Redis底层数据结构详解
Redis作为Key-Value存储系统,数据结构如下:
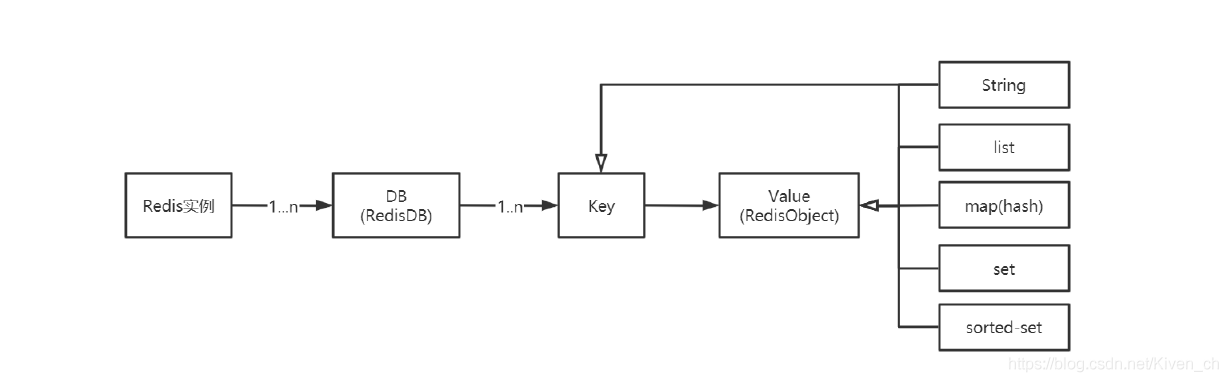
Redis没有表的概念,Redis实例所对应的db以编号区分,db本身就是key的命名空间。
比如:user:1000作为key值,表示在user这个命名空间下id为1000的元素,类似于user表的id=1000的行。
RedisDB结构
Redis中存在“数据库”的概念,该结构由redis.h中的redisDb定义。
当redis 服务器初始化时,会预先分配 16 个数据库
所有数据库保存到结构 redisServer 的一个成员 redisServer.db 数组中
redisClient中存在一个名叫db的指针指向当前使用的数据库
RedisDB结构体源码:
/* Redis database representation. There are multiple databases identified
* by integers from 0 (the default database) up to the max configured
* database. The database number is the 'id' field in the structure. */
typedef struct redisDb {
dict *dict; /* 存储数据库所有的key-value */
dict *expires; /* 存储key的过期时间 */
dict *blocking_keys; /* blpop 存储阻塞key和客户端对象*/
dict *ready_keys; /* 阻塞后push 响应阻塞客户端 存储阻塞后push的key和客户端对象 */
dict *watched_keys; /* 存储watch监控的的key和客户端对象 */
int id; /* Database ID */
long long avg_ttl; /* 存储的数据库对象的平均ttl(time to live),用于统计 */
unsigned long expires_cursor; /* 循环过期检查的光标. */
list *defrag_later; /* 需要尝试去清理磁盘碎片的链表,会慢慢的清理 */
} redisDb;
id
id是数据库序号,为0-15(默认Redis有16个数据库)
dict
存储数据库所有的key-value,后面要详细讲解
expires
存储key的过期时间,后面要详细讲解
RedisObject结构
Value是一个对象
包含字符串对象,列表对象,哈希对象,集合对象和有序集合对象
结构信息概览
typedef struct redisObject {
unsigned type:4; //类型 对象类型
unsigned encoding:4;//编码
// LRU_BITS为24bit 记录最后一次被命令程序访问的时间
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount; //引用计数
void *ptr;//指向底层实现数据结构的指针
} robj;
4位type
type 字段表示对象的类型,占 4 位;
REDIS_STRING(字符串)、REDIS_LIST (列表)、REDIS_HASH(哈希)、REDIS_SET(集合)、REDIS_ZSET(有序集合)。
当我们执行 type 命令时,便是通过读取 RedisObject 的 type 字段获得对象的类型
127.0.0.1:6379> set a1 111 OK 127.0.0.1:6379> type a1 string
4位encoding
encoding 表示对象的内部编码,占 4 位
每个对象有不同的实现编码
Redis 可以根据不同的使用场景来为对象设置不同的编码,大大提高了 Redis 的灵活性和效率。
通过 object encoding 命令,可以查看对象采用的编码方式
127.0.0.1:6379> OBJECT encoding a1 "int"
24位LRU
lru 记录的是对象最后一次被命令程序访问的时间,( 4.0 版本占 24 位,2.6 版本占 22 位)。
高16位存储一个分钟数级别的时间戳,低8位存储访问计数(lfu : 最近访问次数)
lru----> 高16位: 最后被访问的时间
lfu----->低8位:最近访问次数
refcount
refcount 记录的是该对象被引用的次数,类型为整型。
refcount 的作用,主要在于对象的引用计数和内存回收。
当对象的refcount>1时,称为共享对象
Redis 为了节省内存,当有一些对象重复出现时,新的程序不会创建新的对象,而是仍然使用原来的对象。
ptr
ptr 指针指向具体的数据,比如:set hello world,ptr 指向包含字符串 world 的 SDS。
7种type 字符串对象
C语言: 字符数组 “\0”
Redis 使用了 SDS(Simple Dynamic String)。用于存储字符串和整型数据。

