告别网页搜索!教你用python实现一款属于自己的翻译词典软件
一、设计理念
1.先写一个登录的py文件,用python的tkinter库
2.再写一个py文件用于爬取有道翻译输出栏的内容
3.再利用python的tkinter库,完成软件运行的窗口
4.将窗口的返回值与爬取有道翻译的结果接口对一下
5.第二个py文件里import第一个py文件,两个文件相关联
二、代码解析
请求方式为post,要注意from data里的值,这里可以在网页上再输一个想要翻译的内容,观察from data里的值的变化,可以确定'salt'、 ‘sign'、 'lts'这三个值变化
进入网页源代码搜索.js,找到对应的js文件,找到他们的加密规则,最后将获得的response转化为字典,提取结果
class YouDao(object):
a.LoginPage()
def __init__(self):
pass
def crawl(self, content):
# 进入网页源代码搜索.js 点击进入搜索看是否有'salt''sign''lts'这三个 有则证明找的文件正确 全部复制 网页搜js格式化转化 创建js文件
lts = int(time.time() * 1000) # 时间戳转化为毫秒 时间戳转化为时间 站长工具
timestamp = lts + random.randint(0, 10)
# sign: n.md5("fanyideskweb" + e + i + "Tbh5E8=q6U3EXe+&L[4c@")
a = "fanyideskweb"
e = content
i = str(timestamp)
d = "Tbh5E8=q6U3EXe+&L[4c@"
sign = hashlib.md5((a+e+i+d).encode('utf-8')).hexdigest()
data = {
'i': content,
'from': 'AUTO',
'to': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'salt': timestamp,
'sign': sign,
'lts': lts,
'bv': 'dd67d51c2bbb03cccdbcfa48735ba27f',
'doctype': 'json',
'version': '2.1',
'keyfrom': 'fanyi.web',
'action': 'FY_BY_CLICKBUTTION'
}
data = urllib.parse.urlencode(data).encode('utf-8')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36',
'Cookie': 'OUTFOX_SEARCH_USER_ID=406040753@221.204.120.171; DICT_UGC=be3af0da19b5c5e6aa4e17bd8d90b28a|; JSESSIONID=abcJcdIfpYuE3eNgyi3Dx; OUTFOX_SEARCH_USER_ID_NCOO=902501357.1460881; user-from=http://www.youdao.com/; from-page=http://www.youdao.com/; _ntes_nnid=250706e8175b6796101a34821527eb62,1612611490655; DICT_SESS=v2|qKlfGGGmbVOAOfp40fQy0UWhfPuOMzWRlfk4Qz0LYERTu0flfn4Ul0l50He40fOW0TK6LlWRf6B0w46LYmh46F0JShMTLOfOm0; DICT_LOGIN=1||1612612510172; STUDY_SESS=EtwvT8KhyXqnLv8r0zdde8FcMOICmtZSIsltEiKZiAQq44wPVNN6PupszWYKIkBKfygQdvKlXU7p3aF+p0H6VcZLod3s2Bld6H/EWIphmRS92qG/3vVhSxHFAXq2yJp8QyH/R6RElNstKdVewVkZp+NyGWhzlamzU5dl6aBiyQ2Ybdo8MpdaPQB26wR6JPAU+P6MxCmnJEvne6pPMc9TTJJnThNrM7aj0X5LVpSBvjZ0h3M1drl4ZsmtkumIhrpyk1pBNevj8UEmS52Cj8DFo+yez89Xrbg4rxsvfSmuH21KlOh/Gwx6G1S/X4FQ7qd/Z2lDsk6Qgl21Md/1bCxa/orloi9qObM4N2yVCVhvkDdg5ILQezB8iskCpUa+ESZk; STUDY_INFO=UID_10AE81F6EF9DD9807BAC3FF3FD6407BA|4|1456638755|1612612364854; ___rl__test__cookies=1612663596564',
'Referer': 'http://fanyi.youdao.com/',
}
request = urllib.request.Request('http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule',
method='POST', data=data, headers=headers)
response = urllib.request.urlopen(request)
result_str = response.read().decode('utf-8')
result_dict = json.loads(result_str)
result = result_dict["translateResult"][0][0]["tgt"]
return result
三、软件窗口界面
尤其注意按钮这个地方
self.button = Button(self.window, text=u'查询', command=self.function)
command命令执行function
class Application(object):
def __init__(self):
# 创建一个窗口
self.window = Tk()
# 窗口标题
self.window.title(u'武亮宇翻译词典')
# 设置窗口大小位置
self.window.geometry("280x350+400+150")
# 输入框
self.entry = Entry(self.window)
