五个Pandas 实战案例带你分析操作数据
目录
- 构建数据
- 分析维度1:时间
- 2019-2021年每月销量走势
- 2019-2021销售额走势
- 年度销量、销售额和平均销售额
- 分析维度2:商品
- 水果年度销量占比
- 各水果年度销售金额对比
- 商品月度销量变化
- 分析维度3:地区
- 不同地区的销量
- 分析维度4:用户
- 用户订单量、金额对比
- 用户水果喜好
- 用户分层—RFM模型
- 用户复购周期分析
大家好,之前分享过很多关于 Pandas 的文章,今天我给大家分享5个小而美的 Pandas 实战案例。
内容主要分为:
- 如何自行模拟数据
- 多种数据处理方式
- 数据统计与可视化
- 用户RFM模型
- 用户复购周期
构建数据
本案例中用的数据是小编自行模拟的,主要包含两个数据:订单数据和水果信息数据,并且会将两份数据合并
import pandas as pd import numpy as np import random from datetime import * import time import plotly.express as px import plotly.graph_objects as go import plotly as py # 绘制子图 from plotly.subplots import make_subplots
1、时间字段
2、水果和用户

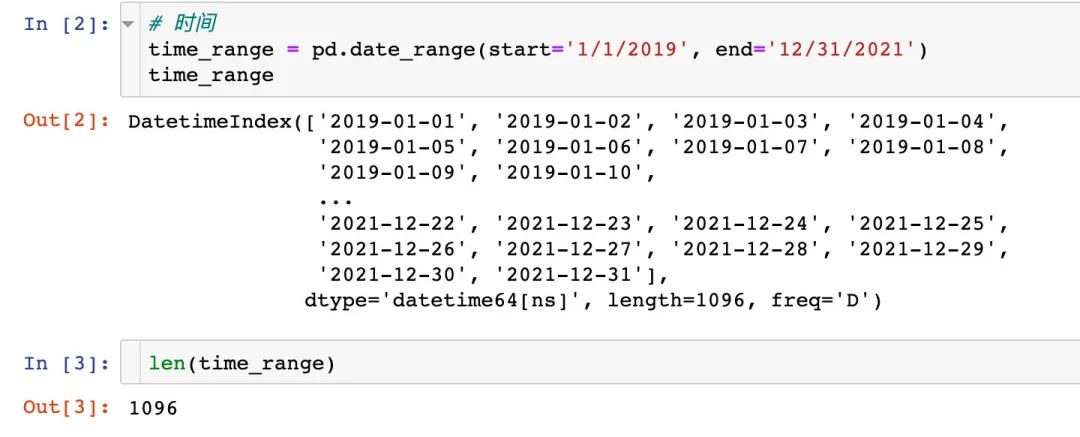
3、生成订单数据
order = pd.DataFrame({
"time":time_range, # 下单时间
"fruit":fruit_list, # 水果名称
"name":name_list, # 顾客名
# 购买量
"kilogram":np.random.choice(list(range(50,100)), size=len(time_range),replace=True)
})
order
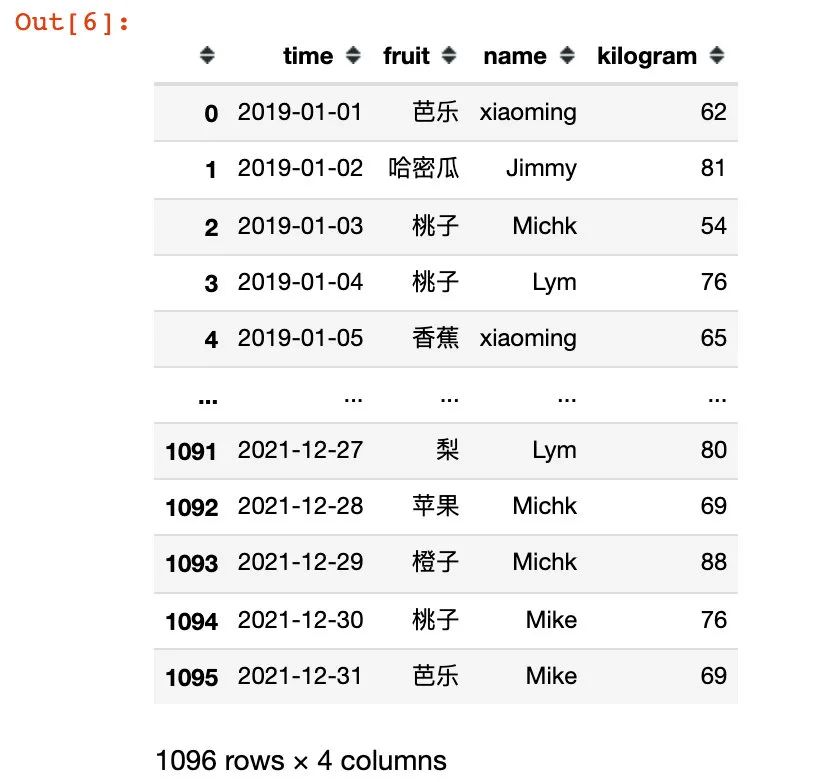
4、生成水果的信息数据
infortmation = pd.DataFrame({
"fruit":fruits,
"price":[3.8, 8.9, 12.8, 6.8, 15.8, 4.9, 5.8, 7],
"region":["华南","华北","西北","华中","西北","华南","华北","华中"]
})
infortmation
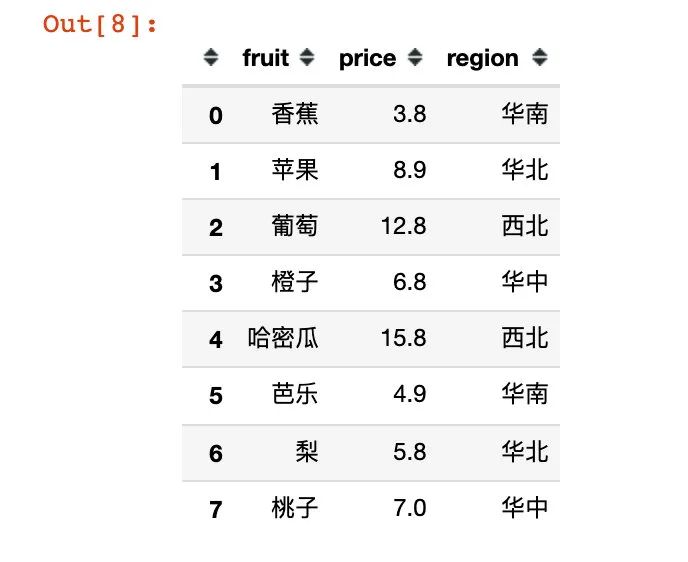