/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
buf[] 的长度=len+free+1
SDS的优势:
1.SDS 在 C 字符串的基础上加入了 free 和 len 字段,获取字符串长度:SDS 是 O(1),C 字符串是
O(n)。
buf数组的长度=free+len+1
2.SDS 由于记录了长度,在可能造成缓冲区溢出时会自动重新分配内存,杜绝了缓冲区溢出。
3.可以存取二进制数据,以字符串长度len来作为结束标识
- C:
\0 空字符串 二进制数据包括空字符串,所以没有办法存取二进制数据
- SDS :
非二进制 \0
二进制: 字符串长度 可以存二进制数据
使用场景:
SDS的主要应用在:存储字符串和整型数据、存储key、AOF缓冲区和用户输入缓冲。
跳跃表(重要)
跳跃表是有序集合(sorted-set)的底层实现,效率高,实现简单。
跳跃表的基本思想:
将有序链表中的部分节点分层,每一层都是一个有序链表。
查找
在查找时优先从最高层开始向后查找,当到达某个节点时,如果next节点值大于要查找的值或next指针指向null,则从当前节点下降一层继续向后查找。
举例:

查找元素9,按道理我们需要从头结点开始遍历,一共遍历8个结点才能找到元素9。
第一次分层:
遍历5次找到元素9(红色的线为查找路径)

第二次分层:
遍历4次找到元素9

第三层分层:
遍历4次找到元素9
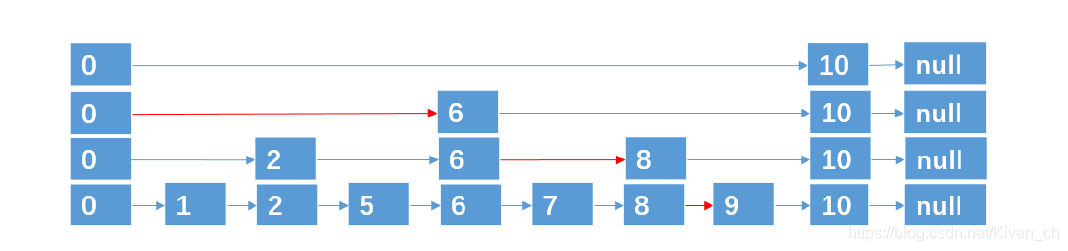
这种数据结构,就是跳跃表,它具有二分查找的功能。
插入与删除
上面例子中,9个结点,一共4层,是理想的跳跃表。
通过抛硬币(概率1/2)的方式来决定新插入结点跨越的层数,每层都需要判断:
正面:插入上层
背面:不插入
达到1/2概率(计算次数)
删除
找到指定元素并删除每层的该元素即可
跳跃表特点:
每层都是一个有序链表
查找次数近似于层数(1/2)
底层包含所有元素
空间复杂度 O(n) 扩充了一倍
Redis跳跃表的实现
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
/* 存储字符串类型数据 redis3.0版本中使用robj类型表示,但是在redis4.0.1中直接使用sds类型表示 */
sds ele;
/*存储排序的分值*/
double score;
/*后退指针,指向当前节点最底层的前一个节点*/
struct zskiplistNode *backward;
/*层,柔性数组,随机生成1-64的值*/
struct zskidictEntryplistLevel {
struct zskiplistNode *forward; //指向本层下一个节点
unsigned long span; //本层下个节点到本节点的元素个数
} level[];
} zskiplistNode;
typedef struct zskiplist {
//表头节点和表尾节点
struct zskiplistNode *header, *tail;
//表中节点的数量
unsigned long length;
//表中层数最大的节点的层数
int level;
} zskiplist;
完整的跳跃表结构体:

跳跃表的优势:
1、可以快速查找到需要的节点 O(logn)
2、可以在O(1)的时间复杂度下,快速获得跳跃表的头节点、尾结点、长度和高度。
应用场景:有序集合的实现
字典(重要)
字典dict又称散列表(hash),是用来存储键值对的一种数据结构。
Redis整个数据库是用字典来存储的。(K-V结构)
对Redis进行CURD操作其实就是对字典中的数据进行CURD操作。
数组
数组:用来存储数据的容器,采用头指针+偏移量的方式能够以O(1)的时间复杂度定位到数据所在的内存地址。
Redis 海量存储 快
Hash函数
Hash(散列),作用是把任意长度的输入通过散列算法转换成固定类型、固定长度的散列值。
hash函数可以把Redis里的key:包括字符串、整数、浮点数统一转换成整数。
key=100.1 String “100.1” 5位长度的字符串
Redis-cli :times 33
Redis-Server : MurmurHash
数组下标=hash(key)%数组容量(hash值%数组容量得到的余数)
Hash冲突
不同的key经过计算后出现数组下标一致,称为Hash冲突。
采用单链表在相同的下标位置处存储原始key和value
当根据key找Value时,找到数组下标,遍历单链表可以找出key相同的value

Redis字典的实现
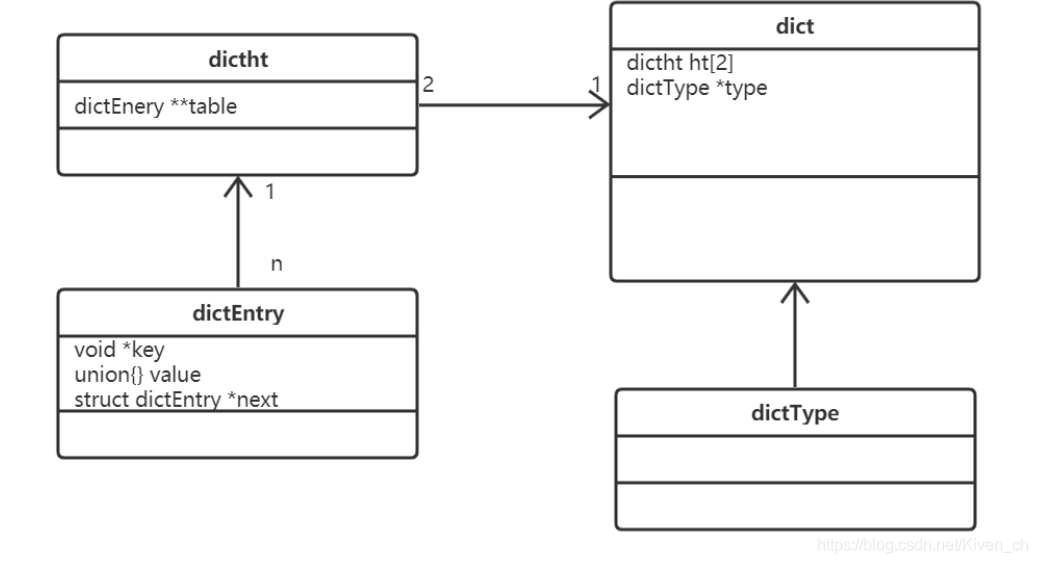
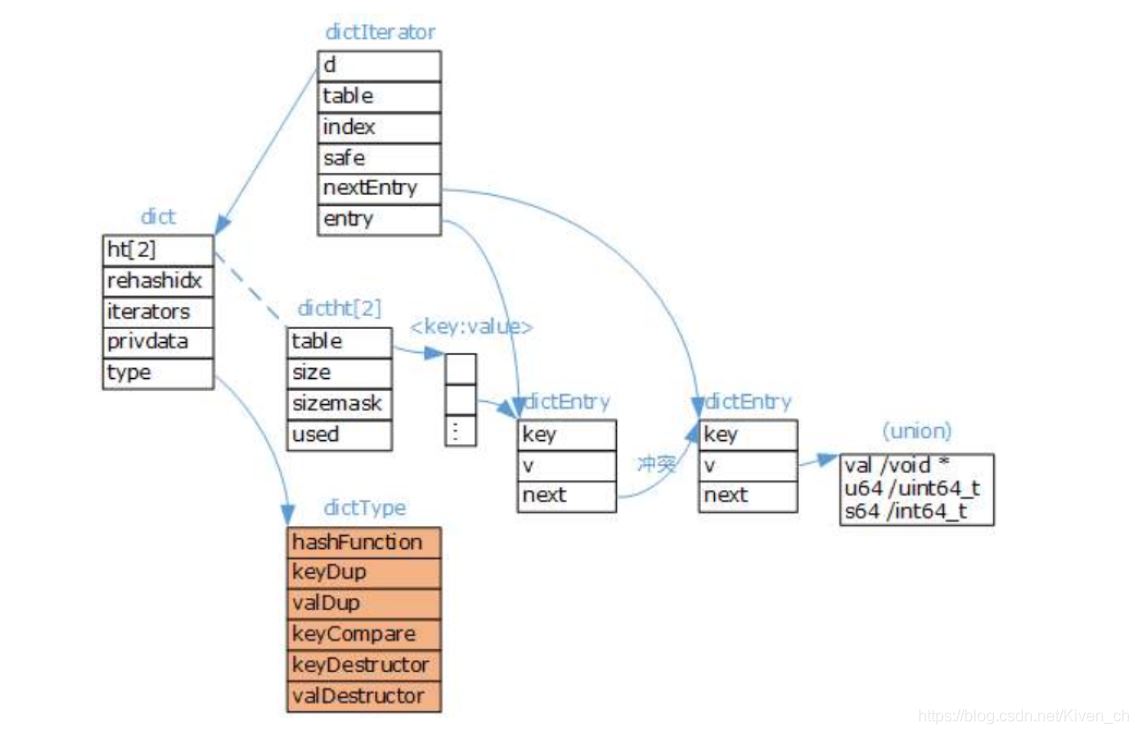
Redis字典实现包括:字典(dict)、Hash表(dictht)、Hash表节点(dictEntry)。
Hash表
typedef struct dictht {
dictEntry **table; // 哈希表数组
unsigned long size; // 哈希表数组的大小
