Python实现RabbitMQ6种消息模型的示例代码
RabbitMQ与Redis对比
RabbitMQ是一种比较流行的消息中间件,之前我一直使用redis作为消息中间件,但是生产环境比较推荐RabbitMQ来替代Redis,所以我去查询了一些RabbitMQ的资料。相比于Redis,RabbitMQ优点很多,比如:
- 具有消息消费确认机制
- 队列,消息,都可以选择是否持久化,粒度更小、更灵活。
- 可以实现负载均衡
RabbitMQ应用场景
- 异步处理:比如用户注册时的确认邮件、短信等交由rabbitMQ进行异步处理
- 应用解耦:比如收发消息双方可以使用消息队列,具有一定的缓冲功能
- 流量削峰:一般应用于秒杀活动,可以控制用户人数,也可以降低流量
- 日志处理:将info、warning、error等不同的记录分开存储
RabbitMQ消息模型
这里使用 Python 的 pika 这个库来实现RabbitMQ中常见的6种消息模型。没有的可以先安装:
pip install pika
1.单生产单消费模型:即完成基本的一对一消息转发。

# 生产者代码
import pika
credentials = pika.PlainCredentials('chuan', '123') # mq用户名和密码,没有则需要自己创建
# 虚拟队列需要指定参数 virtual_host,如果是默认的可以不填。
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost',
port=5672,
virtual_host='/',
credentials=credentials))
# 建立rabbit协议的通道
channel = connection.channel()
# 声明消息队列,消息将在这个队列传递,如不存在,则创建。durable指定队列是否持久化
channel.queue_declare(queue='python-test', durable=False)
# message不能直接发送给queue,需经exchange到达queue,此处使用以空字符串标识的默认的exchange
# 向队列插入数值 routing_key是队列名
channel.basic_publish(exchange='',
routing_key='python-test',
body='Hello world!2')
# 关闭与rabbitmq server的连接
connection.close()
# 消费者代码
import pika
credentials = pika.PlainCredentials('chuan', '123')
# BlockingConnection:同步模式
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost',
port=5672,
virtual_host='/',
credentials=credentials))
channel = connection.channel()
# 申明消息队列。当不确定生产者和消费者哪个先启动时,可以两边重复声明消息队列。
channel.queue_declare(queue='python-test', durable=False)
# 定义一个回调函数来处理消息队列中的消息,这里是打印出来
def callback(ch, method, properties, body):
# 手动发送确认消息
ch.basic_ack(delivery_tag=method.delivery_tag)
print(body.decode())
# 告诉生产者,消费者已收到消息
# 告诉rabbitmq,用callback来接收消息
# 默认情况下是要对消息进行确认的,以防止消息丢失。
# 此处将auto_ack明确指明为True,不对消息进行确认。
channel.basic_consume('python-test',
on_message_callback=callback)
# auto_ack=True) # 自动发送确认消息
# 开始接收信息,并进入阻塞状态,队列里有信息才会调用callback进行处理
channel.start_consuming()
2.消息分发模型:多个收听者监听一个队列。

# 生产者代码
import pika
credentials = pika.PlainCredentials('chuan', '123') # mq用户名和密码
# 虚拟队列需要指定参数 virtual_host,如果是默认的可以不填。
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost',
port=5672,
virtual_host='/',
credentials=credentials))
# 建立rabbit协议的通道
channel = connection.channel()
# 声明消息队列,消息将在这个队列传递,如不存在,则创建。durable指定队列是否持久化。确保没有确认的消息不会丢失
channel.queue_declare(queue='rabbitmqtest', durable=True)
# message不能直接发送给queue,需经exchange到达queue,此处使用以空字符串标识的默认的exchange
# 向队列插入数值 routing_key是队列名
# basic_publish的properties参数指定message的属性。此处delivery_mode=2指明message为持久的
for i in range(10):
channel.basic_publish(exchange='',
routing_key='python-test',
body='Hello world!%s' % i,
properties=pika.BasicProperties(delivery_mode=2))
# 关闭与rabbitmq server的连接
connection.close()
# 消费者代码,consume1与consume2
import pika