5、数据合并
将订单信息和水果信息直接合并成一个完整的DataFrame,这个df就是接下来处理的数据

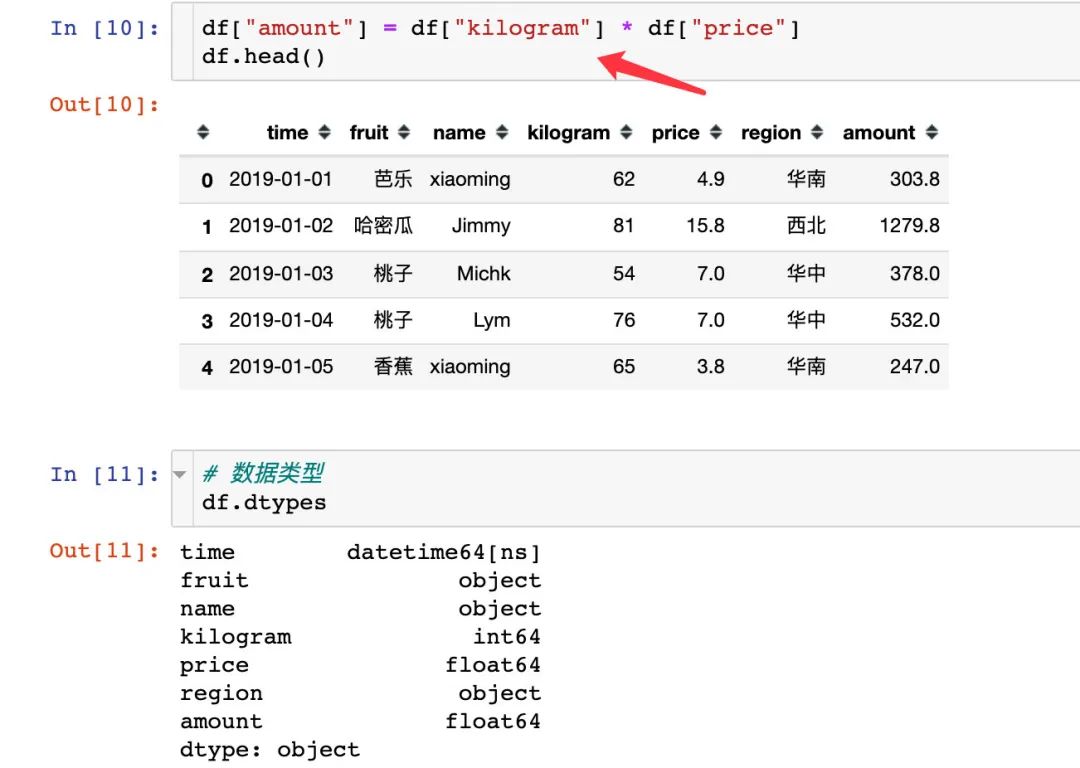
6、生成新的字段:订单金额
到这里你可以学到:
- 如何生成时间相关的数据
- 如何从列表(可迭代对象)中生成随机数据
- Pandas的DataFrame自行创建,包含生成新字段
- Pandas数据合并
分析维度1:时间
2019-2021年每月销量走势
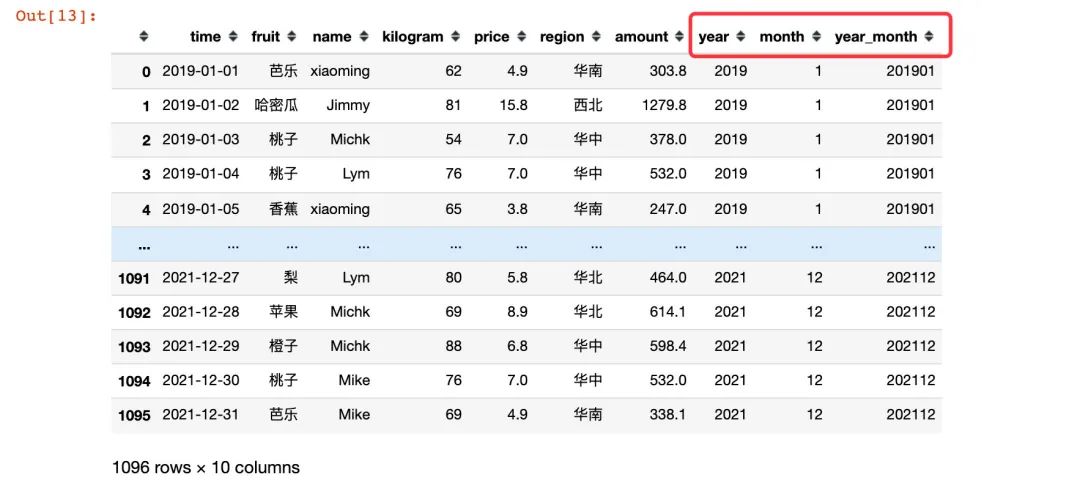
1、先把年份和月份提取出来:
df["year"] = df["time"].dt.year
df["month"] = df["time"].dt.month
# 同时提取年份和月份
df["year_month"] = df["time"].dt.strftime('%Y%m')
df
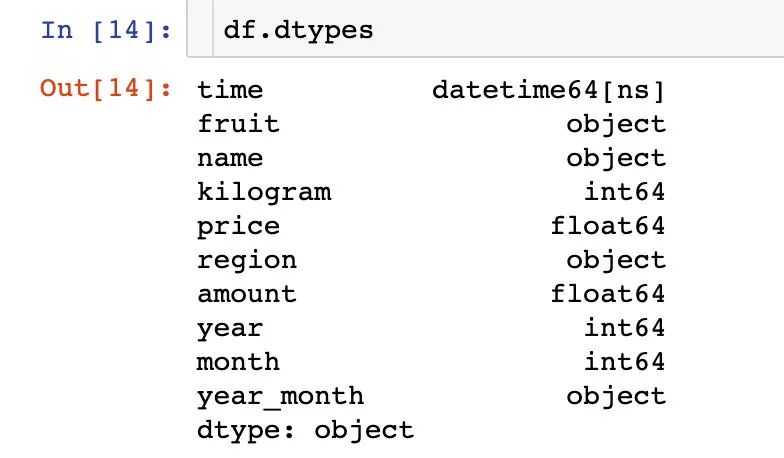
2、查看字段类型:
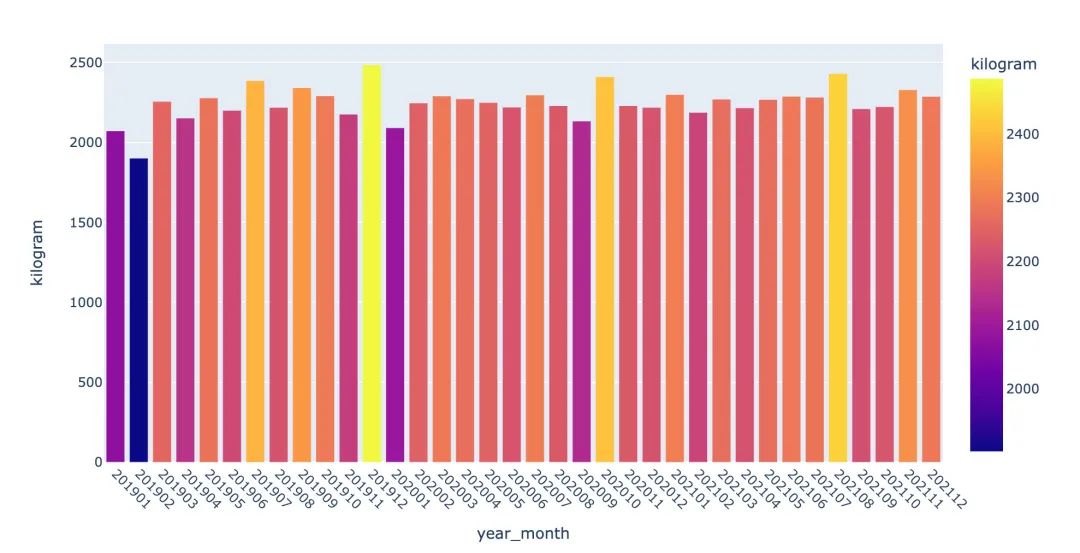
3、分年月统计并展示:
# 分年月统计销量 df1 = df.groupby(["year_month"])["kilogram"].sum().reset_index() fig = px.bar(df1,x="year_month",y="kilogram",color="kilogram") fig.update_layout(xaxis_tickangle=45) # 倾斜角度 fig.show()
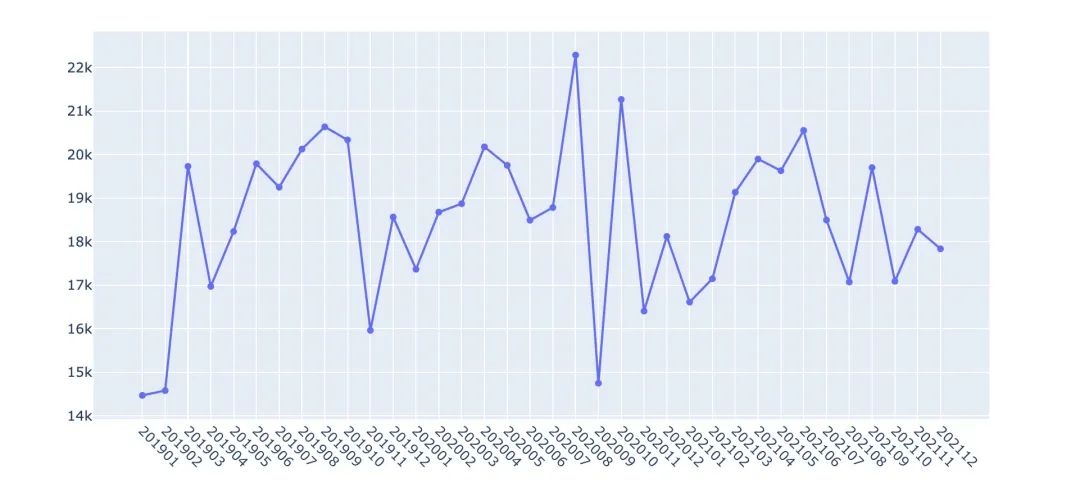
2019-2021销售额走势
df2 = df.groupby(["year_month"])["amount"].sum().reset_index()
df2["amount"] = df2["amount"].apply(lambda x:round(x,2))
fig = go.Figure()
fig.add_trace(go.Scatter( #
x=df2["year_month"],
y=df2["amount"],
mode='lines+markers', # mode模式选择
name='lines')) # 名字
fig.update_layout(xaxis_tickangle=45) # 倾斜角度
fig.show()
