Pandas数据分析之批量拆分/合并Excel
目录
- 前言
- 一、假造数据
- 二、程序演示
- 1、将一个大Excel等份拆成多个Excel
- 2、合并多个小Excel到一个大Excel
- 总结
前言
笔者最近正在学习Pandas数据分析,将自己的学习笔记做成一套系列文章。本节主要记录Pandas中数据的合并(concat和append)
将一个大的Excel等份拆成多个Excel将多个小Excel合并成一个大的Excel并且标记来源
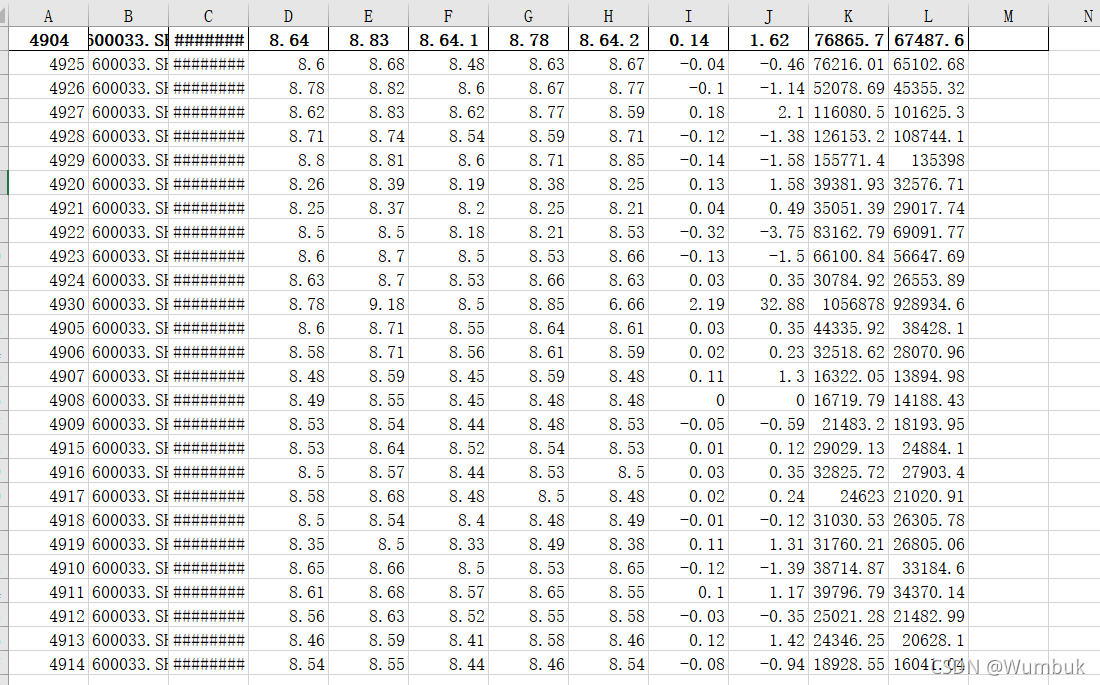
一、假造数据
work_dir="./datas"
splits_dir=f"{work_dir}/splits"
import os
if not os.path.exists(splits_dir):
os.mkdir(splits_dir)
#0.读取源Excel到Pandas
import pandas as pd
df_source=pd.read_excel(f"{work_dir}/1.xlsx")
df_source.head()
df_source.index
df_source.shape
total_row_count=df_source.shape[0]
total_row_count
二、程序演示
1、将一个大Excel等份拆成多个Excel
- 使用df.iloc方法,将一个大的dataframe,拆分成多个小的dataframe
- 将使用dataframe.to_excel保存每个小的Excel
#1.计算拆分后的每个excel的行数
#这个大excel,会拆分给这几个人
user_names=['xiao_shuai',"xiao_wang","xiao_ming","xiao_lei","xiao_bo","xiao_hong"]
#每个人的人数数目
split_size=total_row_count//len(user_names)
if total_row_count%len(user_names)!=0:
split_size+=1
split_size
#拆分成多个dataframe
df_subs=[]
for idx,user_name in enumerate(user_names):
#iloc的开始索引
begin=idx*split_size
#iloc的结束索引
end=begin+split_size
#实现df按照iloc拆分
df_sub=df_source.iloc[begin:end]
#将每个子df存入到列表
df_subs.append((idx,user_name,df_sub))
#3. 将每个dataframe存入到excel
for idx,user_name,df_sub in df_subs:
file_name=f"{splits_dir}/articles_{idx}_{user_name}.xlsx"
df_sub.to_excel(file_name,index=False)
2、合并多个小Excel到一个大Excel
- 遍历文件夹,得到要合并的Excel文件列表
- 分别读取到dataframe,给每个df添加一列用于标记来源
- 使用pd.concat进行df批量合并
- 将合并后的dataframe输出到excel
#1.遍历文件夹,得到要合并的Excel名称列表
import os
excel_names=[]
for excel_name in os.listdir(splits_dir):
excel_names.append(excel_name)
excel_names
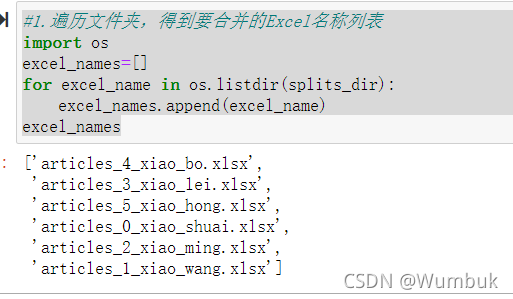
#2分别读取到dataframe
df_list=[]
for excel_name in excel_names:
#读取每个excel到df
excel_path=f"{splits_dir}/{excel_name}"
df_split=pd.read_excel(excel_path)
#得到username
