Python机器学习应用之决策树分类实例详解
目录
- 一、数据集
- 二、实现过程
- 1 数据特征分析
- 2 利用决策树模型在二分类上进行训练和预测
- 3 利用决策树模型在多分类(三分类)上进行训练与预测
- 三、KEYS
- 1 构建过程
- 2 划分选择
- 3 重要参数
一、数据集
该数据集一共包含8个变量,其中7个特征变量,1个目标分类变量。共有150个样本,目标变量为 企鹅的类别 其都属于企鹅类的三个亚属,分别是(Adélie, Chinstrap and Gentoo)。包含的三种种企鹅的七个特征,分别是所在岛屿,嘴巴长度,嘴巴深度,脚蹼长度,身体体积,性别以及年龄。
二、实现过程
1 数据特征分析
## 基础函数库
import numpy as np
import pandas as pd
## 绘图函数库
import matplotlib.pyplot as plt
import seaborn as sns
#%%读入数据
#利用Pandas自带的read_csv函数读取并转化为DataFrame格式
data = pd.read_csv('D:\Python\ML\data\penguins_raw.csv')
#我选取了四个简单的特征进行研究
data = data[['Species','Culmen Length (mm)','Culmen Depth (mm)',
'Flipper Length (mm)','Body Mass (g)']]
data.info()
#查看数据
print(data.head())
#发现数据中存在的NAN,缺失值此处使用-1将缺失值进行填充
data=data.fillna(-1)
print(data.tail())
#查看对应标签
print(data['Species'].unique())
#统计每个类别的数量
print(pd.Series(data['Species']).value_counts())
#对特征进行统一描述
print(data.describe())
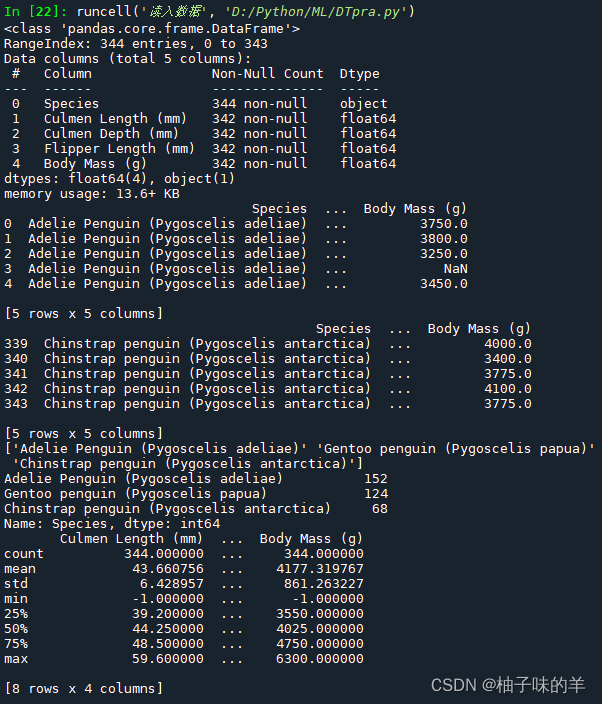
#可视化描述
sns.pairplot(data=data,diag_kind='hist',hue='Species')
plt.show()
#%%为了方便处理,将标签数字化
# 'Adelie Penguin (Pygoscelis adeliae)' ------0
# 'Gentoo penguin (Pygoscelis papua)' ------1
# 'Chinstrap penguin (Pygoscelis antarctica) ------2
def trans(x):
if x == data['Species'].unique()[0]:
return 0
if x == data['Species'].unique()[1]:
return 1
if x == data['Species'].unique()[2]:
return 2
data['Species'] = data['Species'].apply(trans)
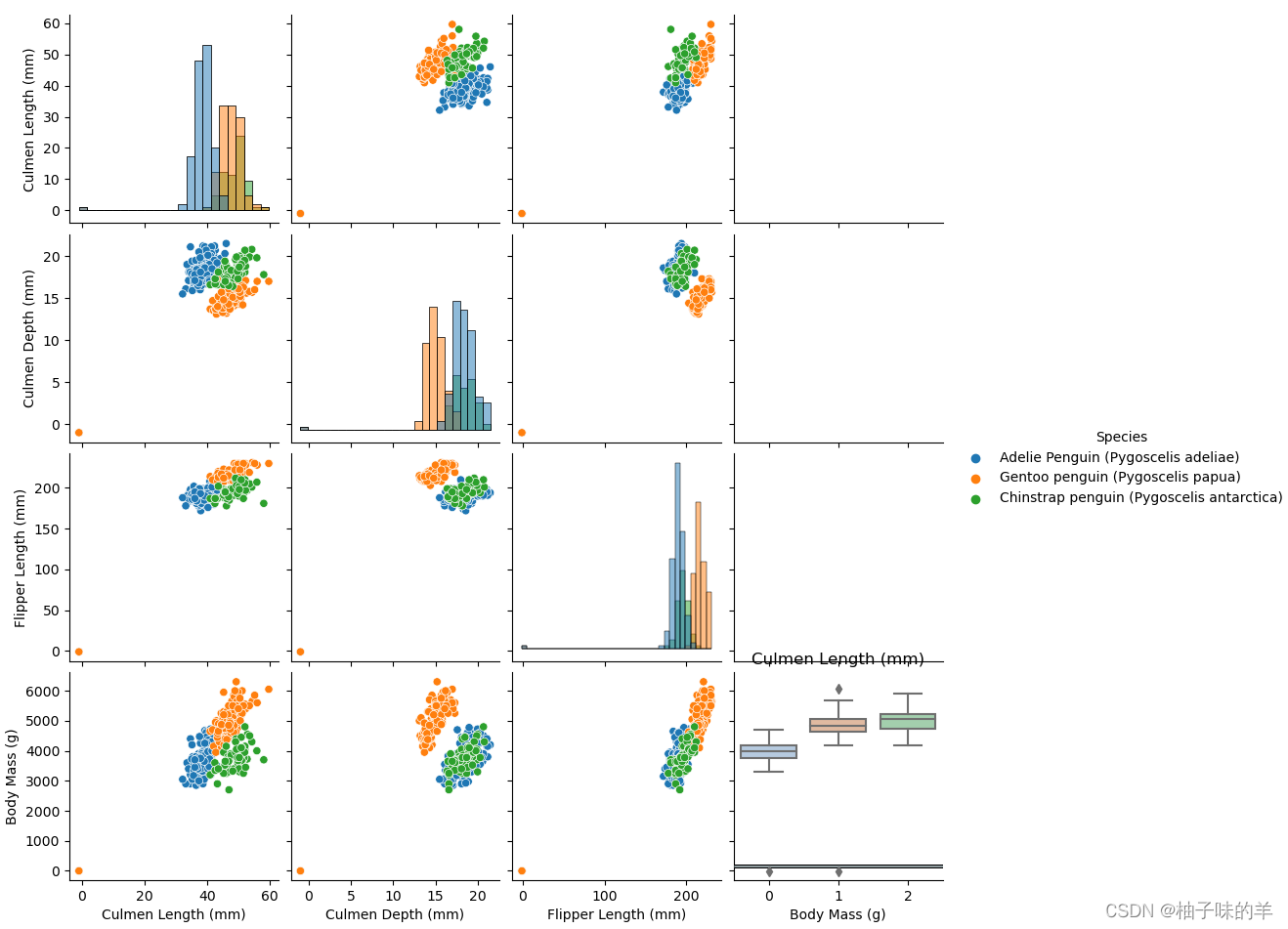
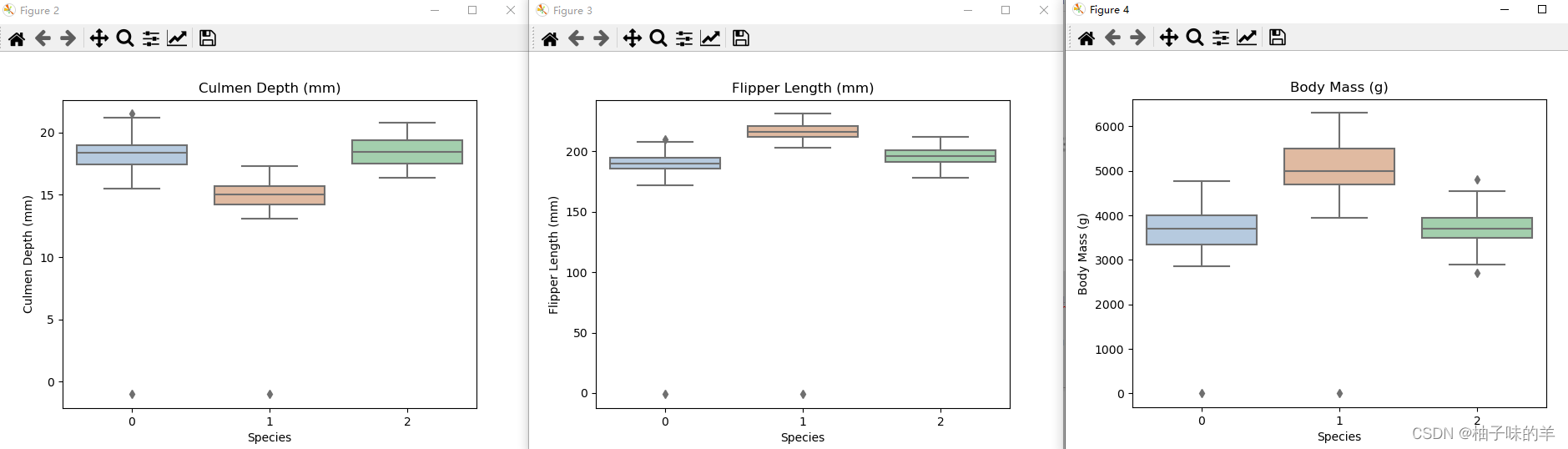
#利用箱图得到不同类别在不同特征上的分布差异
for col in data.columns:
if col != 'Species':
