MySQL中count()和count(1)有何区别以及哪个性能最好详解
目录
- 前言
- 哪种 count 性能最好?
- 为什么要通过遍历的方式来计数?
- 如何优化 count(*)?
- *第一种,近似值*
- 第二种,额外表保存计数值
- 总结
前言
当我们对一张数据表中的记录进行统计的时候,习惯都会使用 count 函数来统计,但是 count 函数传入的参数有很多种,比如 count(1)、count(*)、count(字段) 等。
到底哪种效率是最好的呢?是不是 count(*) 效率最差?
我曾经以为 count(*) 是效率最差的,因为认知上 selete * from t 会读取所有表中的字段,所以凡事带有 * 字符的就觉得会读取表中所有的字段,当时网上有很多博客也这么说。
但是,当我深入 count 函数的原理后,被啪啪啪的打脸了!
不多说, 发车!

哪种 count 性能最好?
哪种 count 性能最好?
我先直接说结论:

要弄明白这个,我们得要深入 count 的原理,以下内容基于常用的 innodb 存储引擎来说明。
count() 是什么?
count() 是一个聚合函数,函数的参数不仅可以是字段名,也可以是其他任意表达式,该函数作用是统计符合查询条件的记录中,函数指定的参数不为 NULL 的记录有多少个。
假设 count() 函数的参数是字段名,如下:
select count(name) from t_order;
这条语句是统计「 t_order 表中,name 字段不为 NULL 的记录」有多少个。也就是说,如果某一条记录中的 name 字段的值为 NULL,则就不会被统计进去。
再来假设 count() 函数的参数是数字 1 这个表达式,如下:
select count(1) from t_order;
这条语句是统计「 t_order 表中,1 这个表达式不为 NULL 的记录」有多少个。
1 这个表达式就是单纯数字,它永远都不是 NULL,所以上面这条语句,其实是在统计 t_order 表中有多少个记录。
count(主键字段) 执行过程是怎样的?
在通过 count 函数统计有多少个记录时,MySQL 的 server 层会维护一个名叫 count 的变量。
server 层会循环向 InnoDB 读取一条记录,如果 count 函数指定的参数不为 NULL,那么就会将变量 count 加 1,直到符合查询的全部记录被读完,就退出循环。最后将 count 变量的值发送给客户端。
InnoDB 是通过 B+ 树来保持记录的,根据索引的类型又分为聚簇索引和二级索引,它们区别在于,聚簇索引的叶子节点存放的是实际数据,而二级索引的叶子节点存放的是主键值,而不是实际数据。
用下面这条语句作为例子:
//id 为主键值 select count(id) from t_order;
如果表里只有主键索引,没有二级索引时,那么,InnoDB 循环遍历聚簇索引,将读取到的记录返回给 server 层,然后读取记录中的 id 值,就会 id 值判断是否为 NULL,如果不为 NULL,就将 count 变量加 1。

但是,如果表里有二级索引时,InnoDB 循环遍历的对象就不是聚簇索引,而是二级索引。

这是因为相同数量的二级索引记录可以比聚簇索引记录占用更少的存储空间,所以二级索引树比聚簇索引树小,这样遍历二级索引的 I/O 成本比遍历聚簇索引的 I/O 成本小,因此「优化器」优先选择的是二级索引。
count(1) 执行过程是怎样的?
用下面这条语句作为例子:
select count(1) from t_order;
如果表里只有主键索引,没有二级索引时。

