使用Python制作一个数据预处理小工具(多种操作一键完成)
在我们平常使用Python进行数据处理与分析时,在import完一大堆库之后,就是对数据进行预览,查看数据是否出现了缺失值、重复值等异常情况,并进行处理。

本文将结合GUI工具PySimpleGUI,来讲解如何制作一款属于自己的数据预处理小工具,让这个过程也能够自动化!最终效果如下

本文将分为三部分讲解:
- 制作GUI界面
- 数据处理讲解
- 打包与测试
主要涉及将涉及以下模块:
- PySimpleGUI
- pandas
- matplotlib
一、GUI界面制作
思路
老规矩,先讲思路再上代码,首先还是说一下,使用PySimpleGUI还是那四个流程
引入模块==>创建元素并填充layout==> 创建窗体 ==>创建事件循环
从元素看,从图中可以知道我们需要的元素有使用说明这个菜单栏、看上去是凹下去的数据预处理框、框内的3个单选项值、读取文件路径的3个元素(固定文本、输入文本、浏览按钮)、"查看、处理、关闭"三个按钮。
从总体看,整个窗体中我们需要所有的元素呈现正中间的分布状态。其中菜单栏在窗体边缘靠左分布。采用行衔接式的总分布。
从事件上看,我们需要在使用说明菜单中加上使用者需要的注意事项。而文件读取位置我们设置我们常用的2种数据存储格式(“.xlsx”,“.xls”)的Excel格式。
读取后,我们在数据预处理框架选择一种处理。接着,我们可以对每一种错误进行弹出框查看,查看完之后对数据做最终处理。
处理的过程需要将处理好的数据覆盖原来的数据文件。整个过程必须是持续不间断的。这里说个tips:每次数据分析之前最好做一个备份,防止分析过程中失败但是又找不到原来数据文件的尴尬。
代码
看望思路后是不是有种蠢蠢欲动的感觉?!我们来实现一波,先看完整代码,后面详细拆解
import PySimpleGUI as sg
import pandas as pd
import matplotlib
matplotlib.use("TkAgg")
sg.ChangeLookAndFeel('GreenTan')
menu_def = [['&使用说明', ['&注意']]]
layout = [
[sg.Menu(menu_def, tearoff=True)],
[sg.Frame(layout=[
[sg.Radio('重复值处理', "RADIO1",size=(15,1),key="dup"), sg.Radio('缺失值处理', "RADIO1",size=(15,1),key="mis"), sg.Radio('异常值处理', "RADIO1",default=True,key="war")]], title='数据预处理',title_color='green',title_location='n',relief=sg.RELIEF_SUNKEN, tooltip='选择其中一种处理方式' )],
[sg.Text('文件位置', size=(8, 1), auto_size_text=False, justification='right'),
sg.InputText(enable_events=True,key="lujing"), sg.Button('浏览',key = 'getf')],
[sg.Button('查看',key = 'look'),sg.Submit('处理',key = 'handle'), sg.Cancel('关闭')]]
window = sg.Window('特征工程', layout, default_element_size=(40, 1), grab_anywhere=False)
while True:
event, values = window.read()
if event == 'getf':
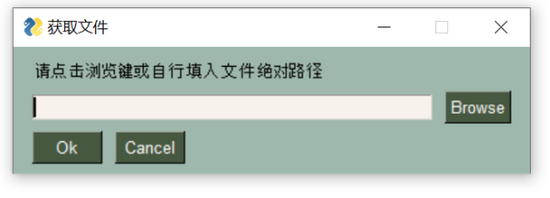
text = sg.popup_get_file('请点击浏览键或自行填入文件绝对路径',title = '获取件',file_types = (("Excel Files", "*.xlsx"),("Excel Files", "*.xls"),))
sg.popup('提示', '是否确认选择文件---', text)
window['lujing'].update(text)
if event == "look":