unsigned long sizemask; // 用于映射位置的掩码,值永远等于(size-1)
unsigned long used; // 哈希表已有节点的数量,包含next单链表数据
} dictht;
1、hash表的数组初始容量为4,随着k-v存储量的增加需要对hash表数组进行扩容,新扩容量为当前量的一倍,即4,8,16,32
2、索引值=Hash值&掩码值(Hash值与Hash表容量取余)
Hash表节点
typedef struct dictEntry {
void *key; // 键
union { // 值v的类型可以是以下4种类型
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; // 指向下一个哈希表节点,形成单向链表 解决hash冲突, 单链表中会存储key和value
} dictEntry;
key字段存储的是键值对中的键
v字段是个联合体,存储的是键值对中的值。
next指向下一个哈希表节点,用于解决hash冲突
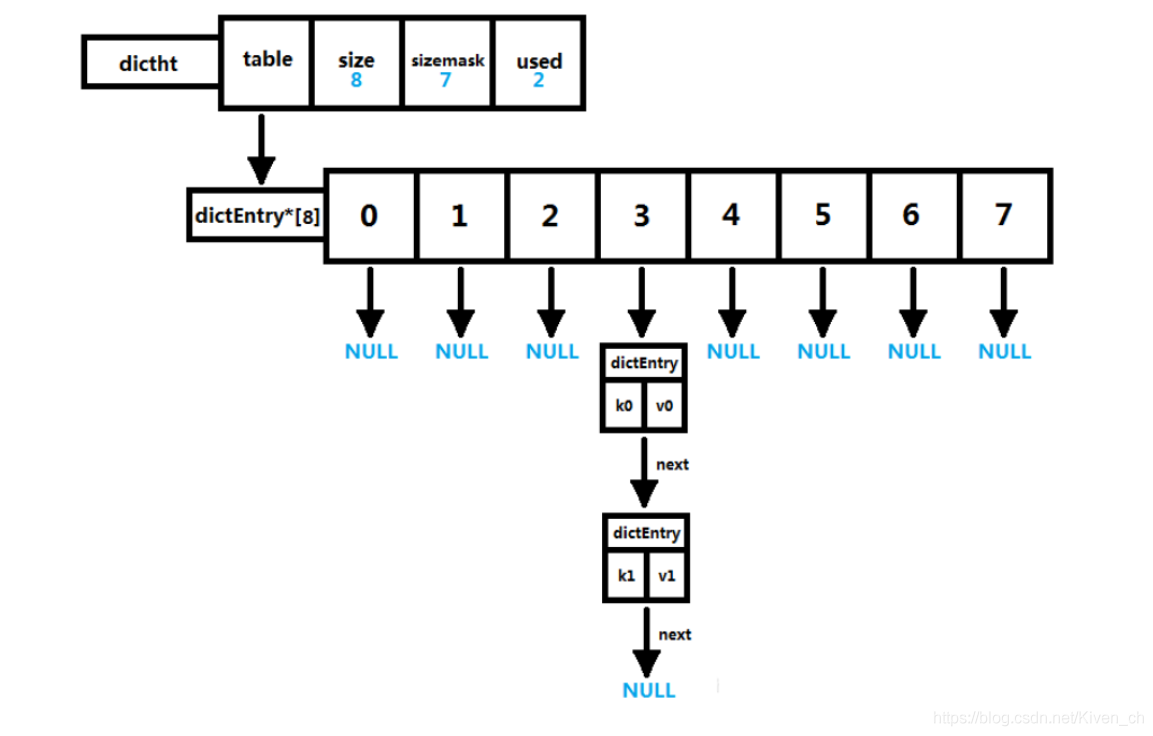
dict字典
typedef struct dict {
dictType *type; //该字典对应的特定操作函数
void *privdata; //上述类型函数对应的可选参数
dictht ht[2];/* 两张哈希表,存储键值对数据,ht[0]为原生哈希表,ht[1]为 rehash 哈希表 */
long rehashidx; /* rehash标识 当等于-1时表示没有在rehash,否则表示正在进行rehash操作,
存储的值表示hash表 ht[0]的rehash进行到哪个索引值(数组下标)*/
unsigned long iterators; /* 当前运行的迭代器数量 */
} dict;
type字段,指向dictType结构体,里边包括了对该字典操作的函数指针
typedef struct dictType {
// 计算哈希值的函数
uint64_t (*hashFunction)(const void *key);
// 复制键的函数
void *(*keyDup)(void *privdata, const void *key);
// 比较键的函数
void *(*valDup)(void *privdata, const void *obj);
// 比较键的函数
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
// 销毁键的函数
void (*keyDestructor)(void *privdata, void *key);
// 销毁值的函数
void (*valDestructor)(void *privdata, void *obj);
} dictType;
Redis字典除了主数据库的K-V数据存储以外,还可以用于:散列表对象、哨兵模式中的主从节点管理等在不同的应用中,字典的形态都可能不同,dictType是为了实现各种形态的字典而抽象出来的操作函数(多态)。
完整的Redis字典数据结构:
字典扩容
字典达到存储上限(阈值 0.75),需要rehash(扩容)

说明:
初次申请默认容量为4个dictEntry,非初次申请为当前hash表容量的一倍。rehashidx=0表示要进行rehash操作。新增加的数据在新的hash表h[1]修改、删除、查询在老hash表h[0]、新hash表h[1]中(rehash中)将老的hash表h[0]的数据重新计算索引值后全部迁移到新的hash表h[1]中,这个过程称为rehash。 渐进式rehash
当数据量巨大时rehash的过程是非常缓慢的,所以需要进行优化。
服务器忙,则只对一个节点进行rehash
服务器闲,可批量rehash(100节点)
应用场景:
1、主数据库的K-V数据存储
2、散列表对象(hash)
3、哨兵模式中的主从节点管理
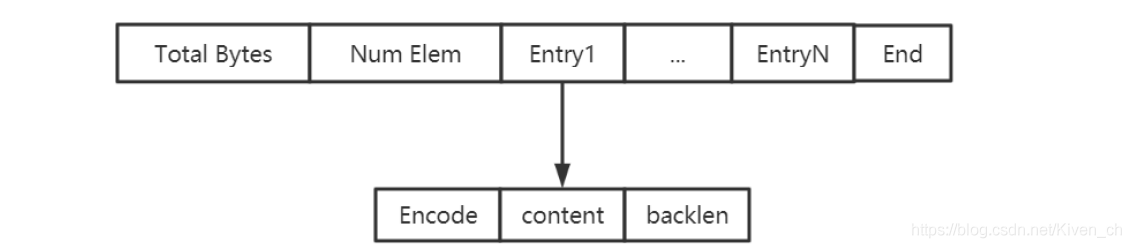
压缩列表
压缩列表(ziplist)是由一系列特殊编码的连续内存块组成的顺序型数据结构
节省内存
是一个字节数组,可以包含多个节点(entry)。每个节点可以保存一个字节数组或一个整数。
压缩列表的数据结构如下:

zlbytes:压缩列表的字节长度
zltail:压缩列表尾元素相对于压缩列表起始地址的偏移量
zllen:压缩列表的元素个数
entry1…entryX : 压缩列表的各个节点
zlend:压缩列表的结尾,占一个字节,恒为0xFF(255)
entryX元素的编码结构:

previous_entry_length:前一个元素的字节长度
encoding:表示当前元素的编码
content:数据内容
ziplist结构体如下:
struct ziplist<T>{
unsigned int zlbytes; // ziplist的长度字节数,包含头部、所有entry和zipend。
unsigned int zloffset; // 从ziplist的头指针到指向最后一个entry的偏移量,用于快速反向查询
