对python3中pathlib库的Path类的使用详解
用了很久的os.path,今天发现竟然还有这么好用的库,记录下来以便使用。
1.调用库
from pathlib import
2.创建Path对象
p = Path('D:/python/1.py')
print(p)
#可以这么使用,相当于os.path.join()
p1 = Path('D:/python')
p2 = p1/'123'
print(p2)
结果
D:\python\1.py D:\python\123
3.Path.cwd()
获取当前路径
path = Path.cwd() print(path)
结果:
D:\python
4.Path.stat()
获取当前文件的信息
p = Path('1.py')
print(p.stat())
结果
os.stat_result(st_mode=33206, st_ino=8444249301448143, st_dev=2561774433, st_nlink=1, st_uid=0, st_gid=0, st_size=4, st_atime=1525926554, st_mtime=1525926554, st_ctime=1525926554)
5.Path.exists()
判断当前路径是否是文件或者文件夹
>>> Path('.').exists()
True
>>> Path('1.py').exists()
True
>>> Path('2.py').exists()
False
6.Path.glob(pattern)与Path.rglob(pattern)
Path.glob(pattern):获取路径下的所有符合pattern的文件,返回一个generator
目录下的文件如下:
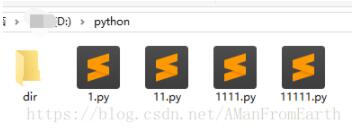
以下是获取该目录下所有py文件的路径:
path=Path.cwd()
pys = path.glob('*.py')#pys是经过yield产生的迭代器
for py in pys:
print(py)
结果:
C:\python\1.py C:\python\11.py C:\python\1111.py C:\python\11111.py
Path.rglob(pattern):与上面类似,只不过是返回路径中所有子文件夹的符合pattern的文件。
7.Path.is_dir()与Path.is_file()
Path.is_dir()判断该路径是否是文件夹
Path.is_file()判断该路径是否是文件
print('p1:')
p1 = Path('D:/python')
print(p1.is_dir())
print(p1.is_file())
print('p2:')
p2 = Path('D:/python/1.py')
print(p2.is_dir())
print(p2.is_file())
#当路径不存在时也会返回Fasle
print('wrong path:')
print(Path('D:/NoneExistsPath').is_dir())
print(Path('D:/NoneExistsPath').is_file())
结果
p1: True False p2: False True wrong path: False False
8.Path.iterdir()
当path为文件夹时,通过yield产生path文件夹下的所有文件、文件夹路径的迭代器
p = Path.cwd() for i in p.iterdir(): print(i)
结果
D:\python\1.py D:\python\11.py D:\python\1111.py D:\python\11111.py D:\python\dir
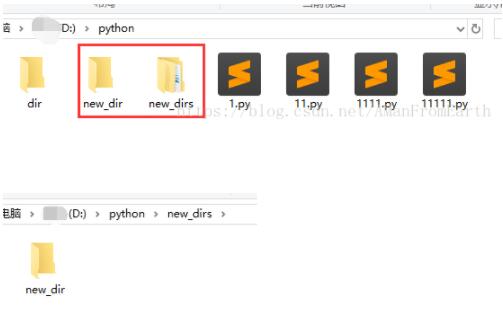
9.Path.mkdir(mode=0o777,parents=Fasle)
根据路径创建文件夹
parents=True时,会依次创建路径中间缺少的文件夹
p_new = p/'new_dir' p_new.mkdir() p_news = p/'new_dirs/new_dir' p_news.mkdir(parents=True)
结果
10.Path.open(mode='r', buffering=-1, encoding=None, errors=None, newline=None)
类似于open()函数
11.Path.rename(target)
当target是string时,重命名文件或文件夹
当target是Path时,重命名并移动文件或文件夹
p1 = Path('1.py')
p1.rename('new_name.py')
p2 = Path('11.py')
target = Path('new_dir/new_name.py')
p2.rename(target)
结果

12.Path.replace(target)
重命名当前文件或文件夹,如果target所指示的文件或文件夹已存在,则覆盖原文件
13.Path.parent(),Path.parents()
parent获取path的上级路径,parents获取path的所有上级路径
14.Path.is_absolute()
判断path是否是绝对路径
15.Path.match(pattern)
判断path是否满足pattern
16.Path.rmdir()
当path为空文件夹的时候,删除该文件夹
17.Path.name
获取path文件名
18.Path.suffix
获取path文件后缀
以上这篇对python3中pathlib库的Path类的使用详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python中的pathlib.Path为什么不继承str详解
起步 既然所有路径都可以表示为字符串,为什么 pathlib.Path 不继承 str ? 这个想法的提出在 https://mail.python.org/pipermail//python-ideas/2016-April/039475.html 可以看到,其中,还提出了将 p'/some/path/to/a/file' 返回 path.Path 实例的想法. 路径都是字符串吗? 从面向对象的继承的思想来看,如果 Path 继承自 str ,那么所有的路径都应该是字符串.但所有的路径都是字符
-
详谈Python3 操作系统与路径 模块(os / os.path / pathlib)