sns.boxplot(x='Species', y=col, saturation=0.5, palette='pastel', data=data)
plt.title(col)
plt.show()
plt.figure()
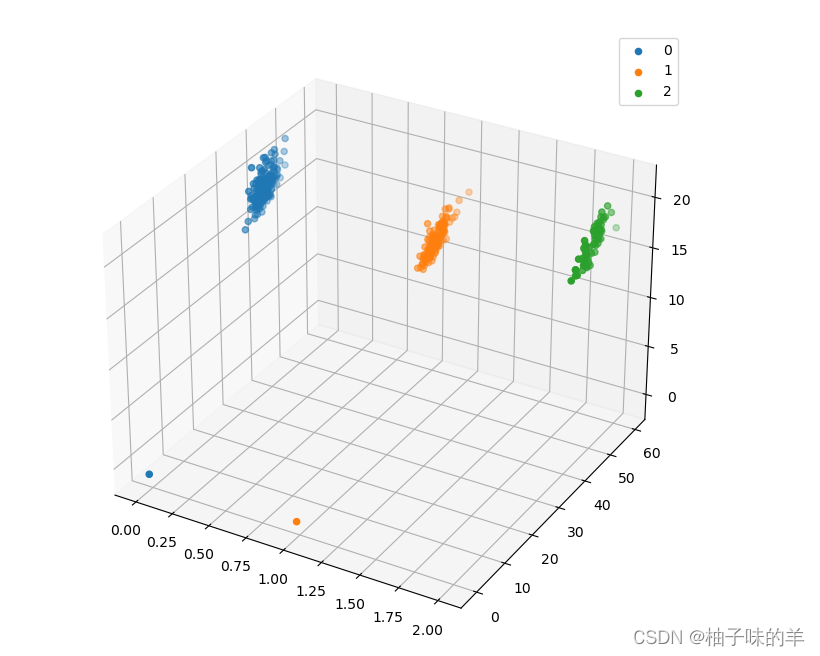
#%%选取species,culmen_length和culmen_depth三个特征绘制三维散点图
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(10,8))
ax = fig.add_subplot(111, projection='3d')
data_class0 = data[data['Species']==0].values
data_class1 = data[data['Species']==1].values
data_class2 = data[data['Species']==2].values
# 'setosa'(0), 'versicolor'(1), 'virginica'(2)
ax.scatter(data_class0[:,0], data_class0[:,1], data_class0[:,2],label=data['Species'].unique()[0])
ax.scatter(data_class1[:,0], data_class1[:,1], data_class1[:,2],label=data['Species'].unique()[1])
ax.scatter(data_class2[:,0], data_class2[:,1], data_class2[:,2],label=data['Species'].unique()[2])
plt.legend()
plt.show()
运行结果
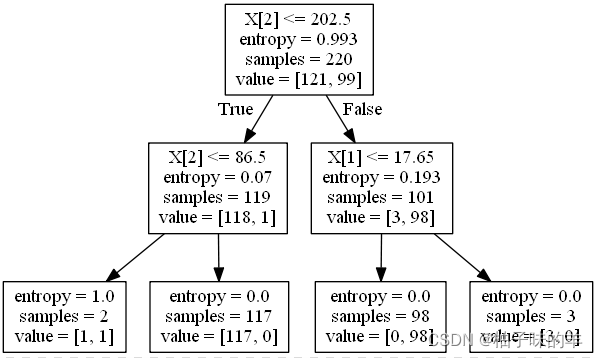
2 利用决策树模型在二分类上进行训练和预测
#%%利用决策树模型在二分类上进行训练和预测——选取0和1两类样本,样本选取其中的四个特征
## 为了正确评估模型性能,将数据划分为训练集和测试集,并在训练集上训练模型,在测试集上验证模型性能。
from sklearn.model_selection import train_test_split
data_target_part = data[data['Species'].isin([0,1])][['Species']]
data_features_part = data[data['Species'].isin([0,1])][['Culmen Length (mm)','Culmen Depth (mm)',
'Flipper Length (mm)','Body Mass (g)']]
## 测试集大小为20%, 80%/20%分
x_train, x_test, y_train, y_test = train_test_split(
data_features_part, data_target_part, test_size = 0.2, random_state = 2020)
## 从sklearn中导入决策树模型
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
## 定义 决策树模型
clf = DecisionTreeClassifier(criterion='entropy')
