Redis大key多key拆分实现方法解析
背景
业务场景中经常会有各种大key多key的情况, 比如:
1:单个简单的key存储的value很大
2:hash, set,zset,list 中存储过多的元素(以万为单位)
3:一个集群存储了上亿的key,Key 本身过多也带来了更多的空间占用
(如无意外,文章中所提及的hash,set等数据结构均指redis中的数据结构 )
由于redis是单线程运行的,如果一次操作的value很大会对整个redis的响应时间造成负面影响,所以,业务上能拆则拆,下面举几个典型的分拆方案。
一、单个简单的key存储的value很大
i:该对象需要每次都整存整取
可以尝试将对象分拆成几个key-value, 使用multiGet获取值,这样分拆的意义在于分拆单次操作的压力,将操作压力平摊到多个redis实例中,降低对单个redis的IO影响;
ii:该对象每次只需要存取部分数据
可以像第一种做法一样,分拆成几个key-value, 也可以将这个存储在一个hash中,每个field代表一个具体的属性,
使用hget,hmget来获取部分的value,使用hset,hmset来更新部分属性
二、value中存储过多的元素
类似于场景一种的第一个做法,可以将这些元素分拆。
以hash为例,原先的正常存取流程是 hget(hashKey, field) ; hset(hashKey, field, value)
现在,固定一个桶的数量,比如 10000, 每次存取的时候,先在本地计算field的hash值,模除 10000, 确定了该field落在哪个key上。
newHashKey = hashKey + (set, zset, list 也可以类似上述做法
但有些不适合的场景,比如,要保证 lpop 的数据的确是最早push到list中去的,这个就需要一些附加的属性,或者是在 key的拼接上做一些工作(比如list按照时间来分拆)。
三、一个集群存储了上亿的key
如果key的个数过多会带来更多的内存空间占用,
i:key本身的占用(每个key 都会有一个Category前缀)
ii:集群模式中,服务端需要建立一些slot2key的映射关系,这其中的指针占用在key多的情况下也是浪费巨大空间
这两个方面在key个数上亿的时候消耗内存十分明显(Redis 3.2及以下版本均存在这个问题,4.0有优化);
所以减少key的个数可以减少内存消耗,可以参考的方案是转Hash结构存储,即原先是直接使用Redis String 的结构存储,现在将多个key存储在一个Hash结构中,具体场景参考如下:
1:key 本身就有很强的相关性,比如多个key 代表一个对象,每个key是对象的一个属性,这种可直接按照特定对象的特征来设置一个新Key——Hash结构, 原先的key则作为这个新Hash 的field。
举例说明:
原先存储的三个key
user.zhangsan-id = 123;
user.zhangsan-age = 18;
user.zhangsan-country = china;
这三个key本身就具有很强的相关特性,转成Hash存储就像这样key = user.zhangsan
field:id = 123;
field:age = 18;
field:country = china;
即redis中存储的是一个key :user.zhangsan, 他有三个 field, 每个field + key 就对应原先的一个key。
2:key 本身没有相关性,预估一下总量,采取和上述第二种场景类似的方案,预分一个固定的桶数量
比如现在预估key 的总数为 2亿,按照一个hash存储 100个field来算,需要 2亿 / 100 = 200W 个桶 (200W 个key占用的空间很少,2亿可能有将近 20G )
原先比如有三个key :
user.123456789
user.987654321
user.678912345
现在按照200W 固定桶分就是先计算出桶的序号 hash(123456789) % 200W , 这里最好保证这个 hash算法的值是个正数,否则需要调整下模除的规则;
这样算出三个key 的桶分别是 1 , 2, 2。 所以存储的时候调用API hset(key, field, value),读取的时候使用 hget (key, field)

注意两个地方:1,hash 取模对负数的处理; 2,预分桶的时候, 一个hash 中存储的值最好不要超过 512 ,100 左右较为合适
四、大Bitmap或布隆过滤器(Bloom )拆分
使用bitmap或布隆过滤器的场景,往往是数据量极大的情况,在这种情况下,Bitmap和布隆过滤器使用空间也比较大,比如用于公司userid匹配的布隆过滤器,就需要512MB的大小,这对redis来说是绝对的大value了。
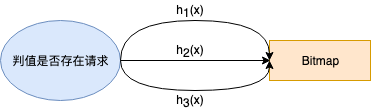
这种场景下,我们就需要对其进行拆分,拆分为足够小的Bitmap,比如将512MB的大Bitmap拆分为1024个512KB的Bitmap。不过拆分的时候需要注意,要将每个key落在一个Bitmap上。有些业务只是把Bitmap 拆开, 但还是当做一个整体的bitmap看, 所以一个 key 还是落在多个 Bitmap 上,这样就有可能导致一个key请求需要查询多个节点、多个Bitmap。
如下图,被请求的值被hash到多个Bitmap上,也就是redis的多个key上,这些key还有可能在不同节点上,这样拆分显然大大降低了查询的效率。

因此我们所要做的是把所有拆分后的Bitmap当作独立的bitmap,然后通过hash将不同的key分配给不同的bitmap上,而不是把所有的小Bitmap当作一个整体。这样做后每次请求都只要取redis中一个key即可。
有同学可能会问,通过这样拆分后,相当于Bitmap变小了,会不会增加布隆过滤器的误判率?实际上是不会的,布隆过滤器的误判率是哈希函数个数k,集合元素个数n,以及Bitmap大小m所决定的,其约等于
 。
。
因此如果我们在第一步,也就是在分配key给不同Bitmap时,能够尽可能均匀的拆分,那么n/m的值几乎是一样的,误判率也就不会改变。具体的误判率推导可以参考wiki:Bloom_filter
同时,客户端也提供便利的api (>=2.3.4版本), setBits/ getBits 用于一次操作同一个key的多个bit值 。
