JDK集合源码之解析TreeMap(二)
目录
- 删除元素
- 删除再平衡
- 删除元素举例
- 二叉树的遍历
- TreeMap的遍历
- 总结
- 总结
删除元素
删除元素本身比较简单,就是采用二叉树的删除规则。
- 如果删除的位置有两个叶子节点,则从其右子树中取最小的元素放到删除的位置,然后把删除位置移到替代元素的位置,进入下一步。
- 如果删除的位置只有一个叶子节点(有可能是经过第一步转换后的删除位置),则把那个叶子节点作为替代元素,放到删除的位置,然后把这个叶子节点删除。
- 如果删除的位置没有叶子节点,则直接把这个删除位置的元素删除即可。
- 针对红黑树,如果删除位置是黑色节点,还需要做再平衡。
- 如果有替代元素,则以替代元素作为当前节点进入再平衡。
- 如果没有替代元素,则以删除的位置的元素作为当前节点进入再平衡,平衡之后再删除这个节点。
public V remove(Object key) {
// 获取节点
Entry<K,V> p = getEntry(key);
if (p == null)
return null;
V oldValue = p.value;
// 删除节点
deleteEntry(p);
// 返回删除的value
return oldValue;
}
private void deleteEntry(Entry<K,V> p) {
// 修改次数加1
modCount++;
// 元素个数减1
size--;
if (p.left != null && p.right != null) {
// 如果当前节点既有左子节点,又有右子节点
// 取其右子树中最小的节点
Entry<K,V> s = successor(p);
// 用右子树中最小节点的值替换当前节点的值
p.key = s.key;
p.value = s.value;
// 把右子树中最小节点设为当前节点
p = s;
// 这种情况实际上并没有删除p节点,而是把p节点的值改了,实际删除的是p的后继节点
}
// 如果原来的当前节点(p)有2个子节点,则当前节点已经变成原来p的右子树中的最小节点了,也就是说其没有左子节点了
// 到这一步,p肯定只有一个子节点了
// 如果当前节点有子节点,则用子节点替换当前节点
Entry<K,V> replacement = (p.left != null ? p.left : p.right);
if (replacement != null) {
// 把替换节点直接放到当前节点的位置上(相当于删除了p,并把替换节点移动过来了)
replacement.parent = p.parent;
if (p.parent == null)
root = replacement;
else if (p == p.parent.left)
p.parent.left = replacement;
else
p.parent.right = replacement;
// 将p的各项属性都设为空
p.left = p.right = p.parent = null;
// 如果p是黑节点,则需要再平衡
if (p.color == BLACK)
fixAfterDeletion(replacement);
} else if (p.parent == null) {
// 如果当前节点就是根节点,则直接将根节点设为空即可
root = null;
} else {
