Python机器学习应用之基于线性判别模型的分类篇详解
目录
- 一、Introduction
- 1 LDA的优点
- 2 LDA的缺点
- 3 LDA在模式识别领域与自然语言处理领域的区别
- 二、Demo
- 三、基于LDA 手写数字的分类
- 四、小结
一、Introduction
线性判别模型(LDA)在模式识别领域(比如人脸识别等图形图像识别领域)中有非常广泛的应用。LDA是一种监督学习的降维技术,也就是说它的数据集的每个样本是有类别输出的。这点和PCA不同。PCA是不考虑样本类别输出的无监督降维技术。 LDA的思想可以用一句话概括,就是“投影后类内方差最小,类间方差最大”。我们要将数据在低维度上进行投影,投影后希望每一种类别数据的投影点尽可能的接近,而不同类别的数据的类别中心之间的距离尽可能的大。即:将数据投影到维度更低的空间中,使得投影后的点,会形成按类别区分,一簇一簇的情况,相同类别的点,将会在投影后的空间中更接近方法。
1 LDA的优点
- 在降维过程中可以使用类别的先验知识经验,而像PCA这样的无监督学习则无法使用类别先验知识;
- LDA在样本分类信息依赖均值而不是方差的时候,比PCA之类的算法较优
2 LDA的缺点
- LDA不适合对非高斯分布样本进行降维,PCA也有这个问题
- LDA降维最多降到类别数 k-1 的维数,如果我们降维的维度大于 k-1,则不能使用 LDA。当然目前有一些LDA的进化版算法可以绕过这个问题
- LDA在样本分类信息依赖方差而不是均值的时候,降维效果不好
- LDA可能过度拟合数据
3 LDA在模式识别领域与自然语言处理领域的区别
在自然语言处理领域,LDA是隐含狄利克雷分布,它是一种处理文档的主题模型。本文讨论的是线性判别分析 LDA除了可以用于降维以外,还可以用于分类。一个常见的LDA分类基本思想是假设各个类别的样本数据符合高斯分布,这样利用LDA进行投影后,可以利用极大似然估计计算各个类别投影数据的均值和方差,进而得到该类别高斯分布的概率密度函数。当一个新的样本到来后,我们可以将它投影,然后将投影后的样本特征分别带入各个类别的高斯分布概率密度函数,计算它属于这个类别的概率,最大的概率对应的类别即为预测类别
二、Demo
#%%导入基本库
# 基础数组运算库导入
import numpy as np
# 画图库导入
import matplotlib.pyplot as plt
# 导入三维显示工具
from mpl_toolkits.mplot3d import Axes3D
# 导入LDA模型
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
# 导入demo数据制作方法
from sklearn.datasets import make_classification
#%%模型训练
# 制作四个类别的数据,每个类别100个样本
X, y = make_classification(n_samples=1000, n_features=3, n_redundant=0,
n_classes=4, n_informative=2, n_clusters_per_class=1,
class_sep=3, random_state=10)
# 将四个类别的数据进行三维显示
fig = plt.figure()
ax = Axes3D(fig, rect=[0, 0, 1, 1], elev=20, azim=20)
ax.scatter(X[:, 0], X[:, 1], X[:, 2], marker='o', c=y)
plt.show()

#%%建立 LDA 模型 lda = LinearDiscriminantAnalysis() # 进行模型训练 lda.fit(X, y) #%%查看lda的参数 print(lda.get_params())

#%%数据可视化 #模型预测 X_new = lda.transform(X) # 可视化预测数据 plt.scatter(X_new[:, 0], X_new[:, 1], marker='o', c=y) plt.show()
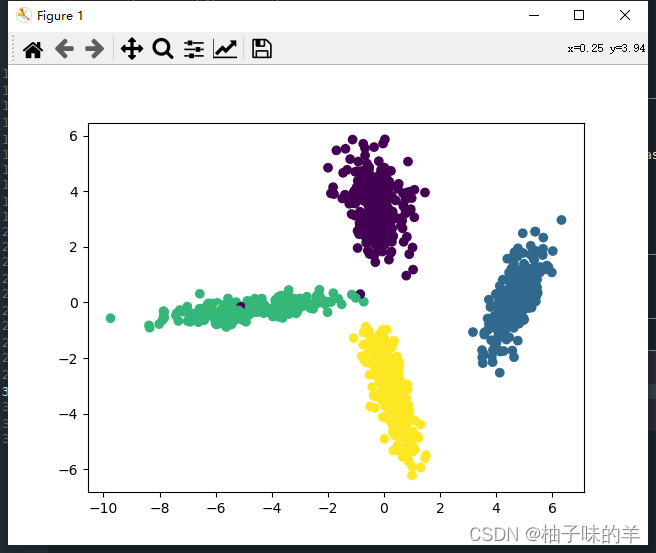
#%%使用新的数据进行测试
a = np.array([[-1, 0.1, 0.1]])
print(f"{a} 类别是: ", lda.predict(a))
print(f"{a} 类别概率分别是: ", lda.predict_proba(a))
a = np.array([[-12, -100, -91]])
print(f"{a} 类别是: ", lda.predict(a))