import time
credentials = pika.PlainCredentials('chuan', '123')
# BlockingConnection:同步模式
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost',
port=5672,
virtual_host='/',
credentials=credentials))
channel = connection.channel()
# 申明消息队列。当不确定生产者和消费者哪个先启动时,可以两边重复声明消息队列。
channel.queue_declare(queue='rabbitmqtest', durable=True)
# 定义一个回调函数来处理消息队列中的消息,这里是打印出来
def callback(ch, method, properties, body):
# 手动发送确认消息
time.sleep(10)
print(body.decode())
# 告诉生产者,消费者已收到消息
ch.basic_ack(delivery_tag=method.delivery_tag)
# 如果该消费者的channel上未确认的消息数达到了prefetch_count数,则不向该消费者发送消息
channel.basic_qos(prefetch_count=1)
# 告诉rabbitmq,用callback来接收消息
# 默认情况下是要对消息进行确认的,以防止消息丢失。
# 此处将no_ack明确指明为True,不对消息进行确认。
channel.basic_consume('python-test',
on_message_callback=callback)
# auto_ack=True) # 自动发送确认消息
# 开始接收信息,并进入阻塞状态,队列里有信息才会调用callback进行处理
channel.start_consuming()
3.fanout消息订阅模式:生产者将消息发送到Exchange,Exchange再转发到与之绑定的Queue中,每个消费者再到自己的Queue中取消息。

# 生产者代码
import pika
credentials = pika.PlainCredentials('chuan', '123') # mq用户名和密码
# 虚拟队列需要指定参数 virtual_host,如果是默认的可以不填。
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost',
port=5672,
virtual_host='/',
credentials=credentials))
# 建立rabbit协议的通道
channel = connection.channel()
# fanout: 所有绑定到此exchange的queue都可以接收消息(实时广播)
# direct: 通过routingKey和exchange决定的那一组的queue可以接收消息(有选择接受)
# topic: 所有符合routingKey(此时可以是一个表达式)的routingKey所bind的queue可以接收消息(更细致的过滤)
channel.exchange_declare('logs', exchange_type='fanout')
#因为是fanout广播类型的exchange,这里无需指定routing_key
for i in range(10):
channel.basic_publish(exchange='logs',
routing_key='',
body='Hello world!%s' % i)
# 关闭与rabbitmq server的连接
connection.close()
import pika
credentials = pika.PlainCredentials('chuan', '123')
# BlockingConnection:同步模式
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost',
port=5672,
virtual_host='/',
credentials=credentials))
channel = connection.channel()
#作为好的习惯,在producer和consumer中分别声明一次以保证所要使用的exchange存在
channel.exchange_declare(exchange='logs',
exchange_type='fanout')
# 随机生成一个新的空的queue,将exclusive置为True,这样在consumer从RabbitMQ断开后会删除该queue
# 是排他的。
result = channel.queue_declare('', exclusive=True)
# 用于获取临时queue的name
queue_name = result.method.queue
# exchange与queue之间的关系成为binding
# binding告诉exchange将message发送该哪些queue
channel.queue_bind(exchange='logs',
queue=queue_name)
# 定义一个回调函数来处理消息队列中的消息,这里是打印出来
def callback(ch, method, properties, body):
# 手动发送确认消息
print(body.decode())
# 告诉生产者,消费者已收到消息
#ch.basic_ack(delivery_tag=method.delivery_tag)
# 如果该消费者的channel上未确认的消息数达到了prefetch_count数,则不向该消费者发送消息
channel.basic_qos(prefetch_count=1)
# 告诉rabbitmq,用callback来接收消息
# 默认情况下是要对消息进行确认的,以防止消息丢失。
# 此处将no_ack明确指明为True,不对消息进行确认。
channel.basic_consume(queue=queue_name,
