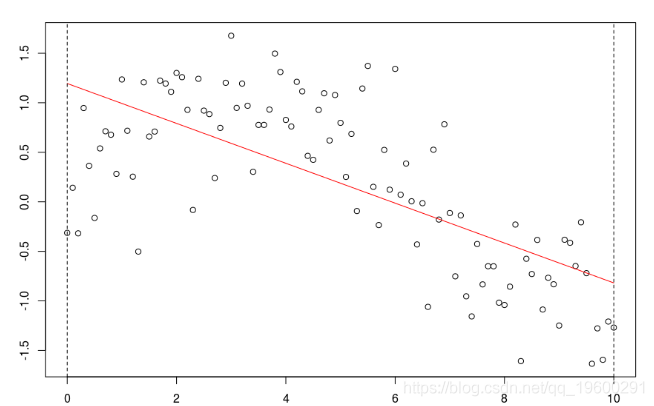
考虑一些多项式回归。如果多项式函数的次数足够大,则可以获得任何一种模型,
reg=lm(y~poly(x,5),data=db)
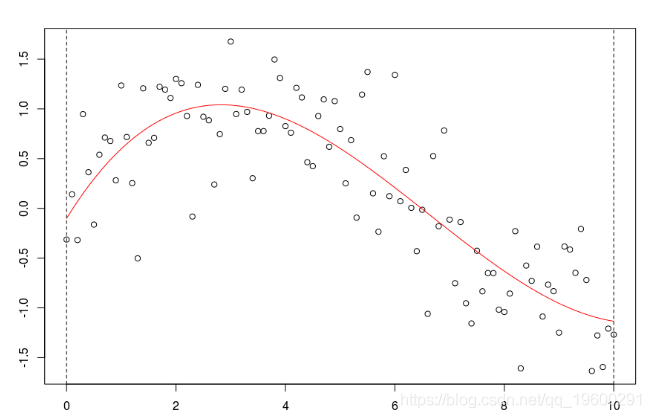
但是,如果次数太大,那么会获得太多的“波动”,
reg=lm(y~poly(x,25),data=db)
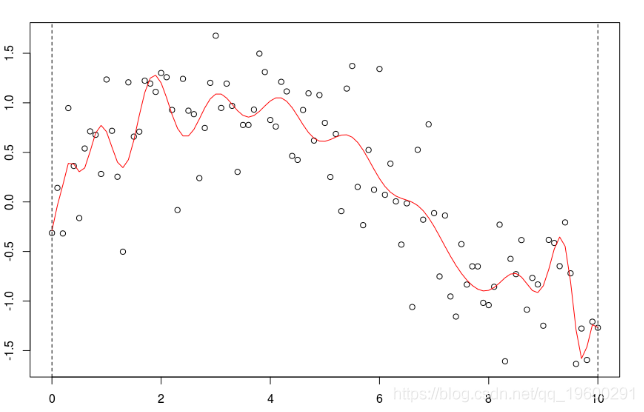
并且估计值可能不可靠:如果我们更改一个点,则可能会发生(局部)更改
yrm=yr;yrm[31]=yr[31]-2 lines(xr,predict(regm),col="red")
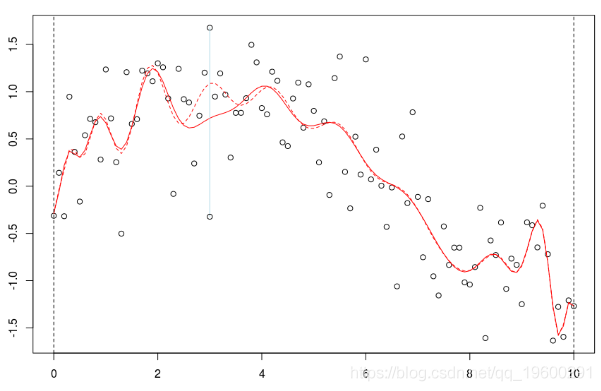
局部回归
实际上,如果我们的兴趣是局部有一个很好的近似值 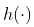 ,为什么不使用局部回归?
,为什么不使用局部回归?
使用加权回归可以很容易地做到这一点,在最小二乘公式中,我们考虑
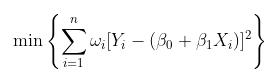
在这里,我考虑了线性模型,但是可以考虑任何多项式模型。在这种情况下,优化问题是
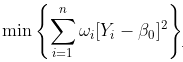 可以解决,因为
可以解决,因为
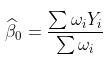
例如,如果我们想在某个时候进行预测 , 考虑 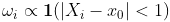 。使用此模型,我们可以删除太远的观测值,
。使用此模型,我们可以删除太远的观测值,
更一般的想法是考虑一些核函数 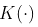 给出权重函数,以及给出邻域长度的一些带宽(通常表示为h),
给出权重函数,以及给出邻域长度的一些带宽(通常表示为h),