unsigned short int zllength; // entry元素个数T[] entry; // 元素值
unsigned char zlend; // ziplist结束符,值固定为0xFF
}
typedef struct zlentry {
unsigned int prevrawlensize; //previous_entry_length字段的长度
unsigned int prevrawlen; //previous_entry_length字段存储的内容
unsigned int lensize; //encoding字段的长度
unsigned int len; //数据内容长度
unsigned int headersize; //当前元素的首部长度,即previous_entry_length字段长度与 encoding字段长度之和。
unsigned char encoding; //数据类型
unsigned char *p; //当前元素首地址
} zlentry;
应用场景:
sorted-set和hash元素个数少且是小整数或短字符串(直接使用)
list用快速链表(quicklist)数据结构存储,而快速链表是双向列表与压缩列表的组合。(间接使用)
整数集合
整数集合(intset)是一个有序的(整数升序)、存储整数的连续存储结构。
当Redis集合类型的元素都是整数并且都处在64位有符号整数范围内(-2^63 ~ 2^63 -1 ),使用该结构体存储。
127.0.0.1:6379> SADD set:1 12 6 8 (integer) 3 127.0.0.1:6379> OBJECT encoding set:1 "intset" 127.0.0.1:6379> SADD set:2 1 1000000000000000000000000000000000000000000000000000000 99999999999999999999999999999 (integer) 3 127.0.0.1:6379> OBJECT encoding set:2 "hashtable"
intset的结构图如下:

typedef struct intset{
//编码方式
uint32_t encoding;
//集合包含的元素数量
uint32_t length;
//保存元素的数组
int8_t contents[];
}intset;
应用场景:
可以保存类型为int16_t、int32_t 或者int64_t 的整数值,并且保证集合中不会出现重复元素。
快速列表(重要)
快速列表(quicklist)是Redis底层重要的数据结构。是列表的底层实现。(在Redis3.2之前,Redis采用双向链表(adlist)和压缩列表(ziplist)实现。)在Redis3.2以后结合adlist和ziplist的优势Redis设计出了quicklist。
127.0.0.1:6379> LPUSH list:001 2 3 5 6 7 (integer) 5 127.0.0.1:6379> OBJECT encoding list:001 "quicklist"
双向列表(adlist)

双向链表优势:
- 双向:链表具有前置节点和后置节点的引用,获取这两个节点时间复杂度都为O(1)。
- 普通链表(单链表):节点类保留下一节点的引用。链表类只保留头节点的引用,只能从头节点插入删除
- 无环:表头节点的 prev 指针和表尾节点的 next 指针都指向 NULL,对链表的访问都是以 NULL 结束。
- 环状:头的前一个节点指向尾节点
- 带链表长度计数器:通过 len 属性获取链表长度的时间复杂度为 O(1)。
- 多态:链表节点使用 void* 指针来保存节点值,可以保存各种不同类型的值。
快速列表
quicklist是一个双向链表,链表中的每个节点时一个ziplist结构。quicklist中的每个节点ziplist都能够存储多个数据元素。
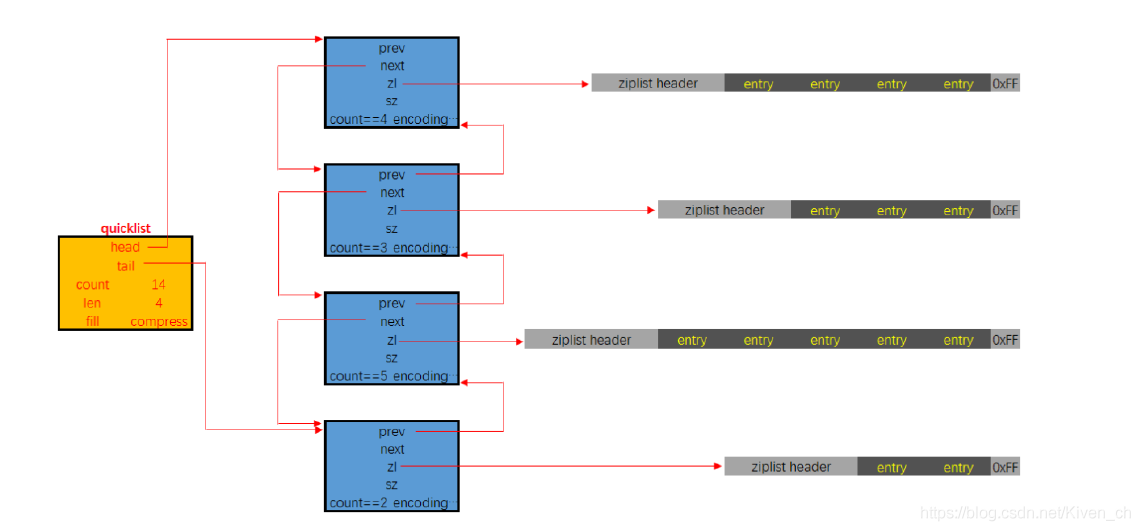
quicklist的结构定义如下:
#if UINTPTR_MAX == 0xffffffff
/* 32-bit */
# define QL_FILL_BITS 14
# define QL_COMP_BITS 14
# define QL_BM_BITS 4
#elif UINTPTR_MAX == 0xffffffffffffffff
/* 64-bit */
# define QL_FILL_BITS 16
# define QL_COMP_BITS 16
# define QL_BM_BITS 4 /* we can encode more, but we rather limit the user
since they cause performance degradation. */
#else
# error unknown arch bits count
#endif
/* quicklist is a 40 byte struct (on 64-bit systems) describing a quicklist.