on_message_callback=callback,
auto_ack=True) # 自动发送确认消息
# 开始接收信息,并进入阻塞状态,队列里有信息才会调用callback进行处理
channel.start_consuming()
4.direct路由模式:此时生产者发送消息时需要指定RoutingKey,即路由Key,Exchange接收到消息时转发到与RoutingKey相匹配的队列中。
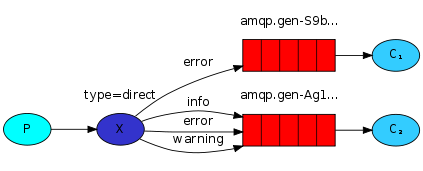
# 生产者代码,测试命令可以使用:python produce.py error 404error
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
# 声明一个名为direct_logs的direct类型的exchange
# direct类型的exchange
channel.exchange_declare(exchange='direct_logs',
exchange_type='direct')
# 从命令行获取basic_publish的配置参数
severity = sys.argv[1] if len(sys.argv) > 1 else 'info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
# 向名为direct_logs的exchage按照设置的routing_key发送message
channel.basic_publish(exchange='direct_logs',
routing_key=severity,
body=message)
print(" [x] Sent %r:%r" % (severity, message))
connection.close()
# 消费者代码,测试可以使用:python consume.py error
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
# 声明一个名为direct_logs类型为direct的exchange
# 同时在producer和consumer中声明exchage或queue是个好习惯,以保证其存在
channel.exchange_declare(exchange='direct_logs',
exchange_type='direct')
result = channel.queue_declare('', exclusive=True)
queue_name = result.method.queue
# 从命令行获取参数:routing_key
severities = sys.argv[1:]
if not severities:
print(sys.stderr, "Usage: %s [info] [warning] [error]" % (sys.argv[0],))
sys.exit(1)
for severity in severities:
# exchange和queue之间的binding可接受routing_key参数
# fanout类型的exchange直接忽略该参数。direct类型的exchange精确匹配该关键字进行message路由
# 一个消费者可以绑定多个routing_key
# Exchange就是根据这个RoutingKey和当前Exchange所有绑定的BindingKey做匹配,
# 如果满足要求,就往BindingKey所绑定的Queue发送消息
channel.queue_bind(exchange='direct_logs',
queue=queue_name,
routing_key=severity)
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body,))
channel.basic_consume(queue=queue_name,
on_message_callback=callback,
auto_ack=True)
channel.start_consuming()
5.topic匹配模式:更细致的分组,允许在RoutingKey中使用匹配符。
- *:匹配一个单词
- #:匹配0个或多个单词
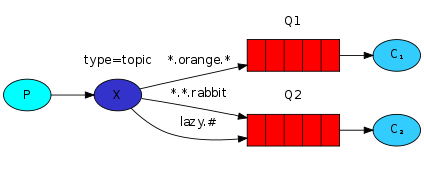
# 生产者代码,基本不变,只需将exchange_type改为topic(测试:python produce.py rabbitmq.red
# red color is my favorite
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
# 声明一个名为direct_logs的direct类型的exchange
# direct类型的exchange
channel.exchange_declare(exchange='topic_logs',
exchange_type='topic')
# 从命令行获取basic_publish的配置参数
severity = sys.argv[1] if len(sys.argv) > 1 else 'info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
# 向名为direct_logs的exchange按照设置的routing_key发送message
channel.basic_publish(exchange='topic_logs',
routing_key=severity,
body=message)
print(" [x] Sent %r:%r" % (severity, message))
connection.close()
# 消费者代码,(测试:python consume.py *.red)
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
