Python爬虫简单运用爬取代理IP的实现
功能1: 爬取西拉ip代理官网上的代理ip
环境:python3.8+pycharm
库:requests,lxml
浏览器:谷歌
IP地址:http://www.xiladaili.com/gaoni/
分析网页源码:

选中div元素后右键找到Copy再深入子菜单找到Copy Xpath点击一下就复制到XPath

我们复制下来的Xpth内容为:/html/body/div/div[3]/div[2]/table/tbody/tr[50]/td[1]
虽然可以查出来ip,但不利于程序自动爬取所有IP,利用谷歌XpathHelp测试一下

从上图可以看出,只匹配到了一个Ip,我们稍作修改,即可达到目的
,有关xpath规则,可以参考下表;


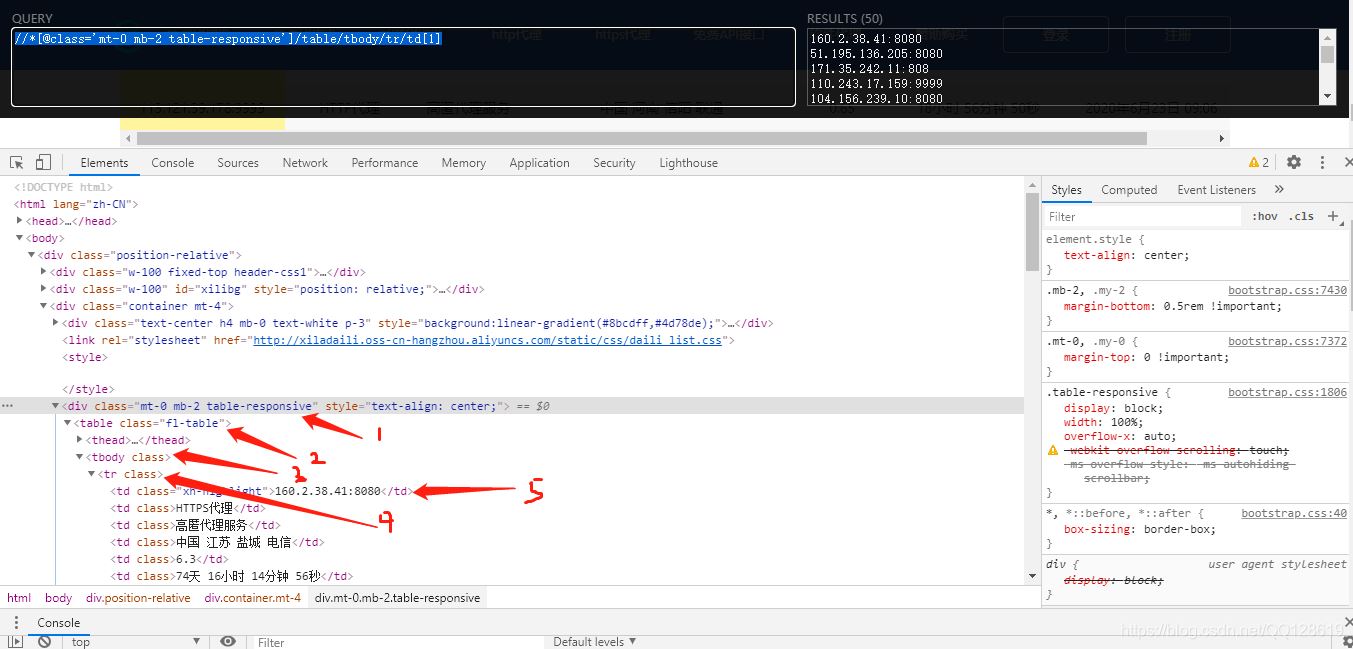
经过上面的规则学习后,我们修改为://*[@class=‘mt-0 mb-2 table-responsive']/table/tbody/tr/td[1],再利用xpthhelp工具验证一下:
这样我们就可以爬取整个页面的Ip地址了,为了方便爬取更多的IP,我们继续往下翻页,找到翻页按钮:

找规律,发现每翻一页,a标签下的href连接地址加1即可,python程序可以利用for循环解决翻页问题即可。
为了提高IP代理的质量,我们爬取评分高的IP来使用。找到评分栏下的Xpath路径,这里不再做详细介绍,思路参考上面找IP地址的思路,及XPath规则,过程参考下图:

