使用pandas计算环比和同比的方法实例
目录
- 前言
- 1.数据准备
- 2.环比计算
- 3.同比计算
- 4.关于pct_change()函数
- 5.后记
前言
在进行业务数据分析时,往往需要使用pandas计算环比、同比及增长率等指标,为了能够更加方便的进行的统计数据,整理方法如下。
1.数据准备
为方便进行演示,此处提前生成需要进行统计的数据,数据已经是按照时间维度进行排序。
months = pd.date_range(start='2010-01-01', end='2020-12-31', freq='M')
test_df = pd.DataFrame({'month': months,
'v': 100*np.random.rand(months.shape[0], 1).reshape(months.shape[0])})
2.环比计算
2.1 方法1
test_df['v_last']=test_df['v'].shift(1) test_df['month_erlier_1']=test_df['v']/test_df['v_last']-1
2.2 方法2
test_df['m_m_diff']=test_df['v'].diff() test_df['month_erlier_2']=test_df['m_m_diff']/test_df['v'].shift(1)
2.3 方法3
test_df['month_erlier_3']=test_df['v'].pct_change()
3.同比计算
继续使用上述构建的数据源进行计算。
3.1 方法1
test_df["last_year_v"]=test_df['v'].shift(12) test_df['year_erlier_1']=test_df['v']/test_df['last_year_v']-12
3.2 方法2
test_df["year_diff"]=test_df['v'].diff(12) test_df['year_diff'].fillna(0,inplace=True) test_df['year_erlier_2']=test_df['year_diff']/(test_df['v']-test_df['year_diff'])
3.3 方法3
test_df['year_erlier_3']=test_df["v"].pct_change(periods=12)
4.关于pct_change()函数
pct_change主要涉及一下参数:
- periods=1,用来设置计算的周期。
- fill_method=‘pad’,如何在计算百分比变化之前处理缺失值(NA)。
- limit=None,设置停止填充条件,即当遇到填充的连续缺失值的数量n时,停止此处填充
- freq=None,从时间序列 API 中使用的增量(例如 ‘M’ 或 BDay())
4.1 使用例子1
#构建数据
months = pd.date_range(start='2020-01-01', end='2020-12-31', freq='M')
test_df2 = pd.DataFrame({'month': months,
'v': 100*np.random.rand(months.shape[0], 1).reshape(months.shape[0])})
test_df2.loc[((test_df2.index>5) & (test_df2.index<9) ),'v']=np.nan
test_df2.loc[test_df2.index==3,'v']=np.nan
test_df2.loc[test_df2.index==10,'v']=np.nan
数据展示:
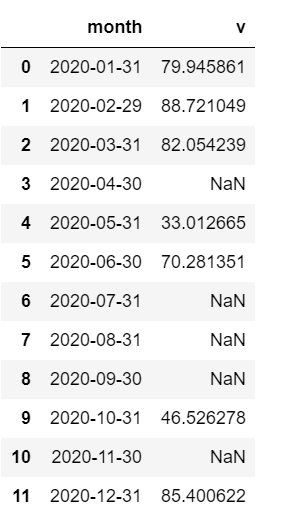
计算环比:
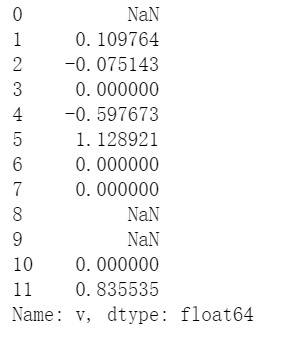
#向下进行填充,当连续缺失值的数量大于2时不进行填充 test_df2['v'].pct_change(1,fill_method='ffill',limit=2)
计算效果图:
4.2 使用例子2
# 生成样本数据
test_df3 = pd.DataFrame({'2020': 100*np.random.rand(5).reshape(5),
'2019': 100*np.random.rand(5).reshape(5),
'2018': 100*np.random.rand(5).reshape(5)})
样本数据截图:
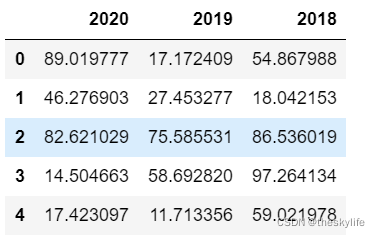
计算同环比:
test_df3.pct_change(axis='columns',periods=-1)
计算效果截图:

4.3 使用例子3
#构建数据样本