# 在训练集上训练决策树模型
clf.fit(x_train, y_train)
#%% 可视化决策树
import pydotplus
dot_data = tree.export_graphviz(clf, out_file=None)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_png("D:\Python\ML\DTpraTree.png")
#%% 在训练集和测试集上利用训练好的模型进行预测
train_predict = clf.predict(x_train)
test_predict = clf.predict(x_test)
from sklearn import metrics
## 利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果
print('The accuracy of the train_DecisionTree is:',metrics.accuracy_score(y_train,train_predict))
print('The accuracy of the test_DecisionTree is:',metrics.accuracy_score(y_test,test_predict))
## 查看混淆矩阵 (预测值和真实值的各类情况统计矩阵)
confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test)
print('The confusion matrix result:\n',confusion_matrix_result)
# 利用热力图对于结果进行可视化
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues')
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()
运行结果


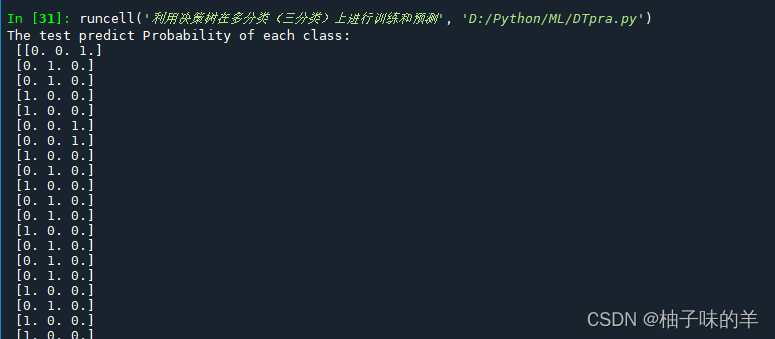
3 利用决策树模型在多分类(三分类)上进行训练与预测
#%%利用决策树在多分类(三分类)上进行训练和预测
## 测试集大小为20%, 80%/20%分
x_train, x_test, y_train, y_test = train_test_split(data[['Culmen Length (mm)','Culmen Depth (mm)',
'Flipper Length (mm)','Body Mass (g)']], data[['Species']], test_size = 0.2, random_state = 2020)
## 定义 决策树模型
clf = DecisionTreeClassifier()
# 在训练集上训练决策树模型
clf.fit(x_train, y_train)
## 在训练集和测试集上分布利用训练好的模型进行预测
train_predict = clf.predict(x_train)
test_predict = clf.predict(x_test)
train_predict_proba = clf.predict_proba(x_train)
test_predict_proba = clf.predict_proba(x_test)
print('The test predict Probability of each class:\n',test_predict_proba)