这实际上就是所谓的 Nadaraya-Watson函数估计器 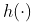 。
。
在前面的案例中,我们考虑了统一核 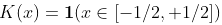 ,
,
但是使用这种权重函数具有很强的不连续性不是最好的选择,尝试高斯核,
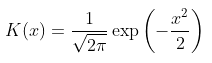
这可以使用
w=dnorm((xr-x0)) reg=lm(y~1,data=db,weights=w)
在我们的数据集上,我们可以绘制
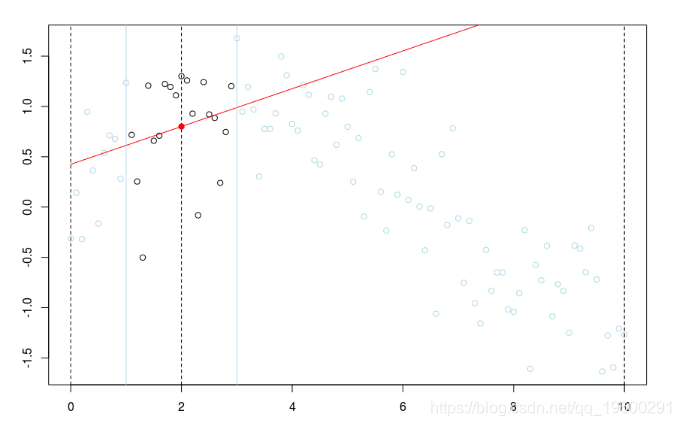
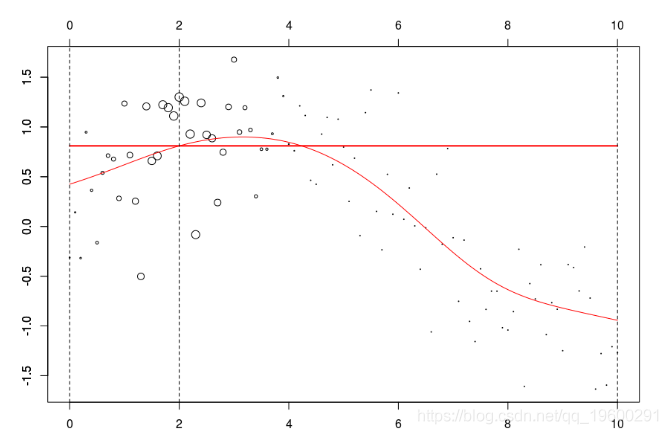
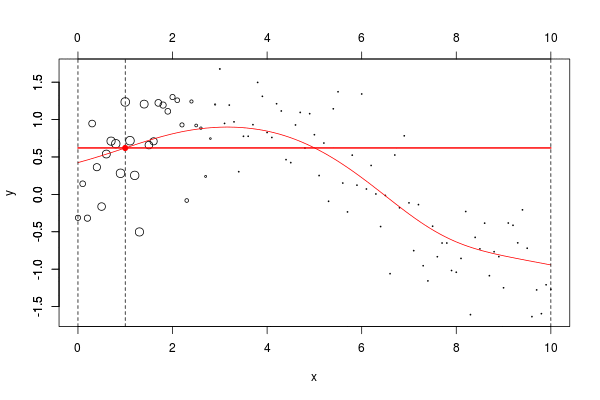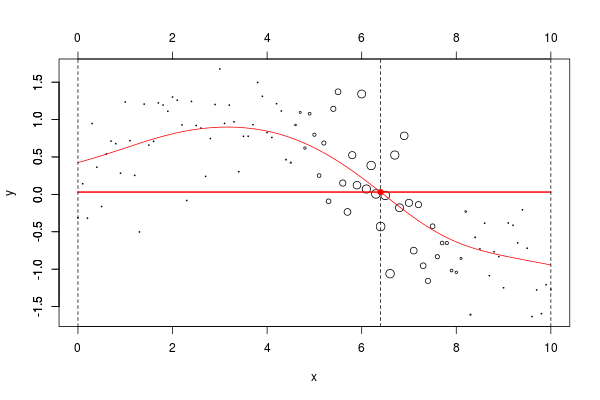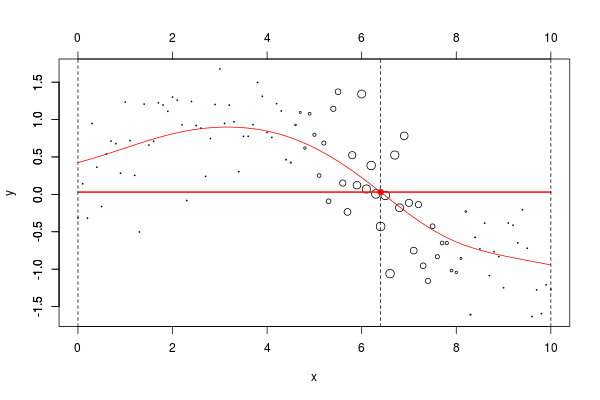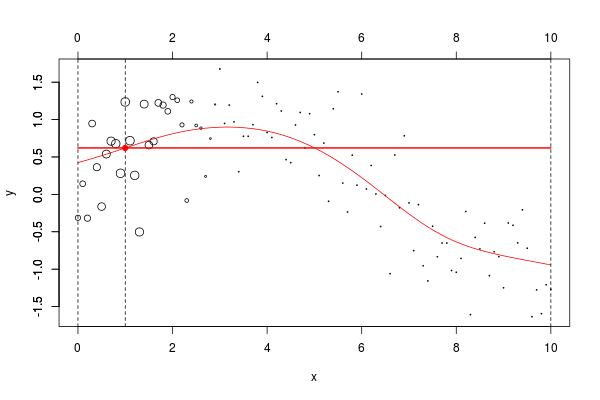
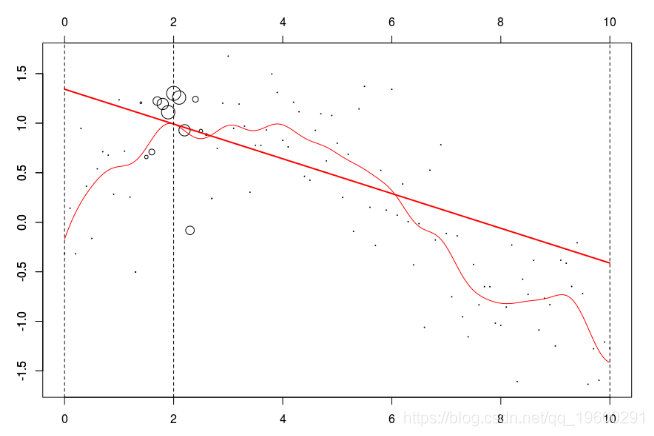
w=dnorm((xr-x0)) plot(db,cex=abs(w)*4) lines(ul,vl0,col="red") axis(3) axis(2) reg=lm(y~1,data=db,weights=w) u=seq(0,10,by=.02) v=predict(reg,newdata=data.frame(x=u)) lines(u,v,col="red",lwd=2)
在这里,我们需要在点2进行局部回归。下面的水平线是回归(点的大小与宽度成比例)。红色曲线是局部回归的演变
让我们使用动画来可视化曲线。
但是由于某些原因,我无法在Linux上轻松安装该软件包。我们可以使用循环来生成一些图形
name=paste("local-reg-",100+i,".png",sep="")