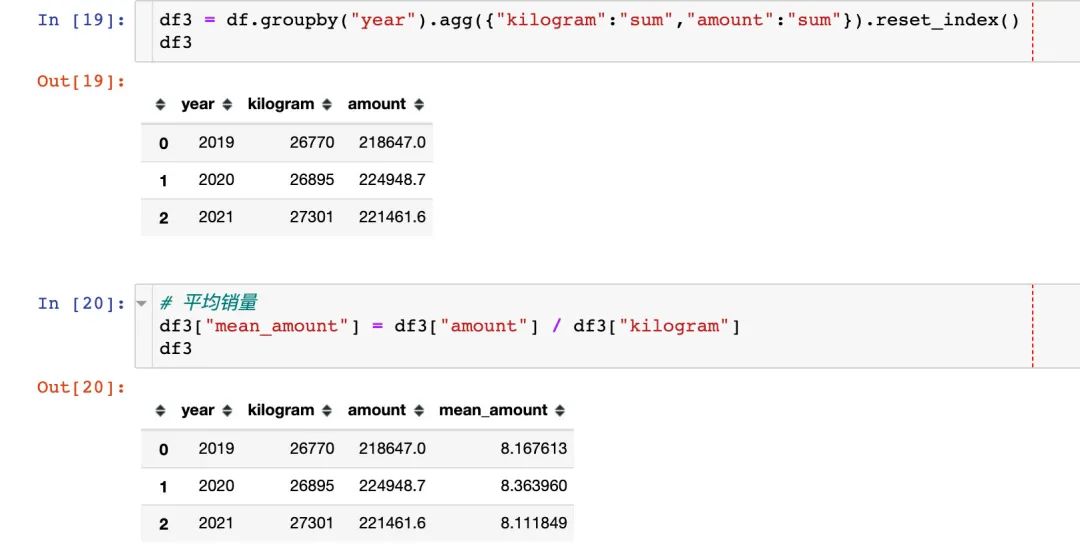
年度销量、销售额和平均销售额
分析维度2:商品
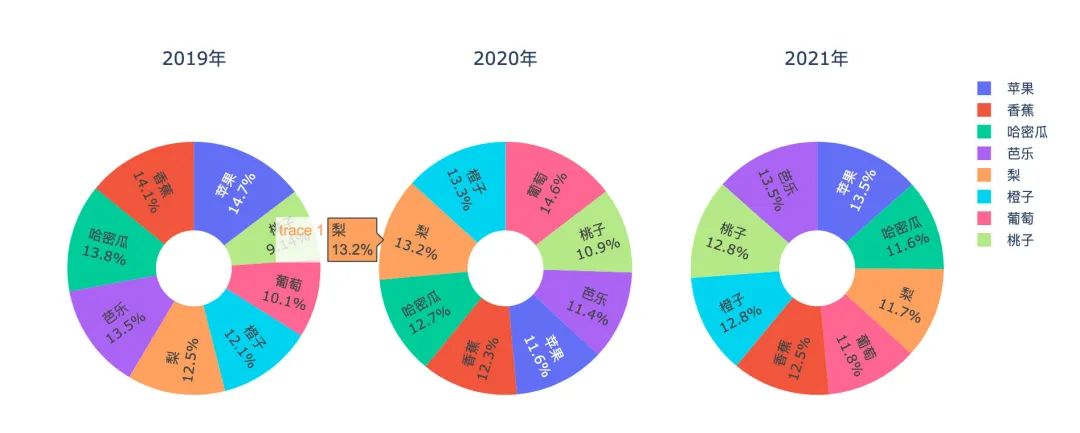
水果年度销量占比
df4 = df.groupby(["year","fruit"]).agg({"kilogram":"sum","amount":"sum"}).reset_index()
df4["year"] = df4["year"].astype(str)
df4["amount"] = df4["amount"].apply(lambda x: round(x,2))
from plotly.subplots import make_subplots
import plotly.graph_objects as go
fig = make_subplots(
rows=1,
cols=3,
subplot_titles=["2019年","2020年","2021年"],
specs=[[{"type": "domain"}, # 通过type来指定类型
{"type": "domain"},
{"type": "domain"}]]
)
years = df4["year"].unique().tolist()
for i, year in enumerate(years):
name = df4[df4["year"] == year].fruit
value = df4[df4["year"] == year].kilogram
fig.add_traces(go.Pie(labels=name,
values=value
),
rows=1,cols=i+1
)
fig.update_traces(
textposition='inside', # 'inside','outside','auto','none'
textinfo='percent+label',
insidetextorientation='radial', # horizontal、radial、tangential
hole=.3,
hoverinfo="label+percent+name"
)
fig.show()
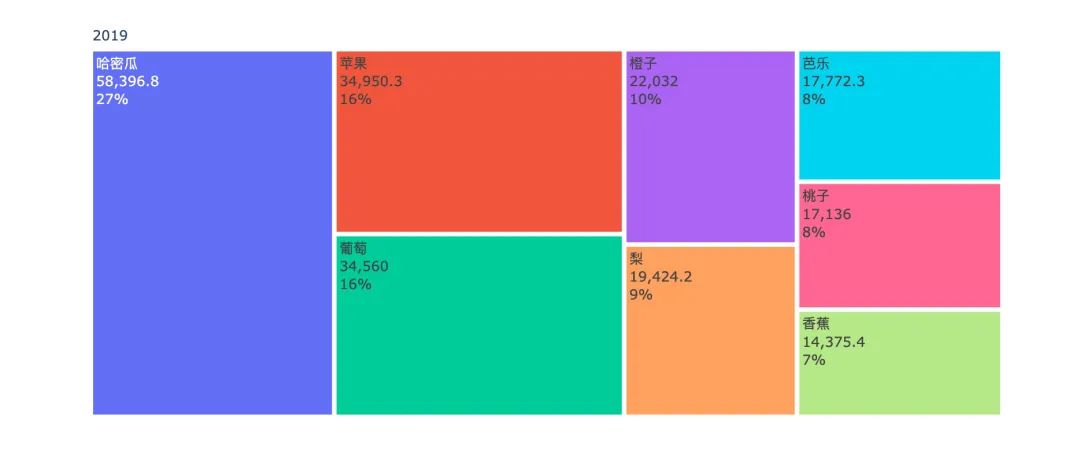
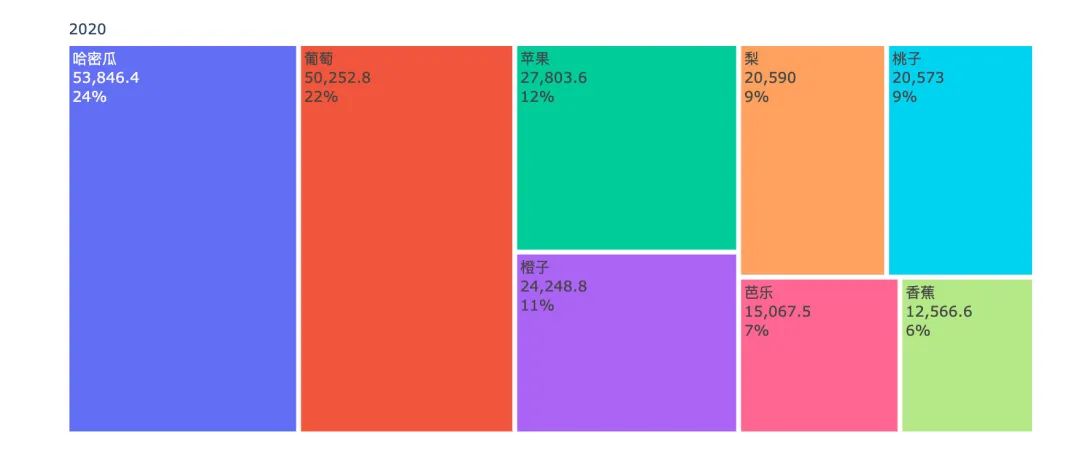
各水果年度销售金额对比
years = df4["year"].unique().tolist()
for _, year in enumerate(years):
