深入浅析ELK原理与简介
为什么用到ELK:
一般我们需要进行日志分析场景:直接在日志文件中 grep、awk 就可以获得自己想要的信息。但在规模较大的场景中,此方法效率低下,面临问题包括日志量太大如何归档、文本搜索太慢怎么办、如何多维度查询。需要集中化的日志管理,所有服务器上的日志收集汇总。常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。
一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
一个完整的集中式日志系统,需要包含以下几个主要特点:
- 收集-能够采集多种来源的日志数据
- 传输-能够稳定的把日志数据传输到中央系统
- 存储-如何存储日志数据
- 分析-可以支持 UI 分析
- 警告-能够提供错误报告,监控机制
ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用。目前主流的一种日志系统。
ELK简介:
ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件。新增了一个FileBeat,它是一个轻量级的日志收集处理工具(Agent),Filebeat占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,官方也推荐此工具。
Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
Kibana 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
Filebeat隶属于Beats。目前Beats包含四种工具:
- Packetbeat(搜集网络流量数据)
- Topbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)
- Filebeat(搜集文件数据)
- Winlogbeat(搜集 Windows 事件日志数据)
官方文档:
Filebeat:
https://www.elastic.co/cn/products/beats/filebeat
https://www.elastic.co/guide/en/beats/filebeat/5.6/index.html
Logstash:
https://www.elastic.co/cn/products/logstash
https://www.elastic.co/guide/en/logstash/5.6/index.html
Kibana:
https://www.elastic.co/cn/products/kibana
https://www.elastic.co/guide/en/kibana/5.5/index.html
Elasticsearch:
https://www.elastic.co/cn/products/elasticsearch
https://www.elastic.co/guide/en/elasticsearch/reference/5.6/index.html
elasticsearch中文社区:
https://elasticsearch.cn/
ELK架构图:
架构图一:
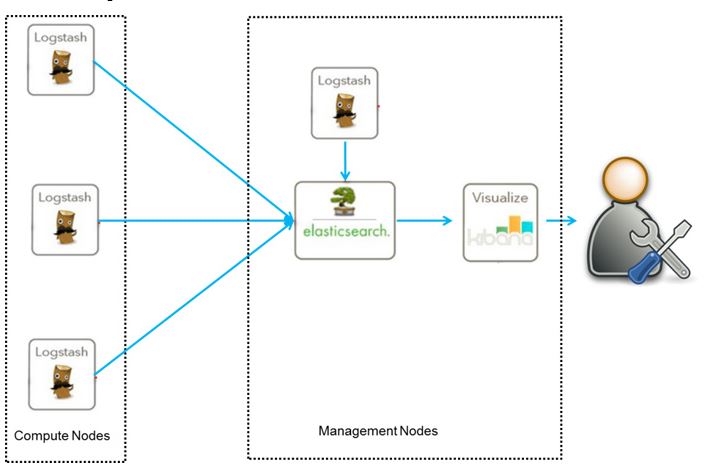
这是最简单的一种ELK架构方式。优点是搭建简单,易于上手。缺点是Logstash耗资源较大,运行占用CPU和内存高。另外没有消息队列缓存,存在数据丢失隐患。
此架构由Logstash分布于各个节点上搜集相关日志、数据,并经过分析、过滤后发送给远端服务器上的Elasticsearch进行存储。Elasticsearch将数据以分片的形式压缩存储并提供多种API供用户查询,操作。用户亦可以更直观的通过配置Kibana Web方便的对日志查询,并根据数据生成报表。
架构图二:

此种架构引入了消息队列机制,位于各个节点上的Logstash Agent先将数据/日志传递给Kafka(或者Redis),并将队列中消息或数据间接传递给Logstash,Logstash过滤、分析后将数据传递给Elasticsearch存储。最后由Kibana将日志和数据呈现给用户。因为引入了Kafka(或者Redis),所以即使远端Logstash server因故障停止运行,数据将会先被存储下来,从而避免数据丢失。
架构图三:

此种架构将收集端logstash替换为beats,更灵活,消耗资源更少,扩展性更强。同时可配置Logstash 和Elasticsearch 集群用于支持大集群系统的运维日志数据监控和查询。
Filebeat工作原理:
Filebeat由两个主要组件组成:prospectors 和 harvesters。这两个组件协同工作将文件变动发送到指定的输出中。

Harvester(收割机):负责读取单个文件内容。每个文件会启动一个Harvester,每个Harvester会逐行读取各个文件,并将文件内容发送到制定输出中。Harvester负责打开和关闭文件,意味在Harvester运行的时候,文件描述符处于打开状态,如果文件在收集中被重命名或者被删除,Filebeat会继续读取此文件。所以在Harvester关闭之前,磁盘不会被释放。默认情况filebeat会保持文件打开的状态,直到达到close_inactive(如果此选项开启,filebeat会在指定时间内将不再更新的文件句柄关闭,时间从harvester读取最后一行的时间开始计时。若文件句柄被关闭后,文件发生变化,则会启动一个新的harvester。关闭文件句柄的时间不取决于文件的修改时间,若此参数配置不当,则可能发生日志不实时的情况,由scan_frequency参数决定,默认10s。Harvester使用内部时间戳来记录文件最后被收集的时间。例如:设置5m,则在Harvester读取文件的最后一行之后,开始倒计时5分钟,若5分钟内文件无变化,则关闭文件句柄。默认5m)。
Prospector(勘测者):负责管理Harvester并找到所有读取源。
Prospector会找到/apps/logs/*目录下的所有info.log文件,并为每个文件启动一个Harvester。Prospector会检查每个文件,看Harvester是否已经启动,是否需要启动,或者文件是否可以忽略。若Harvester关闭,只有在文件大小发生变化的时候Prospector才会执行检查。只能检测本地的文件。
Filebeat如何记录文件状态:
将文件状态记录在文件中(默认在/var/lib/filebeat/registry)。此状态可以记住Harvester收集文件的偏移量。若连接不上输出设备,如ES等,filebeat会记录发送前的最后一行,并再可以连接的时候继续发送。Filebeat在运行的时候,Prospector状态会被记录在内存中。Filebeat重启的时候,利用registry记录的状态来进行重建,用来还原到重启之前的状态。每个Prospector会为每个找到的文件记录一个状态,对于每个文件,Filebeat存储唯一标识符以检测文件是否先前被收集。
Filebeat如何保证事件至少被输出一次:
Filebeat之所以能保证事件至少被传递到配置的输出一次,没有数据丢失,是因为filebeat将每个事件的传递状态保存在文件中。在未得到输出方确认时,filebeat会尝试一直发送,直到得到回应。若filebeat在传输过程中被关闭,则不会再关闭之前确认所有时事件。任何在filebeat关闭之前为确认的时间,都会在filebeat重启之后重新发送。这可确保至少发送一次,但有可能会重复。可通过设置shutdown_timeout 参数来设置关闭之前的等待事件回应的时间(默认禁用)。
Logstash工作原理:
Logstash事件处理有三个阶段:inputs → filters → outputs。是一个接收,处理,转发日志的工具。支持系统日志,webserver日志,错误日志,应用日志,总之包括所有可以抛出来的日志类型。
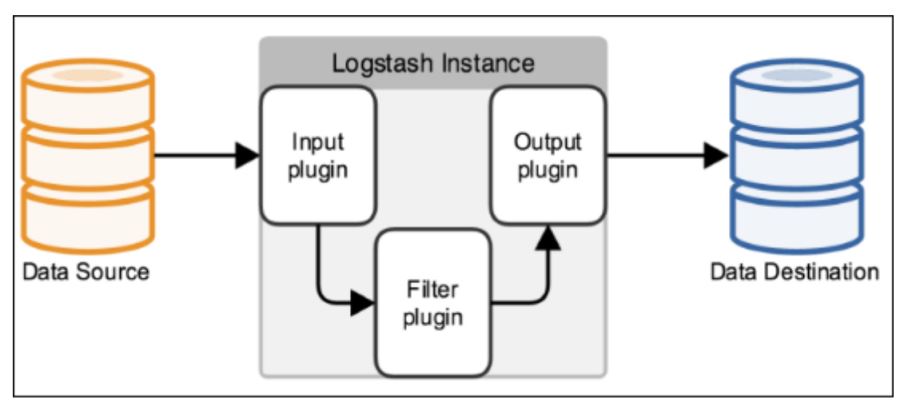
Input:输入数据到logstash。
一些常用的输入为:
file:从文件系统的文件中读取,类似于tail -f命令
syslog:在514端口上监听系统日志消息,并根据RFC3164标准进行解析
redis:从redis service中读取
beats:从filebeat中读取
Filters:数据中间处理,对数据进行操作。
一些常用的过滤器为:
grok:解析任意文本数据,Grok 是 Logstash 最重要的插件。它的主要作用就是将文本格式的字符串,转换成为具体的结构化的数据,配合正则表达式使用。内置120多个解析语法。
官方提供的grok表达式:https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns
grok在线调试:https://grokdebug.herokuapp.com/
mutate:对字段进行转换。例如对字段进行删除、替换、修改、重命名等。
drop:丢弃一部分events不进行处理。
clone:拷贝 event,这个过程中也可以添加或移除字段。
geoip:添加地理信息(为前台kibana图形化展示使用)
Outputs:outputs是logstash处理管道的最末端组件。一个event可以在处理过程中经过多重输出,但是一旦所有的outputs都执行结束,这个event也就完成生命周期。
一些常见的outputs为:
elasticsearch:可以高效的保存数据,并且能够方便和简单的进行查询。
file:将event数据保存到文件中。
graphite:将event数据发送到图形化组件中,一个很流行的开源存储图形化展示的组件。
Codecs:codecs 是基于数据流的过滤器,它可以作为input,output的一部分配置。Codecs可以帮助你轻松的分割发送过来已经被序列化的数据。
一些常见的codecs:
json:使用json格式对数据进行编码/解码。
multiline:将汇多个事件中数据汇总为一个单一的行。比如:java异常信息和堆栈信息。
到此这篇关于ELK原理与介绍的文章就介绍到这了,更多相关ELK原理内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Docker-compose部署ELK的示例代码
环境 主机IP 192.168.0.9 Docker version 19.03.2 docker-compose version 1.24.0-rc1 elasticsearch version 6.6.1 kibana version 6.6.1 logstash version 6.6.1 一.ELK-dockerfile文件编写及配置文件 ● elasticsearch 1.elasticsearch-dockerfile FROM centos:latest ADD elasticse
-
浅谈Node框架接入ELK实践总结
我们都有过上机器查日志的经历,当集群数量增多的时候,这种原始的操作带来的低效率不仅给我们定位现网问题带来极大的挑战,同时,我们也无法对我们服务框架的各项指标进行有效的量化诊断,更无从谈有针对性的优化和改进.这个时候,构建具备信息查找,服务诊断,数据分析等功能的实时日志监控系统尤为重要. ELK (ELK Stack: ElasticSearch, LogStash, Kibana, Beats) 是一套成熟的日志解决方案,其开源及高性能在各大公司广泛使用.而我们业务所使用的服务框架,如何接入 E
-
基于Docker快速搭建ELK的方法
[摘要] 本文基于自建的Docker平台速搭建一套完整的ELK系统,相关的镜像直接从Docker Hub上获取,可以快速实现日志的采集和分析检索. 准备镜像 获取ES镜像:docker pull elasticsearch:latest 获取kibana镜像:docker pull kibana:latest 获取logstash镜像:docker pull logstash:latest 启动Elasticsearch 官方镜像里面ES的配置文件保存在/usr/share/elasticsea
-
使用Docker搭建ELK日志系统的方法示例
以下安装都是以 ~/ 目录作为安装根目录. ElasticSearch 下载镜像: $ sudo docker pull elasticsearch:5.5.0 运行ElasticSearch容器: $ sudo docker run -it -d -p 9200:9200 -p 9300:9300 \ -v ~/elasticsearch/data:/usr/share/elasticsearch/data \ --name myes elasticsearch:5.5.0 特别注意的是如果使
-
深入浅析ELK原理与简介
为什么用到ELK: 一般我们需要进行日志分析场景:直接在日志文件中 grep.awk 就可以获得自己想要的信息.但在规模较大的场景中,此方法效率低下,面临问题包括日志量太大如何归档.文本搜索太慢怎么办.如何多维度查询.需要集中化的日志管理,所有服务器上的日志收集汇总.常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问. 一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,
-
浅析bootstrap原理及优缺点
网格系统的实现原理,是通过定义容器大小,平分12份(也有平分成24份或32份,但12份是最常见的),再调整内外边距,最后结合媒体查询,就制作出了强大的响应式网格系统.Bootstrap框架中的网格系统就是将容器平分成12份. bootstrap优缺点: 1.bootstap最近发布了bootstrap4,拥有了box-flex布局等更新,紧跟最新的web技术的发展 2.比较成熟,在大量的项目中充分的使用和测试 3.拥有完善的文档,使用起来更方便 4.有大量的组件样式,接受定制 缺点: 1.如果有
-
Python接口自动化浅析数据驱动原理