png(name,600,400)
for(i in 1:length(vx0)) graph (i)
然后,我使用
当然,可以考虑局部线性模型,
return(predict(reg,newdata=data.frame(x=x0)))}

甚至是二次(局部)回归,
lm(y~poly(x,degree=2), weights=w)

当然,我们可以更改带宽
请注意,实际上,我们必须选择权重函数(所谓的核)。但是,有(简单)方法来选择“最佳”带宽h。交叉验证的想法是考虑
 是使用局部回归获得的预测。
是使用局部回归获得的预测。
我们可以尝试一些真实的数据。
library(XML) data = readHTMLTable(html)
整理数据集,
plot(data$no,data$mu,ylim=c(6,10)) segments(data$no,data$mu-1.96*data$se,
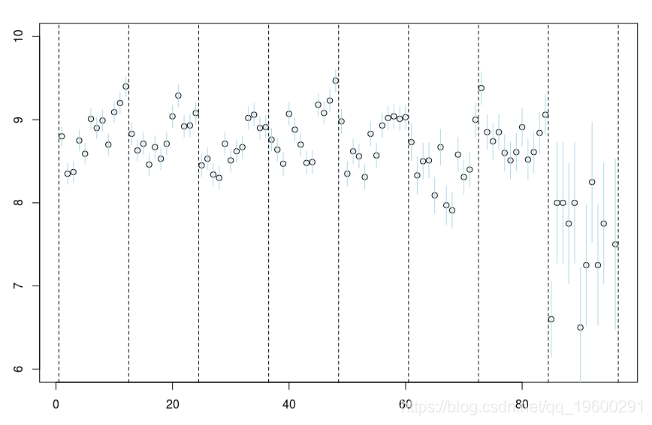
我们计算标准误差,反映不确定性。
for(s in 1:8){reg=lm(mu~no,data=db,
lines((s predict(reg)[1:12]
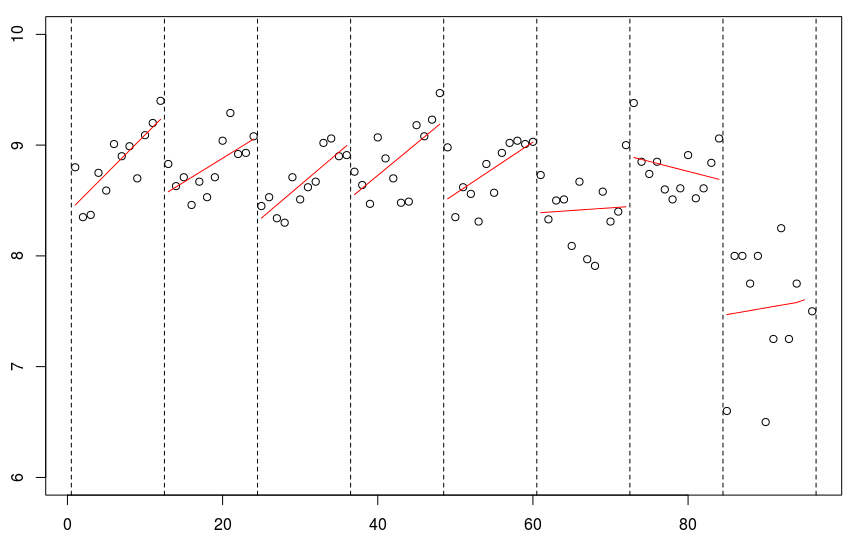
所有季节都应该被认为是完全独立的,这不是一个很好的假设。
smooth(db$no,db$mu,kernel = "normal",band=5)
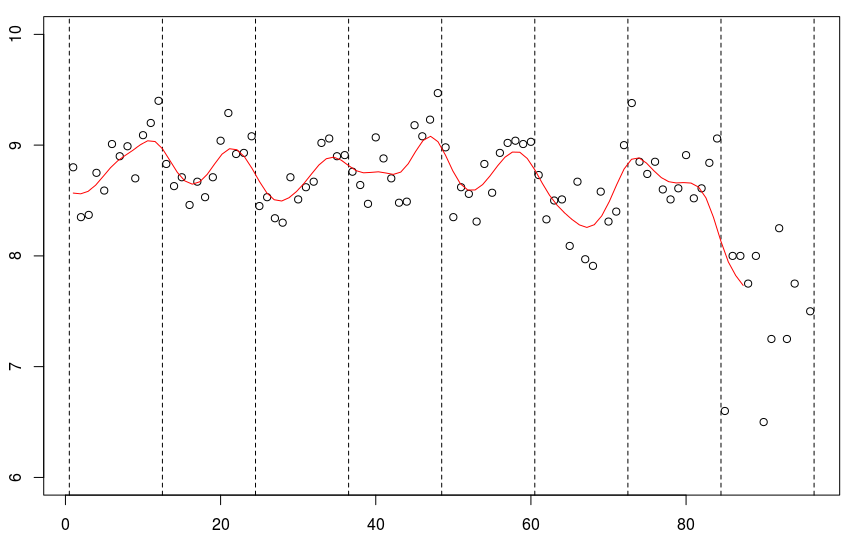
我们可以尝试查看带宽较大的曲线。
db$mu[95]=7 plot(data$no,data$mu lines(NW,col="red")
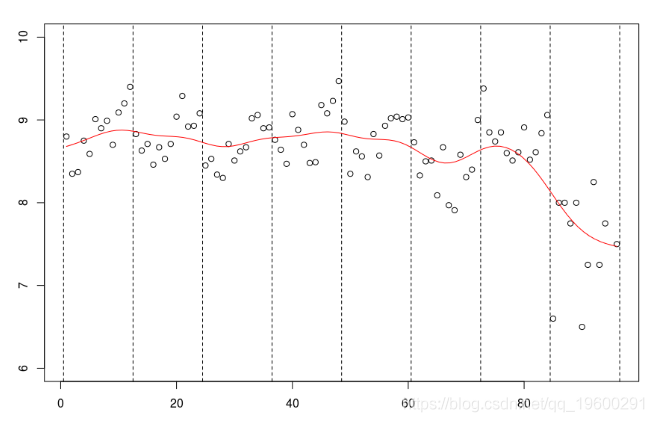
样条平滑
接下来,讨论回归中的平滑方法。假设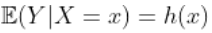 ,