df5 = df4[df4["year"]==year]
fig = go.Figure(go.Treemap(
labels = df5["fruit"].tolist(),
parents = df5["year"].tolist(),
values = df5["amount"].tolist(),
textinfo = "label+value+percent root"
))
fig.show()

商品月度销量变化
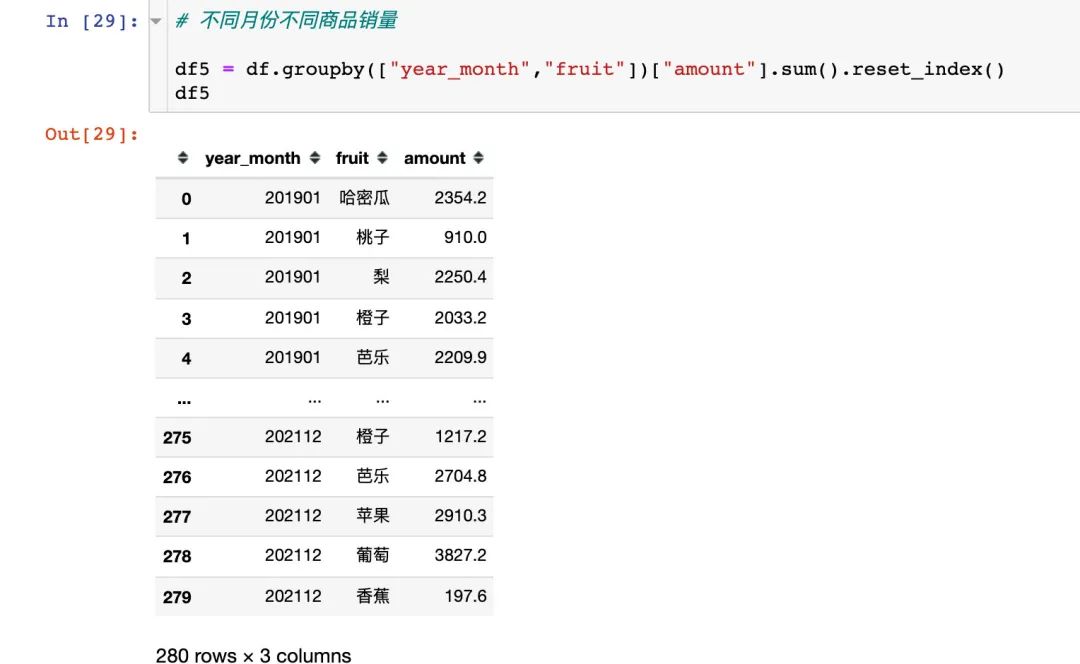
fig = px.bar(df5,x="year_month",y="amount",color="fruit") fig.update_layout(xaxis_tickangle=45) # 倾斜角度 fig.show()
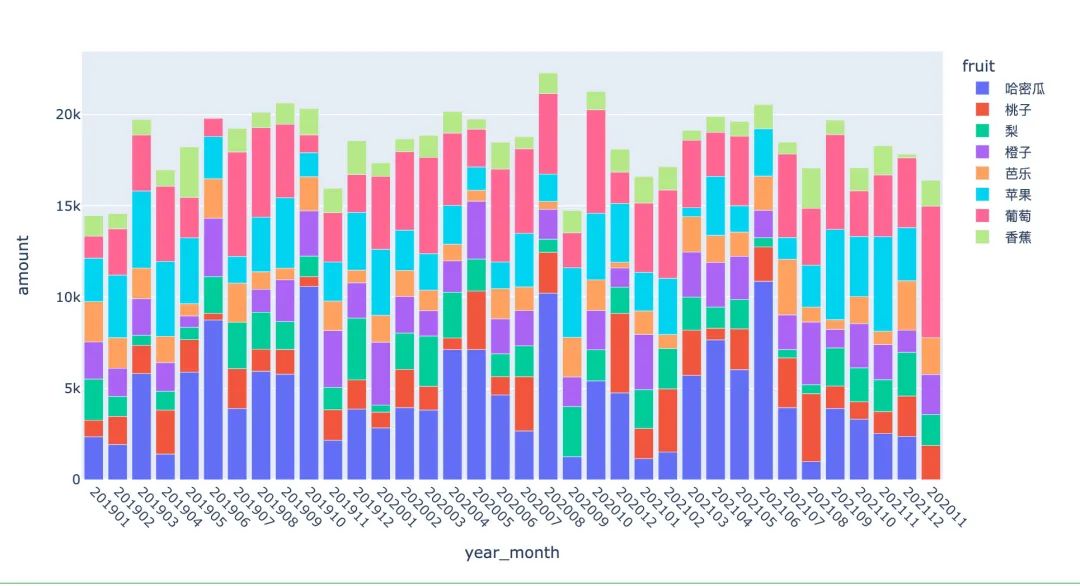
折线图展示的变化:
分析维度3:地区
不同地区的销量

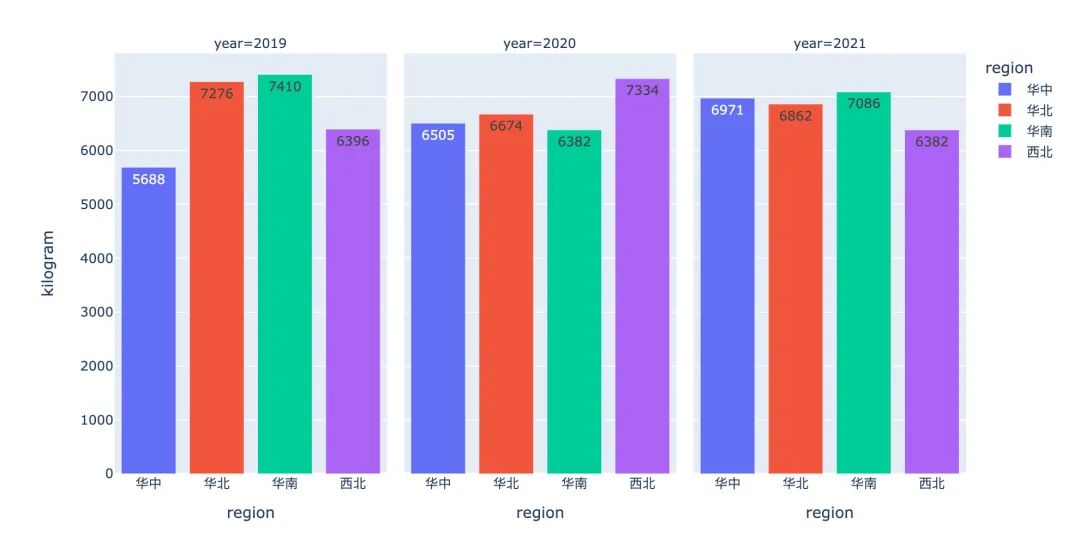
不同地区年度平均销售额
df7 = df.groupby(["year","region"])["amount"].mean().reset_index()

分析维度4:用户
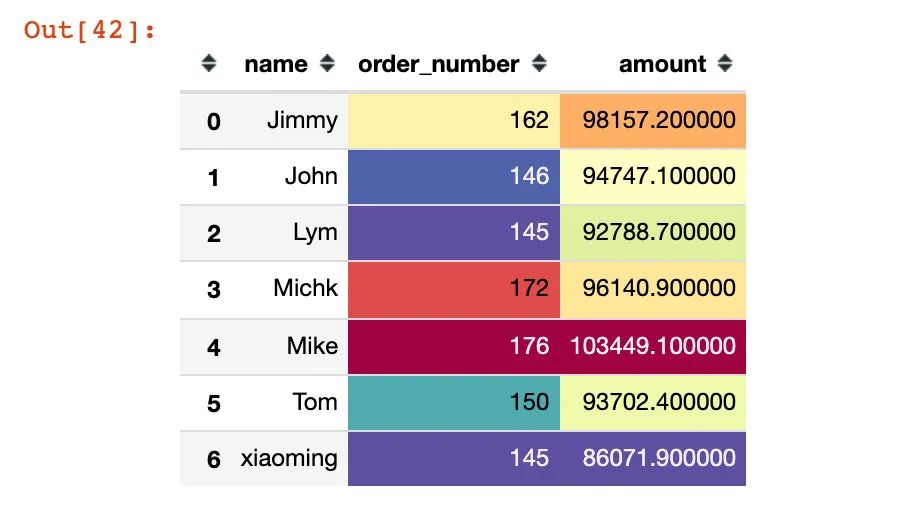
用户订单量、金额对比
df8 = df.groupby(["name"]).agg({"time":"count","amount":"sum"}).reset_index().rename(columns={"time":"order_number"})
df8.style.background_gradient(cmap="Spectral_r")
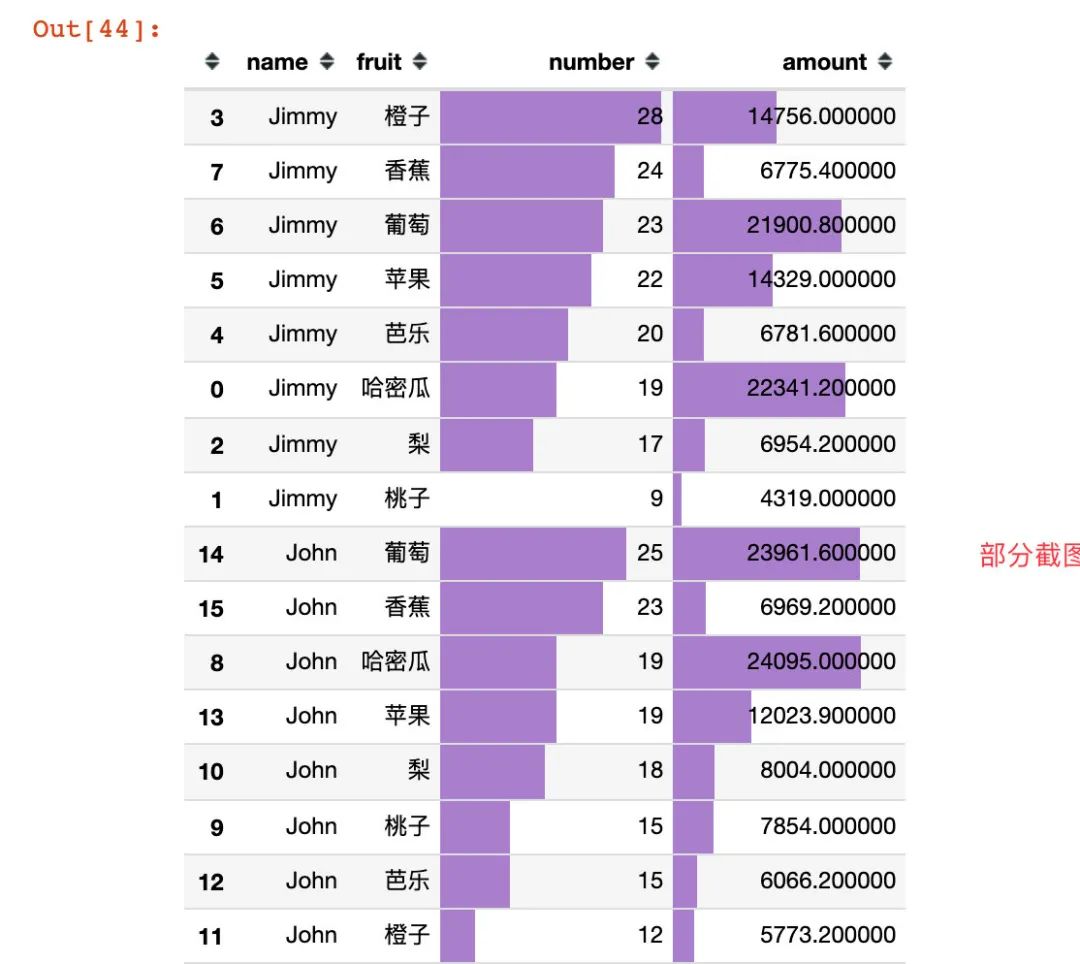
用户水果喜好
根据每个用户对每种水果的订单量和订单金额来分析:
df9 = df.groupby(["name","fruit"]).agg({"time":"count","amount":"sum"}).reset_index().rename(columns={"time":"number"})
df10 = df9.sort_values(["name","number","amount"],ascending=[True,False,False])
df10.style.bar(subset=["number","amount"],color="#a97fcf")