* 'count' is the number of total entries.
* 'len' is the number of quicklist nodes.
* 'compress' is: 0 if compression disabled, otherwise it's the number
* of quicklistNodes to leave uncompressed at ends of quicklist.
* 'fill' is the user-requested (or default) fill factor.
* 'bookmakrs are an optional feature that is used by realloc this struct,
* so that they don't consume memory when not used. */
typedef struct quicklist {
quicklistNode *head; // 指向quicklist的头部
quicklistNode *tail; // 指向quicklist的尾部
unsigned long count; /* 列表中所有数据项的个数总和 */
unsigned long len; /* quicklist节点的个数,即ziplist的个数 */
int fill : QL_FILL_BITS; /* ziplist大小限定,由list-max-ziplist-size给定 (Redis设定)*/
unsigned int compress : QL_COMP_BITS; /* depth of end nodes not to compress;0=off */
unsigned int bookmark_count: QL_BM_BITS; /*节点压缩深度设置,由list-compress-depth给定*/
quicklistBookmark bookmarks[]; /*可选新特性 使用realloc重新分配空间的时候会用到*/
} quicklist;
quicklistNode的结构定义如下:
/* quicklistNode is a 32 byte struct describing a ziplist for a quicklist.
* We use bit fields keep the quicklistNode at 32 bytes.
* count: 16 bits, max 65536 (max zl bytes is 65k, so max count actually < 32k).
* encoding: 2 bits, RAW=1, LZF=2.
* container: 2 bits, NONE=1, ZIPLIST=2.
* recompress: 1 bit, bool, true if node is temporary decompressed for usage.
* attempted_compress: 1 bit, boolean, used for verifying during testing.
* extra: 10 bits, free for future use; pads out the remainder of 32 bits */
typedef struct quicklistNode {
struct quicklistNode *prev; // 指向上一个ziplist节点
struct quicklistNode *next; // 指向下一个ziplist节点
unsigned char *zl; // 数据指针,如果没有被压缩,就指向ziplist结构,反之指向 quicklistLZF结构
unsigned int sz; // 表示指向ziplist结构的总长度(内存占用长度)
unsigned int count : 16; // 表示ziplist中的数据项个数
unsigned int encoding : 2; // 编码方式,1--ziplist,2--quicklistLZF
unsigned int container : 2; // 预留字段,存放数据的方式,1--NONE,2--ziplist
unsigned int recompress : 1; // 解压标记,当查看一个被压缩的数据时,需要暂时解压,标记此参数为 1,之后再重新进行压缩
unsigned int attempted_compress : 1; // 测试相关
unsigned int extra : 10; // 扩展字段,暂时没用
} quicklistNode;
数据压缩
quicklist每个节点的实际数据存储结构为ziplist,这种结构的优势在于节省存储空间。为了进一步降低ziplist的存储空间,还可以对ziplist进行压缩。Redis采用的压缩算法是LZF。其基本思想是:数据与前面重复的记录重复位置及长度,不重复的记录原始数据。
压缩过后的数据可以分成多个片段,每个片段有两个部分:解释字段和数据字段。quicklistLZF的结构体如下:
/* quicklistLZF is a 4+N byte struct holding 'sz' followed by 'compressed'.
* 'sz' is byte length of 'compressed' field.
* 'compressed' is LZF data with total (compressed) length 'sz'
* NOTE: uncompressed length is stored in quicklistNode->sz.
* When quicklistNode->zl is compressed, node->zl points to a quicklistLZF */
typedef struct quicklistLZF {
unsigned int sz; /* LZF压缩后占用的字节数*/
char compressed[]; //柔性数组,指向数据部分
} quicklistLZF;
应用场景
列表(List)的底层实现、发布与订阅、慢查询、监视器等功能。
流对象
stream主要由:消息、生产者、消费者和消费组构成。
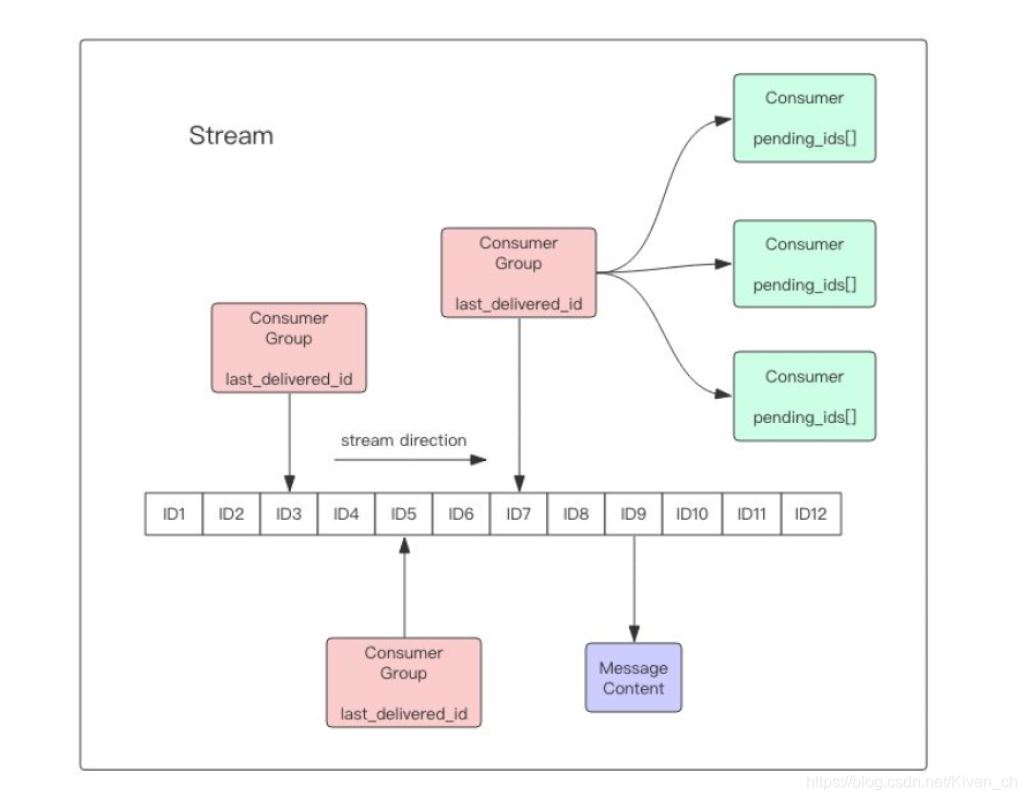