, 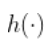 是一些未知函数,但假定足够平滑。例如,假设
是一些未知函数,但假定足够平滑。例如,假设 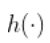 是连续的,
是连续的, 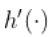 存在,并且是连续的,
存在,并且是连续的, 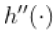 存在并且也是连续的等等。如果 足够平滑, 可以使用泰勒展开式。 因此,对于
存在并且也是连续的等等。如果 足够平滑, 可以使用泰勒展开式。 因此,对于 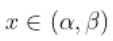
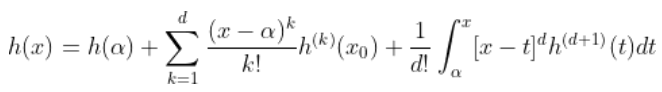
也可以写成
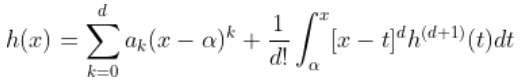
第一部分只是一个多项式。
使用 黎曼积分,观察到
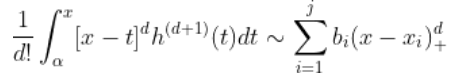
因此,
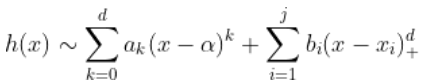
我们有线性回归模型。一个自然的想法是考虑回归 ,对于
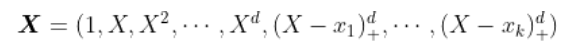
给一些节点 。
plot(db)
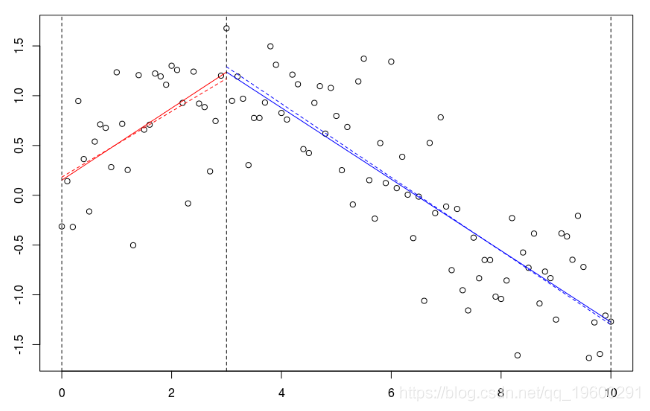
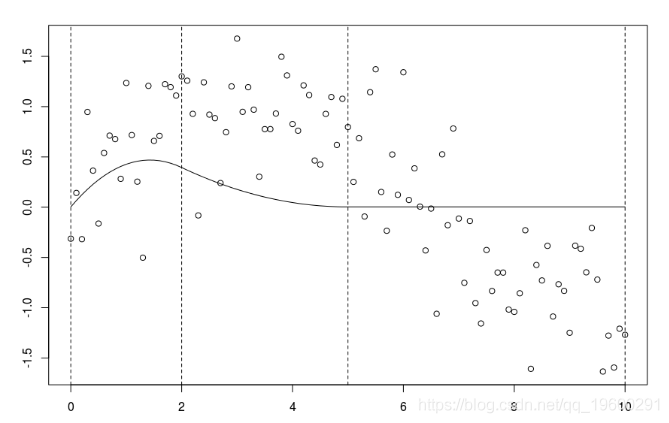
如果我们考虑一个节点,并扩展阶数1,
B=bs(xr,knots=c(3),Boundary.knots=c(0,10),degre=1) lines(xr[xr<=3],predict(reg)[xr<=3],col="red") lines(xr[xr>=3],predict(reg)[xr>=3],col="blue")
可以将用该样条获得的预测与子集(虚线)上的回归进行比较。