// 如果当前节点没有子节点且其为黑节点,则把自己当作虚拟的替换节点进行再平衡
if (p.color == BLACK)
fixAfterDeletion(p);
// 平衡完成后删除当前节点(与父节点断绝关系)
if (p.parent != null) {
if (p == p.parent.left)
p.parent.left = null;
else if (p == p.parent.right)
p.parent.right = null;
p.parent = null;
}
}
}
删除再平衡
经过上面的处理,真正删除的肯定是黑色节点才会进入到再平衡阶段。
因为删除的是黑色节点,导致整颗树不平衡了,所以这里我们假设把删除的黑色赋予当前节点,这样当前节点除了它自已的颜色还多了一个黑色,那么:
(1)如果当前节点是根节点,则直接涂黑即可,不需要再平衡;
(2)如果当前节点是红+黑节点,则直接涂黑即可,不需要平衡;
(3)如果当前节点是黑+黑节点,则我们只要通过旋转把这个多出来的黑色不断的向上传递到一个红色节点即可,这又可能会出现以下四种情况:
(假设当前节点为父节点的左子节点)
| 情况 | 策略 |
|---|---|
| 1)x是黑+黑节点,x的兄弟是红节点 | (1)将兄弟节点设为黑色; (2)将父节点设为红色; (3)以父节点为支点进行左旋; (4)重新设置x的兄弟节点,进入下一步; |
| 2)x是黑+黑节点,x的兄弟是黑节点,且兄弟节点的两个子节点都是黑色 | (1)将兄弟节点设置为红色; (2)将x的父节点作为新的当前节点,进入下一次循环; |
| 3)x是黑+黑节点,x的兄弟是黑节点,且兄弟节点的右子节点为黑色,左子节点为红色 | (1)将兄弟节点的左子节点设为黑色; (2)将兄弟节点设为红色; (3)以兄弟节点为支点进行右旋; (4)重新设置x的兄弟节点,进入下一步; |
| 3)x是黑+黑节点,x的兄弟是黑节点,且兄弟节点的右子节点为红色,左子节点任意颜色 | (1)将兄弟节点的颜色设为父节点的颜色; (2)将父节点设为黑色; (3)将兄弟节点的右子节点设为黑色; (4)以父节点为支点进行左旋; (5)将root作为新的当前节点(退出循环); |
(假设当前节点为父节点的右子节点,正好反过来)
| 情况 | 策略 |
|---|---|
| 1)x是黑+黑节点,x的兄弟是红节点 | (1)将兄弟节点设为黑色; (2)将父节点设为红色; (3)以父节点为支点进行右旋; (4)重新设置x的兄弟节点,进入下一步; |
| 2)x是黑+黑节点,x的兄弟是黑节点,且兄弟节点的两个子节点都是黑色 | (1)将兄弟节点设置为红色; (2)将x的父节点作为新的当前节点,进入下一次循环; |
| 3)x是黑+黑节点,x的兄弟是黑节点,且兄弟节点的左子节点为黑色,右子节点为红色 | (1)将兄弟节点的右子节点设为黑色; (2)将兄弟节点设为红色; (3)以兄弟节点为支点进行左旋; (4)重新设置x的兄弟节点,进入下一步; |
| 3)x是黑+黑节点,x的兄弟是黑节点,且兄弟节点的左子节点为红色,右子节点任意颜色 | (1)将兄弟节点的颜色设为父节点的颜色; (2)将父节点设为黑色; (3)将兄弟节点的左子节点设为黑色; (4)以父节点为支点进行右旋; (5)将root作为新的当前节点(退出循环); |
让我们来看看TreeMap中的实现:
/**
* 删除再平衡
*(1)每个节点或者是黑色,或者是红色。
*(2)根节点是黑色。