Redis Stream的底层主要使用了listpack(紧凑列表)和Rax树(基数树)。
listpack
listpack表示一个字符串列表的序列化,listpack可用于存储字符串或整数。用于存储stream的消息内容。
结构如下图:
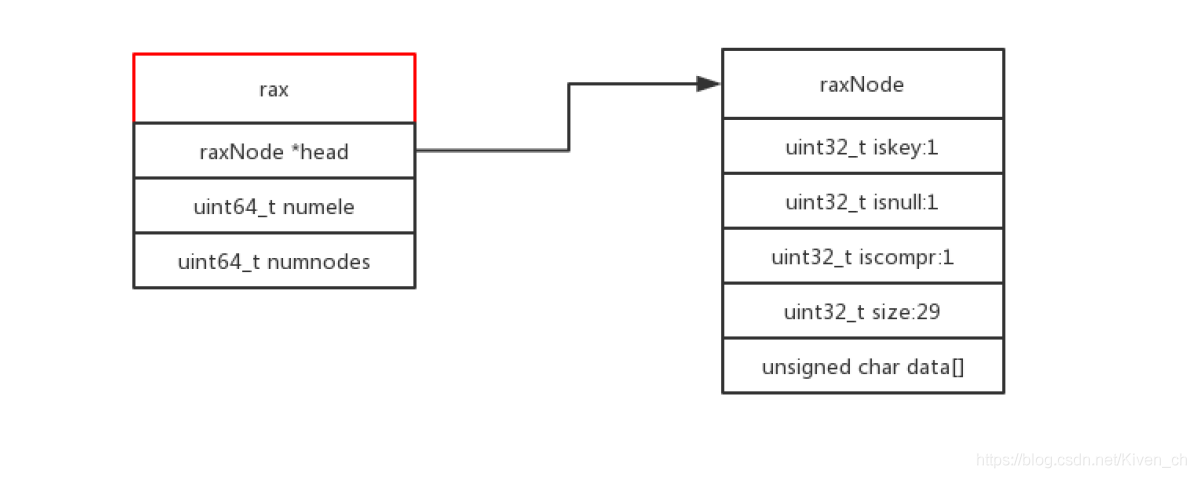
Rax树
Rax 是一个有序字典树 (基数树 Radix Tree),按照 key 的字典序排列,支持快速地定位、插入和删除操作。
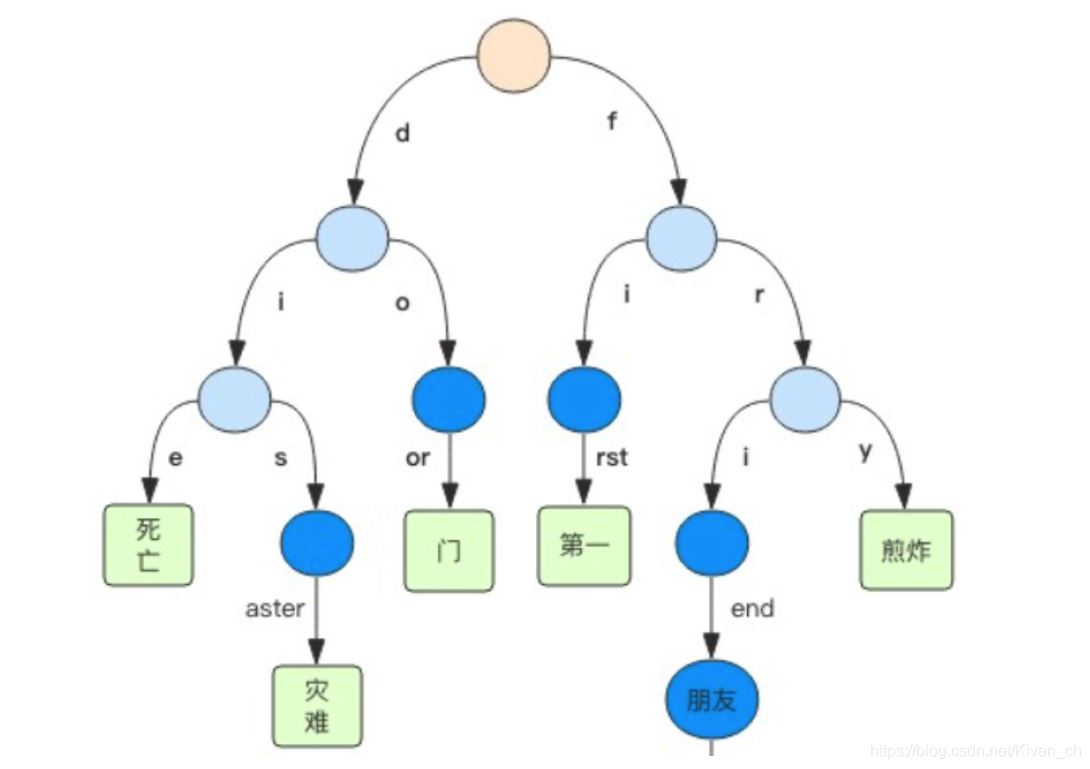
Rax 被用在 Redis Stream 结构里面用于存储消息队列,在 Stream 里面消息 ID 的前缀是时间戳 + 序号,这样的消息可以理解为时间序列消息。使用 Rax 结构 进行存储就可以快速地根据消息 ID 定位到具体的消息,然后继续遍历指定消息 之后的所有消息。
应用场景:
stream的底层实现
10种encoding
/* Objects encoding. Some kind of objects like Strings and Hashes can be * internally represented in multiple ways. The 'encoding' field of the object * is set to one of this fields for this object. */ #define OBJ_ENCODING_RAW 0 /* Raw representation */ #define OBJ_ENCODING_INT 1 /* Encoded as integer */ #define OBJ_ENCODING_HT 2 /* Encoded as hash table */ #define OBJ_ENCODING_ZIPMAP 3 /* Encoded as zipmap */ #define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */ #define OBJ_ENCODING_ZIPLIST 5 /* Encoded as ziplist */ #define OBJ_ENCODING_INTSET 6 /* Encoded as intset */ #define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */ #define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */ #define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists */ #define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */
encoding 表示对象的内部编码,占 4 位。
Redis通过 encoding 属性为对象设置不同的编码
对于少的和小的数据,Redis采用小的和压缩的存储方式,体现Redis的灵活性
大大提高了 Redis 的存储量和执行效率
比如Set对象:
intset : 元素是64位以内的整数
hashtable:元素是64位以外的整数
127.0.0.1:6379> sadd set:001 1 3 5 6 2 (integer) 5 127.0.0.1:6379> object encoding set:001 "intset" 127.0.0.1:6379> sadd set:004 1 100000000000000000000000000 9999999999 (integer) 3 127.0.0.1:6379> object encoding set:004 "hashtable"
String
int、raw、embstr
int
REDIS_ENCODING_INT(int类型的整数)
127.0.0.1:6379> set n1 123 OK 127.0.0.1:6379> object encoding n1 "int"
embstr
REDIS_ENCODING_EMBSTR(编码的简单动态字符串)
小字符串 长度小于44个字节
127.0.0.1:6379> set name:001 zhangfei OK 127.0.0.1:6379> object encoding name:001 "embstr"
raw
REDIS_ENCODING_RAW (简单动态字符串)
大字符串 长度大于44个字节
127.0.0.1:6379> set address:001 asdasdasdasdasdasdsadasdasdasdasdasdasdasdasdasdasdasdasdasdasdasdasdasdasdasdasdasdasdas OK 127.0.0.1:6379> object encoding address:001 "raw"
list
列表的编码是quicklist。
REDIS_ENCODING_QUICKLIST(快速列表)
127.0.0.1:6379> lpush list:001 1 2 5 4 3 (integer) 5 127.0.0.1:6379> object encoding list:001 "quicklist"
hash
散列的编码是字典和压缩列表
dict
REDIS_ENCODING_HT(字典)
当散列表元素的个数比较多或元素不是小整数或短字符串时。
127.0.0.1:6379> hmset user:003 username111111111111111111111111111111111111111111111111111111111111111111111111 11111111111111111111111111111111 zhangfei password 111 num 2300000000000000000000000000000000000000000000000000 OK 127.0.0.1:6379> object encoding user:003 "hashtable"
ziplist
REDIS_ENCODING_ZIPLIST(压缩列表)
当散列表元素的个数比较少,且元素都是小整数或短字符串时。