'''
用户点击查看按钮促发的事件
'''
if event == "handle":
'''
用户点击处理按钮促发的事件
'''
if event == "Cancel" or event == sg.WIN_CLOSED:
break
if event == "注意":
'''
注意事项编写
'''
代码解释
其实有了思路后,你就会发现似乎一切都变得简单了。接下来讲解相关参数的作用。
首先是matplotlib.use("TkAgg"):使用matplotlib模块并且调用这个函数的目的是在我们进行查看异常值处理(箱型图展示)所用到,是改变图像显示的方式:TkAgg(一个交互式后台)。
所谓交互式后台就是你可以对图像进行任意操作,区域放大缩小、值查看等功能。
之所以调用这个函数首先是因为我们使用的是GUI是要有那种交互的感觉的,其次是如果数据量较大时,箱型图会很小,这样子可以利于查看。
其次sg.ChangeLookAndFeel('GreenTan'):改变窗体颜色。
那么menu_def就是菜单栏,使用【“”,【“”】】这种格式来定义主菜单栏和子菜单栏。tearoff这个函数是加一条可爱的虚线间隔每个字段。
sg.Frame():这个和sg.columns()元素的用法是一样的,主要是用来多个子元素的,我们这里设置了relief参数来让整个框架在观感上显得凹形。tooltip参数是你鼠标移动框架的位置出现的小提示框。
title_location参数的用法非常有趣,是标题字符串的位置设置,有(n,s,e,w,se等),你很快会发现这个位置和其他元素布局位置设置不一样,他是以地理位置坐标做子参数的。
sg.Radio:单选选项框,要将所有的单选选项框的子参数group_id都设成一样的,这样你才能三个选项中选一个,这里我们以"RADIO1"为group_id。
sg.Button():整个GUI中我们使用了4个按钮,其中有一个专有的按钮Cancel。
sg.popup():比较初级的弹出框,显示提示类的关键信息所用到。
sg.popup_get_file():这是一个高级的弹出框元素,是从带有文本输入字段和浏览按钮的弹出窗口,以便用户选择文件。效果如下
二、数据预处理
GUI部分搞定后,接着我们讲解数据处理部分,主要是针对重复值、缺失值和异常值。
数据准备
我们这里用到的是2020年10月28日A股的行情。数据部分展示:
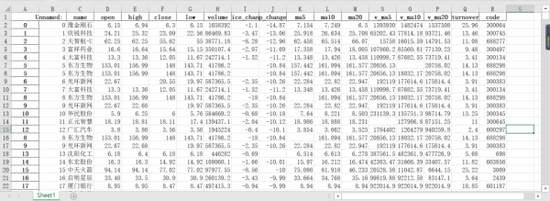
我们可以看到这里面有重复的行、有缺失值的地方。
重复值处理
对于二维列表DataFrame来讲使用Pandas模块是最方便最象征办公简洁化的模块
import pandas as pd
df = df.read_excel('文件绝对路径')
imfor = df[df.duplicated()]
imfor = str(imfor)
首先调用Pandas模块并读取文件路径,这里我们采取绝对路径而不采取相对路径的原因是我们之后打包的GUI是不依靠文件的靠Python自带的环境,所以相对路径读取是无法识别的。
df[df.duplicated()]这个Pandas内的函数是以二维列表形式来打印重复值对应的行。这里把df变量变为str字符串形式是因为我们在后来GUI中使用弹出窗口的元素时要以字符串形式加载。
最终处理重复值的方法如下:
df = df.drop_duplicates(inplace = True)
代码只有一行,却能做到将整个数据表中的重复值都删除,说明Pandas函数的强大。
至于为什么用inplace = True,是因为删除函数不并不能改变原表格结构,所以需要将新表覆盖原来的表格。
缺失值处理
先看代码,其实在之前有关缺失值处理我在一年前就写过相关文章点击查看
import pandas as pd
df = df.read_excel('文件绝对路径')
#df.isnull()
imfor1 = df.isnull().sum()
#df.isnull().any()
imfor1 = str(imfor1)
对于有缺失值的的数据表来说,df.isnull()或者df.isna()来查看空值。这个函数的作用时判断是否为空值,若是为空值则赋予True,否则赋予False。
这里我们使用df.isnull().sum()来统计每一列字段的缺失值数量。如果数据量大的话,还可以使用df.isnull().any()来查看只有缺失值的行。