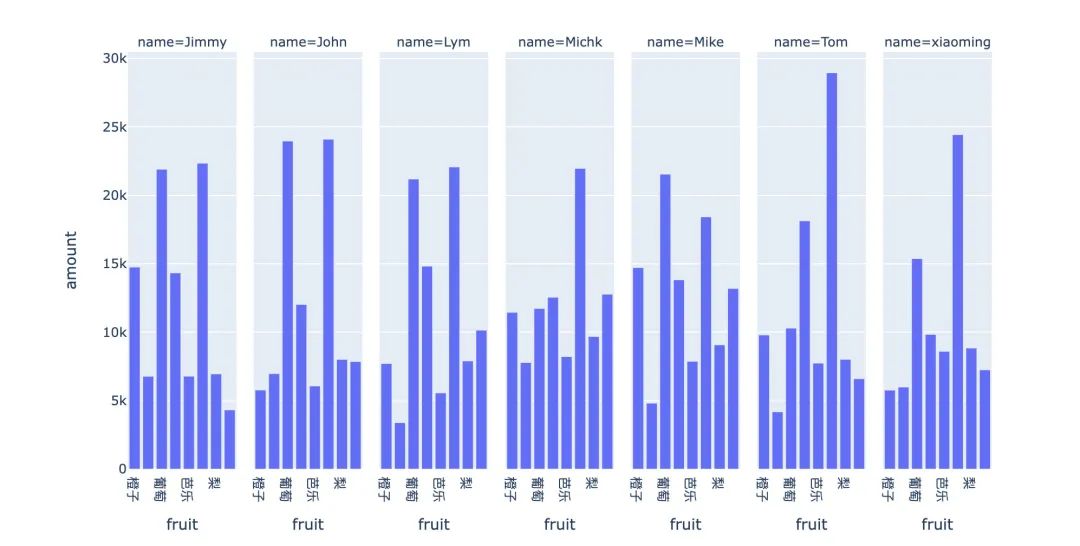
px.bar(df10,
x="fruit",
y="amount",
# color="number",
facet_col="name"
)
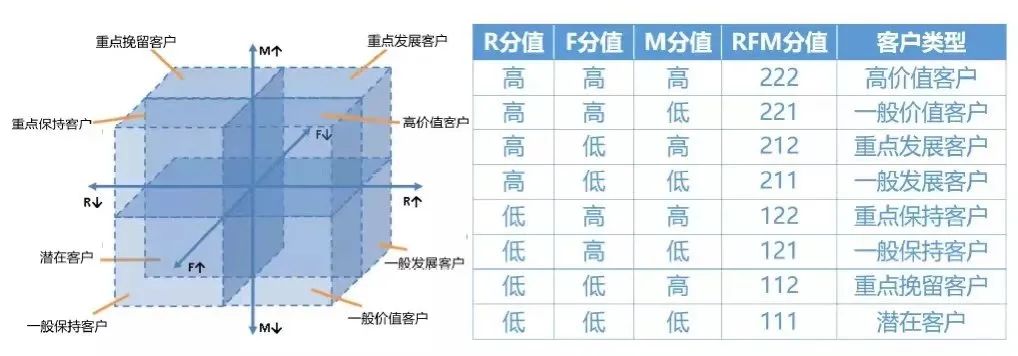
用户分层—RFM模型
RFM模型是衡量客户价值和创利能力的重要工具和手段。
通过这个模型能够反映一个用户的交期交易行为、交易的总体频率和总交易金额3项指标,通过3个指标来描述该客户的价值状况;同时依据这三项指标将客户划分为8类客户价值:
- Recency(R)是客户最近一次购买日期距离现在的天数,这个指标与分析的时间点有关,因此是变动的。理论上客户越是在近期发生购买行为,就越有可能复购
- Frequency(F)指的是客户发生购买行为的次数–最常购买的消费者,忠诚度也就较高。增加顾客购买的次数意味着能占有更多的时长份额。
- Monetary value(M)是客户购买花费的总金额。
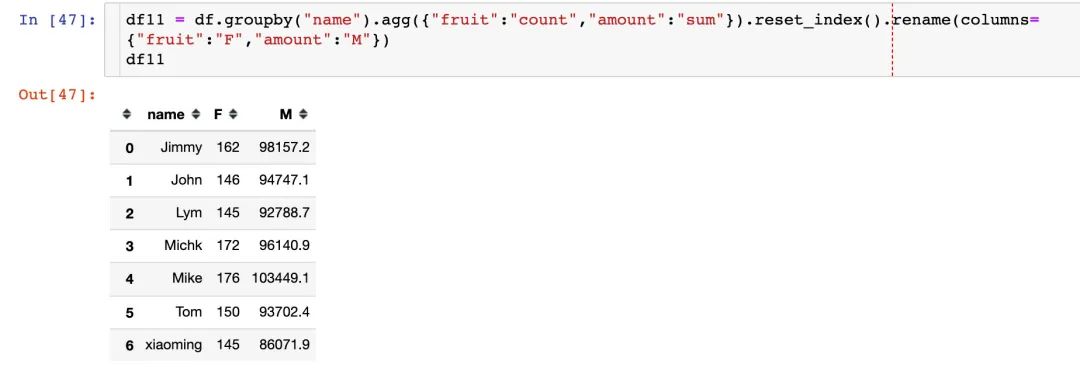
下面通过Pandas的多个方法来分别求解这个3个指标,首先是F和M:每位客户的订单次数和总金额
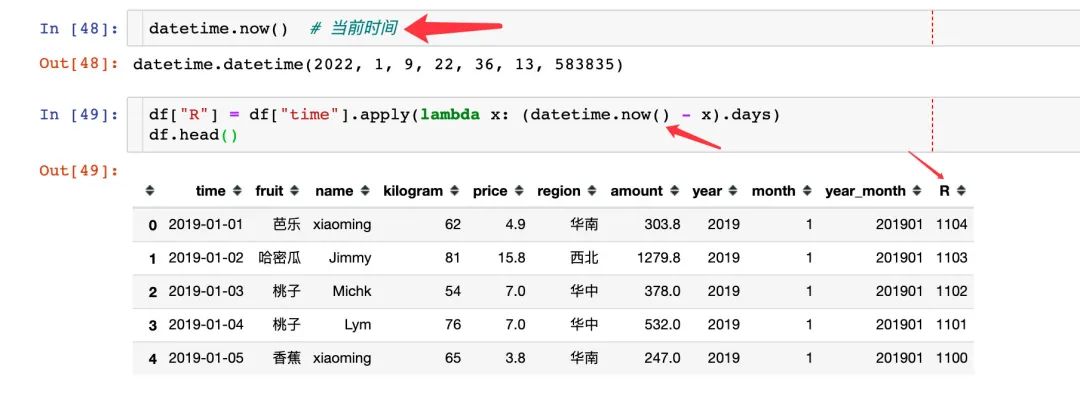
如何求解R指标呢?
1、先求解每个订单和当前时间的差值
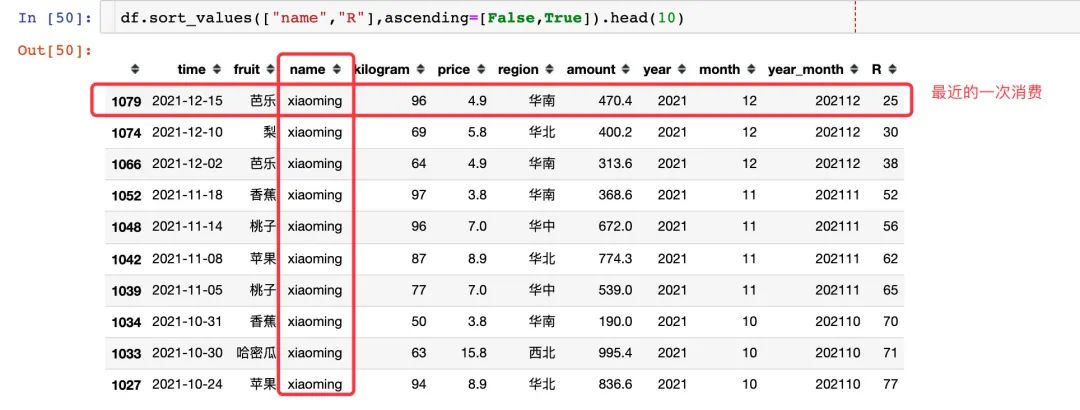
2、根据每个用户的这个差值R来进行升序排列,排在第一位的那条数据就是他最近购买记录:以xiaoming用户为例,最近一次是12月15号,和当前时间的差值是25天
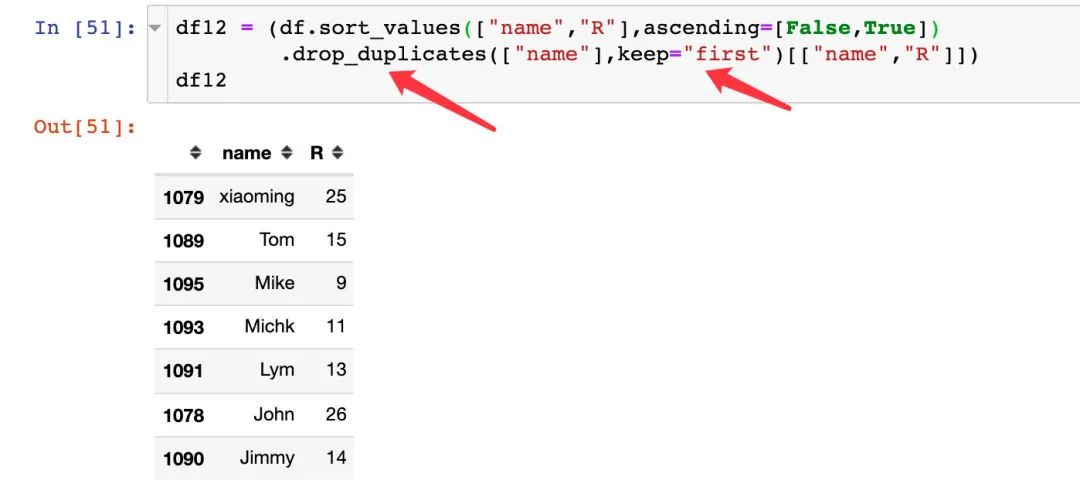
3、根据用户去重,保留第一条数据,这样便得到每个用户的R指标:
4、数据合并得到3个指标:
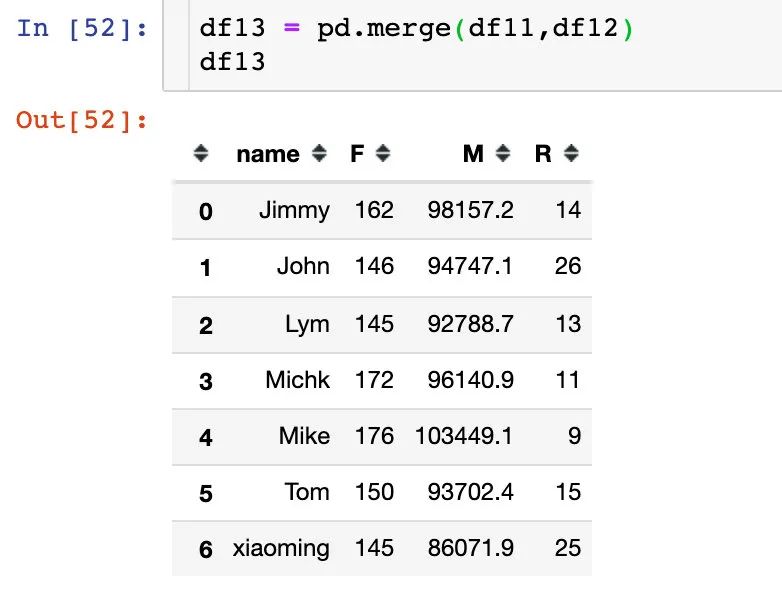

当数据量足够大,用户足够多的时候,就可以只用RFM模型来将用户分成8个类型
用户复购周期分析
复购周期是用户每两次购买之间的时间间隔:以xiaoming用户为例,前2次的复购周期分别是4天和22天
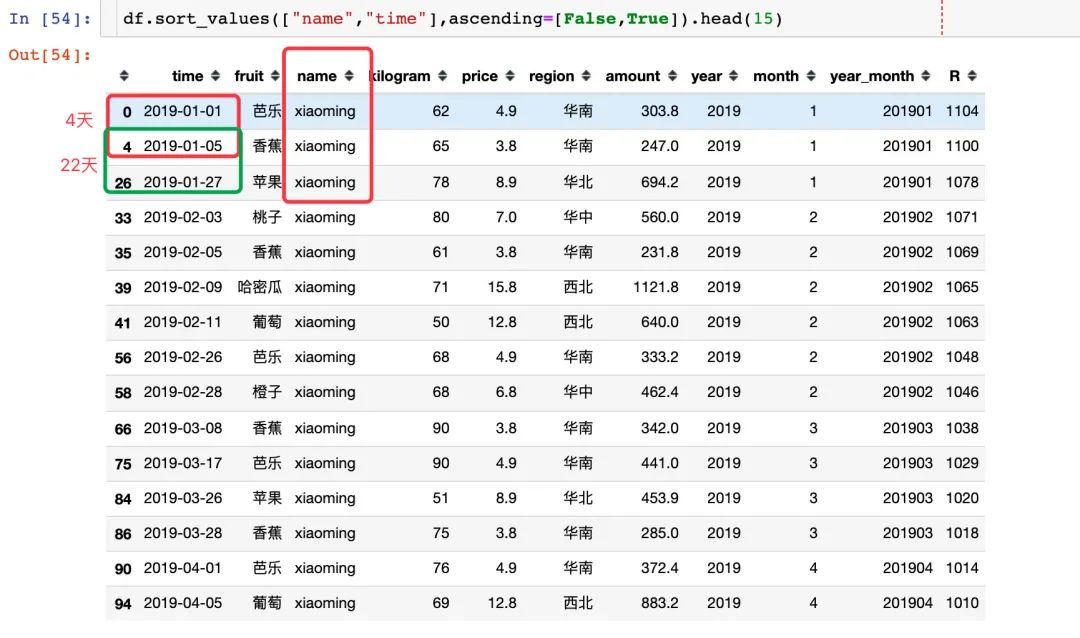
下面是求解每个用户复购周期的过程:
1、每个用户的购买时间升序
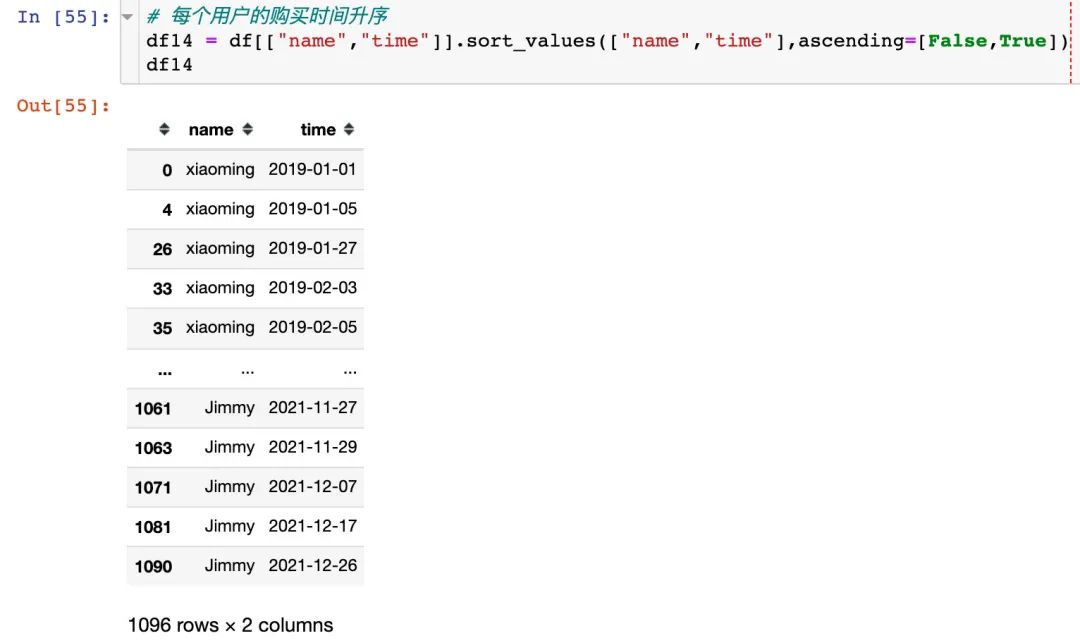
2、将时间移动一个单位:
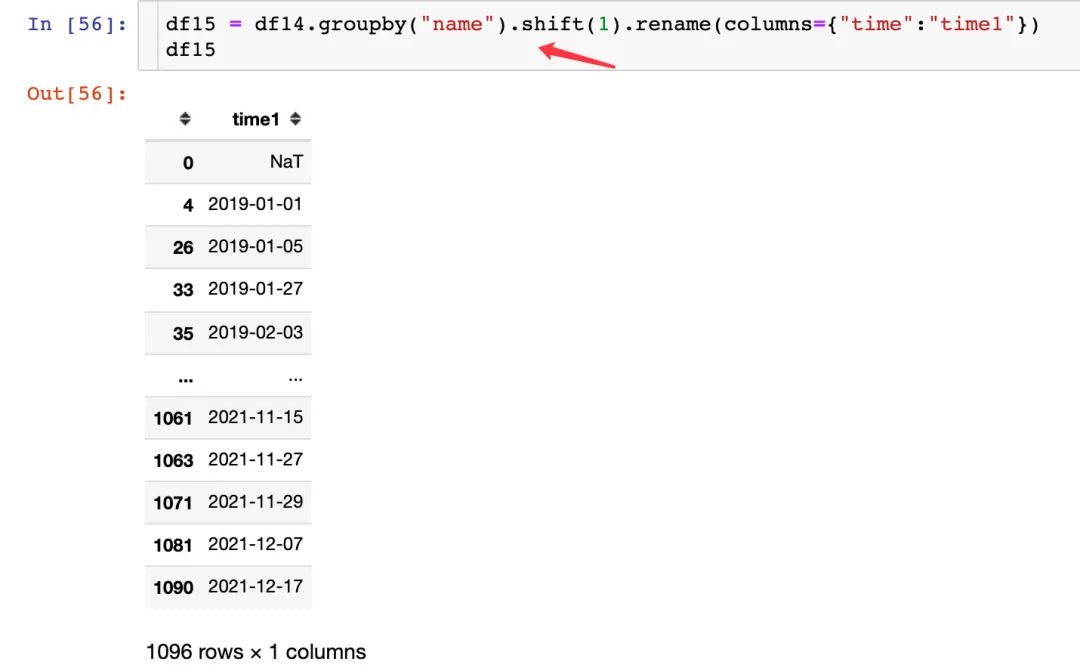
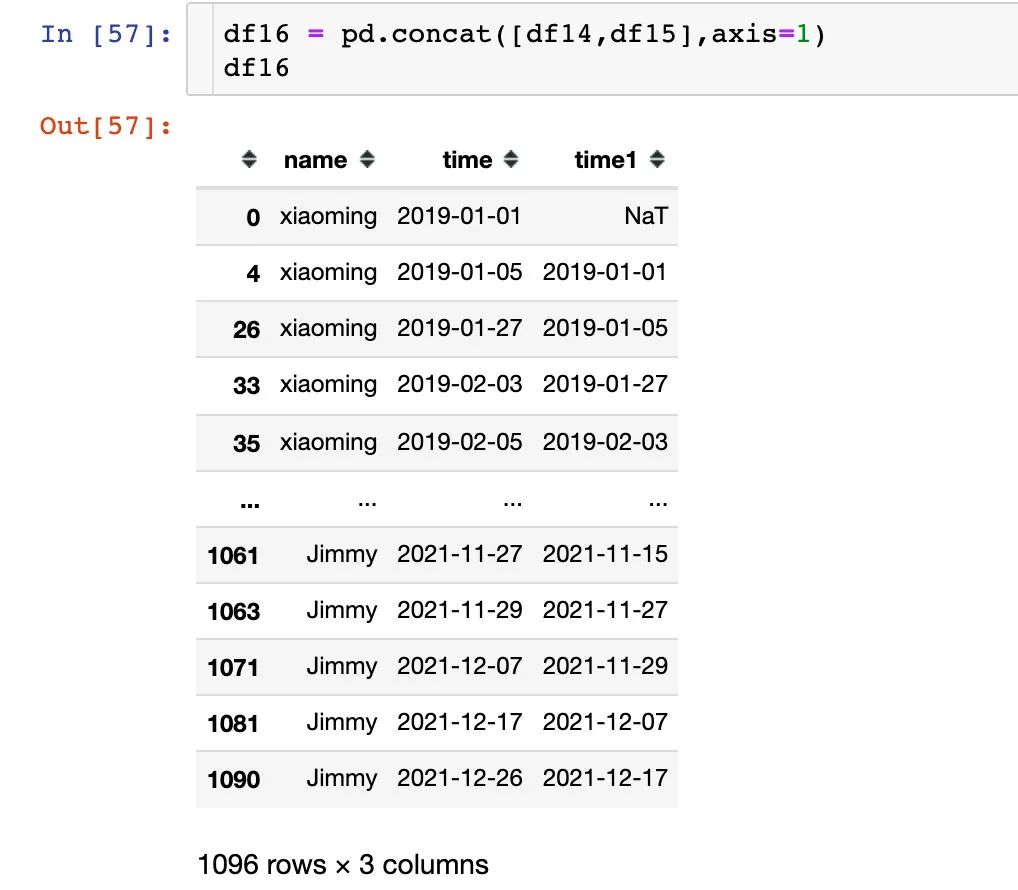
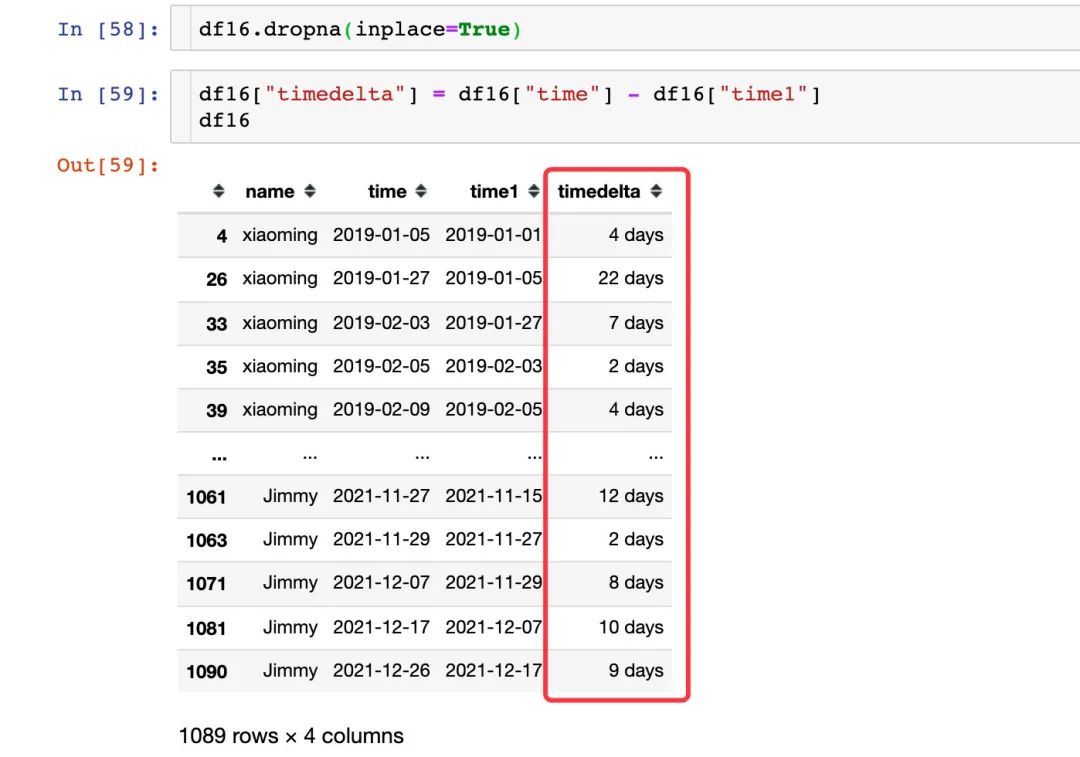
3、合并后的差值:
出现空值是每个用户的第一条记录之前是没有数据,后面直接删除了空值部分
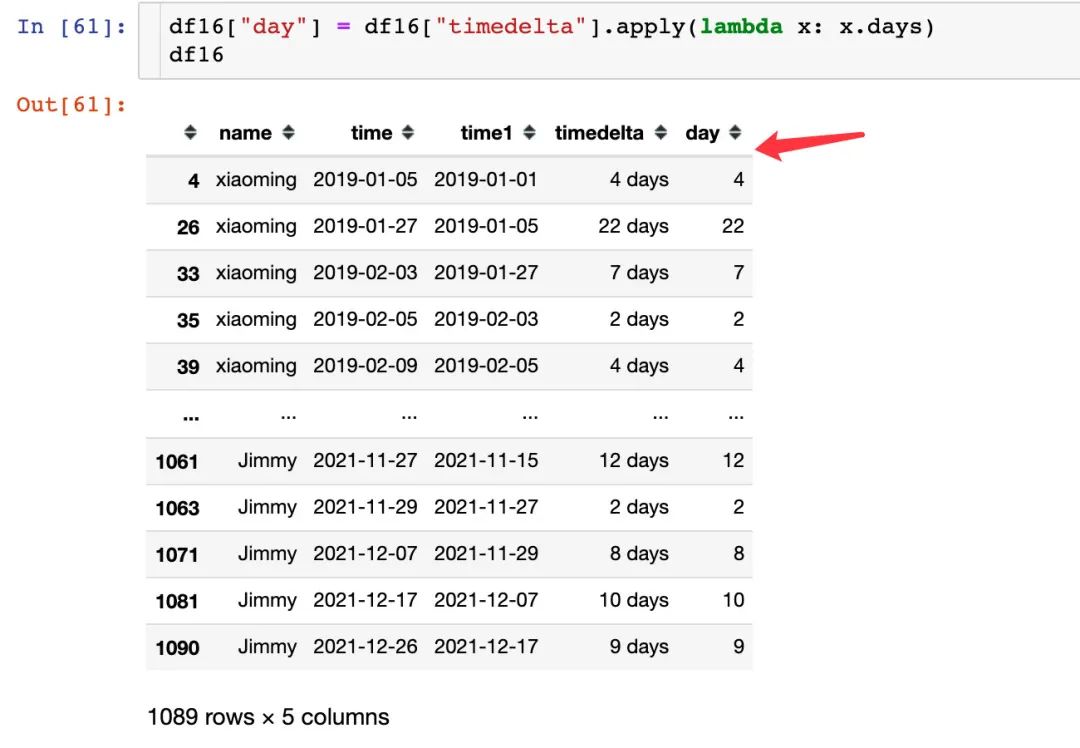
直接取出天数的数值部分:
5、复购周期对比
px.bar(df16,
x="day",
y="name",
orientation="h",
color="day",
color_continuous_scale="spectral" # purples
)
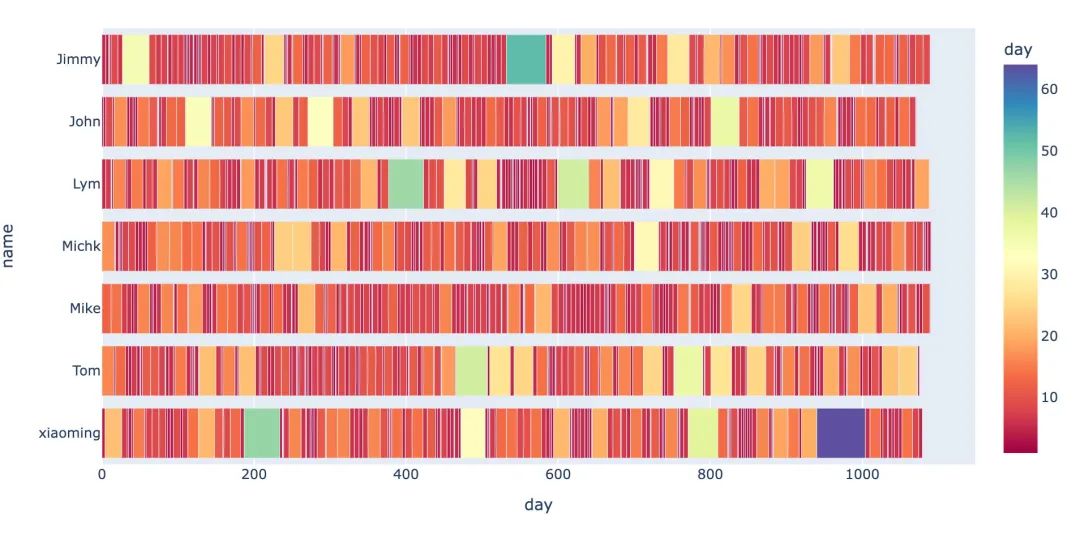
上图中矩形越窄表示间隔越小;每个用户整个复购周期由整个矩形长度决定。查看每个用户的整体复购周期之和与平均复购周期:
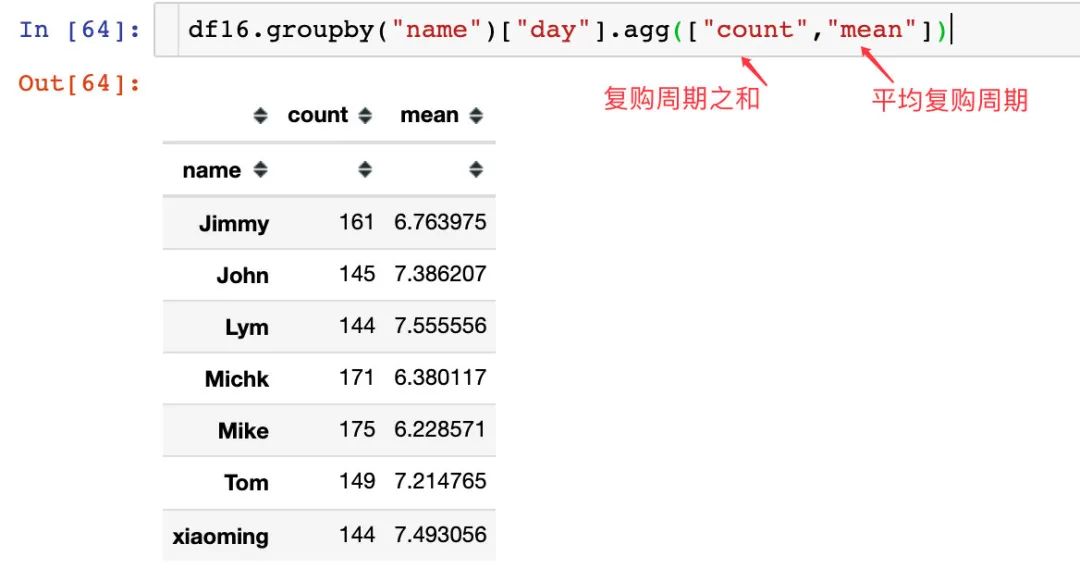
得到一个结论:Michk和Mike两个用户整体的复购周期是比较长的,长期来看是忠诚的用户;而且从平均复购周期来看,相对较低,说明在短时间内复购活跃。
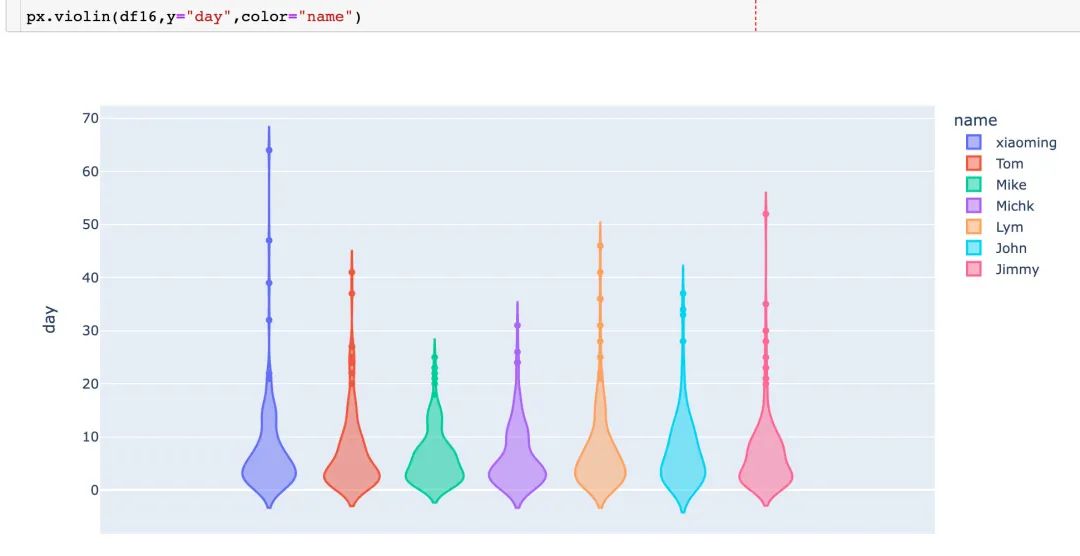
从下面的小提琴中同样可以观察到,Michk和Mike的复购周期分布最为集中。
到此这篇关于五个Pandas 实战案例带你分析操作数据的文章就介绍到这了,更多相关Pandas 分析数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python数据分析之pandas比较操作
一.比较运算符和比较方法 比较运算符用于判断是否相等和比较大小,Python中的比较运算符有==.!=.<.>.<=.>=六个,Pandas中也一样. 在Pandas中,DataFrame和Series还支持6个比较方法,详见下表. 方法 英文全称 用途 eq equal to 等于 ne not equal to 不等于 lt less than 小于 gt greater than 大于 le less than or equal to 小于等于 ge greater than
-
Pandas数据分析之批量拆分/合并Excel
