在 Jupyter 中重新导入特定的 Python 文件(场景分析)
Jupyter 是数据分析领域非常有名的开发环境,使用 Jupyter 写数据分析相关的代码会大大节约开发时间。
设想这样一个场景:别的部门的同事传给你一个数据分析的模块,用于实现对数据的高级分析。模块里面有上百个函数。
如果直接写 Python 文件来调用数据分析模块,那么使用方法非常简单:
from analyze import FathersAnalyzer
data = [...]
father = FathersAnalyzer(data)
result = father.analyze()
print(f'分析结果为:{result}')
现在,你需要使用 Jupyter 来调用这个分析模块。你应该怎么在 Jupyter里面调用?
你可能会觉得,这还不简单吗?直接把这个模块的代码与 Jupyter Notebook 的 .ipynb 文件放在一起,然后在 Jupyter 里面像导入普通模块那样导入即可,如下图所示:

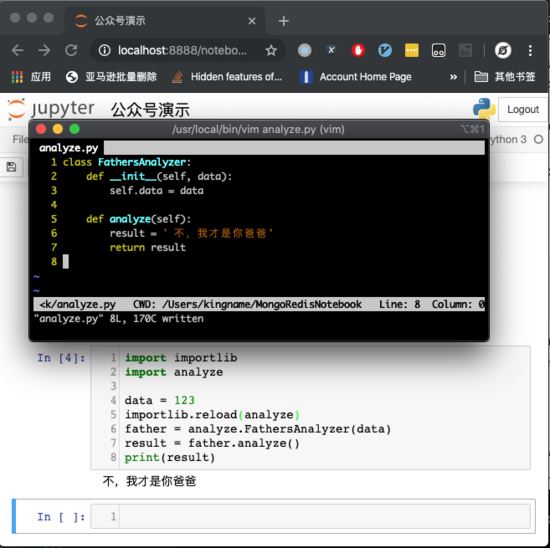
那么现在问题来了,如果我此时修改了 analyze.py 文件,会出现什么情况呢?
我们改一下看看,如下图所示。

重新运行这个 Cell 中的代码,代码中虽然有 from analyze import FathersAnalyzer ,看起来像是重新导入了这个模块,但是运行却发现,它运行的是修改之前的代码。
这是因为,一个 Jupyter Notebook 中的所有代码,都是在同一个运行时中运行的代码,当你多次导入同一个模块时,Python 的包管理机制会自动忽略后面的导入,始终只使用第一次导入的结果(所以使用这种方式也可以实现单例模式)。
那么如果我在修改了被导入的包以后,想重新导入它怎么办呢?有3种方案:
importlib
但这种方案弊端也很明显——除非你按顺序运行每一个 Cell,否则,你的代码会变成下图这样:
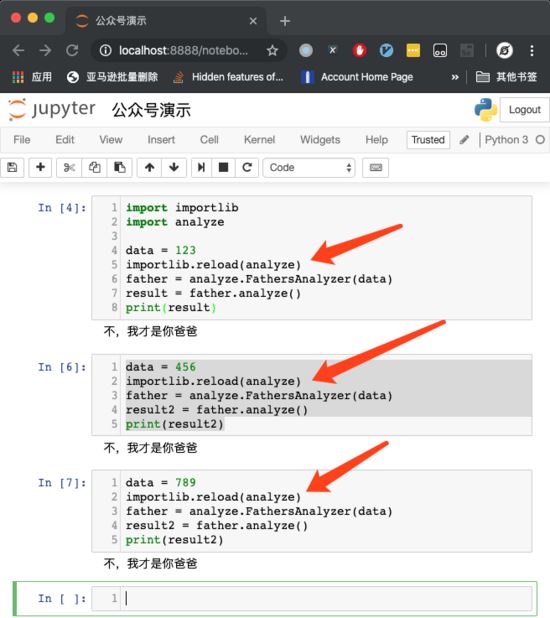
在每一个 Cell 里面都需要 重新加载一次分析模块,否则,很有可能在你单独运行某一个 Cell 的时候,用的是老的代码,就会导致难以察觉的 bug。
使用 Jupyter 自带的 %autoreload :
%load_ext autoreload %autoreload 1 %aimport analyze data = 123 importlib.reload(analyze) father = analyze.FathersAnalyzer(data) result = father.analyze() print(result)
运行效果如下图所示:

其中关键的代码有三行:
%load_ext autoreload %autoreload 1 %aimport analyze
这三行代码只有在 Jupyter 里面才能正常运行,在 普通的.py 文件里面这样写会报错。它们的作用是:第1行启动 autoreload 机制。第2行,设置自动加载通过 %aimport 导入的模块。第3行使用 %aimport 导入 analyze 模块。
这样写以后,任意一个 Cell 运行,所有被 %aimport 导入的模块都会被重新加载一次。从而让你每次都使用最新的代码。
当然,你还可以进一步偷懒,把特殊代码缩减为2行:
%load_ext autoreload %autoreload 2
%autoreload 后面的参数被设置为2时,每次运行任意一个 Cell,都会自动重新加载所有 import xxx 导入的模块。这样做的代价是,运行会慢一些。
总结
以上所述是小编给大家介绍的在 Jupyter 中重新导入特定的 Python 文件的方法,希望对大家有所帮助!
相关推荐
-
windows系统中Python多版本与jupyter notebook使用虚拟环境的过程
