Python实现决策树并且使用Graphviz可视化的例子
一、什么是决策树(decision tree)——机器学习中的一个重要的分类算法
决策树是一个类似于数据流程图的树结构:其中,每个内部节点表示一个属性上的测试,每个分支代表一个属性输出,而每个树叶结点代表类或者类的分布,树的最顶层是根结点
根据天气情况决定出游与否的案例
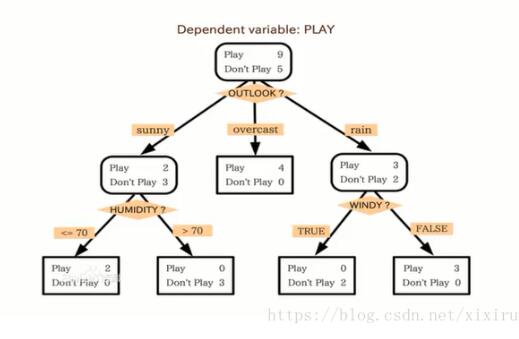
二、决策树算法构建
2.1决策树的核心思路
特征选择:从训练数据的特征中选择一个特征作为当前节点的分裂标准(特征选择的标准不同产生了不同的特征决策树算法)。
决策树生成:根据所选特征评估标准,从上至下递归地生成子节点,直到数据集不可分则停止决策树停止声场。
剪枝:决策树容易过拟合,需要剪枝来缩小树的结构和规模(包括预剪枝和后剪枝)。
2.2 熵的概念:度量信息的方式
实现决策树的算法包括ID3、C4.5算法等。常见的ID3核心思想是以信息增益度量属性选择,选择分裂后信息增益最大的属性进行分裂。
一条信息的信息量大小和它的不确定性有直接的关系,要搞清楚一件非常不确定的事情,或者是我们一无所知的事情,需要大量的信息====>信息量的度量就等于不确定性的 多少。也就是说变量的不确定性越大,熵就越大
信息熵的计算公司
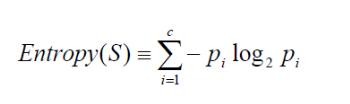
S为所有事件集合,p为发生概率,c为特征总数。
信息增益(information gain)是指信息划分前后的熵的变化,也就是说由于使用这个属性分割样例而导致的期望熵降低。也就是说,信息增益就是原有信息熵与属性划分后信息熵(需要对划分后的信息熵取期望值)的差值,具体计算如下:
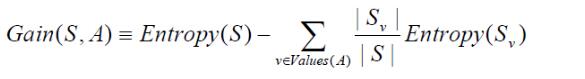
其中,第二项为属性A对S划分的期望信息。
三、IDE3决策树的Python实现
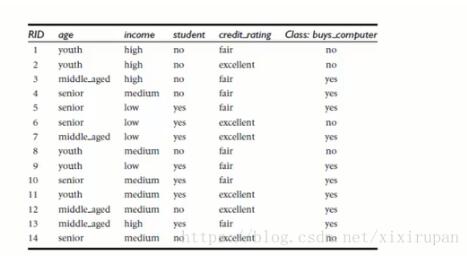
以下面这个不同年龄段的人买电脑的情况为例子建模型算法
'''
Created on 2018年7月5日
使用python内的科学计算的库实现利用决策树解决问题
@author: lenovo
'''
#coding:utf-8
from sklearn.feature_extraction import DictVectorizer
#数据存储的格式 python自带不需要安装
import csv
#预处理的包
from sklearn import preprocessing
from sklearn.externals.six import StringIO
from sklearn.tree import tree
from sklearn.tree import export_graphviz
'''
文件保存格式需要是utf-8
window中的目录形式需要是左斜杠 F:/AA_BigData/test_data/test1.csv
excel表格存储成csv格式并且是utf-8格式的编码
'''
'''
决策树数据源读取
scklearn要求的数据类型 特征值属性必须是数值型的
需要对数据进行预处理
'''
#装特征的值
featureList=[]
#装类别的词
labelList=[]
with open("F:/AA_BigData/test_data/decision_tree.csv", "r",encoding="utf-8") as csvfile:
decision =csv.reader(csvfile)
headers =[]
row =1
for item in decision:
if row==1:
row=row+1
for head in item:
headers.append(head)
else:
itemDict={}
labelList.append(item[len(item)-1])
for num in range(1,len(item)-1):
# print(item[num])
itemDict[headers[num]]=item[num]
featureList.append(itemDict)
print(headers)
print(labelList)
print(featureList)
'''
将原始数据转换成包含有字典的List
将建好的包含字典的list用DictVectorizer对象转换成0-1矩阵
'''
vec =DictVectorizer()
dumyX =vec.fit_transform(featureList).toarray();
#对于类别使用同样的方法
lb =preprocessing.LabelBinarizer()
dumyY=lb.fit_transform(labelList)
print(dumyY)
'''
1.构建分类器——决策树模型
2.使用数据训练决策树模型
'''
clf =tree.DecisionTreeClassifier(criterion="entropy")
clf.fit(dumyX,dumyY)
print(str(clf))
'''
1.将生成的分类器转换成dot格式的 数据
2.在命令行中dot -Tpdf iris.dot -o output.pdf将dot文件转换成pdf图的文件
'''
#视频上讲的不适用python3.5