# 声明一个名为direct_logs类型为direct的exchange
# 同时在producer和consumer中声明exchage或queue是个好习惯,以保证其存在
channel.exchange_declare(exchange='topic_logs',
exchange_type='topic')
result = channel.queue_declare('', exclusive=True)
queue_name = result.method.queue
# 从命令行获取参数:routing_key
severities = sys.argv[1:]
if not severities:
print(sys.stderr, "Usage: %s [info] [warning] [error]" % (sys.argv[0],))
sys.exit(1)
for severity in severities:
# exchange和queue之间的binding可接受routing_key参数
# fanout类型的exchange直接忽略该参数。direct类型的exchange精确匹配该关键字进行message路由
# 一个消费者可以绑定多个routing_key
# Exchange就是根据这个RoutingKey和当前Exchange所有绑定的BindingKey做匹配,
# 如果满足要求,就往BindingKey所绑定的Queue发送消息
channel.queue_bind(exchange='topic_logs',
queue=queue_name,
routing_key=severity)
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body,))
channel.basic_consume(queue=queue_name,
on_message_callback=callback,
auto_ack=True)
channel.start_consuming()
6.RPC远程过程调用:客户端与服务器之间是完全解耦的,即两端既是消息的发送者也是接受者。

# 生产者代码
import pika
import uuid
# 在一个类中封装了connection建立、queue声明、consumer配置、回调函数等
class FibonacciRpcClient(object):
def __init__(self):
# 建立到RabbitMQ Server的connection
self.connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
self.channel = self.connection.channel()
# 声明一个临时的回调队列
result = self.channel.queue_declare('', exclusive=True)
self._queue = result.method.queue
# 此处client既是producer又是consumer,因此要配置consume参数
# 这里的指明从client自己创建的临时队列中接收消息
# 并使用on_response函数处理消息
# 不对消息进行确认
self.channel.basic_consume(queue=self._queue,
on_message_callback=self.on_response,
auto_ack=True)
self.response = None
self.corr_id = None
# 定义回调函数
# 比较类的corr_id属性与props中corr_id属性的值
# 若相同则response属性为接收到的message
def on_response(self, ch, method, props, body):
if self.corr_id == props.correlation_id:
self.response = body
def call(self, n):
# 初始化response和corr_id属性
self.corr_id = str(uuid.uuid4())
# 使用默认exchange向server中定义的rpc_queue发送消息
# 在properties中指定replay_to属性和correlation_id属性用于告知远程server
# correlation_id属性用于匹配request和response
self.channel.basic_publish(exchange='',
routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to=self._queue,
correlation_id=self.corr_id,
),
# message需为字符串
body=str(n))
while self.response is None:
self.connection.process_data_events()
return int(self.response)
# 生成类的实例
fibonacci_rpc = FibonacciRpcClient()
print(" [x] Requesting fib(30)")
# 调用实例的call方法
response = fibonacci_rpc.call(30)
print(" [.] Got %r" % response)
# 消费者代码,这里以生成斐波那契数列为例
import pika
# 建立到达RabbitMQ Server的connection
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
# 声明一个名为rpc_queue的queue
channel.queue_declare(queue='rpc_queue')
# 计算指定数字的斐波那契数
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n - 1) + fib(n - 2)
# 回调函数,从queue接收到message后调用该函数进行处理
def on_request(ch, method, props, body):