lines(xr[xr<=3],predict(reg)[xr<=3 lm(yr~xr,subset=xr>=3)
这是不同的,因为这里我们有三个参数(关于两个子集的回归)。当要求连续模型时,失去了一个自由度。观察到可以等效地写
lm(yr~bs(xr,knots=c(3),Boundary.knots=c(0,10)
回归中出现的函数如下
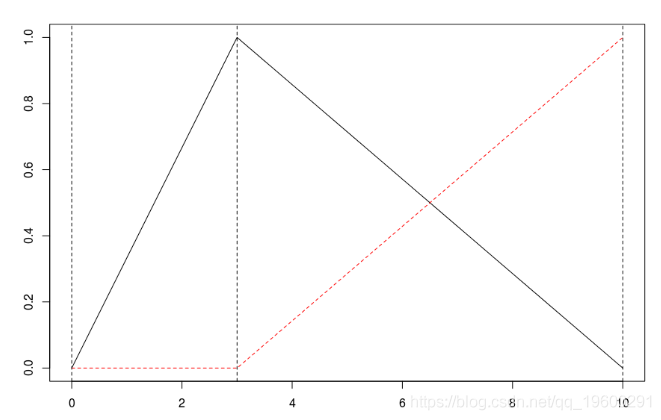
现在,如果我们对这两个分量进行回归,我们得到
matplot(xr,B abline(v=c(0,2,5,10),lty=2)
如果加一个节点,我们得到
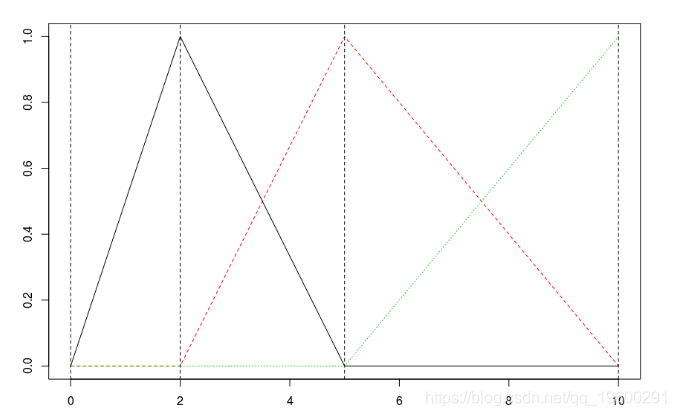
预测是
lines(xr,predict(reg),col="red")
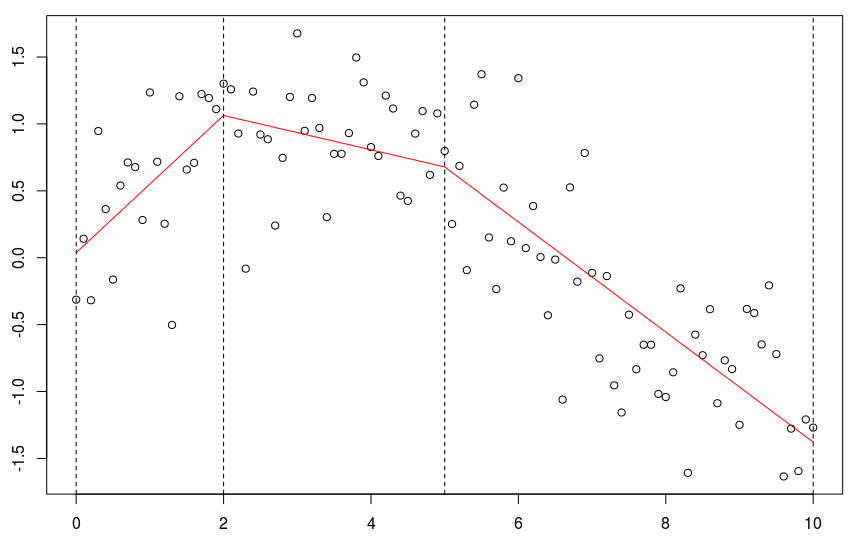
我们可以选择更多的节点
lines(xr,predict(reg),col="red")
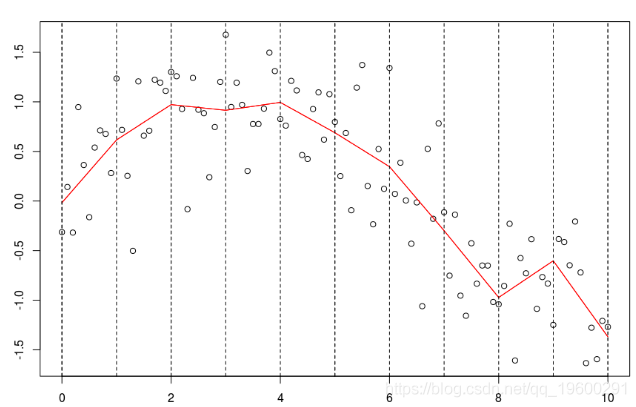
我们可以得到一个置信区间
polygon(c(xr,rev(xr)),c(P[,2],rev(P[,3])) points(db)
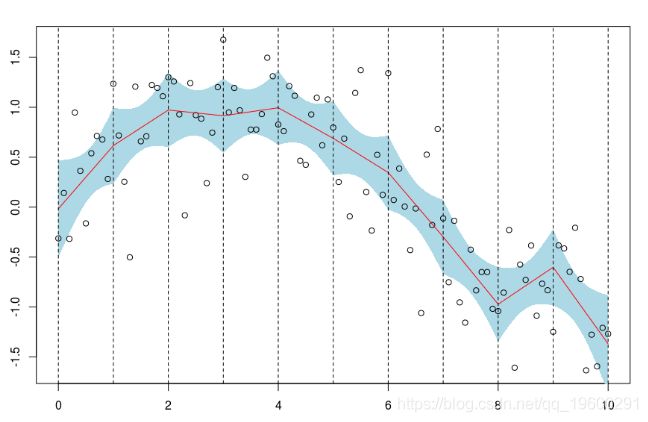
如果我们保持先前选择的两个节点,但考虑泰勒的2阶的展开,我们得到
matplot(xr,B,type="l") abline(v=c(0,2,5,10),lty=2)
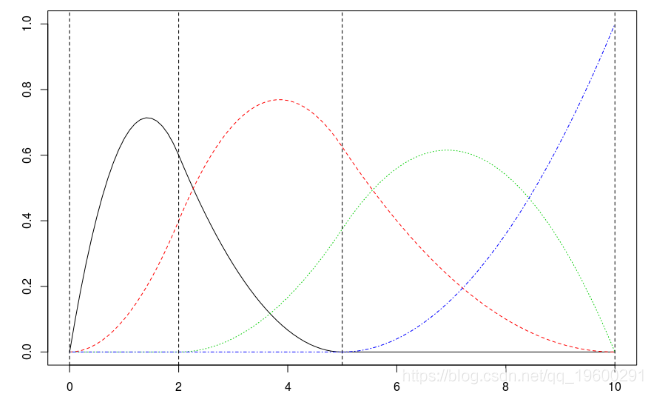
如果我们考虑常数和基于样条的第一部分,我们得到
B=cbind(1,B) lines(xr,B[,1:k]%*%coefficients(reg)[1:k],col=k-1,lty=k-1)
如果我们将常数项,第一项和第二项相加,则我们得到的部分在第一个节点之前位于左侧,
k=3 lines(xr,B[,1:k]%*%coefficients(reg)[1:k]