self.entry.place(x=10, y=10, width=200, height=25) # width=宽度, height=高度
# 查询按钮
self.button = Button(self.window, text=u'查询', command=self.function) # command执行命令的意思 执行这个函数
self.button.place(x=220, y=10, width=50, height=25)
# 翻译结果标题
self.label = Label(self.window, text=u'翻译结果:')
self.label.place(x=10, y=45)
# 翻译框
self.text = Text(self.window, background='#ccc') # 设置背景颜色
self.text.place(x=10, y=75, width=260, height=265)
function这块要把爬虫返回的值和窗口的翻译框做一下接口
def function(self):
# 从输入框中获取用户的值
content = self.entry.get()
# 把值发送给有道服务器进行翻译
youdao = YouDao()
result = youdao.crawl(content)
# 把结果放在翻译框里
self.text.delete(1.0, END) # 每次查询先删除一下
self.text.insert(END, result) # 插入文本最后的位置 导入END库
四、源码展示
import urllib.request # 发送网络请求
import urllib.parse # 参数解析
import time
import random
import hashlib
import json
from tkinter import Tk, Entry, Button, Label, Text, END # Tk(创建窗口), Entry(输入框), Button(按钮), Label(标签), Text(文本框),
# END
import a
class YouDao(object):
a.LoginPage()
def __init__(self):
pass
def crawl(self, content):
# 进入网页源代码搜索.js 点击进入搜索看是否有'salt''sign''lts'这三个 有则证明找的文件正确 全部复制 网页搜js格式化转化 创建js文件
lts = int(time.time() * 1000) # 时间戳转化为毫秒 时间戳转化为时间 站长工具
timestamp = lts + random.randint(0, 10)
# sign: n.md5("fanyideskweb" + e + i + "Tbh5E8=q6U3EXe+&L[4c@")
a = "fanyideskweb"
e = content
i = str(timestamp)
d = "Tbh5E8=q6U3EXe+&L[4c@"
sign = hashlib.md5((a+e+i+d).encode('utf-8')).hexdigest()
data = {
'i': content,
'from': 'AUTO',
'to': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'salt': timestamp,
'sign': sign,
'lts': lts,
'bv': 'dd67d51c2bbb03cccdbcfa48735ba27f',
'doctype': 'json',
'version': '2.1',
'keyfrom': 'fanyi.web',
'action': 'FY_BY_CLICKBUTTION'
}
data = urllib.parse.urlencode(data).encode('utf-8')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36',
'Cookie': 'OUTFOX_SEARCH_USER_ID=406040753@221.204.120.171; DICT_UGC=be3af0da19b5c5e6aa4e17bd8d90b28a|; JSESSIONID=abcJcdIfpYuE3eNgyi3Dx; OUTFOX_SEARCH_USER_ID_NCOO=902501357.1460881; user-from=http://www.youdao.com/; from-page=http://www.youdao.com/; _ntes_nnid=250706e8175b6796101a34821527eb62,1612611490655; DICT_SESS=v2|qKlfGGGmbVOAOfp40fQy0UWhfPuOMzWRlfk4Qz0LYERTu0flfn4Ul0l50He40fOW0TK6LlWRf6B0w46LYmh46F0JShMTLOfOm0; DICT_LOGIN=1||1612612510172; STUDY_SESS=EtwvT8KhyXqnLv8r0zdde8FcMOICmtZSIsltEiKZiAQq44wPVNN6PupszWYKIkBKfygQdvKlXU7p3aF+p0H6VcZLod3s2Bld6H/EWIphmRS92qG/3vVhSxHFAXq2yJp8QyH/R6RElNstKdVewVkZp+NyGWhzlamzU5dl6aBiyQ2Ybdo8MpdaPQB26wR6JPAU+P6MxCmnJEvne6pPMc9TTJJnThNrM7aj0X5LVpSBvjZ0h3M1drl4ZsmtkumIhrpyk1pBNevj8UEmS52Cj8DFo+yez89Xrbg4rxsvfSmuH21KlOh/Gwx6G1S/X4FQ7qd/Z2lDsk6Qgl21Md/1bCxa/orloi9qObM4N2yVCVhvkDdg5ILQezB8iskCpUa+ESZk; STUDY_INFO=UID_10AE81F6EF9DD9807BAC3FF3FD6407BA|4|1456638755|1612612364854; ___rl__test__cookies=1612663596564',
'Referer': 'http://fanyi.youdao.com/',
}