username=excel_name.replace("articles_","").replace(".xlsx","")[2:]
print(excel_name,username)
#给每个df添加1列,即用户名字
df_split["username"]=username
df_list.append(df_split)
#3.使用pd.concat进行合并
df_merged=pd.concat(df_list)
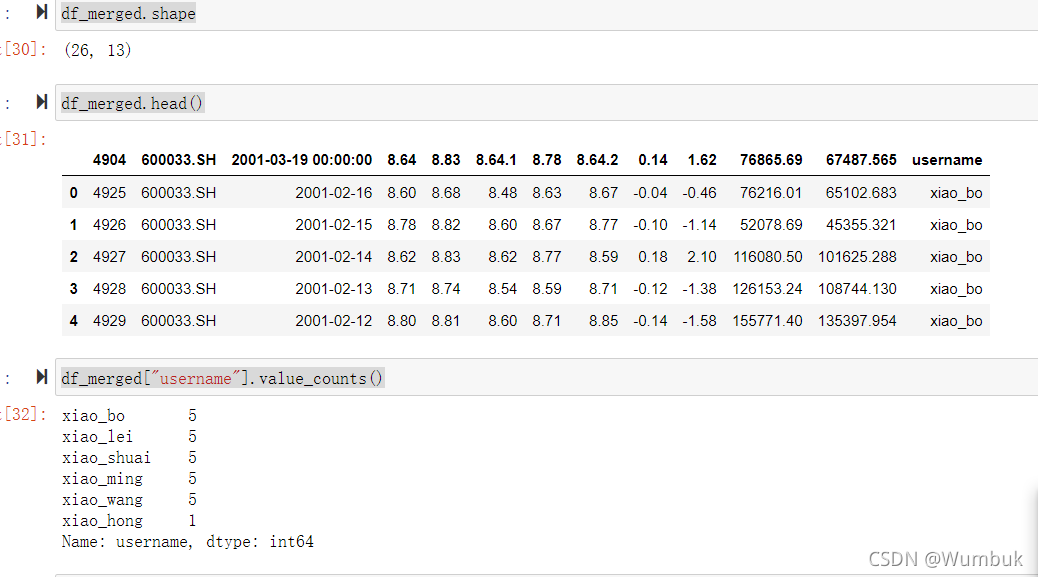
df_merged.shape
df_merged.head()
df_merged["username"].value_counts()
#4.将合并后的dataframe输出到excel
df_merged.to_excel(f"{work_dir}/result_merged.xlsx",index=False)
总结
这就是pandas的DataFrame和存储文件之间转换的基本用法了,希望可以帮助到你。
到此这篇关于Pandas数据分析之批量拆分/合并Excel的文章就介绍到这了,更多相关Pandas批量拆分合并Excel内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
对numpy和pandas中数组的合并和拆分详解
合并 numpy中 numpy中可以通过concatenate,指定参数axis=0 或者 axis=1,在纵轴和横轴上合并两个数组. import numpy as np import pandas as pd arr1=np.ones((3,5)) arr1 Out[5]: array([[ 1., 1., 1., 1., 1.], [ 1., 1., 1., 1., 1.], [ 1., 1., 1., 1., 1.]]) arr2=np.random.randn(15).reshape(
-
利用python Pandas实现批量拆分Excel与合并Excel
一.实例演示 1.将一个大Excel等份拆成多个Excel 2.将多个小Excel合并成一个大Excel并标记来源 work_dir="./course_datas/c15_excel_split_merge" splits_dir=f"{work_dir}/splits" import os if not os.path.exists(splits_dir): os.mkdir(splits_dir) 二.读取源Excel到Pandas import pandas
-

Pandas数据分析之批量拆分/合并Excel
目录 前言 一.假造数据 二.程序演示 1.将一个大Excel等份拆成多个Excel 2.合并多个小Excel到一个大Excel 总结 前言 笔者最近正在学习Pandas数据分析,将自己的学习笔记做成一套系列文章.本节主要记录Pandas中数据的合并(concat和append) 将一个大的Excel等份拆成多个Excel将多个小Excel合并成一个大的Excel并且标记来源 一.假造数据 work_dir="./datas" splits_dir=f"{work_dir}/
-
Pandas实现批量拆分与合并Excel的示例代码
目录 前言 一.拆分成小表格 二.合并excel 1.介绍 2.代码 前言 提示:这里可以添加本文要记录的大概内容: 将一个EXCEL等份拆成多个EXCEL 将多个小EXCEL合并成一个大EXCEL并标记来源 提示:以下是本篇文章正文内容,下面案例可供参考 一.拆分成小表格 代码如下(示例): import pandas as pd import os work_dir=r"G:\360Downloads\myself\zuoye\合并拆分" splits_dir=f"{wo
-
Python 第三方库 Pandas 数据分析教程