*(3)每个叶子节点(NIL)是黑色。(注意:这里叶子节点,是指为空(NIL或NULL)的叶子节点!)
*(4)如果一个节点是红色的,则它的子节点必须是黑色的。
*(5)从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
*/
private void fixAfterDeletion(Entry<K,V> x) {
// 只有当前节点不是根节点且当前节点是黑色时才进入循环
while (x != root && colorOf(x) == BLACK) {
if (x == leftOf(parentOf(x))) {
// 如果当前节点是其父节点的左子节点
// sib是当前节点的兄弟节点
Entry<K,V> sib = rightOf(parentOf(x));
// 情况1)如果兄弟节点是红色
if (colorOf(sib) == RED) {
// (1)将兄弟节点设为黑色
setColor(sib, BLACK);
// (2)将父节点设为红色
setColor(parentOf(x), RED);
// (3)以父节点为支点进行左旋
rotateLeft(parentOf(x));
// (4)重新设置x的兄弟节点,进入下一步
sib = rightOf(parentOf(x));
}
if (colorOf(leftOf(sib)) == BLACK &&
colorOf(rightOf(sib)) == BLACK) {
// 情况2)如果兄弟节点的两个子节点都是黑色
// (1)将兄弟节点设置为红色
setColor(sib, RED);
// (2)将x的父节点作为新的当前节点,进入下一次循环
x = parentOf(x);
} else {
if (colorOf(rightOf(sib)) == BLACK) {
// 情况3)如果兄弟节点的右子节点为黑色
// (1)将兄弟节点的左子节点设为黑色
setColor(leftOf(sib), BLACK);
// (2)将兄弟节点设为红色
setColor(sib, RED);
// (3)以兄弟节点为支点进行右旋
rotateRight(sib);
// (4)重新设置x的兄弟节点
sib = rightOf(parentOf(x));
}
// 情况4)
// (1)将兄弟节点的颜色设为父节点的颜色
setColor(sib, colorOf(parentOf(x)));
// (2)将父节点设为黑色
setColor(parentOf(x), BLACK);
// (3)将兄弟节点的右子节点设为黑色
setColor(rightOf(sib), BLACK);
// (4)以父节点为支点进行左旋
rotateLeft(parentOf(x));
// (5)将root作为新的当前节点(退出循环)
x = root;
}
} else { // symmetric
// 如果当前节点是其父节点的右子节点
// sib是当前节点的兄弟节点
Entry<K,V> sib = leftOf(parentOf(x));
// 情况1)如果兄弟节点是红色
if (colorOf(sib) == RED) {
// (1)将兄弟节点设为黑色
setColor(sib, BLACK);
// (2)将父节点设为红色
setColor(parentOf(x), RED);
// (3)以父节点为支点进行右旋
rotateRight(parentOf(x));