Python代码实现
代码可复制粘贴直接使用,如果出现报错,修改一下cookie。这里使用代理ip爬取,防止IP被封。当然这里的代码还是基础的,有空可以写成代理池,多任务去爬。当然还可以使用其它思路去实现,这里只做入门介绍。当有了这些代理IP后,我们可以用文件保存,或者保存到数据库中,根据实际使用情况而定,这里不做保存,只放到列表变量中保存。
import requests
from lxml import etree
import time
class XiLaIp_Spider:
def __init__(self):
self.url = 'http://www.xiladaili.com/gaoni/'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36',
'cookie': 'td_cookie=1539882751; csrftoken=lymOXQp49maLMeKXS1byEMMmsavQPtOCOUwy6WIbfMNazZW80xKKA8RW2Zuo6ssy; Hm_lvt_31dfac66a938040b9bf68ee2294f9fa9=1592547159; Hm_lvt_9bfa8deaeafc6083c5e4683d7892f23d=1592535959,1592539254,1592612217; Hm_lpvt_9bfa8deaeafc6083c5e4683d7892f23d=1592612332',
}
self.proxy = '116.196.85.150:3128'
self.proxies = {
"http": "http://%(proxy)s/" % {'proxy': self.proxy},
"https": "http://%(proxy)s/" % {'proxy': self.proxy}
}
self.list1 = []
def get_url(self):
file = open('Ip_Proxy.txt', 'a', encoding='utf-8')
ok_file = open('OkIp_Proxy.txt', 'a', encoding='utf-8')
for index in range(50):
time.sleep(3)
try:
res = requests.get(url=self.url if index == 0 else self.url + str(index) + "/", headers=self.headers,
proxies=self.proxies, timeout=10).text
except:
continue
data = etree.HTML(res).xpath("//*[@class='mt-0 mb-2 table-responsive']/table/tbody/tr/td[1]")
# '//*[@id="scroll"]/table/tbody/tr/td[1]'
score_data = etree.HTML(res).xpath("//*[@class='mt-0 mb-2 table-responsive']/table/tbody/tr/td[8]")
for i, j in zip(data, score_data):
# file.write(i.text + '\n')
score = int(j.text)
# 追加评分率大于十万的ip
if score > 100000:
self.list1.append(i.text)
set(self.list1)
file.close()
ok_ip = []
for i in self.list1:
try:
# 验证代理ip是否有效
res = requests.get(url='https://www.baidu.com', headers=self.headers, proxies={'http': 'http://' + i},
timeout=10)
if res.status_code == 200:
# ok_file.write(i + '\n')
ok_ip.append(i)
except:
continue
ok_file.close()
return ok_ip
def run(self):
return self.get_url()
dl = XiLaIp_Spider()
dl.run()
到此这篇关于Python爬虫简单运用爬取代理IP的实现的文章就介绍到这了,更多相关Python 爬取代理IP内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python使用requests xpath 并开启多线程爬取西刺代理ip实例
我就废话不多说啦,大家还是直接看代码吧! import requests,random from lxml import etree import threading import time angents = [ "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)", "Mozilla/4.0 (compati
-