目录 前言 一.假造数据 二.程序演示 1.将一个大Excel等份拆成多个Excel 2.合并多个小Excel到一个大Excel 总结 前言 笔者最近正在学习Pandas数据分析,将自己的学习笔记做成一套系列文章.本节主要记录Pandas中数据的合并(concat和append) 将一个大的Excel等份拆成多个Excel将多个小Excel合并成一个大的Excel并且标记来源 一.假造数据 work_dir="./datas" splits_dir=f"{work_dir}/
-
Python数据分析pandas模块用法实例详解
本文实例讲述了Python数据分析pandas模块用法.分享给大家供大家参考,具体如下: pandas pandas10分钟入门,可以查看官网:10 minutes to pandas 也可以查看更复杂的cookbook pandas是非常强大的数据分析包,pandas 是基于 Numpy 构建的含有更高级数据结构和工具的数据分析包.就好比 Numpy的核心是 ndarray,pandas 围绕着 Series 和 DataFrame 两个核心数据结构展开 .Series和DataFrame 分
-
Pandas数据分析的一些常用小技巧
Pandas小技巧 import pandas as pd pandas生成数据 d = {"sex": ["male", "female", "male", "female"], "color": ["red", "green", "blue", "yellow"], "age": [1
-
python数据分析必会的Pandas技巧汇总
目录 一.Pandas两大数据结构的创建 二.DataFrame常见方法 三.数据索引 四.DataFrame选取和重新组合数据的方法 五.排序 六.相关分析和统计分析 七.分组的方法 八.读写文本格式数据的方法 九.处理缺失数据 十.数据转换 一.Pandas两大数据结构的创建 序号 方法 说明 1 pd.Series(对象,index=[ ]) 创建Series.对象可以是列表\ndarray.字典以及DataFrame中的某一行或某一列 2 pd.DataFrame(data,column
-
基于Python数据分析之pandas统计分析
pandas模块为我们提供了非常多的描述性统计分析的指标函数,如总和.均值.最小值.最大值等,我们来具体看看这些函数: 1.随机生成三组数据 import numpy as np import pandas as pd np.random.seed(1234) d1 = pd.Series(2*np.random.normal(size = 100)+3) d2 = np.random.f(2,4,size = 100) d3 = np.random.randint(1,100,size = 1