目录 Pandas导入 Pandas与numpy的比较 Pandas的Series类型 Pandas的Series类型的创建 Pandas的Series类型的基本操作 pandas的DataFrame类型 pandas的DataFrame类型创建 Pandas的Dataframe类型的基本操作 pandas索引操作 pandas重新索引 pandas删除索引 pandas数据运算 算术运算 Pandas数据分析 pandas导入与导出数据 导入数据 导出数据 Pandas查看.检查数据 Pand
-
Python实现合并excel表格的方法分析
本文实例讲述了Python实现合并excel表格的方法.分享给大家供大家参考,具体如下: 需求 将一个文件夹中的excel表格合并成我们想要的形式,主要要pandas中的concat()函数 思路 用os库将所需要处理的表格放到同一个列表中,然后遍历列表,依次把所有文件纵向连接起来. 最开始的第一种思路是先拿一个文件出来,然后让这个文件依次去和列表中的剩余文件合并: 第二种是用文件夹中第一个文件和剩余的文件合并,使用range(1,len(file)),可以省去单独取第一个文件的步骤. 遇到的问
-
Pandas数据分析常用函数的使用
目录 一.数据导入导出 二.数据加工处理 三.列表格式设置 Pandas是数据处理和分析过程中常用的Python包,提供了大量能使我们快速便捷地处理数据的函数和方法,在此主要整理数据分析过程pandas包常用函数,以便查询.更多函数学习详见padans官网 一.数据导入导出 pandas提供了一些用于将表格型数据读取为DataFrame对象函数,如read_csv,read_table.输入pd.read后,按Tab键,系统将把以read开头的函数和模块都列出来,根据需要读取的文件类型选取. #
-
使用Python横向合并excel文件的实例
起因: 有一批数据需要每个月进行分析,数据存储在excel中,行标题一致,需要横向合并进行分析. 数据示意: 具有多个 代码: # -*- coding: utf-8 -*- """ Created on Sun Nov 12 11:19:03 2017 @author: Li Ying """ #读取第一列作为合并后表格的第一列 from pandas import read_csv df = read_csv(r'E:\excel\vb\ex
-
解决使用Pandas 读取超过65536行的Excel文件问题
场景 今天需要合并天猫订单数据,由于前期6.18活动有很多数据需要处理,将几个月份合并一起,结果报错. 问题分析 Excel 文件的格式曾经发生过一次变化,在 Excel 2007 以前,使用扩展名为 .xls 格式的文件,这种文件格式是一种特定的二进制格式,最多支持 65,536 行,256 列表格.从 Excel 2007 版开始,默认采用了基于 XML 的新的文件格式 .xlsx ,支持的表格行数达到了 1,048,576,列数达到了 16,384.需要注意的是,将 .xlsx 格式的文件
-
pandas使用函数批量处理数据(map、apply、applymap)
前言 在我们对DataFrame对象进行处理时候,下意识的会想到对DataFrame进行遍历,然后将处理后的值再填入DataFrame中,这样做比较繁琐,且处理大量数据时耗时较长.Pandas内置了一个可以对DataFrame批量进行函数处理的工具:map.apply和applymap. 提示:为方便快捷地解决问题,本文仅介绍函数的主要用法,并非全面介绍 一.pandas.Series.map()是什么? 把Series中的值进行逐一映射,带入进函数.字典或Series中得出的另一个值. Ser
-
pandas将list数据拆分成行或列的实现
数据 import numpy as np import pandas as pd data = [{'Name': '小明', 'Chinese': [70, 80], 'Math': [90, 80]}, {'Name': '小红', 'Chinese': [70, 80, 90], 'Math': [90, 80, 70]}] data = pd.DataFrame(data) data 拆分成行 def split_row(data, column): '''拆分成行 :param da