以下代码以Python3.6.1 / windows10为例 Less is more! #!/usr/bin/env python # coding=utf-8 __author__ = 'Luzhuo' __date__ = '2017/5/7' import os def os_demo(): # 执行命令 dirs = os.popen("dir").read() print(dirs) # 打印目录树 dirs_info = os.scandir() for info in
-
对python3中pathlib库的Path类的使用详解
用了很久的os.path,今天发现竟然还有这么好用的库,记录下来以便使用. 1.调用库 from pathlib import 2.创建Path对象 p = Path('D:/python/1.py') print(p) #可以这么使用,相当于os.path.join() p1 = Path('D:/python') p2 = p1/'123' print(p2) 结果 D:\python\1.py D:\python\123 3.Path.cwd() 获取当前路径 path = Path.cw
-

python3中_from...import...与import ...之间的区别详解(包/模块)
目录 前言 1.import ... 2.from ... import ... 3.引用也有区别 4.引用优化 总结 前言 [以下说明以tkinter模块为例进行说明] [下图为安装后在python解释器路径下lib(库)文件夹下的tkinter文件夹下的内容] 1.import ... [语法]import tkinter [说明] import引入的是包中根目录下__init__.py中的全部内容,包括其中的类.类内部的公有属性.类内部的公有方法.方法等内容.(该种方式导入包的本质就是执行
-
python3中apply函数和lambda函数的使用详解
目录 lambda函数 lambda是什么 lambda用法详解 lambda+map lambda+ filter lambda+ reduce 避免过度使用lambda 适合lambda的场景 总结 apply函数 lambda函数 lambda是什么 大家好,今天给大家带来的是有关于Python里面的lambda表达式详细解析.lambda在Python里面的用处很广,但说实话,我个人认为有关于lambda的讨论不是如何使用的问题,而是该不该用的问题.接下来还是通过大量实例和大家分享我的学
-
python中requests库session对象的妙用详解
在进行接口测试的时候,我们会调用多个接口发出多个请求,在这些请求中有时候需要保持一些共用的数据,例如cookies信息. 妙用1 requests库的session对象能够帮我们跨请求保持某些参数,也会在同一个session实例发出的所有请求之间保持cookies. 举个栗子,跨请求保持cookies,在命令行上输入下面命令: # 创建一个session对象 s = requests.Session() # 用session对象发出get请求,设置cookies s.get('http://ht
-
对Python3中列表乘以某一个数的示例详解
在Python列表操作中:列表乘以某一个数,如list2 = list1 * 2 得到一个新的列表是list1的元素重复n次,且list1不改变. 但运行如下代码时,得到的新列表b中,b[0]和b[1]的地址相同,即对b[0]进行操作,b[1]也会发生改变. a = [0] b = [a] * 2 print(b) b[0].append(1) print(b) 输出为: [[0], [0]] [[0, 1], [0, 1]] 随后尝试以下几种代码: 代码(1) a = [0] b = [a f
-
python中join与os.path.join()函数实例详解
目录 一.join函数 (一)参数使用说明 (二)实例说明 二.os.path.join() (一)参数使用 (二)实例说明 总结 一.join函数 (一)参数使用说明 描述 Python join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串. 语法 join()方法语法: str.join(sequence) 参数 sequence -- 要连接的元素序列. 返回值 返回通过指定字符连接序列中元素后生成的新字符串. (二)实例说明 1.对序列进行操作 x = ['qingni
-
Python3中map()、reduce()、filter()的用法详解
目录 1.map() 2.filter() 3.reduce() Python3中的map().reduce().filter() 这3个一般是用于对序列进行操作的内置函数,它们经常需要与 匿名函数 lambda 联合起来使用,我们今天就来学习下. 1.map() map() 可以用于在函数中对指定序列做映射,返回值是一个迭代器,其使用语法如下: map(function, *iterables) 上面的第一个参数 function 指一个函数,第二个参数 iterable 指一个或多个可迭代对
-
Android中Glide获取图片Path、Bitmap用法详解
我们在此之前给大家介绍过图片加载框架Glide的基本用法介绍,大家可以先参考一下,本篇内容更加深入的分析了Glide获取图片Path.Bitmap用法,以及实现的代码分析. 1. 获取Bitmap: 1)在图片下载缓存好之后获取 Glide.with(mContext).load(url).asBitmap().into(new SimpleTarget<Bitmap>() { @Override public void onResourceReady(Bitmap resource, Gli
-
java中List集合及其实现类的方法详解
List集合_List接口介绍 特点 1).有序的: 2).可以存储重复元素: 3).可以通过索引访问: List<String> list = new ArrayList<>(); list.add("张无忌"); list.add("张三丰"); list.add("章子怡"); list.add("章子怡");//OK的,可以添加 for(String s : list){ System.out.
-
python3中datetime库,time库以及pandas中的时间函数区别与详解
1介绍datetime库之前 我们先比较下time库和datetime库的区别 先说下time 在 Python 文档里,time是归类在Generic Operating System Services中,换句话说, 它提供的功能是更加接近于操作系统层面的.通读文档可知,time 模块是围绕着 Unix Timestamp 进行的. 该模块主要包括一个类 struct_time,另外其他几个函数及相关常量. 需要注意的是在该模块中的大多数函数是调用了所在平台C library的同名函数, 所以