本人电脑是windows系统,装了Python3.7版本,但目前tensorflow支持最新的python版本为3.6,遂想再安装Python3.6以跑tensorflow. 因为看极客时间的专栏提到Jupyter是个科学运算语言的计算工具,特别适合机器学习与数学统计,因此也要装个体验一翻. 一.安装Python 电脑原先已经装了Python3.7,virtualenv,virtualenvwrapper,jupyter notebook. 在官网上直接下载windows版本的python3.6
-
Python3 jupyter notebook 服务器搭建过程
1. jupyter notebook 安装 •创建 jupyter 目录 mkdir jupyter cd jupyter/ •创建独立的 Python3 运行环境,并激活进入该环境 virtualenv --python=python3 --no-site-packages venv source venv/bin/activate •安装 jupyter pip install jupyter 2. jupyter notebook 配置 •创建 notebooks 目录 mkdir no
-
win10下安装Anaconda的教程(python环境+jupyter_notebook)
前言: 什么是anaconda?? Anaconda指的是一个开源的Python发行版本,其包含了conda.Python等180多个科学包及其依赖项. [1] 因为包含了大量的科学包,Anaconda 的下载文件比较大(约 531 MB),如果只需要某些包,或者需要节省带宽或存储空间,也可以使用Miniconda这个较小的发行版(仅包含conda和 Python) 什么是jupyter notebook?? Jupyter Notebook 是一款开放源代码的 Web 应用程序,可让我们创建并
-
在 Jupyter 中重新导入特定的 Python 文件(场景分析)
Jupyter 是数据分析领域非常有名的开发环境,使用 Jupyter 写数据分析相关的代码会大大节约开发时间. 设想这样一个场景:别的部门的同事传给你一个数据分析的模块,用于实现对数据的高级分析.模块里面有上百个函数. 如果直接写 Python 文件来调用数据分析模块,那么使用方法非常简单: from analyze import FathersAnalyzer data = [...] father = FathersAnalyzer(data) result = father.analyz
-
在django项目中,如何单独运行某个python文件
有时候,我们可能想在django中写一些代码来测试某些功能,我们希望在django项目中单独运行某个python文件来做这项测试工作. 但是如果直接执行命令python xxx.py来运行django项目中的python文件会报错 在运行该文件之前应该先加载django的配置 import sys import os import django # 这两行很重要,用来寻找项目根目录,os.path.dirname要写多少个根据要运行的python文件到根目录的层数决定 BASE_DIR = os
-
Node.js中npx命令的使用方法及场景分析
npx使用教程 今晚在学习Vue-Cli时, 由于突发奇想想试试最新的@4.x.x版本, 但是本地全局安装的脚手架版本是@2.x.x的, 因为不想污染全局于是就想到用npx命令, 一路上踩坑不断, 为了以后能够更好的使用npx并区分其跟npm的指令, 就有了本篇笔记 npm 是从5.2版开始, 增加(自带)了 npx 命令. 如果发现没安装请手动安装: npm i -g npx npm与npx的概念 NPM(Node Package Manager) 是Node.js提供的一个包管理器, 可以使
-
Python文件如何引入?详解引入Python文件步骤