127.0.0.1:6379> HSET user:001 username zhanyun password 123456 (integer) 2 127.0.0.1:6379> OBJECT encoding user:001 "ziplist"
set
集合的编码是整形集合和字典
intset
REDIS_ENCODING_INTSET(整数集合)
当Redis集合类型的元素都是整数并且都处在64位有符号整数范围内(-9223372036854775808 ~ 9223372036854775807)
127.0.0.1:6379> sadd set:001 1 3 5 6 2 (integer) 5 127.0.0.1:6379> object encoding set:001 "intset"
dict
REDIS_ENCODING_HT(字典)
当Redis集合类型的元素是非整数或都处在64位有符号整数范围外(>9223372036854775807)
127.0.0.1:6379> sadd set:004 1 100000000000000000000000000 9999999999 (integer) 3 127.0.0.1:6379> object encoding set:004 "hashtable"
zset
有序集合的编码是压缩列表和跳跃表+字典
ziplist
REDIS_ENCODING_ZIPLIST(压缩列表)
当元素的个数比较少,且元素都是小整数或短字符串时。
127.0.0.1:6379> zadd hit:1 100 item1 20 item2 45 item3 (integer) 3 127.0.0.1:6379> object encoding hit:1 "ziplist"
skiplist + dict
REDIS_ENCODING_SKIPLIST(跳跃表+字典)
当元素的个数比较多或元素不是小整数或短字符串时。
127.0.0.1:6379> zadd hit:2 100 item1111111111111111111111111111111111111111111111111111111111111111111111111111 1111111111111111111111111111111111 20 item2 45 item3 (integer) 3 127.0.0.1:6379> object encoding hit:2 "skiplist"
到此这篇关于Redis底层数据结构的文章就介绍到这了,更多相关Redis数据结构内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
redis中的数据结构和编码详解
redis中的数据结构和编码: 背景: 1>redis在内部使用redisObject结构体来定义存储的值对象. 2>每种类型都有至少两种内部编码,Redis会根据当前值的类型和长度来决定使用哪种编码实现. 3>编码类型转换在Redis写入数据时自动完成,这个转换过程是不可逆的,转换规则只能从小内存编码向大内存编码转换. 源码: 值对象redisObject: typedef struct redisObject { unsigned ty
-

详解redis数据结构之压缩列表
详解redis数据结构之压缩列表 redis使用压缩列表作为列表键和哈希键的底层实现之一.当一个列表键只包含少量的列表项,并且每个列表项都是由小整数值或者是短字符串组成,那么redis就会使用压缩列表存储列表项:同理,当一个哈希表包含的键值对都是由小整数值或者是短字符串组成,并且存储的键值对数目不多时,redis也会使用压缩列表来存储哈希表.以下是压缩列表存储结构: zlbytes长度为4个字节,记录了整个压缩列表所占用的字节数 zltail长度为4个字节,记录了压缩列表起始位置到压缩列表尾节
-
redis内部数据结构之SDS简单动态字符串详解
前言 reids 没有直接使用C语言传统的字符串表示(以空字符结尾的字符数组)而是构建了一种名为简单动态字符串的抽象类型,并为redis的默认字符串表示,因为C字符串不能满足redis对字符串的安全性.效率以及功能方面的需求 1.SDS 定义 在C语言中,字符串是以'\0'字符结尾(NULL结束符)的字符数组来存储的,通常表达为字符指针的形式(char *).它不允许字节0出现在字符串中间,因此,它不能用来存储任意的二进制数据. sds的类型定义 typedef char *sds; 每个sds
-
redis数据结构之intset的实例详解
redis数据结构之intset的实例详解 在redis中,intset主要用于保存整数值,由于其底层是使用数组来保存数据的,因而当对集合进行数据添加时需要对集合进行扩容和迁移操作,因而也只有在数据量不大时redis才使用该数据结构来保存整数集合.其具体的底层数据结构如下: typedef struct intset { // 编码方式 uint32_t encoding; // 集合包含的元素数量 uint32_t length; // 保存元素的数组 int8_t contents[]; }
-
详解Redis数据结构之跳跃表
1.简介 我们先不谈Redis,来看一下跳表. 1.1.业务场景 场景来自小灰的算法之旅,我们需要做一个拍卖行系统,用来查阅和出售游戏中的道具,类似于魔兽世界中的拍卖行那样,还有以下需求: 拍卖行拍卖的商品需要支持四种排序方式,分别是:按价格.按等级.按剩余时间.按出售者ID排序,排序查询要尽可能地快.还要支持输入道具名称的精确查询和不输入名称的全量查询. 这样的业务场景所需要的数据结构该如何设计呢?拍卖行商品列表是线性的,最容易表达线性结构的是数组和链表.假如用有序数组,虽然查找的时候可以使用
-
Redis中5种数据结构的使用场景介绍
一.redis 数据结构使用场景 原来看过 redisbook 这本书,对 redis 的基本功能都已经熟悉了,从上周开始看 redis 的源码.目前目标是吃透 redis 的数据结构.我们都知道,在 redis 中一共有5种数据结构,那每种数据结构的使用场景都是什么呢? String--字符串 Hash--字典 List--列表 Set--集合 Sorted Set--有序集合 下面我们就来简单说明一下它们各自的使用场景: 1. String--字符串 String 数据结构是简单的 key-