print(f"{a} 类别概率分别是: ", lda.predict_proba(a))
a = np.array([[-12, -0.1, -0.1]])
print(f"{a} 类别是: ", lda.predict(a))
print(f"{a} 类别概率分别是: ", lda.predict_proba(a))
a = np.array([[0.1, 90.1, 9.1]])
print(f"{a} 类别是: ", lda.predict(a))
print(f"{a} 类别概率分别是: ", lda.predict_proba(a))
三、基于LDA 手写数字的分类
#%%导入库函数
# 导入手写数据集 MNIST
from sklearn.datasets import load_digits
# 导入训练集分割方法
from sklearn.model_selection import train_test_split
# 导入LDA模型
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
# 导入预测指标计算函数和混淆矩阵计算函数
from sklearn.metrics import classification_report, confusion_matrix
# 导入绘图包
import seaborn as sns
import matplotlib
import matplotlib.pyplot as plt
#%% 导入MNIST数据集
mnist = load_digits()
# 查看数据集信息
print('The Mnist dataeset:\n',mnist)
# 分割数据为训练集和测试集
x, test_x, y, test_y = train_test_split(mnist.data, mnist.target, test_size=0.1, random_state=2)

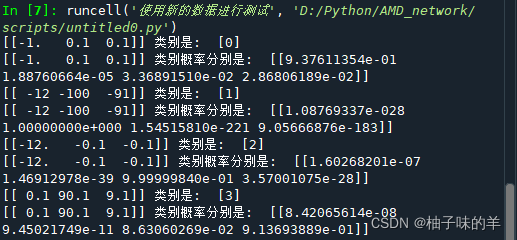
#%%## 输出示例图像
images = range(0,9)
plt.figure(dpi=100)
for i in images:
plt.subplot(330 + 1 + i)
plt.imshow(x[i].reshape(8, 8), cmap = matplotlib.cm.binary,interpolation="nearest")
# show the plot
plt.show()
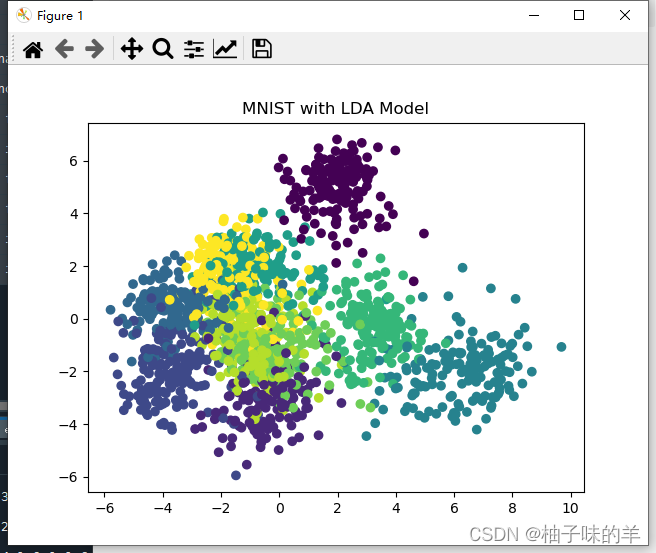
#%%利用LDA对手写数字进行训练与预测
m_lda = LinearDiscriminantAnalysis()# 建立 LDA 模型
# 进行模型训练
m_lda.fit(x, y)
# 进行模型预测
x_new = m_lda.transform(x)
# 可视化预测数据
plt.scatter(x_new[:, 0], x_new[:, 1], marker='o', c=y)
plt.title('MNIST with LDA Model')
plt.show()
#%% 进行测试集数据的类别预测
y_test_pred = m_lda.predict(test_x)
print("测试集的真实标签:\n", test_y)
print("测试集的预测标签:\n", y_test_pred)
#%% 进行预测结果指标统计 统计每一类别的预测准确率、召回率、F1分数
print(classification_report(test_y, y_test_pred))
# 计算混淆矩阵
C2 = confusion_matrix(test_y, y_test_pred)
# 打混淆矩阵
print(C2)
# 将混淆矩阵以热力图的防线显示
sns.set()
f, ax = plt.subplots()
# 画热力图
sns.heatmap(C2, cmap="YlGnBu_r", annot=True, ax=ax)
# 标题
ax.set_title('confusion matrix')
# x轴为预测类别
ax.set_xlabel('predict')
# y轴实际类别
ax.set_ylabel('true')
plt.show()



四、小结
LDA适用于线性可分数据,在非线性数据上要谨慎使用。 886~~~
到此这篇关于Python机器学习应用之基于线性判别模型的分类篇详解的文章就介绍到这了,更多相关Python 线性判别模型的分类内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

深入浅析Python数据分析的过程记录