python基本语法--引入Python文件 1.新建python文件 :在同目录lib下创建mylib.py和loadlib.py两个文件 2.在mylib.py文件中创建一个Hello的类 并且给这个类添加一个sayHello的方法,让她输出hello python 3.在loadlib.py 文件中引入mylib import mylib 4.在loadlib中调用引用过来的python文件mylib.py中的Hello方法 这时import mylib中的mylib就相当与一个命名空间
-

python中模块导入模式详解
目录 模块导入 1.1 import导入模块 1.2 from 模块名 import 导入模板的方法 1.3 as 关键字 OS模块操作文件 OS模块的作用 模块的制作.发布.安装 3.1 模块制作 3.2 模块的分 3.3 示例 3.4 测试方法 3.5 all魔术方法 模块导入 1.1 import导入模块 所谓的模块其实就是一个外部的工具包,其中存在的其实就是Python文件,这些文件都实现了某种特定的功能,我们导入包之后直接使用即可,非常的方便. 在开发中使用最多的就是使用: impor
-
Python中import导入不同目录的模块方法详解
测试的目录如下: root ├── module_root.py ├── package_a │ ├── child │ │ ├── __init__.py │ │ └── child_a.py │ ├── module.py │ └── module_a.py └── package_b └── module_b.py 每个文件中的内容如下(__init__.py文件可以为空): print(__name
-
文件上传服务器-jupyter 中python解压及压缩方式
由于并不清楚服务器具体地址,只有jupyter 连接的情况下,上传文件. 方法一:用Linux命令 直接用linux命令,在jupyter中只需要在命令前加一个!即可.学校服务器上没有装zip,但装了tar,可以在压缩的时候选择文件压缩为.tar.gz的文件格式. 命令: !tar -zxvf ./Language-Detector.tar.gz 方法二: 用python的函数模块. ### 利用zipfile模块来压缩和解压文件 <br> 先将想要上传的多个文件压缩为.zip格式,在jupy
-
终端能到import模块 解决jupyter notebook无法导入的问题
这个问题让我查了许多天才解决,为了避免后面的人重复走弯路,记录下来. 问题描述: 我在ubuntu 下编译安装了caffe ,在命令行模式下可以import caffe ,但是在jupyter notebook 中无法import caffe,同样的 我安装的pytorch 也遇到了类似的问题. 解决方案: 首先在打开终端,输入python , 然后import sys,最后执行sys.executable 结果如下图,路径是:/home/jack/anaconda2/bin/python 第二
-
python文件特定行插入和替换实例详解
python文件特定行插入和替换实例详解 python提供了read,write,但和很多语言类似似乎没有提供insert.当然真要提供的话,肯定是可以实现的,但可能引入insert会带来很多其他问题,比如在插入过程中crash掉可能会导致后面的内容没来得及写回. 不过用fileinput可以简单实现在特定行插入的需求: Python代码 import os import fileinput def file_insert(fname,linenos=[],strings=[]): ""
-
java中静态导入机制用法实例详解
java中静态导入机制用法实例详解 这里主要讲解了如何使用Java中静态机制的用法,这里提供了简单实例大家可以参考下. 静态常量类 在java开发中,我们会经常用到一些静态常量用于状态判断等操作.为了能够在多个地方复用这些常量,通常每个模块都会加一个常量类,举个简单的列子: import com.sky.OrderMouleConsstants; /** * Created by gantianxing on 2017/4/21. */ public class Test { public vo