解决方法,处理缺失值的方法有很多种,取均值、取中位数、删除、取下方的值等。我们这里用取上方值的方法来填补。
df = df.fillna(method='pad')
异常值处理
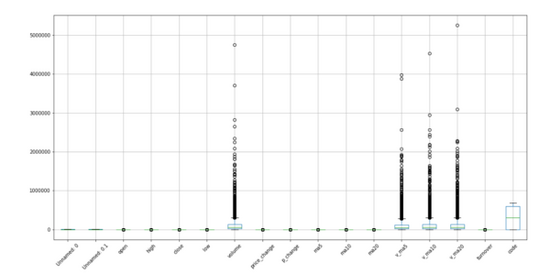
所谓异常值,就是在一个数字字段里出现一个或多个不合群得数字。举个例子,在一列都为个位数得数字列中出现了一个百位数的数字,这个百位数就是异常值。
用Python检测异常值有两种:箱线图图观察和标准差观察。这里我们选则箱体图观察。
箱线图是用于显示所选数据分散情况的统计图,通过设定标准,将大于或小于箱体图上下线的数值表示为异常点。
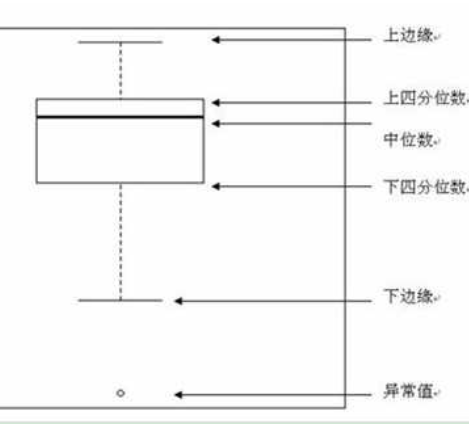
如图,下四分分位数指的是样本中有百分之25的数据小于这个数,记为。上四分分位数指的是样本中有百分之25大于这个数,记为。上四分位数和下四分位数的差值的1.5倍加上上四分位数就是上边缘,反之为下边缘。
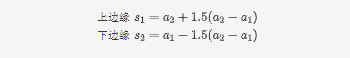
在Pandas中可以调用.boxplot()函数来画箱型图
import pandas as pd df.boxplot()
打包与效果展示
在写完全部代码之后,我们可以使用pyinstaller进行打包。
假定你的程序命名为yuchuli.py,在cmd窗口输入即可完成打包。
pyinstaller -F yuchuli.py
打包后,exe在Python文件所在文件夹的dist文件夹中。我们启动来看下效果
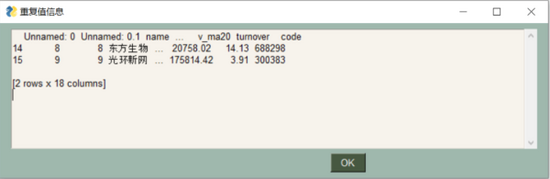
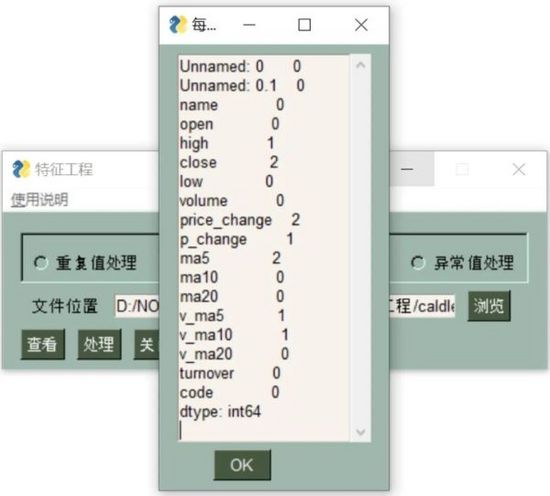
可以看到,我们需要的数据预处理的三个功能:重复值、缺失值、异常值都能按照指定方式进行处理!
当然你可以在本文提供的方法上,自己进行修改,来定制一款属于你自己平时习惯的数据预处理小软件!
到此这篇关于使用Python制作一个数据预处理小工具(多种操作一键完成)的文章就介绍到这了,更多相关Python数据预处理小工具内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python数据预处理方式 :数据降维
数据为何要降维 数据降维可以降低模型的计算量并减少模型运行时间.降低噪音变量信息对于模型结果的影响.便于通过可视化方式展示归约后的维度信息并减少数据存储空间.因此,大多数情况下,当我们面临高维数据时,都需要对数据做降维处理. 数据降维有两种方式:特征选择,维度转换 特征选择 特征选择指根据一定的规则和经验,直接在原有的维度中挑选一部分参与到计算和建模过程,用选择的特征代替所有特征,不改变原有特征,也不产生新的特征值. 特征选择的降维方式好处是可以保留原有维度特征的基础上进行降维,既能满足后续数据
-
python数据预处理之将类别数据转换为数值的方法
在进行python数据分析的时候,首先要进行数据预处理. 有时候不得不处理一些非数值类别的数据,嗯, 今天要说的就是面对这些数据该如何处理. 目前了解到的大概有三种方法: 1,通过LabelEncoder来进行快速的转换: 2,通过mapping方式,将类别映射为数值.不过这种方法适用范围有限: 3,通过get_dummies方法来转换. import pandas as pd from io import StringIO csv_data = '''A,B,C,D 1,2,3,4 5,6,,
-
python数据预处理之数据标准化的几种处理方式
何为标准化: 在数据分析之前,我们通常需要先将数据标准化(normalization),利用标准化后的数据进行数据分析.数据标准化也就是统计数据的指数化.数据标准化处理主要包括数据同趋化处理和无量纲化处理两个方面.数据同趋化处理主要解决不同性质数据问题,对不同性质指标直接加总不能正确反映不同作用力的综合结果,须先考虑改变逆指标数据性质,使所有指标对测评方案的作用力同趋化,再加总才能得出正确结果.数据无量纲化处理主要解决数据的可比性. 几种标准化方法: 归一化Max-Min min-max标准化方
-
Python----数据预处理代码实例