## 其中第一列代表预测为0类的概率,第二列代表预测为1类的概率,第三列代表预测为2类的概率。
## 利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果
print('The accuracy of the train_DecisionTree is:',metrics.accuracy_score(y_train,train_predict))
print('The accuracy of the test_DecisionTree is:',metrics.accuracy_score(y_test,test_predict))
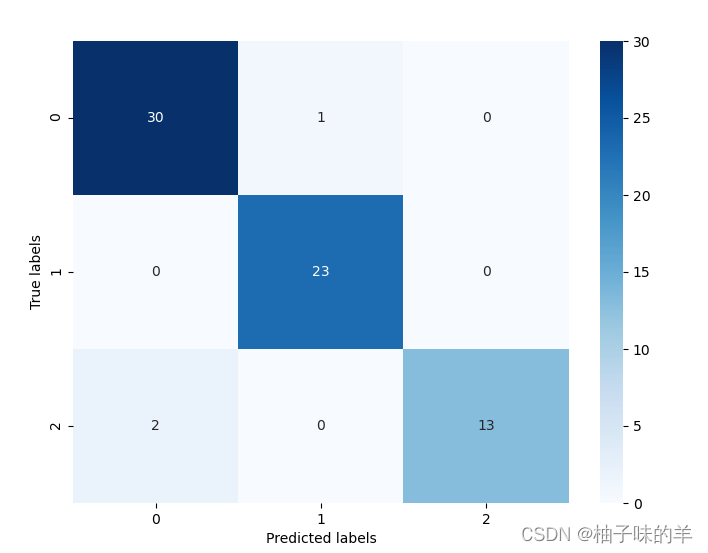
## 查看混淆矩阵 (预测值和真实值的各类情况统计矩阵)
confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test)
print('The confusion matrix result:\n',confusion_matrix_result)
# 利用热力图对于结果进行可视化
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues')
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()
运行结果

三、KEYS
1 构建过程
决策树的构建过程是一个递归的过程,函数存在三种返回状态:
- 当前节点包含的样本全部属于同一类别,无需继续划分
- 当前属性集为空或者所有样本在某个属性上的取值相同,无法继续划分
- 当前节点包含的样本几何为空,无法划分
2 划分选择
决策树构建的关键是从特征集中选择最优划分属性,一般大家希望决策树每次划分节点中包含的样本尽量属于同一类别,也就是节点的“纯度”最高
- 信息熵:衡量数据混乱程度的指标,信息熵越小,数据的“纯度”越高
- 基尼指数:反应了从数据集中随机抽取两个类别的标记不一致的概率
3 重要参数
- criterion:用来决定模型特征选择的计算方法,sklearn提供两种方法:
entropy:使用信息熵
gini:使用基尼系数
- random_state&splitte:
random_state用于设置分支的随机模式的参数
splitter用来控制决策树中的随机选项
- max_depth:限制数的深度
- min_samples_leaf:一个节点在分支之后的每个子节点都必须包含至少几个训练样本。该参数设置太小,会出现过拟合现象,设置太大会阻止模型学习数据
886~~
到此这篇关于Python机器学习应用之决策树分类实例详解的文章就介绍到这了,更多相关Python 决策树分类实例内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python机器学习应用之支持向量机的分类预测篇
目录 1.Question? 2.Answer!——SVM 3.软间隔 4.超平面 支持向量机常用于数据分类,也可以用于数据的回归预测 1.Question? 我们经常会遇到这样的问题,给你一些属于两个类别的数据(如子图1),需要一个线性分类器将这些数据分开,有很多分法(如子图2),现在有一个问题,两个分类器,哪一个更好?为了判断好坏,我们需要引入一个准则:好的分类器不仅仅能够很好的分开已有的数据集,还能对为知的数据进行两个划分,假设现在有一个属于红色数据点的新数据(如子图3中的绿三角),可以看