request = urllib.request.Request('http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule',
method='POST', data=data, headers=headers)
response = urllib.request.urlopen(request)
result_str = response.read().decode('utf-8')
result_dict = json.loads(result_str)
result = result_dict["translateResult"][0][0]["tgt"]
return result
class Application(object):
def __init__(self):
# 创建一个窗口
self.window = Tk()
# 窗口标题
self.window.title(u'武亮宇翻译词典')
# 设置窗口大小位置
self.window.geometry("280x350+400+150")
# 输入框
self.entry = Entry(self.window)
self.entry.place(x=10, y=10, width=200, height=25) # width=宽度, height=高度
# 查询按钮
self.button = Button(self.window, text=u'查询', command=self.function) # command执行命令的意思 执行这个函数
self.button.place(x=220, y=10, width=50, height=25)
# 翻译结果标题
self.label = Label(self.window, text=u'翻译结果:')
self.label.place(x=10, y=45)
# 翻译框
self.text = Text(self.window, background='#ccc') # 设置背景颜色
self.text.place(x=10, y=75, width=260, height=265)
def function(self):
# 从输入框中获取用户的值
content = self.entry.get()
# 把值发送给有道服务器进行翻译
youdao = YouDao()
result = youdao.crawl(content)
# 把结果放在翻译框里
self.text.delete(1.0, END) # 每次查询先删除一下
self.text.insert(END, result) # 插入文本最后的位置 导入END库
def run(self):
self.window.mainloop()
if __name__ == '__main__':
app = Application()
app.run()
# !/usr/bin/nev python
# -*-coding:utf8-*-
import tkinter
import tkinter.messagebox
class LoginPage(object):
def __init__(self):
#声明两个变量
self.win = tkinter.Tk() # 窗口
self.username = tkinter.StringVar()
self.password = tkinter.StringVar()
self.n=2
self.createForm()
def login(self):
if self.username.get()=='新星计划' and self.password.get()=='新星计划':
print('登录成功')
tkinter.messagebox.showinfo(title='登录信息',message='登录成功')
self.win.quit()
elif self.n==0:
print('你没有权限进入该系统')
self.win.quit()
else:
print('登录失败')
print('账号或密码错误,你还有%d次机会'%self.n)
tkinter.messagebox.showerror(title='登录信息',message='登录失败')
self.n-=1
def createForm(self):
self.win.title('登录界面')
self.win.geometry("280x200+400+150")
#创建标签
labelname = tkinter.Label(self.win,text='用户名:',justify=tkinter.RIGHT,width = 100)
labelname.place(x=35,y=50,width=80,height=20)
#创建文本框
entryname = tkinter.Entry(self.win, width=150, textvariable=self.username)
entryname.place(x=110, y=50, width=120, height=20)
#创建密码标签
labelpwd = tkinter.Label(self.win,text='密 码:', justify=tkinter.RIGHT,width=80)
labelpwd.place(x=35, y=80, width=80, height=20)
#创建密码的文本框
entrypwd = tkinter.Entry(self.win, width=150,textvariable=self.password)
entrypwd.place(x=110, y=80, width=120, height=20)
#创建button按钮
buttonOk = tkinter.Button(self.win,text='登录',command=self.login)
buttonOk.place(x=95,y=130,width=50,height=20)
#创建退出的按钮
buttonQuit = tkinter.Button(self.win,text='退出',command=self.win.quit)
buttonQuit.place(x=145,y=130,width=50,height=20)
self.win.mainloop()
if __name__ == '__main__':
lg = LoginPage()
一共两个py文件,赶快收藏啊,快去试试吧,能拥有自己的翻译词典!!!