months = pd.date_range(start='2020-01-01', end='2020-12-31', freq='M')
test_df4 = pd.DataFrame({
'v': 100*np.random.rand(months.shape[0], 1).reshape(months.shape[0])}, index=months)
数据样本截图:
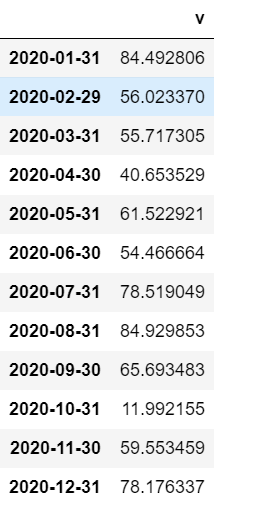
计算季度末环比:
test_df4["v"].pct_change(freq="Q")
计算效果图:

计算过程解释:
2020-03-31行处的值:使用3月份和1月份进行环比,即55.717305/84.492806-1
2020-06-30行处的值:使用6月份和3月份进行环比
计算环比增长
方法一:
for i in range(0,len(data)):
if i == 0:
data['huanbi'][i] = 'null'
else:
data['huanbi'][i] = format((data['mony'][i] - data['mony'][i-1])/data['mony'][i-1],'.2%')
#format(res,'.2%') 小数格式化为百分数
方法二:
使用diff(periods=1, axis=0)) 一阶差分函数
periods:移动的幅度 默认值为1
axis:移动的方向,{0 or ‘index’, 1 or ‘columns’},如果为0或者’index’,则上下移动,如果为1或者’columns’,则左右移动。默认列向移动
data['huanbi_1'] = data.mony.diff()
方法三:
使用pct_change()
data['huanbi_1'] = data.mony.pct_change() data.fillna(0,inplace=True)
计算同比增长
使用一阶差分函数diff()
data['tongbi_shu'] = data.mony.diff(12) data.fillna(0,inplace=True) data['tongbi'] = data['tongbi_shu']/(data['mony'] - data['tongbi_shu']) ``
5.后记
以上就是时候用pandas进行计算同比和环比的方法,请在使用过程中,结合数据情况先进行数据清洗后,再选择合适的方法进行计算。
到此这篇关于使用pandas计算环比和同比的文章就介绍到这了,更多相关pandas计算环比和同比内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python 使用pandas计算累积求和的方法
使用pandas下的cumsum函数 cumsum:计算轴向元素累积加和,返回由中间结果组成的数组.重点就是返回值是"由中间结果组成的数组" import numpy as np ''' arr是一个2*2*3三维矩阵,索引值为0,1,2 cumsum(0):实现0轴上的累加:以最外面的数组元素为单位,以[[1,2,3],[8,9,12]]为开始实现后面元素的对应累加 cumsum(1):实现1轴上的累加:以中间数组元素为单位,以[1,2,3]为开始,实现后面元素的对应累加 cumsu
-

Python科学计算之Pandas详解
起步 Pandas最初被作为金融数据分析工具而开发出来,因此 pandas 为时间序列分析提供了很好的支持. Pandas 的名称来自于面板数据(panel data)和python数据分析 (data analysis) .panel data是经济学中关于多维数据集的一个术语,在Pandas中也提供了panel的数据类型. 在我看来,对于 Numpy 以及 Matplotlib ,Pandas可以帮助创建一个非常牢固的用于数据挖掘与分析的基础.而Scipy当然是另一个主要的也十分出色的科学计
-
使用pandas计算环比和同比的方法实例
目录 前言 1.数据准备 2.环比计算 3.同比计算 4.关于pct_change()函数 5.后记 前言 在进行业务数据分析时,往往需要使用pandas计算环比.同比及增长率等指标,为了能够更加方便的进行的统计数据,整理方法如下. 1.数据准备 为方便进行演示,此处提前生成需要进行统计的数据,数据已经是按照时间维度进行排序. months = pd.date_range(start='2010-01-01', end='2020-12-31', freq='M') test_df = pd.D
-
Pandas修改DataFrame列名的两种方法实例