那么,InnoDB 循环遍历聚簇索引(主键索引),将读取到的记录返回给 server 层,但是不会读取记录中的任何字段的值,因为 count 函数的参数是 1,不是字段,所以不需要读取记录中的字段值。参数 1 很明显并不是 NULL,因此 server 层每从 InnoDB 读取到一条记录,就将 count 变量加 1。
可以看到,count(1) 相比 count(主键字段) 少一个步骤,就是不需要读取记录中的字段值,所以通常会说 count(1) 执行效率会比 count(主键字段) 高一点。
但是,如果表里有二级索引时,InnoDB 循环遍历的对象就二级索引了。

count(*) 执行过程是怎样的?
看到 * 这个字符的时候,是不是大家觉得是读取记录中的所有字段值?
对于 selete * 这条语句来说是这个意思,但是在 count(*) 中并不是这个意思。
count(*) 其实等于 count(0),也就是说,当你使用 count(*) 时,MySQL 会将 * 参数转化为参数 0 来处理。
所以,count(*) 执行过程跟 count(1) 执行过程基本一样的,性能没有什么差异。
在 MySQL 5.7 的官方手册中有这么一句话:
InnoDB handles SELECT COUNT(*) and SELECT COUNT(1) operations in the same way. There is no performance difference.
翻译:InnoDB以相同的方式处理SELECT COUNT(*)和SELECT COUNT(1)操作,没有性能差异。
而且 MySQL 会对 count(*) 和 count(1) 有个优化,如果有多个二级索引的时候,优化器会使用key_len 最小的二级索引进行扫描。
只有当没有二级索引的时候,才会采用主键索引来进行统计。
count(字段) 执行过程是怎样的?
count(字段) 的执行效率相比前面的 count(1)、 count(*)、 count(主键字段) 执行效率是最差的。
用下面这条语句作为例子:
//name不是索引,普通字段 select count(name) from t_order;
对于这个查询来说,会采用全表扫描的方式来计数,所以它的执行效率是比较差的。

小结
count(1)、 count(*)、 count(主键字段)在执行的时候,如果表里存在二级索引,优化器就会选择二级索引进行扫描。
所以,如果要执行 count(1)、 count(*)、 count(主键字段) 时,尽量在数据表上建立二级索引,这样优化器会自动采用 key_len 最小的二级索引进行扫描,相比于扫描主键索引效率会高一些。
再来,就是不要使用 count(字段) 来统计记录个数,因为它的效率是最差的,会采用全表扫描的方式来统计。如果你非要统计表中该字段不为 NULL 的记录个数,建议给这个字段建立一个二级索引。
为什么要通过遍历的方式来计数?
你可以会好奇,为什么 count 函数需要通过遍历的方式来统计记录个数?
我前面将的案例都是基于 Innodb 存储引擎来说明的,但是在 MyISAM 存储引擎里,执行 count 函数的方式是不一样的,通常在没有任何查询条件下的 count(*),MyISAM 的查询速度要明显快于 InnoDB。
使用 MyISAM 引擎时,执行 count 函数只需要 O(1 )复杂度,这是因为每张 MyISAM 的数据表都有一个 meta 信息有存储了row_count值,由表级锁保证一致性,所以直接读取 row_count 值就是 count 函数的执行结果。
而 InnoDB 存储引擎是支持事务的,同一个时刻的多个查询,由于多版本并发控制(MVCC)的原因,InnoDB 表“应该返回多少行”也是不确定的,所以无法像 MyISAM一样,只维护一个 row_count 变量。
举个例子,假设表 t_order 有 100 条记录,现在有两个会话并行以下语句:

在会话 A 和会话 B的最后一个时刻,同时查表 t_order 的记录总个数,可以发现,显示的结果是不一样的。所以,在使用 InnoDB 存储引擎时,就需要扫描表来统计具体的记录。
而当带上 where 条件语句之后,MyISAM 跟 InnoDB 就没有区别了,它们都需要扫描表来进行记录个数的统计。
如何优化 count(*)?
如果对一张大表经常用 count(*) 来做统计,其实是很不好的。
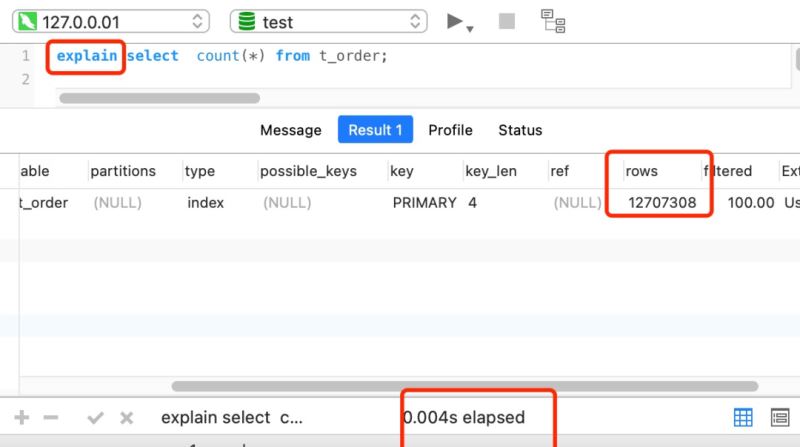
比如下面我这个案例,表 t_order 共有 1200+ 万条记录,我也创建了二级索引,但是执行一次 select count(*) from t_order 要花费差不多 5 秒!