// (4)重新设置x的兄弟节点
sib = leftOf(parentOf(x));
}
if (colorOf(rightOf(sib)) == BLACK &&
colorOf(leftOf(sib)) == BLACK) {
// 情况2)如果兄弟节点的两个子节点都是黑色
// (1)将兄弟节点设置为红色
setColor(sib, RED);
// (2)将x的父节点作为新的当前节点,进入下一次循环
x = parentOf(x);
} else {
if (colorOf(leftOf(sib)) == BLACK) {
// 情况3)如果兄弟节点的左子节点为黑色
// (1)将兄弟节点的右子节点设为黑色
setColor(rightOf(sib), BLACK);
// (2)将兄弟节点设为红色
setColor(sib, RED);
// (3)以兄弟节点为支点进行左旋
rotateLeft(sib);
// (4)重新设置x的兄弟节点
sib = leftOf(parentOf(x));
}
// 情况4)
// (1)将兄弟节点的颜色设为父节点的颜色
setColor(sib, colorOf(parentOf(x)));
// (2)将父节点设为黑色
setColor(parentOf(x), BLACK);
// (3)将兄弟节点的左子节点设为黑色
setColor(leftOf(sib), BLACK);
// (4)以父节点为支点进行右旋
rotateRight(parentOf(x));
// (5)将root作为新的当前节点(退出循环)
x = root;
}
}
}
// 退出条件为多出来的黑色向上传递到了根节点或者红节点
// 则将x设为黑色即可满足红黑树规则
setColor(x, BLACK);
}
删除元素举例
假设我们有下面这样一颗红黑树。
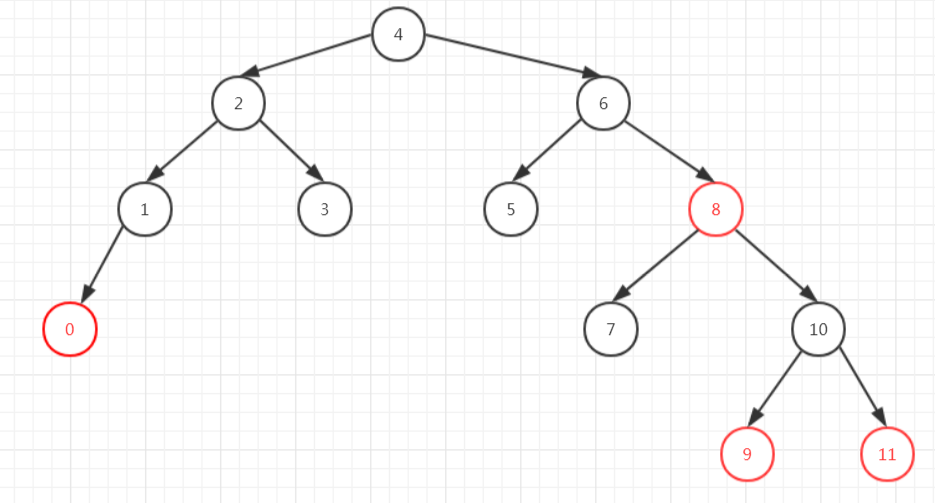
我们删除6号元素,则从右子树中找到了最小元素7,7又没有子节点了,所以把7作为当前节点进行再平衡。
我们看到7是黑节点,且其兄弟为黑节点,且其兄弟的两个子节点都是红色,满足情况4),平衡之后如下图所示。
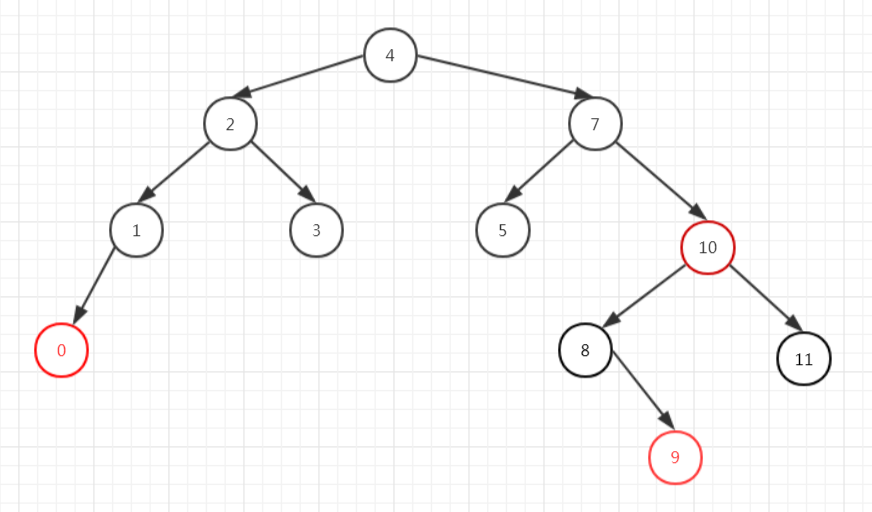
我们再删除7号元素,则从右子树中找到了最小元素8,8有子节点且为黑色,所以8的子节点9是替代节点,以9为当前节点进行再平衡。
我们发现9是红节点,则直接把它涂成黑色即满足了红黑树的特性,不需要再过多的平衡了。
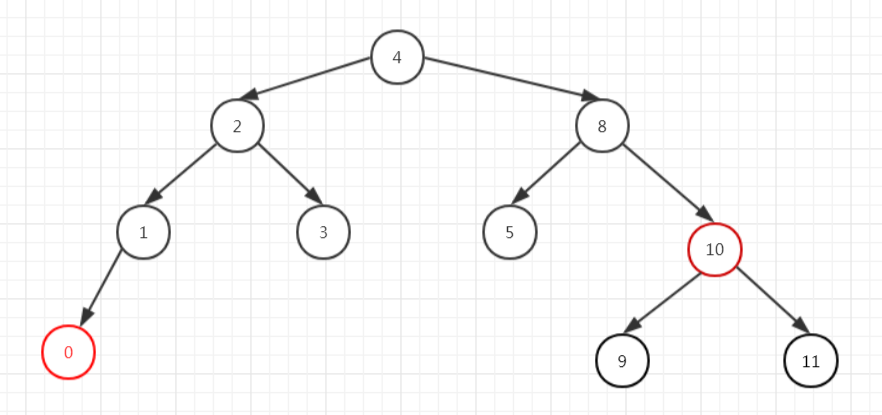
这次我们来个狠的,把根节点删除,从右子树中找到了最小的元素5,5没有子节点,所以把5作为当前节点进行再平衡。
我们看到5是黑节点,且其兄弟为红色,符合情况1),平衡之后如下图所示,然后进入情况2)。

对情况2)进行再平衡后如下图所示。
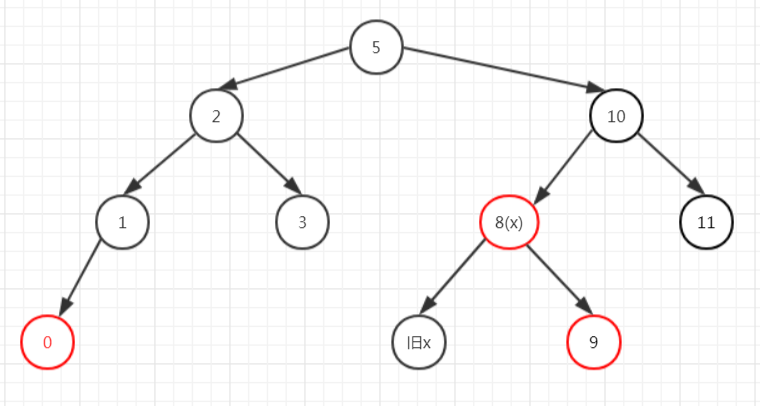
然后进入下一次循环,发现不符合循环条件了,直接把x涂为黑色即可,退出这个方法之后会把旧x删除掉(见deleteEntry()方法),最后的结果就是下面这样。
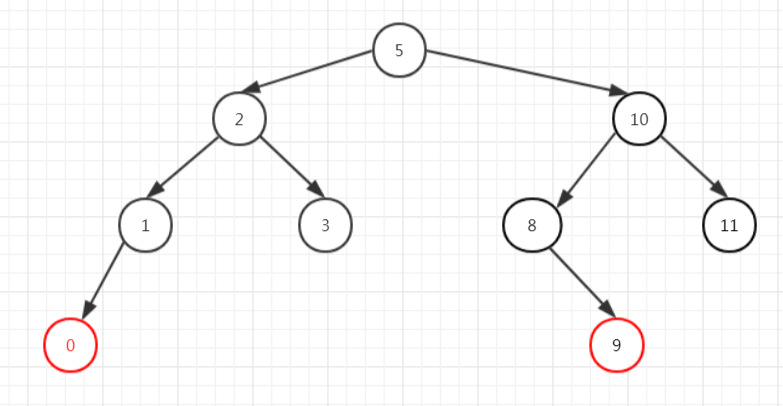
二叉树的遍历
我们知道二叉查找树的遍历有前序遍历、中序遍历、后序遍历。
(1)前序遍历,先遍历我,再遍历我的左子节点,最后遍历我的右子节点;