with open("F:/AA_BigData/test_data/decisiontree.dot", "w") as wFile:
export_graphviz(clf,out_file=wFile,feature_names=vec.get_feature_names())
Graphviz对决策树的可视化

以上这篇Python实现决策树并且使用Graphviz可视化的例子就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
VSCode基础使用与VSCode调试python程序入门的图文教程
用VSCode编程是需要依赖扩展的.写python需要安装python的扩展,写C++需要安装C++的扩展.刚打开编辑器的时候,它一般会推荐一些扩展,你如果什么都不知道,可以先安装官方推荐的这些扩展: 修改VSCode的一些选项的默认值 VSCode有很多选项可以被修改,其各个选项都有默认值,这些默认值存储在"\settings.json"中(不过我没找到这个文件),用户如果想修改某些选项的值(比如:修改字体的大小),VSCode会自动帮我们生成一个"settings.jso
-
Python使用graphviz画流程图过程解析
问题描述 项目中需要用到流程图,如果用js的echarts处理,不同层级建动态计算位置比较复杂,考虑用python来实现 测试demo 实现效果如下 完整代码 import yaml import os import ibm_db from graphviz import Digraph from datetime import datetime # db连接 def db2_query(sql): conn = ibm_db.connect( "DATABASE=%s;HOSTNAME=%s;
-
解决使用export_graphviz可视化树报错的问题
在使用可视化树的过程中,报错了.说是'dot.exe'not found in path 原代码: # import tools needed for visualization from sklearn.tree import export_graphviz import pydot #Pull out one tree from the forest tree = rf.estimators_[5] # Export the image to a dot file export_graphv
-
基于python爬取有道翻译过程图解
1.准备工作 先来到有道在线翻译的界面http://fanyi.youdao.com/ F12 审查元素 ->选Network一栏,然后F5刷新 (如果看不到Method一栏,右键Name栏,选中Method) 输入文字自动翻译后发现Method一栏有GET还有POST:GET是指从服务器请求和获得数据,POST是向指定服务器提交被处理的数据. 随便打开一个POST,找到preview可以看到我们输入的"我爱你一生一世"数据,可以证明post的提交数据的 下面分析一下Header
-
windows下Graphviz安装及入门教程的实现方法
下载安装配置环境变量intall配置环境变量验证基本绘图入门graphdigraph一个复杂的例子和python交互 发现好的工具,如同发现新大陆.有时,我们会好奇,论文中.各种专业的书中那么形象的插图是如何做出来的,无一例外不是对绘图工具的熟练使用. 下载安装.配置环境变量 intall windows版本下载地址:http://www.graphviz.org/Download_windows.php 双击msi文件,然后一直next(记住安装路径,后面配置环境变量会用到路径信息),安装完成
-
Python调用graphviz绘制结构化图形网络示例
首先要下载:Graphviz - Graph Visualization Software 安装完成后将安装目录的bin 路径加到系统路径中,有时候需要重启电脑. 然后: pip install graphviz import graphviz as gz 有向图 dot = gz.Digraph() dot.node('1', 'Test1') dot.node('2', 'Test2') dot.node('3', 'Test3') dot.node('4', 'Test4') dot.ed
-
Python实现决策树并且使用Graphviz可视化的例子
一.什么是决策树(decision tree)--机器学习中的一个重要的分类算法 决策树是一个类似于数据流程图的树结构:其中,每个内部节点表示一个属性上的测试,每个分支代表一个属性输出,而每个树叶结点代表类或者类的分布,树的最顶层是根结点 根据天气情况决定出游与否的案例 二.决策树算法构建 2.1决策树的核心思路 特征选择:从训练数据的特征中选择一个特征作为当前节点的分裂标准(特征选择的标准不同产生了不同的特征决策树算法). 决策树生成:根据所选特征评估标准,从上至下递归地生成子节点,直到数据集
-
Python实现决策树并且使用Graphvize可视化的例子