面对大表的记录统计,我们有没有什么其他更好的办法呢?
*第一种,近似值*
如果你的业务对于统计个数不需要很精确,比如搜索引擎在搜索关键词的时候,给出的搜索结果条数是一个大概值。

这时,我们就可以使用 show table status 或者 explain 命令来表进行估算。
执行 explain 命令效率是很高的,因为它并不会真正的去查询,下图中的 rows 字段值就是 explain 命令对表 t_order 记录的估算值。
第二种,额外表保存计数值
如果是想精确的获取表的记录总数,我们可以将这个计数值保存到单独的一张计数表中。
当我们在数据表插入一条记录的同时,将计数表中的计数字段 + 1。也就是说,在新增和删除操作时,我们需要额外维护这个计数表。
总结
到此这篇关于MySQL中count()和count(1)有何区别以及哪个性能最好的文章就介绍到这了,更多相关MySQL中count()和count(1)区别对比内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

一文搞清楚MySQL count(*)、count(1)、count(col)区别
目录 count作用 测试 count(*) count(1) count(col) count(id):统计id count(indexcol):统计带索引的字段 count(normalcol):统计不带索引的字段 count(1)和count(*)取舍 总结 在工作中遇到count(*).count(1).count(col) ,可能会让你分不清楚,都是计数,干嘛这么搞这么多东西. count 作用 COUNT(expression):返回查询的记录总数,expression 参数是一个字
-
Mysql中count(*)、count(1)、count(主键id)与count(字段)的区别
目录 count()函数 count(*).count(1) .count(主键id) 和 count(字段) 区别 count(主键id) 与 count(1) count(字段) count(非空字段) count(可空字段) count(*) 执行效率 执行效果上: 执行效率上: 实例分析 count()函数 count() 是一个聚合函数,对于返回的结果集,一行行地判断,如果 count 函数的参数不是 NULL,累计值就加 1,否则不加.最后返回累计值. count(*).count(
-
MySQL 大表的count()优化实现
以下是基于我结合B+树的数据结构和对实验结果的推测作出的判断,如有错误,恳请指正! 今天实验了一下MySQL的count()操作优化, 以下讨论基于mysql5.7 InnoDB存储引擎. x86 windows操作系统. 创建的表的结构如下(数据量为100万): 首先是关于mysql的count(*),count(PK), count(1)哪个快的问题. 实现结果如下: 并没有什么区别!加上了WHERE子句之后3个查询的时间也是相同的,我就不贴图片了. 之前在公司的时候就写过一个select
-
一文解答为什么MySQL的count()方法这么慢
目录 前言 count()的原理 各种count()方法的原理 允许粗略估计行数的场景 必须精确估计行数的场景 总结 前言 mysql用count方法查全表数据,在不同的存储引擎里实现不同,myisam有专门字段记录全表的行数,直接读这个字段就好了.而innodb则需要一行行去算. 比如说,你有一张短信表(sms),里面放了各种需要发送的短信信息. sms建表sql: sms表; 需要注意的是state字段,为0的时候说明这时候短信还未发送. 此时还会有一个异步线程不断的捞起未发送(state=
-
Mysql中的count()与sum()区别详细介绍
首先创建个表说明问题 复制代码 代码如下: CREATE TABLE `result` ( `name` varchar(20) default NULL, `subject` varchar(20) default NULL, `score` tinyint(4) default NULL ) ENGINE=MyISAM DEFAULT CHARSET=utf8 插入一些数据, 复制代码 代码如下: insert into result values ('张三','数学',90), ('张三'