在上一篇Python接口自动化测试系列文章:Python接口自动化浅析登录接口测试实战,主要介绍接口概念.接口用例设计及登录接口测试实战. 以下主要介绍使用openpyxl模块操作excel及结合ddt实现数据驱动. 在此之前,我们已经实现了用unittest框架编写测试用例,实现了请求接口的封装,这样虽然已经可以完成接口的自动化测试,但是其复用性并不高. 我们看到每个方法(测试用例)的代码几乎是一模一样的,试想一下,在我们的测试场景中, 一个登录接口有可能会有十几条到几十条测试用例,如果每组数
-
浅析vue-router原理
近期被问到一个问题,在你们项目中使用的是Vue的SPA(单页面)还是Vue的多页面设计? 这篇文章主要围绕Vue的SPA单页面设计展开. 关于如何展开Vue多页面设计请点击查看. vue-router是什么? 首先我们需要知道vue-router是什么,它是干什么的? 这里指的路由并不是指我们平时所说的硬件路由器,这里的路由就是SPA(单页应用)的路径管理器. 换句话说,vue-router就是WebApp的链接路径管理系统. vue-router是Vue.js官方的路由插件,它和vue.js是
-
深入浅析python with语句简介
with 语句是从 Python 2.5 开始引入的一种与异常处理相关的功能(2.5 版本中要通过 from __future__ import with_statement 导入后才可以使用),从 2.6 版本开始缺省可用(参考 What's new in Python 2.6? 中 with 语句相关部分介绍).with 语句适用于对资源进行访问的场合,确保不管使用过程中是否发生异常都会执行必要的"清理"操作,释放资源,比如文件使用后自动关闭.线程中锁的自动获取和释放等. 术语 要
-
浅析PHP原理之变量(Variables inside PHP)
或许你知道,或许你不知道,PHP是一个弱类型,动态的脚本语言.所谓弱类型,就是说PHP并不严格验证变量类型(严格来讲,PHP是一个中强类型语言,这部分内容会在以后的文章中叙述),在申明一个变量的时候,并不需要显示指明它保存的数据的类型: 复制代码 代码如下: <?php $var = 1; //int $var = "laruence"; //string $var = 1.0002; //float $var = array(); // array $var = ne
-
浅析PHP原理之变量分离/引用(Variables Separation)
首先我们回顾一下zval的结构: 复制代码 代码如下: struct _zval_struct { /* Variable information */ zvalue_value value; /* value */ zend_uint refcount; zend_uchar type; /* active type */ zend_uchar is_ref;}; 其中的refcount和is_ref字段我们一直都没有介绍过
-
深入浅析React refs的简介
一.是什么 Refs在计算机中称为弹性文件系统(英语:Resilient File System,简称ReFS) React中的Refs提供了一种方式,允许我们访问DOM节点或在render方法中创建的React元素 本质为ReactDOM.render()返回的组件实例,如果是渲染组件则返回的是组件实例,如果渲染dom则返回的是具体的dom节点 二.如何使用 创建ref的形式有三种: 传入字符串,使用时通过 this.refs.传入的字符串的格式获取对应的元素 传入对象,对象是通过 React
-
Python接口自动化浅析yaml配置文件原理及用法
目录 一.yaml介绍及使用 01 yaml简介 02 yaml语法规则 03 yaml数据结构 对象 数组 纯量 二.yaml配置文件的使用 01 yaml配置文件准备 02 yaml配置文件格式校验 三.yaml配置文件读写 01 安装pyYaml 02 yaml模块源码解析 load: dump: 03 读写yaml配置文件 在上一篇Python接口自动化测试系列文章:Python接口自动化浅析数据驱动原理,主要介绍openpyxl操作excel,结合ddt实现数据驱动. 在自动化过程中,
-
JavaScript闭包原理及作用详解
目录 简介 闭包的用途 柯里化 实现公有变量 缓存 封装(属性私有化) 闭包的原理 垃圾收集 简介 实际开发中的优化 简介 说明 本文介绍JavaScript的闭包的作用.用途及其原理. 闭包的定义 闭包是指内部函数总是可以访问其所在的外部函数中声明的变量和参数,即使在其外部函 数被返回(寿命终结)了之后. 闭包的作用(特点) 1.函数嵌套函数 2.内部函数可以引用外部函数的参数或者变量 3.外部函数的参数和变量不会被垃圾回收,因为被内部函数引用. 闭包与全局变量 闭包的用途 柯里化 可以通过参