-
在Python中通过机器学习实现人体姿势估计
目录 什么是姿态估计? 2D 与 3D 姿态估计 为姿态估计准备数据集 创建姿势估计模型 模型结果 结论 姿态检测是计算机视觉领域的一个活跃研究领域.你可以从字面上找到数百篇研究论文和几个试图解决姿势检测问题的模型. 之所以有如此多的机器学习爱好者被姿势估计所吸引,是因为它的应用范围很广,而且实用性很强. 在本文中,我们将介绍一种使用机器学习和 Python 中一些非常有用的库进行姿势检测和估计的应用. 什么是姿态估计? 姿态估计是一种跟踪人或物体运动的计算机视觉技术.这通常通过查找给定对象的关
-
Python DPED机器学习之实现照片美化
目录 前言 环境部署 项目结构 tensorflow安装 其他依赖安装 VGG-19下载 项目运行 准备图片素材 测试效果 前言 最近发现了一个可以把照片美化的项目,自己玩了玩,挺有意思的,分享一下. Github地址:DPED项目地址 下面来看看项目怎么玩?先放一些项目给出的效果图.可以看出照片更明亮好看了. 环境部署 项目结构 下面是项目的原始结构: tensorflow安装 按照项目的说明,我们需要安装tensorflow以及一些必要的库. 如果安装gpu版本的tensorflow需要对照
-
Python机器学习应用之基于决策树算法的分类预测篇
目录 一.决策树的特点 1.优点 2.缺点 二.决策树的适用场景 三.demo 一.决策树的特点 1.优点 具有很好的解释性,模型可以生成可以理解的规则. 可以发现特征的重要程度. 模型的计算复杂度较低. 2.缺点 模型容易过拟合,需要采用减枝技术处理. 不能很好利用连续型特征. 预测能力有限,无法达到其他强监督模型效果. 方差较高,数据分布的轻微改变很容易造成树结构完全不同. 二.决策树的适用场景 决策树模型多用于处理自变量与因变量是非线性的关系. 梯度提升树(GBDT),XGBoost以及L
-
Python OpenCV实战之与机器学习的碰撞
目录 0. 前言 1. 机器学习简介 1.1 监督学习 1.2 无监督学习 1.3 半监督学习 2. K均值 (K-Means) 聚类 2.1 K-Means 聚类示例 3. K最近邻 3.1 K最近邻示例 4. 支持向量机 4.1 支持向量机示例 小结 0. 前言 机器学习是人工智能的子集,它为计算机以及其它具有计算能力的系统提供自动预测或决策的能力,诸如虚拟助理.车牌识别系统.智能推荐系统等机器学习应用程序给我们的日常生活带来了便捷的体验.机器学习的蓬勃发展,得益于以下三个关键因素:1) 海
-
Python机器学习之手写KNN算法预测城市空气质量
目录 一.KNN算法简介 二.KNN算法实现思路 三.KNN算法预测城市空气质量 1. 获取数据 2. 生成测试集和训练集 3. 实现KNN算法 一.KNN算法简介 KNN(K-Nearest Neighbor)最邻近分类算法是数据挖掘分类(classification)技术中常用算法之一,其指导思想是"近朱者赤,近墨者黑",即由你的邻居来推断出你的类别. KNN最邻近分类算法的实现原理:为了判断未知样本的类别,以所有已知类别的样本作为参照,计算未知样本与所有已知样本的距离,从中选取与
-
Python机器学习之实现模糊照片人脸恢复清晰