-
MySQL中count(*)、count(1)和count(col)的区别汇总
前言 count函数是用来统计表中或数组中记录的一个函数,count(*) 它返回检索行的数目, 不论其是否包含 NULL值.最近感觉大家都在讨论count的区别,那么我也写下吧:欢迎留言讨论,话不多说了,来一起看看详细的介绍吧. 1.表结构: dba_jingjing@3306>[rds_test]>CREATE TABLE `test_count` ( -> `c1` varchar(10) DEFAULT NULL, -> `c2` varchar(10) DEFAULT N
-
MySQL 中的count(*) 与 count(1) 谁更快一些?
目录 1.实践 2.explain分析 3.原理分析 3.1主键索引与普通索引 3.2原理分析 4.MyISAM呢? 先说结论:这两个性能差别不大. 1.实践 我准备了一张有 100W 条数据的表,表结构如下: CREATE TABLE `user` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `username` varchar(255) DEFAULT NULL, `address` varchar(255) DEFAULT
-
MySQL count(1)、count(*)、count(字段)的区别
目录 1.初识COUNT 2.COUNT(字段).COUNT(常量)和COUNT(*)之间的区别 3.COUNT(*)的优化 MyISAM InnoDB 4.COUNT(*)和COUNT(1) 5.COUNT(字段) 6.总结 关于数据库中行数统计,无论是MySQL还是Oracle,都有一个函数可以使用,那就是COUNT. 但是,就是这个常用的COUNT函数,却暗藏着很多玄机,尤其是在面试的时候,一不小心就会被虐.不信的话请尝试回答下以下问题: > 1.COUNT有几种用法? > 2.COUN
-
MySQL中dd::columns表结构转table过程及应用详解
目录 一.MySQL的dd表介绍 二.代码跟踪 三.知识应用 四.总结 一.MySQL的dd表介绍 MySQL的dd表是用来存放表结构和各种建表信息的,客户端建的表都存在mysql.table和mysql.columns表里,还有一个表mysql.column_type_elements比较特殊,用来存放SET和ENUM类型的字段集合值信息.看一下下面这张表的mysql.columns表和mysql.column_type_elements信息.为了缩短显示长度,这里只展示几个重要的值. #建表
-
MySQL中count()和count(1)有何区别以及哪个性能最好详解
目录 前言 哪种 count 性能最好? 为什么要通过遍历的方式来计数? 如何优化 count(*)? *第一种,近似值* 第二种,额外表保存计数值 总结 前言 当我们对一张数据表中的记录进行统计的时候,习惯都会使用 count 函数来统计,但是 count 函数传入的参数有很多种,比如 count(1).count(*).count(字段) 等. 到底哪种效率是最好的呢?是不是 count(*) 效率最差? 我曾经以为 count(*) 是效率最差的,因为认知上 selete * from t
-
MySQL中的引号和反引号的区别与用法详解
前言 因此我写下了这个博客,本博客也引荐了一些大佬文章的知识,如有侵权联系我哦!如果有缘人能看到这个博客希望能对你有帮助,如果一些地方有错误也可以直接指出来哦!! 1.单引号: 我们先来介绍一下单引号,下图中的 '男' 就是使用的英文单引号. 为什么要去使用单引号呢?在SQL中一些varchar(string,等字符串类型)是需要用到单引号而不是直接去使用. 一般的在数据库中数值类型是不需要去使用单引号去给他圈起来,我们来看下图的例子: 上述说的是在一般情况下是不用去加引号的,但是如果在不同的可
-
MySQL中B树索引和B+树索引的区别详解