通过基于样条的矩阵中的三个项,我们可以得到两个节点之间的部分,
lines(xr,B[,1:k]%*%coefficients(reg)[1:k]
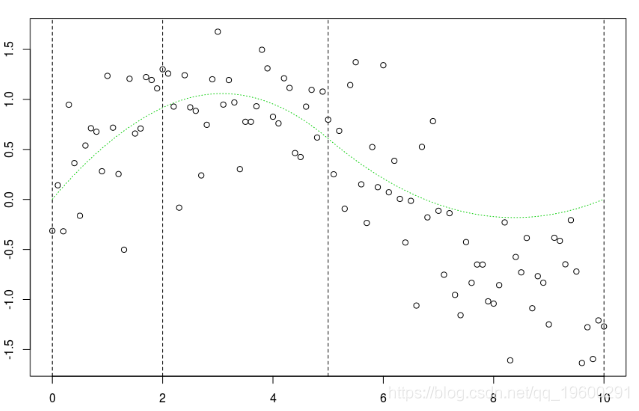
最后,当我们对它们求和时,这次是最后一个节点之后的右侧部分,
k=5
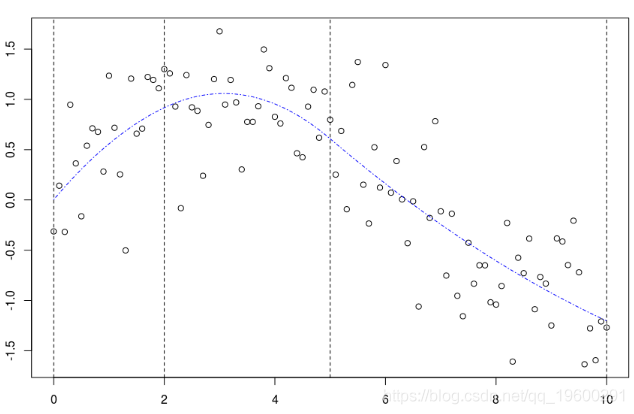
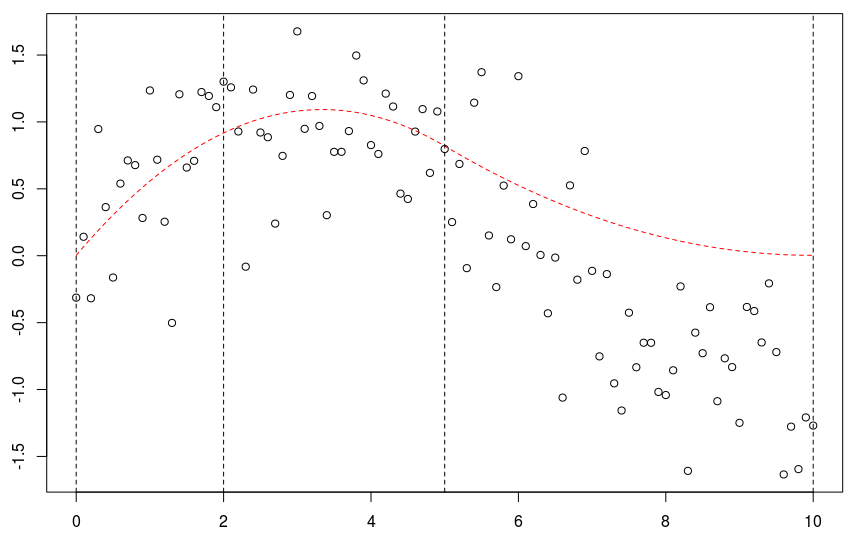
这是我们使用带有两个(固定)节点的二次样条回归得到的结果。可以像以前一样获得置信区间
polygon(c(xr,rev(xr)),c(P[,2],rev(P[,3])) points(db) lines(xr,P[,1],col="red")
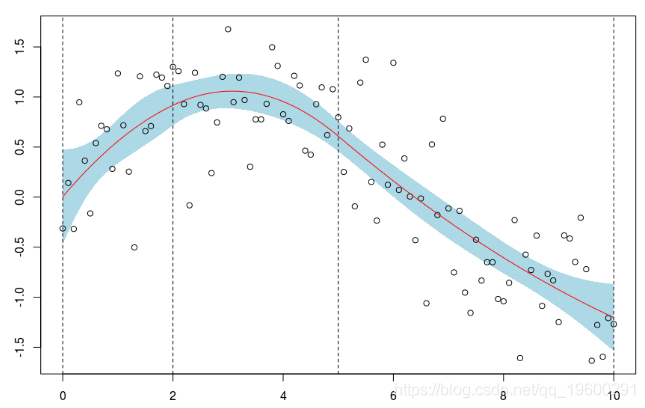
使用函数 ,可以确保点的连续性
。
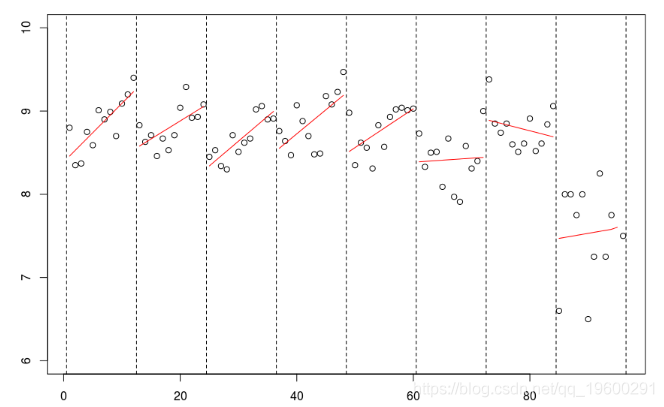
再一次,使用线性样条函数,可以增加连续性约束,
lm(mu~bs(no,knots=c(12*(1:7)+.5),Boundary.knots=c(0,97), lines(c(1:94,96),predict(reg),col="red")
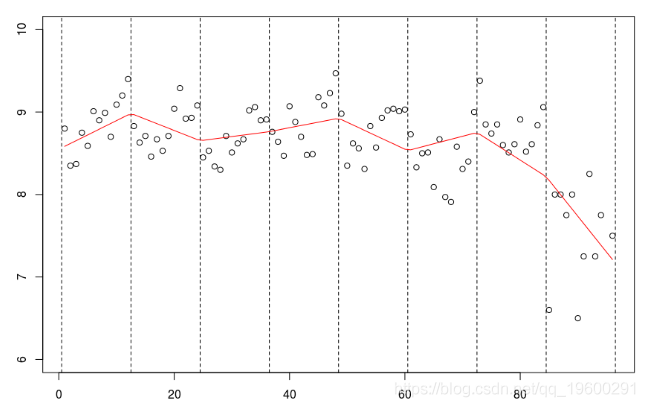
但是我们也可以考虑二次样条,
abline(v=12*(0:8)+.5,lty=2) lm(mu~bs(no,knots=c(12*(1:7)+.5),Boundary.knots=c(0,97),
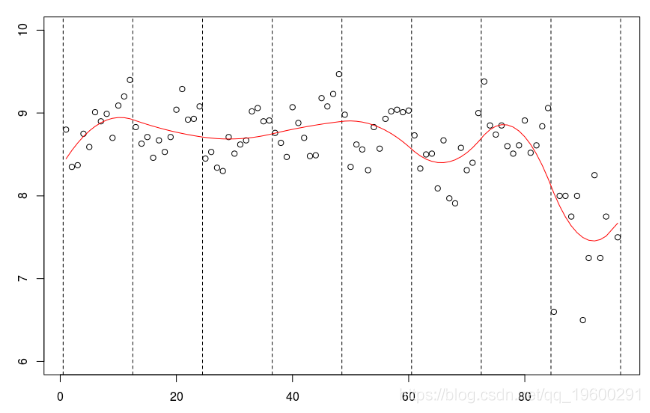

到此这篇关于详解R语言中的多项式回归、局部回归、核平滑和平滑样条回归模型的文章就介绍到这了,更多相关R语言多项式回归、局部回归内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

详解R语言中的PCA分析与可视化