-
Redis底层数据结构详解
Redis作为Key-Value存储系统,数据结构如下: Redis没有表的概念,Redis实例所对应的db以编号区分,db本身就是key的命名空间. 比如:user:1000作为key值,表示在user这个命名空间下id为1000的元素,类似于user表的id=1000的行. RedisDB结构 Redis中存在"数据库"的概念,该结构由redis.h中的redisDb定义. 当redis 服务器初始化时,会预先分配 16 个数据库 所有数据库保存到结构 redisServer 的一
-
Redis 哈希Hash底层数据结构详解
目录 1. Redis 底层数据结构 2. hashtable 3. redisDb 与 redisObject 4. ziplist 5. linkedlist 6. quicklist 1. Redis 底层数据结构 Redis数据库就像是一个哈希表,首先对key进行哈希运算得到哈希值再取模得到一个下标,每个元素是一个节点,节点之间形成链表.这感觉有点像Java中的HashMap. 不同的数据类型的实现方式是不一样的,可以通过object encoding命令查看底层真正的数据存储结构 同一
-
Redis底层数据结构之dict、ziplist、quicklist详解
目录 1 Redis dict 1.1 扩缩容的条件 1.2 渐进式rehash操作 2 Redis ziplist 2.1 ziplist结构 2.2 entry结构 3 Redis quicklist 此前我们学习了常见的Reids数据类型,这些数据类型都需要底层的数据结构的支持,现在我们来看看Redis常见的底层数据结构:dict.ziplist.quicklist. 1 Redis dict dict就是"字典"的意思,它是Redis中的一种使用的非常多的底层的数据结构,除了h
-
Redis RDB技术底层原理详解
每日一句 低头是一种能力,它不是自卑,也不是怯弱,它是清醒中的嬗变.有时,稍微低一下头,或者我们的人生路会更精彩. 前提概要 Redis是一个的键-值(K-V)对的内存数据库服务,通常包含了任意个非空数据库.而每个非空的键值数据库中又可以存放任意个K-V,基本的结构如下图所示: Redis的强劲性能很大程度上是由于其将所有数据都存储在了内存中,为了使Redis在重启之后仍能保证数据不丢失,需要将数据从内存中以某种形式同步到硬盘中,这一过程就是持久化. 我们知道redis中缓存的数据都存放在内存中
-
MySQL8新特性之降序索引底层实现详解
什么是降序索引 大家可能对索引比较熟悉,而对降序索引比较陌生,事实上降序索引是索引的子集. 我们通常使用下面的语句来创建一个索引: create index idx_t1_bcd on t1(b,c,d); 上面sql的意思是在t1表中,针对b,c,d三个字段创建一个联合索引. 但是大家不知道的是,上面这个sql实际上和下面的这个sql是等价的: create index idx_t1_bcd on t1(b asc,c asc,d asc); asc表示的是升序,使用这种语法创建出来的索引叫做
-
Redis 的 GeoHash详解
Redis 在 3.2 版本以后增加了地理位置 GEO 模块,意味着我们可以使用 Redis 来实现摩拜单车「附近的 Mobike」.美团和饿了么「附近的餐馆」这样的功能了. 用数据库来算附近的人 地图元素的位置数据使用二维的经纬度表示,经度范围 (-180, 180],纬度范围 (-90, 90],纬度正负以赤道为界,北正南负,经度正负以本初子午线 (英国格林尼治天文台) 为界,东正西负.比如掘金办公室在望京 SOHO,它的经纬度坐标是 (116.48105,39.996794),都是正数,因
-
Windows下安装Redis的流程详解
目录 一.简介 二.下载与安装Redis 1.下载 2.解压 3.几个重要的文件 三.环境变量配置 四.验证与连接redis 1.验证 3.连接Redis 4.设置一个key测试一下 一.简介 Redis作为常用开源的非关系型数据库,是开发中常用的数据库之一.Redis底层是使用ANSI C编写的,支持网络可基于内存和可持久化的日志型.Key-Value数据库,提供了多种语言API.(基于内存是Redis快的一个重要因素) 二.下载与安装Redis 1.下载 github上可以下载Windows
-
Java并发编程深入理解之Synchronized的使用及底层原理详解 下
目录 一.synchronized锁优化 1.自旋锁与自适应自旋 2.锁消除 逃逸分析: 3.锁粗化 二.对象头内存布局 三.synchronized锁的膨胀升级过程 1.偏向锁 2.轻量级锁 3.重量级锁 4.各种锁的优缺点 接着上文<Java并发编程深入理解之Synchronized的使用及底层原理详解 上>继续介绍synchronized 一.synchronized锁优化 高效并发是从JDK 5升级到JDK 6后一项重要的改进项,HotSpot虚拟机开发团队在这个版本上花费了大量的资源
-
C++使用redis的实例详解
C++使用redis的实例详解 hiredis是redis数据库的C接口,目前只能在linux下使用,几个基本的函数就可以操作redis数据库了. 函数原型:redisContext *redisConnect(const char *ip, int port); 说明:该函数用来连接redis数据库,参数为数据库的ip地址和端口,一般redis数据库的端口为6379: 函数返回值:该函数返回一个结构体redisContext: 类似的提供了一个函数redisContext* redisConn
-
Redis 命令的详解及简单实例
Redis 命令的详解及简单实例 Redis 命令用于在 redis 服务上执行操作. 要在 redis 服务上执行命令需要一个 redis 客户端.Redis 客户端在我们之前下载的的 redis 的安装包中. 语法 Redis 客户端的基本语法为: $ redis-cli 实例 以下实例讲解了如何启动 redis 客户端: 启动 redis 客户端,打开终端并输入命令 redis-cli.该命令会连接本地的 redis 服务. $redis-cli redis 127.0.0.1:6379>