建议 :k 取 13 个, 单个bloomfilter控制在 512KB 以下
以上方案仅供参考,欢迎大家提供其他的优秀方案。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
解决spring中redistemplate不能用通配符keys查出相应Key的问题
有个业务中需要删除某个前缀的所有Redis缓存,于是用RedisTemplate的keys方法先查出所有合适的key,再遍历删除. 但是在keys(patten+"*")时每次取出的都为空. 解决问题: spring中redis配置中,引入StringRedisTemplate而不是RedisTemplate,StringRedisTemplate本身继承自RedisTemplate, 即 <bean id="redisTemplate" class=&quo
-
spring boot+redis 监听过期Key的操作方法
前言: 在订单业务中,有时候需要对订单设置有效期,有效期到了后如果还未支付,就需要修改订单状态.对于这种业务的实现,有多种不同的办法,比如: 1.使用querytz,每次生成一个订单,就创建一个定时任务,到期后执行业务代码: 2.rabbitMq中的延迟队列: 3.对Redis的Key进行监控: 1.引入依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring
-
redis批量删除key的步骤
由于误用插件,某台服务器上的redis实例存在数百万无用的key.为了删除无用数据,上网查找redis批量删除key的方法,发现使用过程中都有问题.经过本人的研究,终于找到redis批量删除key的正确用法. 本文分享最新版Redis批量删除key的方法,希望能帮到遇到同样问题的网友. redis批量删除key 网上许多文章和教程给出的redis批量删除key命令是: redis-cli KEYS "$PATTERN" | xargs redis-cli DEL 在本人的实践中,这条命
-
Java使用RedisTemplate模糊删除key操作
Redis模糊匹配批量删除操作,使用RedisTemplate操作: public void deleteByPrex(String prex) { Set<String> keys = redisTemplate.keys(prex); if (CollectionUtils.isNotEmpty(keys)) { redisTemplate.delete(keys); } } prex为迷糊匹配的key,如cache:user:* 这里需要判断keys是否存在,如果一个都匹配不到会报错:
-
浅谈Redis的key和value大小限制
今天研究了下将java bean序列化到redis中存储起来,突然脑袋灵光一闪,对象大小会不会超过redis限制?不管怎么着,还是搞清楚一下比较好,所以就去问了下百度,果然没多少人关心这个问题,没找到比较合适的答案,所以决定还是去官网找吧. 找到两句比较关键的话, 截图如下. 结论 redis的key和string类型value限制均为512MB. 补充知识:Redis获取所有键值 通过遍历获取目标键值: import redis redis = redis.Redis(host='192.24
-
基于redis key占用内存量分析
Redis的指令看不出哪一类型的key,占用了多少内存,不好分析redis内存开销大的情况下,各应用程序使用缓存的占比. 借助第3方工具进行分析 1.采用2个工具结合 redis-rdb-tools+sqlite 2.sqlite linux服务器都会自带,安装redis-rdb-tools 使用pip安装 pip install redis-rdb-tools 源码安装 git clone https://github.com/sripathikrishnan/redis-rdb-tools
-
springBoot集成redis的key,value序列化的相关问题
使用的是maven工程 springBoot集成redis默认使用的是注解,在官方文档中只需要2步; 1.在pom文件中引入即可 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-redis</artifactId> </dependency> 2.编写一个CacheService接口,使用redisCach
-
Redis集群下过期key监听的实现代码
1. 前言 在使用redis集群时,发现过期key始终监听不到.网上也没有现成的解决方案.于是想,既然不能监听集群,那我可以建立多个redis连接,分别对每个redis的key过期进行监听.以上做法可能不尽人意,目前也没找到好的解决方案,如果有好的想法,请留言告知哦!不多说,直接贴我自己的代码! 2. 代码实现 关于Redis集群配置代码此处不贴,直接贴配置监听类代码! redis.host1: 10.113.56.68 redis.port1: 7030 redis.host2: 10.113
-
Redis大key多key拆分实现方法解析
背景 业务场景中经常会有各种大key多key的情况, 比如: 1:单个简单的key存储的value很大 2:hash, set,zset,list 中存储过多的元素(以万为单位) 3:一个集群存储了上亿的key,Key 本身过多也带来了更多的空间占用 (如无意外,文章中所提及的hash,set等数据结构均指redis中的数据结构 ) 由于redis是单线程运行的,如果一次操作的value很大会对整个redis的响应时间造成负面影响,所以,业务上能拆则拆,下面举几个典型的分拆方案. 一.单个简单的
-
关于redis Key淘汰策略的实现方法
1 配置文件中的最大内存删除策略 在redis的配置文件中,可以设置redis内存使用的最大值,当redis使用内存达到最大值时(如何知道已达到最大值?),redis会根据配置文件中的策略选取要删除的key,并删除这些key-value的值.若根据配置的策略,没有符合策略的key,也就是说内存已经容不下新的key-value了,但此时有不能删除key,那么这时候写的话,将会出现写错误. 1.1 最大内存参数设置 若maxmemory参数设置为0,则分两种情况: *在64位系统上,表示没有限制.