一.什么是决策树(decision tree)--机器学习中的一个重要的分类算法 决策树是一个类似于数据流程图的树结构:其中,每个内部节点表示一个属性上的测试,每个分支代表一个属性输出,而每个树叶结点代表类或者类的分布,树的最顶层是根结点 根据天气情况决定出游与否的案例 二.决策树算法构建 2.1决策树的核心思路 特征选择:从训练数据的特征中选择一个特征作为当前节点的分裂标准(特征选择的标准不同产生了不同的特征决策树算法). 决策树生成:根据所选特征评估标准,从上至下递归地生成子节点,直到数据集
-
python输出决策树图形的例子
windows10: 1,先要pip安装pydotplus和graphviz: pip install pydotplus pip install graphviz 2,www.graphviz.org下载msi文件并安装. 3,系统环境变量path中增加两项: C:\Program Files (x86)\Graphviz2.38\bin C:\Program Files (x86)\Graphviz2.38 #确认graphviz是安装在上面路径当中. 4,python中使用方法: from
-

python实现决策树C4.5算法详解(在ID3基础上改进)
一.概论 C4.5主要是在ID3的基础上改进,ID3选择(属性)树节点是选择信息增益值最大的属性作为节点.而C4.5引入了新概念"信息增益率",C4.5是选择信息增益率最大的属性作为树节点. 二.信息增益 以上公式是求信息增益率(ID3的知识点) 三.信息增益率 信息增益率是在求出信息增益值在除以. 例如下面公式为求属性为"outlook"的值: 四.C4.5的完整代码 from numpy import * from scipy import * from mat
-
python实现决策树
本文实例为大家分享了python实现决策树的具体代码,供大家参考,具体内容如下 算法优缺点: 优点:计算复杂度不高,输出结果易于理解,对中间值缺失不敏感,可以处理不相关的特征数据 缺点:可能会产生过度匹配的问题 适用数据类型:数值型和标称型 算法思想: 1.决策树构造的整体思想: 决策树说白了就好像是if-else结构一样,它的结果就是你要生成这个一个可以从根开始不断判断选择到叶子节点的树,但是呢这里的if-else必然不会是让我们认为去设置的,我们要做的是提供一种方法,计算机可以根据这种方法得
-
python实现决策树分类算法
本文实例为大家分享了python实现决策树分类算法的具体代码,供大家参考,具体内容如下 1.概述 决策树(decision tree)--是一种被广泛使用的分类算法. 相比贝叶斯算法,决策树的优势在于构造过程不需要任何领域知识或参数设置 在实际应用中,对于探测式的知识发现,决策树更加适用. 2.算法思想 通俗来说,决策树分类的思想类似于找对象.现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话: 女儿:多大年纪了? 母亲:26. 女儿:长的帅不帅? 母亲:挺帅的. 女儿:收入高不?
-
python代码实现TSNE降维数据可视化教程
TSNE降维 降维就是用2维或3维表示多维数据(彼此具有相关性的多个特征数据)的技术,利用降维算法,可以显式地表现数据.(t-SNE)t分布随机邻域嵌入 是一种用于探索高维数据的非线性降维算法.它将多维数据映射到适合于人类观察的两个或多个维度. python代码 km.py #k_mean算法 import pandas as pd import csv import pandas as pd import numpy as np #参数初始化 inputfile = 'x.xlsx' #销量及
-
如何使用Python处理HDF格式数据及可视化问题
原文链接:https://blog.csdn.net/Fairy_Nan/article/details/105914203 HDF也是一种自描述格式文件,主要用于存储和分发科学数据.气象领域中卫星数据经常使用此格式,比如MODIS,OMI,LIS/OTD等卫星产品.对HDF格式细节感兴趣的可以Google了解一下. 这一次呢还是以Python为主,来介绍如何处理HDF格式数据.Python中有不少库都可以用来处理HDF格式数据,比如h5py可以处理HDF5格式(pandas中 read_hdf
-
Python爬取股票信息,并可视化数据的示例
前言 截止2019年年底我国股票投资者数量为15975.24万户, 如此多的股民热衷于炒股,首先抛开炒股技术不说, 那么多股票数据是不是非常难找, 找到之后是不是看着密密麻麻的数据是不是头都大了? 今天带大家爬取雪球平台的股票数据, 并且实现数据可视化 先看下效果图 基本环境配置 python 3.6 pycharm requests csv time 目标地址 https://xueqiu.com/hq 爬虫代码 请求网页 import requests url = 'https://xueq
-
Python绘制K线图之可视化神器pyecharts的使用
K线图 概念 股市及期货市bai场中的K线图的du画法包含四个zhi数据,即开盘dao价.最高价.最低价zhuan.收盘价,所有的shuk线都是围绕这四个数据展开,反映大势的状况和价格信息.如果把每日的K线图放在一张纸上,就能得到日K线图,同样也可画出周K线图.月K线图.研究金融的小伙伴肯定比较熟悉这个,那么我们看起来比较复杂的K线图,又是这样画出来的,本文我们将一起探索K线图的魅力与神奇之处吧! K线图 用处 K线图用处于股票分析,作为数据分析,以后的进入大数据肯定是一个趋势和热潮,K线图的专