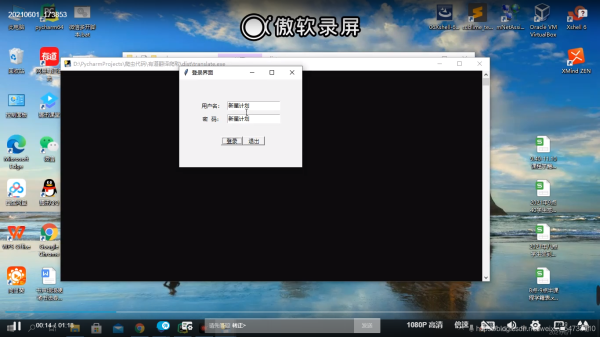
五、效果展示
先看一下软件效果,先登录
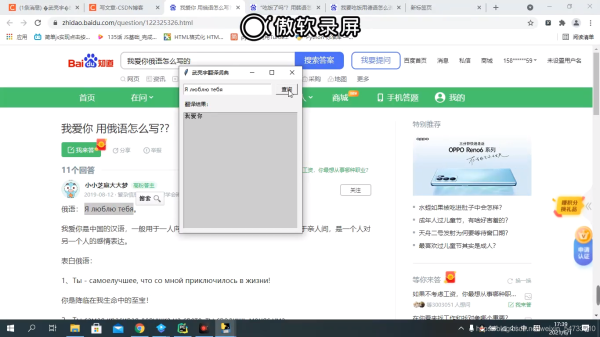
各种语言都可以转换
到此这篇关于告别网页搜索!教你用python实现一款属于自己的翻译词典软件的文章就介绍到这了,更多相关python翻译词典软件内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

利用python爬取有道词典的方法
前言 大家好 最近python爬虫有点火啊,啥python爬取马保国视频--我也来凑个热闹,今天我们来试着做个翻译软件--不是不是,说错了,今天我们来试着提交翻译内容并爬取翻译结果 主要内容 材料 1.Python 3.8.4 2.电脑一台(应该不至于有"穷苦人家"连一台电脑都没有吧) 3.Google浏览器(其他的也行,但我是用的Google) 写程序前准备 打开Google浏览器,找的有道词典的翻译网页(http://fanyi.youdao.com/) 打开后摁F12打开开发
-
python进阶教程之词典、字典、dict
基础教程介绍了基本概念,特别是对象和类. 进阶教程对基础教程的进一步拓展,说明Python的细节.希望在进阶教程之后,你对Python有一个更全面的认识. 之前我们说了,列表是Python里的一个类.一个特定的表,比如说nl = [1,3,8],就是这个类的一个对象.我们可以调用这个对象的一些方法,比如 nl.append(15). 我们要介绍一个新的类,词典 (dictionary).与列表相似,词典也可以储存多个元素.这种储存多个元素的对象称为容器(container). 基本概念 常见的创
-
Python使用tkinter制作在线翻译软件
tkinter的功能是如此强大,竟然还能做翻译软件.当然是在线的,我发现有一个quicktranslate模块,可以提供在线翻译功能,相当于提供了一个翻译的接口,利用它就可以制作在线翻译软件了.下面是代码,分享给大家. 注意要首先 pip install quicktranslate #-*- coding:utf-8 -*- import tkinter as tk #使用Tkinter前需要先导入 from tkinter import messagebox,ttk import datet
-
Python结合百度语音识别实现实时翻译软件的实现
一.所需库安装 pip install PyAudio pip install SpeechRecognition pip install baidu-aip pip install Wave pip install Wheel pip install Pyinstaller 二.百度官网申请服务 三.源代码分享 import pyaudio import wave from aip import AipSpeech import time # 用Pyaudio库录制音频 # out_file:
-
python翻译软件实现代码(使用google api完成)
复制代码 代码如下: # -*- coding: utf-8 -*- import httplibfrom urllib import urlencodeimport re def out(text): p = re.compile(r'","') m = p.split(text) print m[0][4:].decode('UTF-8').encode('GBK') if __name__=='__main__': while True: w
-
使用Python从有道词典网页获取单词翻译