(2)中序遍历,先遍历我的左子节点,再遍历我,最后遍历我的右子节点;
(3)后序遍历,先遍历我的左子节点,再遍历我的右子节点,最后遍历我;
这里的前中后都是以“我”的顺序为准的,我在前就是前序遍历,我在中就是中序遍历,我在后就是后序遍历。
下面让我们看看经典的中序遍历是怎么实现的:
public class TreeMapTest {
public static void main(String[] args) {
// 构建一颗10个元素的树
TreeNode<Integer> node = new TreeNode<>(1, null).insert(2)
.insert(6).insert(3).insert(5).insert(9)
.insert(7).insert(8).insert(4).insert(10);
// 中序遍历,打印结果为1到10的顺序
node.root().inOrderTraverse();
}
}
/**
* 树节点,假设不存在重复元素
* @param <T>
*/
class TreeNode<T extends Comparable<T>> {
T value;
TreeNode<T> parent;
TreeNode<T> left, right;
public TreeNode(T value, TreeNode<T> parent) {
this.value = value;
this.parent = parent;
}
/**
* 获取根节点
*/
TreeNode<T> root() {
TreeNode<T> cur = this;
while (cur.parent != null) {
cur = cur.parent;
}
return cur;
}
/**
* 中序遍历
*/
void inOrderTraverse() {
if(this.left != null) this.left.inOrderTraverse();
System.out.println(this.value);
if(this.right != null) this.right.inOrderTraverse();
}
/**
* 经典的二叉树插入元素的方法
*/
TreeNode<T> insert(T value) {
// 先找根元素
TreeNode<T> cur = root();
TreeNode<T> p;
int dir;
// 寻找元素应该插入的位置
do {
p = cur;
if ((dir=value.compareTo(p.value)) < 0) {
cur = cur.left;
} else {
cur = cur.right;
}
} while (cur != null);
// 把元素放到找到的位置
if (dir < 0) {
p.left = new TreeNode<>(value, p);
return p.left;
} else {
p.right = new TreeNode<>(value, p);
return p.right;
}
}
}
TreeMap的遍历
从上面二叉树的遍历我们很明显地看到,它是通过递归的方式实现的,但是递归会占用额外的空间,直接到线程栈整个释放掉才会把方法中申请的变量销毁掉,所以当元素特别多的时候是一件很危险的事。
(上面的例子中,没有申请额外的空间,如果有声明变量,则可以理解为直到方法完成才会销毁变量)
那么,有没有什么方法不用递归呢?