本文实例为大家分享了Python数据预处理的具体代码,供大家参考,具体内容如下 1.导入标准库 import numpy as np import matplotlib.pyplot as plt import pandas as pd 2.导入数据集 dataset = pd.read_csv('data (1).csv') # read_csv:读取csv文件 #创建一个包含所有自变量的矩阵,及因变量的向量 #iloc表示选取数据集的某行某列:逗号之前的表示行,之后的表示列:冒号表示选取全部
-
python实现数据预处理之填充缺失值的示例
1.给定一个数据集noise-data-1.txt,该数据集中保护大量的缺失值(空格.不完整值等).利用"全局常量"."均值或者中位数"来填充缺失值. noise-data-1.txt: 5.1 3.5 1.4 0.2 4.9 3 1.4 0.2 4.7 3.2 1.3 0.2 4.6 3.1 1.5 0.2 5 3.6 1.4 0.2 5.4 3.9 1.7 0.4 4.6 3.4 1.4 0.3 5 3.4 1.5 0.2 4.4 2.9 1.4 0.2 4.9
-
Python数据预处理之数据规范化(归一化)示例
本文实例讲述了Python数据预处理之数据规范化.分享给大家供大家参考,具体如下: 数据规范化 为了消除指标之间的量纲和取值范围差异的影响,需要进行标准化(归一化)处理,将数据按照比例进行缩放,使之落入一个特定的区域,便于进行综合分析. 数据规范化方法主要有: - 最小-最大规范化 - 零-均值规范化 数据示例 代码实现 #-*- coding: utf-8 -*- #数据规范化 import pandas as pd import numpy as np datafile = 'normali
-
python数据预处理 :样本分布不均的解决(过采样和欠采样)
何为样本分布不均: 样本分布不均衡就是指样本差异非常大,例如共1000条数据样本的数据集中,其中占有10条样本分类,其特征无论如何你和也无法实现完整特征值的覆盖,此时属于严重的样本分布不均衡. 为何要解决样本分布不均: 样本分部不均衡的数据集也是很常见的:比如恶意刷单.黄牛订单.信用卡欺诈.电力窃电.设备故障.大企业客户流失等. 样本不均衡将导致样本量少的分类所包含的特征过少,很难从中提取规律,即使得到分类模型,也容易产生过度依赖于有限的数量样本而导致过拟合问题,当模型应用到新的数据上时,模型的
-
使用Python制作一个数据预处理小工具(多种操作一键完成)
在我们平常使用Python进行数据处理与分析时,在import完一大堆库之后,就是对数据进行预览,查看数据是否出现了缺失值.重复值等异常情况,并进行处理. 本文将结合GUI工具PySimpleGUI,来讲解如何制作一款属于自己的数据预处理小工具,让这个过程也能够自动化!最终效果如下 本文将分为三部分讲解: 制作GUI界面 数据处理讲解 打包与测试 主要涉及将涉及以下模块: PySimpleGUI pandas matplotlib 一.GUI界面制作 思路 老规矩,先讲思路再上代码,首先还是说一
-
Python制作一个随机抽奖小工具的实现
目录 1. 核心功能设计 2. GUI设计与实现 3. 功能实现 3.1 读取人员名单 3.2. 随机抽奖 3.3. 保存中奖名单 3.4. GUI交互逻辑 最近在工作中面向社群玩家组织了一场活动,需要进行随机抽奖,参考之前小明大佬的案例,再结合自己的需求,做了一个简单的随机抽奖小工具. 今天我就来顺便介绍一下这个小工具的制作过程吧! 先看效果: 1. 核心功能设计 针对随机抽奖的小工具,需要可以导入参与抽奖的人员名单,然后选择不同的奖励类型进行随机抽取获奖名单并导出. 那么,简单进行需求拆解,
-
基于Python制作一个文件去重小工具
目录 前言 实现步骤 补充 前言 常常在下载网络素材时有很多的重复文件乱七八糟的,于是想实现一个去重的操作. 主要实现思路就是遍历出某个文件夹包括其子文件夹下面的所有文件,最后,将所有文件通过MD5函数的对比筛选出来,最后将重复的文件移除. 实现步骤 用到的第三方库都比较的常见,其中只有hashlib是用来对比文件的不是很常见.其他的都是一些比较常见的第三方库用来做辅助操作. import os # 应用文件操作 import hashlib # 文件对比操作 import logging #
-
使用Python制作一个打字训练小工具