-
Python数据分析之pandas函数详解
一.apply和applymap 1. 可直接使用NumPy的函数 示例代码: # Numpy ufunc 函数 df = pd.DataFrame(np.random.randn(5,4) - 1) print(df) print(np.abs(df)) 运行结果: 0 1 2 3 0 -0.062413 0.844813 -1.853721 -1.980717 1 -0.539628 -1.975173 -0.856597 -2.612406
-
Python Pandas数据分析工具用法实例
1.介绍 Pandas是基于Numpy的专业数据分析工具,可以灵活高效的处理各种数据集,也是我们后期分析案例的神器.它提供了两种类型的数据结构,分别是DataFrame和Series,我们可以简单粗暴的把DataFrame理解为Excel里面的一张表,而Series就是表中的某一列 2.创建DataFrame # -*- encoding=utf-8 -*- import pandas if __name__ == '__main__': pass test_stu = pandas.DataF
-
Python数据分析之pandas读取数据
一.三种数据文件的读取 二.csv.tsv.txt 文件读取 1)CSV文件读取: 语法格式:pandas.read_csv(文件路径) CSV文件内容如下: import pandas as pd file_path = "e:\\pandas_study\\test.csv" content = pd.read_csv(file_path) content.head() # 默认返回前5行数据 content.head(3) # 返回前3行数据 content.shape # 返回
-
Python教程pandas数据分析去重复值
目录 加载数据 sample抽样函数 指定需要更新的值 append直接添加 append函数用法 根据某一列key值进行去重(key唯一) 加载数据 首先,我们需要加载到所需要的数据,这里我们所需要的数据是同过sample函数采样过来的. import pandas as pd #这里说明一下,clean_beer.csv数据有两千多行数据 #所以从其中采样一部分,来进行演示,当然可以简单实用data.head()也可以做练习 data = pd.read_csv('clean_beer.cs