1. 常用术语 (1)标准化(Scale) 如果不对数据进行scale处理,本身数值大的基因对主成分的贡献会大.如果关注的是变量的相对大小对样品分类的贡献,则应SCALE,以防数值高的变量导入的大方差引入的偏见.但是定标(scale)可能会有一些负面效果,因为定标后变量之间的权重就是变得相同.如果我们的变量中有噪音的话,我们就在无形中把噪音和信息的权重变得相同,但PCA本身无法区分信号和噪音.在这样的情形下,我们就不必做定标. (2)特征值 (eigen value) 特征值与特征向量均为矩阵分
-
详解R语言中生存分析模型与时间依赖性ROC曲线可视化
R语言简介 R是用于统计分析.绘图的语言和操作环境.R是属于GNU系统的一个自由.免费.源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具. 人们通常使用接收者操作特征曲线(ROC)进行二元结果逻辑回归.但是,流行病学研究中感兴趣的结果通常是事件发生时间.使用随时间变化的时间依赖性ROC可以更全面地描述这种情况下的预测模型. 时间依赖性ROC定义 令 Mi为用于死亡率预测的基线(时间0)标量标记. 当随时间推移观察到结果时,其预测性能取决于评估时间 t.直观地说,在零时间测量的标记值应该
-
R语言dplyr包之高效数据处理函数(filter、group_by、mutate、summarise)详解
R语言dplyr包的数据整理.分析函数用法文章连载NO.01 在日常数据处理过程中难免会遇到些难处理的,选取更适合的函数分割.筛选.合并等实在是大快人心! 利用dplyr包中的函数更高效的数据清洗.数据分析,及为后续数据建模创造环境:本篇涉及到的函数为filter.filter_all().filter_if().filter_at().mutate.group_by.select.summarise. 1.数据筛选函数: #可使用filter()函数筛选/查找特定条件的行或者样本 #filte
-
R语言 vs Python对比:数据分析哪家强?