目录 前言 环境安装 验证模型 总结 前言 最近看到一个有意思的机器学习项目--GFPGAN,他可以将模糊的人脸照片恢复清晰.开源项目的Github地址:https://github.com/TencentARC/GFPGAN 我们看一看作者给出的对比图. 最右侧的就是GFPGAN的效果,看一下最左层的输入图片,可以发现GFPGAN将图片恢复的非常清晰.这个效果非常惊艳. 按照以前的惯例,我还是先把这个项目安装使用一下,看看能不能对代码重新封装,变成可以工程化的项目. 环境安装 我们先看一下项目
-
Python机器学习应用之朴素贝叶斯篇
朴素贝叶斯(Naive Bayes,NB):朴素贝叶斯分类算法是学习效率和分类效果较好的分类器之一.朴素贝叶斯算法一般应用在文本分类,垃圾邮件的分类,信用评估,钓鱼网站检测等. 1.鸢尾花案例 #%%库函数导入 import warnings warnings.filterwarnings('ignore') import numpy as np # 加载莺尾花数据集 from sklearn import datasets # 导入高斯朴素贝叶斯分类器 from sklearn.naive_b
-
Python机器学习应用之决策树分类实例详解
目录 一.数据集 二.实现过程 1 数据特征分析 2 利用决策树模型在二分类上进行训练和预测 3 利用决策树模型在多分类(三分类)上进行训练与预测 三.KEYS 1 构建过程 2 划分选择 3 重要参数 一.数据集 小企鹅数据集,提取码:1234 该数据集一共包含8个变量,其中7个特征变量,1个目标分类变量.共有150个样本,目标变量为 企鹅的类别 其都属于企鹅类的三个亚属,分别是(Adélie, Chinstrap and Gentoo).包含的三种种企鹅的七个特征,分别是所在岛屿,嘴巴长度,
-
python机器学习算法与数据降维分析详解
目录 一.数据降维 1.特征选择 2.主成分分析(PCA) 3.降维方法使用流程 二.机器学习开发流程 1.机器学习算法分类 2.机器学习开发流程 三.转换器与估计器 1.转换器 2.估计器 一.数据降维 机器学习中的维度就是特征的数量,降维即减少特征数量.降维方式有:特征选择.主成分分析. 1.特征选择 当出现以下情况时,可选择该方式降维: ①冗余:部分特征的相关度高,容易消耗计算性能 ②噪声:部分特征对预测结果有影响 特征选择主要方法:过滤式(VarianceThreshold).嵌入式(正
-
python人工智能算法之决策树流程示例详解
目录 决策树 总结 决策树 是一种将数据集通过分割成小的.易于处理的子集来进行分类或回归的算法.其中每个节点代表一个用于划分数据的特征,每个叶子节点代表一个类别或一个预测值.构建决策树时,算法会选择最好的特征进行分割数据,使每个子集中的数据尽可能的归属同一类或具有相似的特征.这个过程会不断重复,类似于Java中的递归,直到达到停止条件(例如叶子节点数目达到一个预设值),形成一棵完整的决策树.它适合于处理分类和回归任务.而在人工智能领域,决策树也是一种经典的算法,具有广泛的应用. 接下来简单介绍下
-
python机器学习Sklearn实战adaboost算法示例详解
目录 pandas批量处理体测成绩 adaboost adaboost原理案例举例 弱分类器合并成强分类器 pandas批量处理体测成绩 import numpy as np import pandas as pd from pandas import Series,DataFrame import matplotlib.pyplot as plt data = pd.read_excel("/Users/zhucan/Desktop/18级高一体测成绩汇总.xls") cond =
-
python之sqlalchemy创建表的实例详解