让我们来看看java中的实现:
@Override
public void forEach(BiConsumer<? super K, ? super V> action) {
Objects.requireNonNull(action);
// 遍历前的修改次数
int expectedModCount = modCount;
// 执行遍历,先获取第一个元素的位置,再循环遍历后继节点
for (Entry<K, V> e = getFirstEntry(); e != null; e = successor(e)) {
// 执行动作
action.accept(e.key, e.value);
// 如果发现修改次数变了,则抛出异常
if (expectedModCount != modCount) {
throw new ConcurrentModificationException();
}
}
}
是不是很简单?!
(1)寻找第一个节点;
从根节点开始找最左边的节点,即最小的元素。
final Entry<K,V> getFirstEntry() {
Entry<K,V> p = root;
// 从根节点开始找最左边的节点,即最小的元素
if (p != null)
while (p.left != null)
p = p.left;
return p;
}
(2)循环遍历后继节点;
寻找后继节点这个方法我们在删除元素的时候也用到过,当时的场景是有右子树,则从其右子树中寻找最小的节点。
static <K,V> TreeMap.Entry<K,V> successor(Entry<K,V> t) {
if (t == null)
// 如果当前节点为空,返回空
return null;
else if (t.right != null) {
// 如果当前节点有右子树,取右子树中最小的节点
Entry<K,V> p = t.right;
while (p.left != null)
p = p.left;
return p;
} else {
// 如果当前节点没有右子树
// 如果当前节点是父节点的左子节点,直接返回父节点
// 如果当前节点是父节点的右子节点,一直往上找,直到找到一个祖先节点是其父节点的左子节点为止,返回这个祖先节点的父节点
Entry<K,V> p = t.parent;
Entry<K,V> ch = t;
while (p != null && ch == p.right) {
ch = p;
p = p.parent;
}
return p;
}
}
让我们一起来分析下这种方式的时间复杂度吧。
首先,寻找第一个元素,因为红黑树是接近平衡的二叉树,所以找最小的节点,相当于是从顶到底了,时间复杂度为O(log n);
其次,寻找后继节点,因为红黑树插入元素的时候会自动平衡,最坏的情况就是寻找右子树中最小的节点,时间复杂度为O(log k),k为右子树元素个数;
最后,需要遍历所有元素,时间复杂度为O(n);
所以,总的时间复杂度为 O(log n) + O(n * log k) ≈ O(n)。
虽然遍历红黑树的时间复杂度是O(n),但是它实际是要比跳表要慢一点的,啥?跳表是啥?安心,后面会讲到跳表的。
总结
到这里红黑树就整个讲完了,让我们再回顾下红黑树的特性:
- 每个节点或者是黑色,或者是红色。
- 根节点是黑色。
- 每个叶子节点(NIL)是黑色。(注意:这里叶子节点,是指为空(NIL或NULL)的叶子节点!)