目录 1.多路搜索树 2.B树-多路平衡搜索树 3.B树索引 4.B+树索引 总结 如果用树作为索引的数据结构,每查找一次数据就会从磁盘中读取树的一个节点,也就是一页,而二叉树的每个节点只存储一条数据,并不能填满一页的存储空间,那多余的存储空间岂不是要浪费了?为了解决二叉平衡搜索树的这个弊端,我们应该寻找一种单个节点可以存储更多数据的数据结构,也就是多路搜索树. 1. 多路搜索树 1.完全二叉树高度:O(log2N),其中2为对数,树每层的节点数: 2.完全M路搜索树的高度:O(logmN),其
-
MySQL COUNT(*)性能原理详解
目录 前言 1.COUNT(1).COUNT(*)与COUNT(字段)哪个更快? 实验分析 实验结果 实验结论 2.COUNT(*)与TABLES_ROWS 3.COUNT(*)是怎么样执行的? 4.总结 前言 在实际开发过程中,统计一个表的数据量是经常遇到的需求,用来统计数据库表的行数都会使用COUNT(*),COUNT(1)或者COUNT(字段),但是表中的记录越来越多,使用COUNT(*)也会变得越来越慢,今天我们就来分析一下COUNT(*)的性能到底如何. 1.COUNT(1).COUN
-
MySQL null与not null和null与空值''''的区别详解
相信很多用了MySQL很久的人,对这两个字段属性的概念还不是很清楚,一般会有以下疑问: 我字段类型是not null,为什么我可以插入空值 为毛not null的效率比null高 判断字段不为空的时候,到底要 select * from table where column <> '' 还是要用 select * from table wherecolumn is not null 呢. 带着上面几个疑问,我们来深入研究一下null 和 not null 到底有什么不一样. 首先,我们要搞清楚
-
MySQL索引优化之适合构建索引的几种情况详解
目录 结论 建立索引的场景 小结 结论 在where后面的过滤字段上建立索引(select/update/delete后面的where都是适用的),使用索引加快过滤效率,不用进行全表扫描 在具有唯一要求的字段上添加唯一索引,加快查询效率,查到即可直接返回 group by或者order by后面的字段添加索引,由于索引是排好序的,所以建立索引就等同于在查询之前已经是排好序了(这里需要注意建立的联合索引建立中字段的顺序,可以结合具体案例场景7进行学习) 在DISTINCT(去重字段)后面的字段添加
-
mysql查找删除重复数据并只保留一条实例详解
有这样一张表,表数据及结果如下: school_id school_name total_student test_takers 1239 Abraham Lincoln High School 55 50 1240 Abraham Lincoln High School 70 35 1241 Acalanes High School 120 89 1242 Academy Of The Canyons 30 30 1243 Agoura High School 89 40 1244 Agour
-
Linux 中可重入函数与不可重入函数详解
Linux 中可重入函数与不可重入函数详解 可重入函数和不可重入函数说起来有点拗口,其实写过多进程(线程)程序的人肯定很快就能明白这两种函数是个神马东西.下面是我对这两个函数的理解: 可重入函数可以理解为是能被中断的函数,并且它被中断返回后也不会出现什么错误. 不可重入函数可以理解为如果函数被中断的话,就会出现不可预料的错误.这是因为函数中使用了一些系统资源,比如全局变量区,中断向量表之类的.比如多个进程同时对一个文件进行写操作,如果没有同步机制的话,对文件的写入就会变得难以控制. 在多进程(线
-
python中的split()函数和os.path.split()函数使用详解
Python中有split()和os.path.split()两个函数: split():拆分字符串.通过指定分隔符对字符串进行切片,并返回分割后的字符串列表. os.path.split():将文件名和路径分割开. 1.split()函数 语法:str.split(str=" ",num=string.count(str))[n] 参数说明: str: 表示为分隔符,默认为空格,但是不能为空串.若字符串中没有分隔符,则把整个字符串作为列表的一个元素. num:表示分割次数.如果存在参