# 由message获取要计算斐波那契数的数字
n = int(body)
print(" [.] fib(%s)" % n)
# 调用fib函数获得计算结果
response = fib(n)
# exchage为空字符串则将message发送个到routing_key指定的queue
# 这里queue为回调函数参数props中reply_ro指定的queue
# 要发送的message为计算所得的斐波那契数
# properties中correlation_id指定为回调函数参数props中co的rrelation_id
# 最后对消息进行确认
ch.basic_publish(exchange='',
routing_key=props.reply_to,
properties=pika.BasicProperties(correlation_id=props.correlation_id),
body=str(response))
ch.basic_ack(delivery_tag=method.delivery_tag)
# 只有consumer已经处理并确认了上一条message时queue才分派新的message给它
channel.basic_qos(prefetch_count=1)
# 设置consumeer参数,即从哪个queue获取消息使用哪个函数进行处理,是否对消息进行确认
channel.basic_consume(queue='rpc_queue', on_message_callback=on_request)
print(" [x] Awaiting RPC requests")
# 开始接收并处理消息
channel.start_consuming()
到此这篇关于Python实现RabbitMQ6种消息模型的示例代码的文章就介绍到这了,更多相关Python RabbitMQ消息模型 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

详解Python操作RabbitMQ服务器消息队列的远程结果返回
先说一下笔者这里的测试环境:Ubuntu14.04 + Python 2.7.4 RabbitMQ服务器 sudo apt-get install rabbitmq-server Python使用RabbitMQ需要Pika库 sudo pip install pika 远程结果返回 消息发送端发送消息出去后没有结果返回.如果只是单纯发送消息,当然没有问题了,但是在实际中,常常会需要接收端将收到的消息进行处理之后,返回给发送端. 处理方法描述:发送端在发送信息前,产生一个接收消息的临时队列,该队
-
利用Python操作消息队列RabbitMQ的方法教程
前言 RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统.他遵循Mozilla Public License开源协议. MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法.应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们.消 息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用通常是用于诸如远程过程调用的技术.排队指的是应用程序通过 队列来通信.队列的使用除去了接收和发
-
Python RabbitMQ消息队列实现rpc
上个项目中用到了ActiveMQ,只是简单应用,安装完成后直接是用就可以了.由于新项目中一些硬件的限制,需要把消息队列换成RabbitMQ. RabbitMQ中的几种模式和机制比ActiveMQ多多了,根据业务需要,使用RPC实现功能,其中踩过的一些坑,有必要记录一下了. 上代码,目录结构分为 c_server.c_client.c_hanlder: c_server: #!/usr/bin/env python # -*- coding:utf-8 -*- import pika import
-
利用Python学习RabbitMQ消息队列
RabbitMQ可以当做一个消息代理,它的核心原理非常简单:即接收和发送消息,可以把它想象成一个邮局:我们把信件放入邮箱,邮递员就会把信件投递到你的收件人处,RabbitMQ就是一个邮箱.邮局.投递员功能综合体,整个过程就是:邮箱接收信件,邮局转发信件,投递员投递信件到达收件人处. RabbitMQ和邮局的主要区别就是RabbitMQ接收.存储和发送的是二进制数据----消息. rabbitmq基本管理命令: 一步启动Erlang node和Rabbit应用:sudo rabbitmq-serv
-
Python操作RabbitMQ服务器实现消息队列的路由功能
Python使用Pika库(安装:sudo pip install pika)可以操作RabbitMQ消息队列服务器(安装:sudo apt-get install rabbitmq-server),这里我们来看一下MQ相关的路由功能. 路由键的实现 比如有一个需要给所有接收端发送消息的场景,但是如果需要自由定制,有的消息发给其中一些接收端,有些消息发送给另外一些接收端,要怎么办呢?这种情况下就要用到路由键了. 路由键的工作原理:每个接收端的消息队列在绑定交换机的时候,可以设定相应的路由键.发送
-
python实现RabbitMQ的消息队列的示例代码
最近在研究redis做消息队列时,顺便看了一下RabbitMQ做消息队列的实现.以下是总结的RabbitMQ中三种exchange模式的实现,分别是fanout, direct和topic. base.py: import pika # 获取认证对象,参数是用户名.密码.远程连接时需要认证 credentials = pika.PlainCredentials("admin", "admin") # BlockingConnection(): 实例化连接对象 # C
-
rabbitmq(中间消息代理)在python中的使用详解