什么是R语言? R语言,一种自由软件编程语言与操作环境,主要用于统计分析.绘图.数据挖掘.R本来是由来自新西兰奥克兰大学的罗斯·伊哈卡和罗伯特·杰特曼开发(也因此称为R),现在由"R开发核心团队"负责开发.R基于S语言的一个GNU计划项目,所以也可以当作S语言的一种实现,通常用S语言编写的代码都可以不作修改的在R环境下运行.R的语法是来自Scheme. R的源代码可自由下载使用,亦有已编译的可执行文件版本可以下载,可在多种平台下运行,包括UNIX(也包括FreeBSD和Linux).W
-
R语言利用loess如何去除某个变量对数据的影响详解
R语言介绍 R语言是用于统计分析,图形表示和报告的编程语言和软件环境. R语言由Ross Ihaka和Robert Gentleman在新西兰奥克兰大学创建,目前由R语言开发核心团队开发. R语言的核心是解释计算机语言,其允许分支和循环以及使用函数的模块化编程. R语言允许与以C,C ++,.Net,Python或FORTRAN语言编写的过程集成以提高效率. R语言在GNU通用公共许可证下免费提供,并为各种操作系统(如Linux,Windows和Mac)提供预编译的二进制版本. R是一个在GNU
-
详解R语言中的多项式回归、局部回归、核平滑和平滑样条回归模型
在标准线性模型中,我们假设 .当线性假设无法满足时,可以考虑使用其他方法. 多项式回归 扩展可能是假设某些多项式函数, 同样,在标准线性模型方法(使用GLM的条件正态分布)中,参数 可以使用最小二乘法获得,其中 在 . 即使此多项式模型不是真正的多项式模型,也可能仍然是一个很好的近似值 .实际上,根据 Stone-Weierstrass定理,如果 在某个区间上是连续的,则有一个统一的近似值 ,通过多项式函数. 仅作说明,请考虑以下数据集 db = data.frame(x=xr,y=y
-
详解R语言中的表达式、数学公式、特殊符号
在R语言的绘图函数中,如果文本参数是合法的R语言表达式,那么这个表达式就被用Tex类似的规则进行文本格式化. y <- function(x) (exp(-(x^2)/2))/sqrt(2*pi) plot(y, -5, 5, main = expression(f(x) == frac(1,sqrt(2*pi))*e^(-frac(x^2,2))), lwd = 3, col = "blue") library(ggplot2) x <- seq(0, 2*pi, b
-
详解R语言MCMC:Metropolis-Hastings采样用于回归的贝叶斯估计
MCMC是从复杂概率模型中采样的通用技术. 蒙特卡洛 马尔可夫链 Metropolis-Hastings算法 问题 如果需要计算有复杂后验pdf p(θ| y)的随机变量θ的函数f(θ)的平均值或期望值. 您可能需要计算后验概率分布p(θ)的最大值. 解决期望值的一种方法是从p(θ)绘制N个随机样本,当N足够大时,我们可以通过以下公式逼近期望值或最大值 将相同的策略应用于通过从p(θ| y)采样并取样本集中的最大值来找到argmaxp(θ| y). 解决方法 1.1直接模拟 1.2逆CDF 1.
-
详解R语言数据合并一行代码搞定
数据的合并 需要的函数 cbind(),rbind(),bind_rows(),merge() 准备数据 我们先构造一组数据,以便下面的演示 > data1<-data.frame( + namea=c("海波","立波","秀波"), + value=c("一波","接","一波") + ) > data1 namea value 1 海波 一波 2 立波 接 3 秀
-
详解R语言实现前向逐步回归(前向选择模型)
目录 前向逐步回归原理 数据导入并分组 导入数据 特征与标签分开存放 前向逐步回归构建输出特征集合 从空开始一次创建属性列表 模型效果评估 前向逐步回归原理 前向逐步回归的过程是:遍历属性的一列子集,选择使模型效果最好的那一列属性.接着寻找与其组合效果最好的第二列属性,而不是遍历所有的两列子集.以此类推,每次遍历时,子集都包含上一次遍历得到的最优子集.这样,每次遍历都会选择一个新的属性添加到特征集合中,直至特征集合中特征个数不能再增加. 数据导入并分组 导入数据,将数据集抽取70%作为训练集,剩
-
详解C语言中二分查找的运用技巧
目录 基础的二分查 查找左侧边界 查找右侧边界 二分查找问题分析 实例1: 爱吃香蕉的珂珂 实例2:运送包裹 前篇文章聊到了二分查找的基础以及细节的处理问题,主要介绍了 查找和目标值相等的元素.查找第一个和目标值相等的元素.查找最后一个和目标值相等的元素 三种情况. 这些情况都适用于有序数组中查找指定元素 这个基本的场景,但实际应用中可能不会这么直接,甚至看了题目之后,都不会想到可以用二分查找算法来解决 . 本文就来分析下二分查找在实际中的应用,通过分析几个应用二分查找的实例,总结下能使用二分查
-
详解Go语言中泛型的实现原理与使用
目录 前言 问题 解决方法 类型约束 重获类型安全 泛型使用场景 性能 虚拟方法表 单态化 Go 的实现 结论 前言 原文:A gentle introduction to generics in Go byDominik Braun 万俊峰Kevin:我看了觉得文章非常简单易懂,就征求了作者同意,翻译出来给大家分享一下. 本文是对泛型的基本思想及其在 Go 中的实现的一个比较容易理解的介绍,同时也是对围绕泛型的各种性能讨论的简单总结.首先,我们来看看泛型所解决的核心问题. 问题 假设我们想实现
-
一文详解C语言中文件相关函数的使用
目录 一.文件和流 1.程序文件 2.数据文件 3.流 二.文件组成 三.文件的打开和关闭 1.文件的打开fopen 2.文件关闭fclose 四.文件的顺序读写 1.使用fputc和fgetc写入/读取单个字符 2.使用fputs和fgets写入/读取一串字符 3.使用fprintf和fscanf按照指定的格式写入/读取 4.使用fwrite和fread按照二进制的方式写入/读取 5.使用sprintf和sscanf将格式化数据和字符串互相转换(文件无关) 五.文件的随机读写 1.fseek(
-
详解Go语言中关于包导入必学的 8 个知识点
1. 单行导入与多行导入 在 Go 语言中,一个包可包含多个 .go 文件(这些文件必须得在同一级文件夹中),只要这些 .go 文件的头部都使用 package 关键字声明了同一个包. 导入包主要可分为两种方式: 单行导入 import "fmt" import "sync" 多行导入 import( "fmt" "sync" ) 如你所见,Go 语言中 导入的包,必须得用双引号包含,在这里吐槽一下. 2. 使用别名 在一些场