Python爬虫爬取新浪微博内容示例【基于代理IP】
本文实例讲述了Python爬虫爬取新浪微博内容.分享给大家供大家参考,具体如下: 用Python编写爬虫,爬取微博大V的微博内容,本文以女神的微博为例(爬新浪m站:https://m.weibo.cn/u/1259110474) 一般做爬虫爬取网站,首选的都是m站,其次是wap站,最后考虑PC站.当然,这不是绝对的,有的时候PC站的信息最全,而你又恰好需要全部的信息,那么PC站是你的首选.一般m站都以m开头后接域名, 所以本文开搞的网址就是 m.weibo.cn. 前期准备 1.代理IP 网上有
-
利用Python爬取可用的代理IP
前言 就以最近发现的一个免费代理IP网站为例:http://www.xicidaili.com/nn/.在使用的时候发现很多IP都用不了. 所以用Python写了个脚本,该脚本可以把能用的代理IP检测出来. 脚本如下: #encoding=utf8 import urllib2 from bs4 import BeautifulSoup import urllib import socket User_Agent = 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv
-
python爬取代理IP并进行有效的IP测试实现
爬取代理IP及测试是否可用 很多人在爬虫时为了防止被封IP,所以就会去各大网站上查找免费的代理IP,由于不是每个IP地址都是有效的,如果要进去一个一个比对的话效率太低了,我也遇到了这种情况,所以就直接尝试了一下去网站爬取免费的代理IP,并且逐一的测试,最后将有效的IP进行返回. 在这里我选择的是89免费代理IP网站进行爬取,并且每一个IP都进行比对测试,最后会将可用的IP进行另存放为一个列表 https://www.89ip.cn/ 一.准备工作 导入包并且设置头标签 import reques
-
Python爬虫简单运用爬取代理IP的实现
功能1: 爬取西拉ip代理官网上的代理ip 环境:python3.8+pycharm 库:requests,lxml 浏览器:谷歌 IP地址:http://www.xiladaili.com/gaoni/ 分析网页源码: 选中div元素后右键找到Copy再深入子菜单找到Copy Xpath点击一下就复制到XPath 我们复制下来的Xpth内容为:/html/body/div/div[3]/div[2]/table/tbody/tr[50]/td[1] 虽然可以查出来ip,但不利于程序自动爬取所有
-
python爬取代理ip的示例
要写爬虫爬取大量的数据,就会面临ip被封的问题,虽然可以通过设置延时的方法来延缓对网站的访问,但是一旦访问次数过多仍然会面临ip被封的风险,这时我们就需要用到动态的ip地址来隐藏真实的ip信息,如果做爬虫项目,建议选取一些平台提供的动态ip服务,引用api即可.目前国内有很多提供动态ip的平台,普遍价格不菲,而对于只想跑个小项目用来学习的话可以参考下本篇文章. 简述 本篇使用简单的爬虫程序来爬取免费ip网站的ip信息并生成json文档,存储可用的ip地址,写其它爬取项目的时候可以从生成的json
-
通过python爬虫mechanize库爬取本机ip地址的方法
目录 需求分析 实现分析 实际使用 完整代码演示 需求分析 最近,各平台更新的ip属地功能非常火爆,因此呢,也出现了许多新的网络用语,比如说“xx加几分”,“xx扣大分”等等,非常的有趣啊 可是呢,最近一个小伙伴和我说,“仙草哥哥,我也想查看一下自己的ip地址,可是我不会啊,我应该怎么样才能查看到自己的ip地址呢?” 关于如何查看自己的ip地址,这个我记得我在很早之前已经写过了,有兴趣的话可以查看一下我的这篇文章,当然这次呢,我会换一个复古的方式,使用mechanize进行爬取 实现分析 pyt
-
Python爬虫小例子——爬取51job发布的工作职位
概述 不知从何时起,Python和爬虫就如初恋一般,情不知所起,一往而深,相信很多朋友学习Python,都是从爬虫开始,其实究其原因,不外两方面:其一Python对爬虫的支持度比较好,类库众多.其二Pyhton的语法简单,入门容易.所以两者形影相随,不离不弃,本文主要以一个简单的小例子,简述Python在爬虫方面的简单应用,仅供学习分享使用,如有不足之处,还请指正. 涉及知识点 本例主要爬取51job发布的工作职位,用到的知识点如下: 开发环境及工具:主要用到Python3.7 ,IDE为PyC
-
Python爬虫实战之爬取京东商品数据并实实现数据可视化
一.开发工具 Python版本:3.6.4 相关模块: DecryptLogin模块: argparse模块: 以及一些python自带的模块. 二.环境搭建 安装Python并添加到环境变量,pip安装需要的相关模块即可. 三.原理简介 原理其实挺简单的,首先,我们利用之前开源的DecryptLogin库来实现一下微博的模拟登录操作: '''模拟登录京东''' @staticmethod def login(): lg = login.Login() infos_return, session
-
Python爬虫利用多线程爬取 LOL 高清壁纸
目录 页面分析 抓取思路 数据采集 程序运行 总结 前言: 随着移动端的普及出现了很多的移动 APP,应用软件也随之流行起来. 最近又捡起来了英雄联盟手游,感觉还行,PC 端英雄联盟可谓是爆火的游戏,不知道移动端的英雄联盟前途如何,那今天我们使用到多线程的方式爬取 LOL 官网英雄高清壁纸. 页面分析 目标网站:英雄联盟 官网界面如图所示,显而易见,一个小图表示一个英雄,我们的目的是爬取每一个英雄的所有皮肤图片,全部下载下来并保存到本地. 次级页面 上面的页面我们称为主页面,次级页面也就是每一个
-
Python爬虫DOTA排行榜爬取实例(分享)
1.分析网站 打开开发者工具,我们观察到排行榜的数据并没有在doc里 doc文档 在Javascript里我么可以看到下面代码: ajax的post方法异步请求数据 在 XHR一栏里,我们找到所请求的数据 json存储的数据 请求字段为: post请求字段 2.伪装浏览器,并将json数据存入excel里面 获取信息 将数据保存到excel中 3.结果展示 以上这篇Python爬虫DOTA排行榜爬取实例(分享)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
java代理实现爬取代理IP的示例
仅仅使用了一个java文件,运行main方法即可,需要依赖的jar包是com.alibaba.fastjson(版本1.2.28)和Jsoup(版本1.10.2) 如果用了pom,那么就是以下两个: <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.28</version> </depe
-
python爬虫使用正则爬取网站的实现
本文章的所有代码和相关文章, 仅用于经验技术交流分享,禁止将相关技术应用到不正当途径,滥用技术产生的风险与本人无关. 本文章是自己学习的一些记录.欢迎各位大佬点评! 首先 今天是第一天写博客,感受到了博客的魅力,博客不仅能够记录每天的代码学习情况,并且可以当作是自己的学习笔记,以便在后面知识点不清楚的时候前来复习.这是第一次使用爬虫爬取网页,这里展示的是爬取豆瓣电影top250的整个过程,欢迎大家指点. 这里我只爬取了电影链接和电影名称,如果想要更加完整的爬取代码,请联系我.qq 1540741