目录 一.需求介绍 二.以第1.个为例进行数据分析 1.获取一天的数据 2.开始一天的数据的分析 3.循环日期进行多天的数据分析: 4.将数据写入Excel表格中 三.完整的代码展示: 总结 一.需求介绍 该需求主要是分析某一种数据的历史数据. 客户的需求是根据该数据的前两期的情况,如果存在某个斜着的两个数字相等,那么就买第三期的同一个位置处的彩票,对于1.,如果相等的数字是:1-5,那就买6-10,如果相等的数字是:6-10,那就买1-5:对于2.,如果相等的数字是:1-5,那就买1-5,如果
-
Python数据分析之Matplotlib的常用操作总结
目录 使用准备 1.简单的绘制图像 2.视图面板的常用操作 3.样式及各类常用修饰属性 4.legend图例的使用 5.添加文字等描述 6.不同类型图像的绘制 总结 使用准备 使用matplotlib需引入: import matplotlib.pyplot as plt 通常2会配合着numpy使用,numpy引入: import numpy as np 1.简单的绘制图像 def matplotlib_draw(): # 从-1到1生成100个点,包括最后一个点,默认为不包括最后一个点 x
-
Python机器学习应用之工业蒸汽数据分析篇详解
目录 一.数据集 二.数据分析 1 数据导入 2 数据特征探索(数据可视化) 三.特征优化 四.对特征构造后的训练集和测试集进行主成分分析 五.使用LightGBM模型进行训练和预测 一.数据集 1. 训练集 提取码:1234 2. 测试集 提取码:1234 二.数据分析 1 数据导入 #%%导入基础包 import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from
-
基于Python实现股票数据分析的可视化
目录 一.简介 二.代码 1.主文件 2.数据库使用文件 3.ui设计模块 4.数据处理模块 三.数据样例的展示 四.效果展示 一.简介 我们知道在购买股票的时候,可以使用历史数据来对当前的股票的走势进行预测,这就需要对股票的数据进行获取并且进行一定的分析,当然了,人们是比较喜欢图形化的界面的,因此,我们在这里采用一种可视化的方法来实现股票数据的分析. 二.代码 1.主文件 from work1 import get_data from work1 import read_data from w
-
python数据分析之文件读取详解
目录 前言: 一·Numpy库中操作文件 二·Pandas库中操作文件 三·补充 总结 前言: 如果你使用的是Anaconda中的Jupyter,则不需要下载Pands和Numpy库:如果你使用的是pycharm或其他集成环境,则需要Pands和Numpy库 一·Numpy库中操作文件 1.操作csv文件 import numpy as np a=np.random.randint(0,10,size=(3,4)) np.savetext("score.csv",a,deliminte
-
Python机器学习应用之基于天气数据集的XGBoost分类篇解读
目录 一.XGBoost 1 XGBoost的优点 2 XGBoost的缺点 二.实现过程 1 数据集 2 实现 三.Keys XGBoost的重要参数 一.XGBoost XGBoost并不是一种模型,而是一个可供用户轻松解决分类.回归或排序问题的软件包. 1 XGBoost的优点 简单易用.相对其他机器学习库,用户可以轻松使用XGBoost并获得相当不错的效果. 高效可扩展.在处理大规模数据集时速度快效果好,对内存等硬件资源要求不高. 鲁棒性强.相对于深度学习模型不需要精细调参便能取得接近的
-
Python机器学习应用之基于LightGBM的分类预测篇解读
目录 一.Introduction 1 LightGBM的优点 2 LightGBM的缺点 二.实现过程 1 数据集介绍 2 Coding 三.Keys LightGBM的重要参数 基本参数调整 针对训练速度的参数调整 针对准确率的参数调整 针对过拟合的参数调整 一.Introduction LightGBM是扩展机器学习系统.是一款基于GBDT(梯度提升决策树)算法的分布梯度提升框架.其设计思路主要集中在减少数据对内存与计算性能的使用上,以及减少多机器并行计算时的通讯代价 1 LightGBM
-
Python机器学习应用之基于BP神经网络的预测篇详解