-
spring redis 如何实现模糊查找key
spring redis 模糊查找key 用法 Set<String> keySet = stringRedisTemplate.keys("keyprefix:"+"*"); 需要使用StringRedisTemplate,或自定义keySerializer为StringRedisSerializer的redisTemplate redis里模糊查询key允许使用的通配符: * 任意多个字符 ? 单个字符 [] 括号内的某1个字符 源码 org.spr
-

Redis什么是热Key问题以及如何解决热Key问题
目录 一.什么是热Key? 二.热Key产生的原因? 三.热点Key的危害? 四.如何识别热点Key? 五.如何解决热Key问题? 一.什么是热Key? 在Redis中,我们把访问频率高的Key,称为热Key. 比如突然又几十万的请求去访问redis中某个特定的Key,那么这样会造成redis服务器短时间流量过于集中,很可能导致redis的服务器宕机. 那么接下来对这个Key的请求,都会直接请求到我们的后端数据库中,数据库性能本来就不高,这样就可能直接压垮数据库,进而导致后端服务不可用. 二.热
-
linux系统重装导致免密码key登录失败的解决方法
在一台linux机器上ssh远程另外一台linux服务器时候出现: [root@server .ssh]# ssh 192.0.50.80 @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ @ WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! @ @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
-
PHP实现向关联数组指定的Key之前插入元素的方法
本文实例讲述了PHP实现向关联数组指定的Key之前插入元素的方法.分享给大家供大家参考,具体如下: PHP 关联数组可以通过三种方式插入新元素: 1. $array[$insert_key] = $insert_value; 2. $array = array_merge($array, $insert_array); 3. $array = $array+$insert_array; 但是如果要在指定的键之前插入元素呢?下面的代码将 $data 插入关联数组 $array 的键名为 $key
-
php恢复数组的key为数字序列的方法
本文实例讲述了php恢复数组的key为数字序列的方法.分享给大家供大家参考.具体分析如下: 这里实现php把数组的key值恢复成类似于0,1,2,3,4,5...这样的数字序列 function restore_array($arr){ if (!is_array($arr)){ return $arr; } $c = 0; $new = array(); while (list($key, $value) = each($arr)){ if (is_array($value)){ $new[$
-
Laravel框架运行出错提示RuntimeException No application encryption key has been specified.解决方法
本文实例讲述了Laravel框架运行出错提示RuntimeException No application encryption key has been specified.解决方法.分享给大家供大家参考,具体如下: ①在项目根目录放置.env文件 .env APP_NAME=Laravel APP_ENV=local APP_KEY= APP_DEBUG=true APP_LOG_LEVEL=debug APP_URL=http://localhost DB_CONNECTION=mysql
-
Java中对list map根据map某个key值进行排序的方法
实例如下所示: package test; import java.util.ArrayList; import java.util.Collections; import java.util.Comparator; import java.util.HashMap; import java.util.List; import java.util.Map; public class java_ListMapSort { public static void main(String[] args)
-
python redis 批量设置过期key过程解析
这篇文章主要介绍了python redis 批量设置过期key过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 在使用 Redis.Codis 时,我们经常需要做一些批量操作,通过连接数据库批量对 key 进行操作: 关于未过期: 1.常有大批量的key未设置过期,导致内存一直暴增 2.rd需求 扫描出这些key,rd自己处理过期(一般dba不介入数据的修改) 3.dba 批量设置过期时间,(一般测试可以直接批量设置,线上谨慎操作) 通过