一.写在前面 说道程序员,你会想到什么呢?有人认为程序员象征着高薪,有人认为程序员都是死肥宅,还有人想到的则是996和 ICU. 别人眼中的程序员:飞快的敲击键盘.酷炫的切换屏幕.各种看不懂的字符代码. 然而现实中的程序员呢?对于很多程序员来说,没有百度和 Google 解决不了的问题,也没有 ctrl + c 和 ctrl + v 实现不了的功能. 那么身为一个程序员,要怎么让自己看起来更加"专业"呢?答案就是加快自己的打字速度了,敲的代码可能是错的,但这个13却是必须装的! 然而还
-
如何基于Python制作有道翻译小工具
这篇文章主要介绍了如何基于Python制作有道翻译小工具,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 该工具主要是利用了爬虫,爬取web有道翻译的内容. 然后利用简易GUI来可视化结果. 首先我们进入有道词典的首页,并点击翻译结果的审查元素 之后request响应网页,并分析网页,定位到翻译结果. 使用tkinter来制作一个建议的GUI 期间遇到的一个问题则是如何刷新翻译的结果,否则的话会在text里一直累加翻译结果. 于是,在mainlo
-
基于Python写一个番茄钟小工具
目录 一.功能简述 二.使用到的主要模块 三.核心模块代码分析 1.番茄钟模块 2.音乐控制函数 3.main中的按钮部分 四.整体代码 一.功能简述 番茄钟即番茄工作法,番茄工作法是简单易行的时间管理工具,使用番茄工作法即一个番茄时间共30分钟,25分钟工作,5分钟休息: 特点一:番茄时长有三档 因为这个工具本人也是考虑到每个人情况不一样,不一定25分钟就适合自己,所以将番茄钟时长设为30min/45min/60min三档,自由选择 特点二:番茄统计功能 特点三:休息期间会自动播放放松音乐,当
-
python 制作一个gui界面的翻译工具
一.准备工作 除了Tkinter,还需要google_trans_new,没有安装这个库的朋友,可以使用 pip install google_trans_new 安装一下. 二.预览 1.主界面 2.翻译 3.支持多种语言哦 三.源代码 设计流程很简单,这里就直接贴代码了 3.1 My_Translator-v2.0.py from tkinter import * from tkinter import messagebox from tkinter import ttk import py
-
详解使用Python写一个向数据库填充数据的小工具(推荐)
一. 背景 公司又要做一个新项目,是一个合作型项目,我们公司出web展示服务,合作伙伴线下提供展示数据. 而且本次项目是数据统计展示为主要功能,并没有研发对应的数据接入接口,所有展示数据源均来自数据库查询, 所以验证数据没有别的入口,只能通过在数据库写入数据来进行验证. 二. 工具 Python+mysql 三.前期准备 前置:当然是要先准备好测试方案和测试用例,在准备好这些后才能目标明确将要开发自动化小工具都要有哪些功能,避免走弯路 3.1 跟开发沟通 1)确认数据库连接方式,库名 : 2)测
-
基于PyQt5制作Excel文件数据去重小工具
需求说明:将单个或者多个Excel文件数据进行去重操作,去重的列可以通过自定义制定. 开始源码说明之前,先说明一下工具的使用过程. 1.准备需要去重的数据文件. 2.使用工具执行去重操作. 3.处理完成后的结果文件. PyQt5 界面UI相关的模块引用 from PyQt5.QtWidgets import * from PyQt5.QtGui import * 核心组件 from PyQt5.QtCore import * 主题样式模块引用 from QCandyUi import Candy
-
基于Python制作一个多进制转换工具
目录 前言 主要步骤 完整代码 前言 学习资料下载链接 提取码:tha8 进制转换计算工具含源文件 主要步骤 导入模块 import tkinter from tkinter import * import tkinter as tk from tkinter.ttk import * 整个框架的主结构 root = Tk() root.title('贱工坊-进制转换计算') # 程序的标题名称 root.geometry("580x400+512+288") # 窗口的大小及页面的