python之sqlalchemy创建表的实例详解 通过sqlalchemy创建表需要三要素:引擎,基类,元素 from sqlalchemy import create_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column,Integer,String 引擎:也就是实体数据库连接 engine = create_engine('mysql+pymysql://go
-
python获取指定时间差的时间实例详解
python获取指定时间差的时间实例详解 在分析数据的时间经常需要截取一定范围时间的数据,比如三天之内,两小时前等等时间要求的数据,因此将该部分经常需要用到的功能模块化,方便以后以后用到的时候复用.在此,也分享给大家. import time import sys reload(sys) def get_day_of_day(UTC=False, days=0, hours=0, miutes=0, seconds=0): ''''''' if days>=0,date is larger th
-
Python使用struct处理二进制的实例详解
Python使用struct处理二进制的实例详解 有的时候需要用python处理二进制数据,比如,存取文件,socket操作时.这时候,可以使用python的struct模块来完成.可以用 struct来处理c语言中的结构体. struct模块中最重要的三个函数是pack(), unpack(), calcsize() pack(fmt, v1, v2, ...) 按照给定的格式(fmt),把数据封装成字符串(实际上是类似于c结构体的字节流) unpack(fmt, string)
-
python 中split 和 strip的实例详解
python 中split 和 strip的实例详解 一直以来都分不清楚strip和split的功能,实际上strip是删除的意思:而split则是分割的意思. python中strip() 函数和 split() 函数的理解,有需要的朋友可以参考下. splite 和strip 都是Python 对字符串的处理. splite 意为分割,划分. a='123456' a.split('3') 输出为 ['12', '456'] 可以看到,使用何种字符切割,该字符也被略去.例如这里的字符"3&
-
使用ThinkPHP的自动完成实现无限级分类实例详解
一.实现效果 二.主要代码 1.模板 2.控制器 ·index模块 ·add模块 3.模型 三.代码 以便于各位看官复制测试 1.模板 <form action="__URL__/add" method="post"> 栏目<select name="fid" size=20> <option value="0">栏目</option> <volist name='list
-
python生成二维码的实例详解
python生成二维码的实例详解 版本相关 操作系统:Mac OS X EI Caption Python版本:2.7 IDE:Sublime Text 3 依赖库 Python生成二维码需要的依赖库为PIL和QRcode. 坑爹的是,百度了好久都没有找到PIL,不知道是什么时候改名了,还是其他原因,pillow就是传说中的PIL. 安装命令:sudo pip install pillow.sudo pip install qrcode 验证是否安装成功,使用命令from PIL import