目录 一.Introduction 1 BP神经网络的优点 2 BP神经网络的缺点 二.实现过程 1 Demo 2 基于BP神经网络的乳腺癌分类预测 三.Keys 一.Introduction 1 BP神经网络的优点 非线性映射能力:BP神经网络实质上实现了一个从输入到输出的映射功能,数学理论证明三层的神经网络就能够以任意精度逼近任何非线性连续函数.这使得其特别适合于求解内部机制复杂的问题,即BP神经网络具有较强的非线性映射能力. 自学习和自适应能力:BP神经网络在训练时,能够通过学习自动提取输
-
Python数据分析基础之文件的读取
目录 一·Numpy库中操作文件 1.操作csv文件 2.在pycharm中操作csv文件 3.其他情况(.npy类型文件) 二·Pandas库中操作文件 1.操作csv文件 2.从剪贴板上复制数据 3.读取excel或xlsx文件 三·补充 1.常用 2.pandas中读取文件的函数 总结 前言:如果你使用的是Anaconda中的Jupyter,则不需要下载Pands和Numpy库:如果你使用的是pycharm或其他集成环境,则需要Pands和Numpy库 一·Numpy库中操作文件 1.操作
-
Python机器学习应用之基于线性判别模型的分类篇详解
目录 一.Introduction 1 LDA的优点 2 LDA的缺点 3 LDA在模式识别领域与自然语言处理领域的区别 二.Demo 三.基于LDA 手写数字的分类 四.小结 一.Introduction 线性判别模型(LDA)在模式识别领域(比如人脸识别等图形图像识别领域)中有非常广泛的应用.LDA是一种监督学习的降维技术,也就是说它的数据集的每个样本是有类别输出的.这点和PCA不同.PCA是不考虑样本类别输出的无监督降维技术. LDA的思想可以用一句话概括,就是"投影后类内方差最小,类间方
-
Python机器学习应用之基于决策树算法的分类预测篇
目录 一.决策树的特点 1.优点 2.缺点 二.决策树的适用场景 三.demo 一.决策树的特点 1.优点 具有很好的解释性,模型可以生成可以理解的规则. 可以发现特征的重要程度. 模型的计算复杂度较低. 2.缺点 模型容易过拟合,需要采用减枝技术处理. 不能很好利用连续型特征. 预测能力有限,无法达到其他强监督模型效果. 方差较高,数据分布的轻微改变很容易造成树结构完全不同. 二.决策树的适用场景 决策树模型多用于处理自变量与因变量是非线性的关系. 梯度提升树(GBDT),XGBoost以及L
-
Python机器学习NLP自然语言处理基本操作之京东评论分类
目录 概述 RNN 权重共享 计算过程 LSTM 阶段 数据介绍 代码 预处理 主函数 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. RNN RNN (Recurrent Neural Network), 即循环神经网络. RNN 相较于 CNN, 可以帮助我们更好的处理序列信息, 挖掘前后信息之间的联系. 对于 NLP 这类的任务, 语料的前后概率有极大的联系. 比如: "明天
-
Python机器学习应用之决策树分类实例详解
目录 一.数据集 二.实现过程 1 数据特征分析 2 利用决策树模型在二分类上进行训练和预测 3 利用决策树模型在多分类(三分类)上进行训练与预测 三.KEYS 1 构建过程 2 划分选择 3 重要参数 一.数据集 小企鹅数据集,提取码:1234 该数据集一共包含8个变量,其中7个特征变量,1个目标分类变量.共有150个样本,目标变量为 企鹅的类别 其都属于企鹅类的三个亚属,分别是(Adélie, Chinstrap and Gentoo).包含的三种种企鹅的七个特征,分别是所在岛屿,嘴巴长度,
-
基于python计算滚动方差(标准差)talib和pd.rolling函数差异详解
我就废话不多说了,大家还是直接看代码吧! # -*- coding: utf-8 -*- """ Created on Thu Apr 12 11:23:46 2018 @author: henbile """ #计算滚动波动率可以使用专门做技术分析的talib包里面的函数,也可以使用pandas包里面的滚动函数. #但是两个函数对于分母的选择,就是使用N还是N-1作为分母这件事情上是有分歧的. #另一个差异在于:talib包计算基于numpy,
-
Python线性表种的单链表详解
目录 1. 线性表简介 2. 数组 3. 单向链表 设计链表的实现 链表与顺序表的对比 1. 线性表简介 线性表是一种线性结构,它是由零个或多个数据元素构成的有限序列.线性表的特征是在一个序列中,除了头尾元素,每个元素都有且只有一个直接前驱,有且只有一个直接后继,而序列头元素没有直接前驱,序列尾元素没有直接后继. 数据结构中常见的线性结构有数组.单链表.双链表.循环链表等.线性表中的元素为某种相同的抽象数据类型.可以是C语言的内置类型或结构体,也可以是C++自定义类型. 2. 数组 数组在实际的