- 如果一个节点是红色的,则它的子节点必须是黑色的。
- 从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
除了上述这些标准的红黑树的特性,你还能讲出来哪些TreeMap的特性呢?
- TreeMap的存储结构只有一颗红黑树;
- TreeMap中的元素是有序的,按key的顺序排列;
- TreeMap比HashMap要慢一些,因为HashMap前面还做了一层桶,寻找元素要快很多;
- TreeMap没有扩容的概念;
- TreeMap的遍历不是采用传统的递归式遍历;
- TreeMap可以按范围查找元素,查找最近的元素;
总结
本篇文章就到这里了,希望能给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-

JDK集合源码之解析TreeMap(一)
目录 简介 继承体系 存储结构 源码解析 属性 Entry内部类 构造方法 get(Object key)方法 特性再回顾 左旋 右旋 插入元素 插入再平衡 插入元素举例 总结 简介 TreeMap使用红黑树存储元素,可以保证元素按key值的大小进行遍历. 继承体系 TreeMap实现了Map.SortedMap.NavigableMap.Cloneable.Serializable等接口. SortedMap规定了元素可以按key的大小来遍历,它定义了一些返回部分map的方法. public
-
java TreeMap源码解析详解
java TreeMap源码解析详解 在介绍TreeMap之前,我们来了解一种数据结构:排序二叉树.相信学过数据结构的同学知道,这种结构的数据存储形式在查找的时候效率非常高. 如图所示,这种数据结构是以二叉树为基础的,所有的左孩子的value值都是小于根结点的value值的,所有右孩子的value值都是大于根结点的.这样做的好处在于:如果需要按照键值查找数据元素,只要比较当前结点的value值即可(小于当前结点value值的,往左走,否则往右走),这种方式,每次可以减少一半的操作,所以效率比较高
-
通过java.util.TreeMap源码加强红黑树的理解
在此之前,我们已经为大家整理了很多关于经典问题红黑树的思路和解决办法.本篇文章,是通过分析java.util.TreeMap源码,让大家通过实例来对红黑树这个问题有更加深入的理解. 本篇将结合JDK1.6的TreeMap源码,来一起探索红-黑树的奥秘.红黑树是解决二叉搜索树的非平衡问题. 当插入(或者删除)一个新节点时,为了使树保持平衡,必须遵循一定的规则,这个规则就是红-黑规则: 1) 每个节点不是红色的就是黑色的 2) 根总是黑色的 3) 如果节点是红色的,则它的子节点必须是黑色的(反
-
浅谈java中的TreeMap 排序与TreeSet 排序
TreeMap: package com; import java.util.Comparator; import java.util.TreeMap; public class Test5 { /** * @param args */ public static void main(String[] args) { // TODO Auto-generated method stub TreeMap<String, String> tree = new TreeMap<String,
-
Java源码解析TreeMap简介
TreeMap是常用的排序树,本文主要介绍TreeMap中,类的注释中对TreeMap的介绍.代码如下. /** * A Red-Black tree based {@link NavigableMap} implementation. * The map is sorted according to the {@linkplain Comparable natural * ordering} of its keys, or by a {@link Comparator} provided at
-
JDK集合源码之解析TreeMap(二)
目录 删除元素 删除再平衡 删除元素举例 二叉树的遍历 TreeMap的遍历 总结 总结 删除元素 删除元素本身比较简单,就是采用二叉树的删除规则. 如果删除的位置有两个叶子节点,则从其右子树中取最小的元素放到删除的位置,然后把删除位置移到替代元素的位置,进入下一步. 如果删除的位置只有一个叶子节点(有可能是经过第一步转换后的删除位置),则把那个叶子节点作为替代元素,放到删除的位置,然后把这个叶子节点删除. 如果删除的位置没有叶子节点,则直接把这个删除位置的元素删除即可. 针对红黑树,如果删除位
-
基于ArrayList常用方法的源码全面解析