在之前的有关线程,进程的博客中,我们介绍了它们各自在同一个程序中的通信方法.但是不同程序,甚至不同编程语言所写的应用软件之间的通信,以前所介绍的线程.进程队列便不再适用了:此种情况便只能使用socket编程了,然而不同程序之间的通信便不再像线程进程之间的那么简单了,要考虑多种情况(比如其中一方断线另一方如何处理:消息群发,多个程序之间的通信等等),如果每遇到一次程序间的通信,便要根据不同情况编写不同的socket,还要维护.完善这个socket这会使得编程人员的工作量大大增加,也使得程序更易崩溃
-
Python实现RabbitMQ6种消息模型的示例代码
RabbitMQ与Redis对比 RabbitMQ是一种比较流行的消息中间件,之前我一直使用redis作为消息中间件,但是生产环境比较推荐RabbitMQ来替代Redis,所以我去查询了一些RabbitMQ的资料.相比于Redis,RabbitMQ优点很多,比如: 具有消息消费确认机制 队列,消息,都可以选择是否持久化,粒度更小.更灵活. 可以实现负载均衡 RabbitMQ应用场景 异步处理:比如用户注册时的确认邮件.短信等交由rabbitMQ进行异步处理 应用解耦:比如收发消息双方可以使用
-
Python实现12种降维算法的示例代码
目录 为什么要进行数据降维 数据降维原理 主成分分析(PCA)降维算法 其它降维算法及代码地址 1.KPCA(kernel PCA) 2.LDA(Linear Discriminant Analysis) 3.MDS(multidimensional scaling) 4.ISOMAP 5.LLE(locally linear embedding) 6.t-SNE 7.LE(Laplacian Eigenmaps) 8.LPP(Locality Preserving Projections) 网
-
Python实现自动回复QQ消息功能的示例代码
目录 1.需要安装的模块 2.整体逻辑 3.代码实现 最近在看测试相关的内容,发现自动化测试很好玩,就决定做一个自动回复QQ消息的脚本(我很菜) 1.需要安装的模块 这个自动化脚本需要用到3个模块,如果要使用这个脚本的朋友,自己的python中可能没有安装这些模块,所以就可以安装一下 第1个模块:pyautogui 这个模块主要是用来让程序自动控制鼠标和键盘的一系列操作来达到自动化测试的目的. 在cmd下输入安装命令:pip install pyautogui 第2个模块:pyperclip 这
-
Python 实现3种回归模型(Linear Regression,Lasso,Ridge)的示例
公共的抽象基类 import numpy as np from abc import ABCMeta, abstractmethod class LinearModel(metaclass=ABCMeta): """ Abstract base class of Linear Model. """ def __init__(self): # Before fit or predict, please transform samples' mean
-
Python实现异常检测LOF算法的示例代码
目录 背景 LOF算法 1.k邻近距离 2.k距离领域 3.可达距离 4.局部可达密度 5.局部异常因子 LOF算法流程 LOF优缺点 Python实现LOF PyOD Sklearn 大家好,我是东哥. 本篇和大家介绍一个经典的异常检测算法:局部离群因子(Local Outlier Factor),简称LOF算法. 背景 Local Outlier Factor(LOF)是基于密度的经典算法(Breuning et. al. 2000), 文章发表于 SIGMOD 2000, 到目前已经有 3
-
Python实现邮件的批量发送的示例代码
1 发送文本信息 '''加密发送文本邮件''' def sendEmail(from_addr,password,to_addr,smtp_server): try: msg = MIMEText('你好,来自信息化工程所的问候...', 'plain', 'utf-8') # 文本邮件 # msg = MIMEText('<html><body><h1>你好</h1>' + '<p>send by <a href="http:/
-
Python实现自动打开电脑应用的示例代码
由于时间原因,有时候可能会错过某个上网课的时间段.因此想要实现自动定时启动DingDing. 新手一枚,如有不当勿喷望大佬指正. 自动打开DingDing可以由两种方法实现: 通过找出找出软件在电脑中快捷方式的位置(电脑屏幕中的坐标),使用代码模拟鼠标进行双击打开. 通过输入软件在电脑中的安装路径打开软件. 1.第一种方法: 在python中,使用pip install pyautogui 安装第三方库,在此库中,可以使用pyautogui.position()获取当前鼠标放置位置的坐标.我们
-
Python Opencv实现单目标检测的示例代码
一 简介 目标检测即为在图像中找到自己感兴趣的部分,将其分割出来进行下一步操作,可避免背景的干扰.以下介绍几种基于opencv的单目标检测算法,算法总体思想先尽量将目标区域的像素值全置为1,背景区域全置为0,然后通过其它方法找到目标的外接矩形并分割,在此选择一张前景和背景相差较大的图片作为示例. 环境:python3.7 opencv4.4.0 二 背景前景分离 1 灰度+二值+形态学 轮廓特征和联通组件 根据图像前景和背景的差异进行二值化,例如有明显颜色差异的转换到HSV色彩空间进行分割. 1
-
Python聊天室带界面实现的示例代码(tkinter,Mysql,Treading,socket)
一.前言 我用的是面向对象写的,把界面功能模块封装成类,然后在客户端创建对象然后进行调用.好处就是方便我们维护代码以及把相应的信息封装起来,每一个实例都是各不相同的. 所有的界面按钮处理事件都在客户端,在创建界面对象是会把客户端的处理事件函数作为创建对象的参数,之后再按钮上绑定这个函数,当点击按钮时便会回调函数 二.登录界面实现 登录界面模块chat_login_panel.py from tkinter import * # 导入模块,用户创建GUI界面 # 登陆界面类 class Login