从有道词典网页获取某单词的中文解释. import re import urllib word=raw_input('input a word\n') url='http://dict.youdao.com/search?q=%s'%word content=urllib.urlopen(url) pattern=re.compile("</h2.*?</ul>",re.DOTALL) result=pattern.search(content.read()).gro
-
python爬虫实现中英翻译词典
本文实例为大家分享了python爬虫实现中英翻译词典的具体代码,供大家参考,具体内容如下 通过根据某平台的翻译资源,提取出翻译信息,并展示出来,包括输入,翻译,输出三个过程,主要利用python语言实现(python3.6),抓取信息展示. import urllib.request import urllib.parse import json def en_zh(content): url = 'http://fanyi.baidu.com/v2transapi' head = {} hea
-
Python爬虫+Tkinter制作一个翻译软件的示例
今天咱们用Python爬虫和Tkinter界面来做一个翻译软件. 一.运行效果 软件实现功能:当我们输入英文或中文时,程序即可打印出来对应的译文,如图: 二.实现方法 1. 爬虫部分 实现一键翻译最简单的方式就是爬虫,我们只需将要翻译的内容传入,然后将翻译的结果爬取下来呈现给用户即可.在本文中,我们选择的网站是有道翻译. 下图这个界面,你在左边输入文字,那么浏览器会把你输入的信息传输给服务器.再在右侧返回对应翻译结果.这就是一个典型的Post操作. 由于之前我们的爬取都是采用的Get方式来获取数
-
告别网页搜索!教你用python实现一款属于自己的翻译词典软件
一.设计理念 1.先写一个登录的py文件,用python的tkinter库 2.再写一个py文件用于爬取有道翻译输出栏的内容 3.再利用python的tkinter库,完成软件运行的窗口 4.将窗口的返回值与爬取有道翻译的结果接口对一下 5.第二个py文件里import第一个py文件,两个文件相关联 二.代码解析 请求方式为post,要注意from data里的值,这里可以在网页上再输一个想要翻译的内容,观察from data里的值的变化,可以确定'salt'. 'sign'. 'lts'这三个
-
亲手教你用Python打造一款摸鱼倒计时界面
前言 前段时间在微博看到一段摸鱼人的倒计时模板,感觉还挺有趣的. 于是我用了一小时的时间写了个页面出来 摸鱼办地址 (当然是摸鱼的时间啦). 模板是这样的: 摸鱼办公室 你好,摸鱼人,工作再累,一定不要忘记摸鱼哦 ! 有事没事起身去茶水间去廊道去天台走走,别老在工位上坐着.多喝点水,钱是老板的,但命是自己的 ! 距离 周末 放假还有 2 天 距离 元旦 放假还有 3 天 距离 过年 放假还有 34 天 距离 清明节 放假还有 97 天 距离 劳动节 放假还有 123 天 距离 端午节 放假还有
-
教你用Python爬取英雄联盟皮肤原画
一.推理原理 1.先去<英雄联盟>官网找到英雄及皮肤图片的网址: http://lol.qq.com/data/info-heros.shtml 2.从上面网址可以看到所有英雄都在,按下F12查看源代码,发现英雄及皮肤图片并没有直接给出,而是隐藏在JS文件中.这时候需要点开Network,找到js窗口,刷新网页,就看到一个champion.js的选项,点击可以看到一个字典--里面就包含了所有英雄的名字(英文)以及对应的编号. 3.但是只有英雄的名字(英文)以及对应的编号并不能找到图片地址,于是
-
教你用python实现12306余票查询
python实现12306余票查询 我们说先在浏览器中打开开发者工具(F12),尝试一次余票的查询,通过开发者工具查看发出请求的包 余票查询界面 可以看到红框框中的URL就是我们向12306服务器发出的请求,那么具体是什么呢?我们来看看 [ https://kyfw.12306.cn/otn/leftTicket/queryZ?leftTicketDTO.train_date=2019-01-21&leftTicketDTO.from_station=CDW&leftTicketDTO.t