我相信几乎所有的同学在大大小小的笔试.面试过程中都会被问及ArrayList与LinkedList之间的异同点.稍有准备的人这些问题早已烂熟于心,前者基于数组实现,后者基于链表实现:前者随机方法速度快删除和插入指定位置速度慢,后者随机访问速度慢删除和插入指定位置速度快:两者都是线程不安全的:列表与数组之间的区别等等. 列表与数组之间很大的一个区别就是:数组在其初始化就需要给它确定大小不能动态扩容,而列表则可以动态扩容.ArrayList是基于数组实现的,那么它是如何实现的动态扩容呢? 对于Arr
-
关于Java Guava ImmutableMap不可变集合源码分析
目录 Java Guava不可变集合ImmutableMap的源码分析 一.案例场景 二.ImmutableMap源码分析 Java Guava不可变集合ImmutableMap的源码分析 一.案例场景 遇到过这样的场景,在定义一个static修饰的Map时,使用了大量的put()方法赋值,就类似这样-- public static final Map<String,String> dayMap= new HashMap<>(); static { dayMap.put("
-
Java集合源码全面分析
Java集合工具包位于Java.util包下,包含了很多常用的数据结构,如数组.链表.栈.队列.集合.哈希表等.学习Java集合框架下大致可以分为如下五个部分:List列表.Set集合.Map映射.迭代器(Iterator.Enumeration).工具类(Arrays.Collections). 从上图中可以看出,集合类主要分为两大类:Collection和Map. Collection是List.Set等集合高度抽象出来的接口,它包含了这些集合的基本操作,它主要又分为两大部分:List和Se
-
Spring启动流程refresh()源码深入解析
一.Spring容器的refresh() spring version:4.3.12 ,尚硅谷Spring注解驱动开发-源码部分 //refresh():543, AbstractApplicationContext (org.springframework.context.support) public void refresh() throws BeansException, IllegalStateException { synchronized (this.startupShutdo
-
ahooks useRequest源码精读解析
目录 前言 架构图 源码解析 Fetch onBefore onRequest onSuccess onFinally onError 其它 API 小结 plugins usePollingPlugin useRetryPlugin 小结 useRequest 对自定义 hook 的思考 总结 前言 自从 React v16.8 推出了 Hooks API,前端框架圈并开启了新的逻辑复用的时代,不再需要在意 HOC 的无限套娃导致性能差的问题,也解决了 mixin 的可阅读性差的问题.当然对于
-
Java OkHttp框架源码深入解析
目录 1.OkHttp发起网络请求 可以通过OkHttpClient发起一个网络请求 通过Retrofit发起一个OkHttp请求 2.OkHttp的连接器 1.OkHttp发起网络请求 可以通过OkHttpClient发起一个网络请求 //创建一个Client,相当于打开一个浏览器 OkHttpClient okHttpClient = new OkHttpClient.Builder().build(); //创建一个请求. Request request = new Request.Bui
-
Java HashTable与Collections.synchronizedMap源码深入解析
目录 一.类继承关系图 二.HashTable介绍 三.HashTable和HashMap的对比 1.线程安全 2.插入null 3.容量 4.Hash映射 5.扩容机制 6.结构区别 四.Collections.synchronizedMap解析 1.Collections.synchronizedMap是怎么实现线程安全的 2.SynchronizedMap源码 一.类继承关系图 二.HashTable介绍 HashTable的操作几乎和HashMap一致,主要的区别在于HashTable为
-
MyBatis SqlSource源码示例解析
目录 正文 SqlNode SqlNode接口定义 BoundSql SqlSource SqlSource解析时机 SqlSource调用时机 总结 正文 MyBatis版本:3.5.12. 本篇讲从mybatis的角度分析SqlSource.在xml中sql可能是带?的预处理语句,也可能是带$或者动态标签的动态语句,也可能是这两者的混合语句. SqlSource设计的目标就是封装xml的crud节点,使得mybatis运行过程中可以直接通过SqlSource获取xml节点中解析后的SQL.