目录 解决方法1:通过DataFrame.columns类的自身属性修改 1.暴力修改 2.stirp方法 3.lambda表达式 解决方法2:通过DataFrame.rename()函数修改 1.暴力修改(可以只修改部分列名) 2.lambda表达式 pandas更改DataFrame的行名或列名实例 更改列名 更改行名 总结 输入: $a $b $c $d $e 0 1 2 3 4 5 期望的输出: a b c d e0 1 2 3 4 5 原数据DataFrame: im
-
Python pandas删除指定行/列数据的方法实例
目录 1.滤除缺失数据dropna() 1)滤除含有NaN值的所有行 2)滤除含有NaN值的所有列 3)滤除元素都是NaN值的行 4)滤除元素都是NaN值的列 5)滤除指定列中含有缺失的行 2.删除重复值 drop_duplicates() 1)keep=“first” 2)keep=“last” 3)keep=False 4)删除指定列中重复项对应的行 3.根据指定条件删除行列drop() 1).删除指定列 2).删除指定行 总结 1.滤除缺失数据dropna() import pandas
-
在Pandas DataFrame中插入一列的方法实例
目录 引言 示例1:插入新列作为第一列 示例2:插入新列作为中间列 示例3:插入新列作为最后一列 补充:按条件选择分组分别赋值 总结 引言 通常,您可能希望在 Pandas DataFrame 中插入一个新列.幸运的是,使用 pandas insert()函数很容易做到这一点,该函数使用以下语法: insert(loc, column, value, allow_duplicates=False) 在哪里: loc: 插入列的索引.第一列是 0. column: 赋予新列的名称. value:
-
Python利用pandas计算多个CSV文件数据值的实例
功能:扫描当前目录下所有CSV文件并对其中文件进行统计,输出统计值到CSV文件 pip install pandas import pandas as pd import glob,os,sys input_path='./' output_fiel='pandas_union_concat.csv' all_files=glob.glob(os.path.join(input_path,'sales_*')) all_data_frames=[] for file in all_files:
-
pandas计算最大连续间隔的方法
如下所示: 群里一朋友发了一个如上图的问题,解决方法如下 data = {'a':[1,1,1,1,1,1,1,1,2,2,2,2,2,2,2,2,2],'b':[1,2,3,4,5,8,9,10,1,2,3,6,7,8,9,12,13]} df = pd.DataFrame(data) for name,group in df.groupby('a'): group['c'] = ((group['b'].shift(1).fillna(0) + 1).astype(int) != group
-
python判断单向链表是否包括环,若包含则计算环入口的节点实例分析
本文实例讲述了python判断单向链表是否包括环,若包含则计算环入口的节点.分享给大家供大家参考,具体如下: 关于数据结构相关的面试题,经常会问到链表中是否存在环结构的判断,下图就是存在环结构的链表. 那么如何判断链表中是否存在环呢,下面解法的思路是采用快慢指针: 两个指向头节点的指针,fast和slow,一起从头结点开始往后遍历,fast每次移动两个节点,slow每次移动一个节点, 这样,如果存在环结构,那么fast指针在不断绕环过程中,肯定会追上slow指针. # -*- coding:ut
-
Python pandas 计算每行的增长率与累计增长率
读取数据: FacebookDf=pd.read_excel(r'D:\jupyter\Untitled Folder\Facebook2017年股票数据.xlsx',index_col='Date') FacebookDf.tail() 计算当前行比上一行增长的百分比(每行的增长率) # .pct_change()返回变化百分比,第一行因没有可对比的,返回Nan,填充为0 # apply(lambda x: format(x, '.2%'))将小数点转换为百分数 FacebookDf['pct
-
Pandas 计算相关性系数corr()方式
目录 Pandas 计算相关性系数corr() 相关:数据之间有关联,相互有影响 相关性系数:衡量相关性强弱的 构造如下数据 pandas相关系数-DataFrame.corr()参数 参数说明 Pandas 计算相关性系数corr() 相关:数据之间有关联,相互有影响 如:A和B 存在一定的相关性,A对B存在一定程度的影响,A变化,B也会有一定的变化 如果A和B相等 或者 B可以由A经过计算得到---->完全相关 如果B是由 A和C计算得到 ---->并且 A可以计算出B的大部分 -----