-
教你用python编写脚本实现自动签到
目录 1. 背景原因 2. 签到原理 3. 需要的环境selenium 4. 安装模拟的插件 5. 下载完成 6.正题 7. 完工! 8. 更新 1. 背景原因 最近才上班,要求每天打卡!我老是忘记,于是乎搞个脚本进行自动签到. 2. 签到原理 模拟用户进行自行输入,然后登录,然后签到,在研究过程中使用到了python的selenium包,本人在win10环境中进行测试使用,可以实现基本的自动打卡. 3. 需要的环境selenium pip install selenium 4. 安装模拟的插件
-
手把手教你使用Python绘制时间序列图
目录 01从Quandl检索数据集 02绘制收盘价与成交量的关系图 03绘制烛台图 导读:分析时间序列数据的一种简单而有效的方法就是将时间序列数据可视化在一个图表上,这样我们就可以从中推断出某些假设.本文将以股价数据集为例,指导你从Quandl下载股价数据集,并将这些数据绘制在价格和成交量图表上.还将教大家绘制烛台图,比起直线图表,这将给我们更多的信息. 01从Quandl检索数据集 Quandl简介 Quandl是一个为金融.经济和另类数据服务的平台,这些数据由各种数据发布商提供,包括联合国.
-
教你用 Python 发送告警通知到微信的操作过程
常见的告警方式有:邮件,电话,短信,微信. 短信和电话,通常是收费的(若你有不收费的,可以评论分享一下),而邮件又不是那么及时,因此最后我选择微信通知. 这里说的微信,是企业微信,而我之前用注册过个体户的执照,因此可以很轻松就可以注册自己的企业微信. # 1. 新建应用 登陆网页版企业微信 (https://work.weixin.qq.com/),点击 应用管理 -> 应用 -> 创建应用 上传应用的 logo,输入应用名称,再选择可见范围,成功创建一个告警应用 # 2. 获取Sec
-
手把手教你用python抢票回家过年(代码简单)
首先看看如何快速查看剩余火车票? 当你想查询一下火车票信息的时候,你还在上12306官网吗?或是打开你手机里的APP?下面让我们来用Python写一个命令行版的火车票查看器, 只要在命令行敲一行命令就能获得你想要的火车票信息!如果你刚掌握了Python基础,这将是个不错的小练习. 接口设计 一个应用写出来最终是要给人使用的,哪怕只是给你自己使用.所以,首先应该想想你希望怎么使用它?让我们先给这个小应用起个名字吧,既然及查询票务信息,那就叫它tickets好了.我们希望用户只要输入出发站,到达站以
-
10分钟教你用python动画演示深度优先算法搜寻逃出迷宫的路径
深度优先算法(DFS 算法)是什么? 寻找起始节点与目标节点之间路径的算法,常用于搜索逃出迷宫的路径.主要思想是,从入口开始,依次搜寻周围可能的节点坐标,但不会重复经过同一个节点,且不能通过障碍节点.如果走到某个节点发现无路可走,那么就会回退到上一个节点,重新选择其他路径.直到找到出口,或者退到起点再也无路可走,游戏结束.当然,深度优先算法,只要查找到一条行得通的路径,就会停止搜索:也就是说只要有路可走,深度优先算法就不会回退到上一步. 如果你依然在编程的世界里迷茫,可以加入我们的Python学
-
如何教少儿学习Python编程
如何给少儿讲编程? 1.首先给少儿讲编程一定要简单,通俗易懂. 因为少儿接触的事务比较少,你要用形象的少儿可以接受的方式让他们理解. 2.讲编程的速度一定要慢. 因为少儿的接受能力相对较弱一些,所以要适当调慢步骤. 3.讲编程一定要少儿亲手实践. 因为编程本来就是抽象的事物,如果不进行练习的话,少儿不能很好理解抽象的事物. 4.一定要多复习. 少儿的自觉力差些,课上一定要先复习再讲新的知识. 知识点扩展: 我们需要明确,给孩子上编程课的目的是什么 我想,对于中小学年龄段的孩子,编程课的主要目的应