使用numpy对数组求平均时如何忽略nan值
目录
- numpy对数组求平均时忽略nan值
- 使用np.mean()的效果
- 使用np.nanmean()的效果
- numpy含nan值进行归一化操作
- 方法一
- 方法二
numpy对数组求平均时忽略nan值
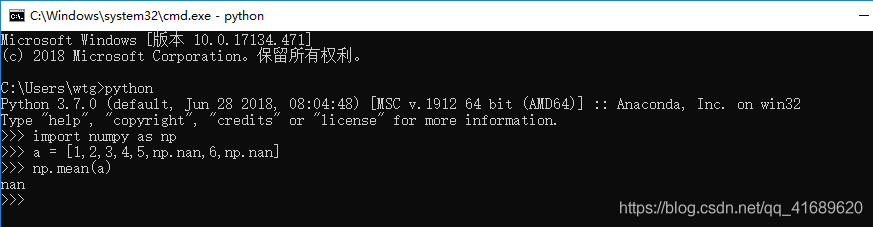
在对numpy数组求平均np.mean()或者求数组中最大最小值np.max()/np.min()时,如果数组中有nan,此时求得的结果为:nan,那么该如何忽略其中的nan呢?
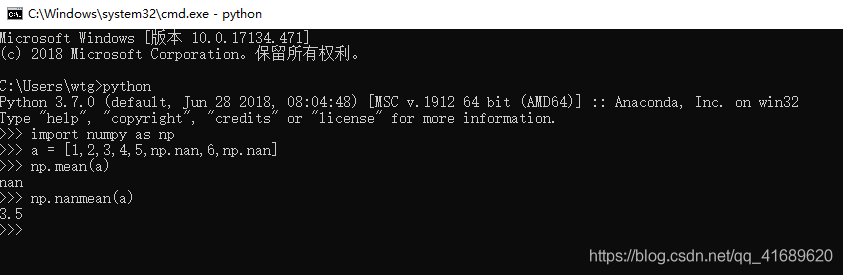
此时应该用另一个方法
np.nanmean(),np.nanmax(),np.nanmin()
使用np.mean()的效果
使用np.nanmean()的效果
numpy含nan值进行归一化操作
方法一
import numpy as np
A = np.array([[ 7, 4, 5, 7000],
[ 1, 900, 9, nan],
[ 5, -1000, nan, 100],
[nan, nan, 3, 1000]])
#Compute NaN-norms
L1_norm = np.nansum(np.abs(A), axis=1)
L2_norm = np.sqrt(np.nansum(A**2, axis=1))
max_norm = np.nanmax(np.abs(A), axis=1)
#Normalize rows
A_L1 = A / L1_norm[:,np.newaxis] # A.values if Dataframe
A_L2 = A / L2_norm[:,np.newaxis]
A_max = A / max_norm[:,np.newaxis]
#Check that it worked
L1_norm_after = np.nansum(np.abs(A_L1), axis=1)
L2_norm_after = np.sqrt(np.nansum(A_L2**2, axis=1))
max_norm_after = np.nanmax(np.abs(A_max), axis=1)
In[182]: L1_norm_after
Out[182]: array([1., 1., 1., 1.])
In[183]: L2_norm_after
Out[183]: array([1., 1., 1., 1.])
In[184]: max_norm_after
Out[184]: array([1., 1., 1., 1.])
方法二
rom numpy import nan, nanmean
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
A = [[ 7, 4, 5, 7000],
[ 1, 900, 9, nan],
[ 5, -1000, nan, 100],
[nan, nan, 3, 1000]]
scaler.fit(A)
In [45]: scaler.mean_
Out[45]: array([4.33333333, -32., 5.66666667, 2700.])
In [46]: scaler.transform(A)
Out[46]: array([[ 1.06904497, 0.04638641, -0.26726124, 1.40399977],
[-1.33630621, 1.20089267, 1.33630621, nan],
[ 0.26726124, -1.24727908, nan, -0.84893009],
[ nan, nan, -1.06904497, -0.55506968]])
In [54]: nanmean(scaler.transform(A), axis=0)
Out[54]: array([ 1.48029737e-16, 0.00000000e+00, -1.48029737e-16,0.00000000e+00])
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python过滤掉numpy.array中非nan数据实例
代码 需要先导入pandas arr的数据类型为一维的np.array import pandas as pd arr[~pd.isnull(arr)] 补充知识:python numpy.mean() axis参数使用方法[sum(axis=*)是求和,mean(axis=*)是求平均值] 如下所示: import numpy as np X = np.array([[1, 2], [4, 5], [7, 8]]) print(np.mean(X, axis=0, keepdims=True)
-
numpy 对矩阵中Nan的处理:采用平均值的方法
尽管我们可以将所有的NaN替换成0,但是由于并不知道这些值的意义,所以这样做是个下策.如果它们是开氏温度,那么将它们置成0这种处理策略就太差劲了. 下面我们用平均值来代替缺失值,平均值根据那些非NaN得到. from numpy import * datMat = mat([[1,2,3],[4,Nan,6]]) numFeat = shape(datMat)[1] for i in range(numFeat): meanVal = mean(datMat[nonzero(~isnan(dat
-
Python Numpy:找到list中的np.nan值方法
这个问题源于在训练机器学习的一个模型时,使用训练数据时提示prepare的数据中存在np.nan 报错信息如下: ValueError: np.nan is an invalid document, expected byte or unicode string. 刚开始不知道为什么会有这个,后来发现是list中存在nan值 下面是找到nan值的方法: 简单找到: import numpy as np x = np.array([2,3,np.nan,5, np.nan,5,2,3]) for
-

使用numpy对数组求平均时如何忽略nan值
目录 numpy对数组求平均时忽略nan值 使用np.mean()的效果 使用np.nanmean()的效果 numpy含nan值进行归一化操作 方法一 方法二 numpy对数组求平均时忽略nan值 在对numpy数组求平均np.mean()或者求数组中最大最小值np.max()/np.min()时,如果数组中有nan,此时求得的结果为:nan,那么该如何忽略其中的nan呢? 此时应该用另一个方法 np.nanmean(),np.nanmax(),np.nanmin() 使用np.mean()的
-
python NumPy ndarray二维数组 按照行列求平均实例
我就废话不多说了,直接上代码吧! c = np.array([[1, 2, 3, 4], [4, 5, 6, 7], [7, 8, 9, 10]]) print(c.mean(axis=1))#行 print(c.mean(axis=0))#列 输出为: [ 2.5 5.5 8.5] [ 4. 5. 6. 7.] 以上这篇python NumPy ndarray二维数组 按照行列求平均实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
Python:Numpy 求平均向量的实例
如下所示: >>> import numpy as np >>> a = np.array([[1, 2, 3], [3, 1, 2]]) >>> b = np.array([[5, 2, 6], [5, 1, 2]]) >>> a array([[1, 2, 3], [3, 1, 2]]) >>> b array([[5, 2, 6], [5, 1, 2]]) >>> c = a + b >
-
python+numpy按行求一个二维数组的最大值方法
问题描述: 给定一个二维数组,求每一行的最大值 返回一个列向量 如: 给定数组[1,2,3:4,5,3] 返回[3:5] import numpy as np x = np.array([[1,2,3],[4,5,3]]) # 先求每行最大值得下标 index_max = np.argmax(x, axis=1)# 其中,axis=1表示按行计算 print(index_max.shape) max = x[range(x.shape[0]), index_max] print(max) # 注
-
基于Python Numpy的数组array和矩阵matrix详解
NumPy的主要对象是同种元素的多维数组.这是一个所有的元素都是一种类型.通过一个正整数元组索引的元素表格(通常是元素是数字). 在NumPy中维度(dimensions)叫做轴(axes),轴的个数叫做秩(rank,但是和线性代数中的秩不是一样的,在用python求线代中的秩中,我们用numpy包中的linalg.matrix_rank方法计算矩阵的秩,例子如下). 结果是: 线性代数中秩的定义:设在矩阵A中有一个不等于0的r阶子式D,且所有r+1阶子式(如果存在的话)全等于0,那末D称为矩阵
-
Python numpy 点数组去重的实例
废话不多说,直接上代码,有详细注释 # coding = utf-8 import numpy as np from IPython import embed # xy 输入,可支持浮点数操作 速度很快哦 # return xy 去重后结果 def duplicate_removal(xy): if xy.shape[0] < 2: return xy _tmp = (xy*4000).astype('i4') # 转换成 i4 处理 _tmp = _tmp[:,0] + _tmp[:,1]*1
-
浅谈numpy生成数组的零值问题
今天在用numpy写sinc函数时偶然发现在x=0时函数居然能取到1,觉得很不可思议,按理来说在x=0时函数无意义,研究了一下,发现竟然时numpy在生成数组时自动用一个很小的数代替了0. In[2]: import numpy as np In[3]: np.arange(-1, 1, 0.1) Out[3]: array([ -1.00000000e+00, -9.00000000e-01, -8.00000000e-01, -7.00000000e-01, -6.00000000e-01,
-
python3 numpy中数组相乘np.dot(a,b)运算的规则说明
python np.dot(a,b)运算规则解析 首先我们知道dot运算时不满足交换律的,np.dot(a, b)与np.dot(b, a)是不一样的 另外np.dot(a,b)和a.dot(b)果是一样的 1.numpy中数组相乘np.dot(a,b)运算条件: 对于两数组a和b : 示例一: a = np.array([[3], [3], [3]]) # (3,1) b = np.array([2, 2, 1]) # (3,) print(a, "\na的shape", a.sha
-
解决Numpy与Pytorch彼此转换时的坑
前言 最近使用 Numpy包与Pytorch写神经网络时,经常需要两者彼此转换,故用此笔记记录码代码时踩(菜)过的坑,网上有人说: Pytorch 又被称为 GPU 版的 Numpy,二者的许多功能都有良好的一一对应. 但在使用时还是得多多注意,一个不留神就陷入到了 一根烟一杯酒,一个Bug找一宿 的地步. 1.1.numpy --> torch 使用 torch.from_numpy() 转换,需要注意,两者共享内存.例子如下: import torch import num
-
如何将numpy二维数组中的np.nan值替换为指定的值
基础知识: (1)np.nan表示该值不是一个数,比如数据中收入.年龄的缺失值:np.inf表示无穷大 (2)np.nan == np.nan 的结果为False (3)nan与任何数的操作结果均为nan,例如sum((np.nan,4)) 的结果为nan (4)一个ndarray数组t1,可以用np.isnan(t1) 定位到nan值的位置,再用t1[np.isnan(t1)] = 指定值 将nan替换为指定值 (5)np.nan_to_num(t1),可以将t1中的nan替换为0 (6)t1