在sql中对两列数据进行运算作为新的列操作
如下所示:
select a1,a2,a1+a2 a,a1*a2 b,a1*1.0/a2 c from bb_sb
把a表的a1,a2列相加作为新列a,把a1,a2相乘作为新列b,注意:
相除的时候得进行类型转换处理,否则结果为0.
select a.a1,b.b1,a.a1+b.b1 a from bb_sb a ,bb_cywzbrzb b
这是两个不同表之间的列进行运算。
补充知识:Sql语句实现不同记录同一属性列的差值计算
所使用的表的具体结构如下图所示

Table中主键是(plateNumber+currentTime)
要实现的查询是:
给定车牌号和查询的时间区间,查询给定的时间区间内所包含记录的currentTime的差值,并计算AverageSpeed和该差值的乘积,求这段时间内的最高速度(HighestSpeed),并按照type值得不同进行划分。–>(type值只有0和1两个值)
主要思路是,首先能够得出的是相同type类型下同一个车牌号(也即同一车辆)在给定的时间区间内的currentTime的差值,比如按照currentTime排序号,相邻两条记录currentTime的差值,得出这个以后,其余的都可以通过聚合函数得出。
我们以车牌号为京A111111为例,设计如下图所示的测试用例。
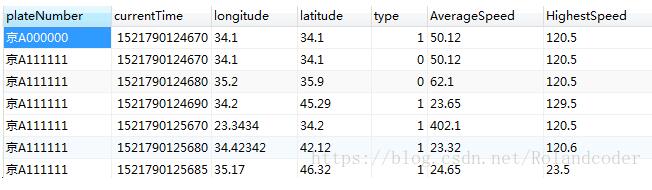
可以看到车牌号为京A111111的车辆总共有6条记录,其中type为0的有两条,type为1的有4条,
我们首先计算时间的差值,sql语句书写如下:
SELECT a.platenumber,
a.currenttime,
a.type,
a.averagespeed,
a.highestspeed,
currenttime - (SELECT currenttime
FROM carmultispeedinfo
WHERE platenumber = a.platenumber
AND type = a.type
AND currenttime < a.currenttime
ORDER BY currenttime DESC
LIMIT 1)AS timediff
FROM carmultispeedinfo a
通过navicat可以看到如下图所示的查询结果:
通过核查timediff的值是正确的,这样之后就可以在这个基础上添加内容了。
完整的sql语句如下:
SELECT Sum(aa.averagespeed * aa.timediff) AS milesdiff,
Max(aa.highestspeed) AS HighestSpeed,
Sum(aa.timediff) AS timediff,
aa.type
FROM (SELECT a.platenumber,
a.currenttime,
a.type,
a.averagespeed,
a.highestspeed,
currenttime - (SELECT currenttime
FROM carmultispeedinfo
WHERE platenumber = a.platenumber
AND type = a.type
AND currenttime < a.currenttime
ORDER BY currenttime DESC
LIMIT 1) AS timediff
FROM carmultispeedinfo a)aa
WHERE aa.platenumber = '京A111111'
AND aa.currenttime >= 1521790124670
AND aa.currenttime <= 1521790125685
GROUP BY aa.type
显示结果如下:
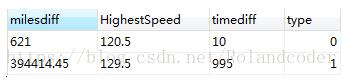
经过核对,是我们想要得出的结果。之后将sql对应替换到mybatis的mapper文件中就可以了。<记录一下,备忘>将来有更深入的理解之后会继续更新,谢谢大家,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
MySQL根据某一个或者多个字段查找重复数据的sql语句
sql 查出一张表中重复的所有记录数据 1.表中有id和name 两个字段,查询出name重复的所有数据 select * from xi a where (a.username) in (select username from xi group by username having count(*) > 1) 2.查询出所有数据进行分组之后,和重复数据的重复次数的查询数据,先列下: select count(username) as '重复次数',username from xi group
-
MySQL计算两个日期相差的天数、月数、年数
MySQL自带的日期函数TIMESTAMPDIFF计算两个日期相差的秒数.分钟数.小时数.天数.周数.季度数.月数.年数,当前日期增加或者减少一天.一周等等. SELECT TIMESTAMPDIFF(类型,开始时间,结束时间) 相差的秒数: SELECT TIMESTAMPDIFF(SECOND,'1993-03-23 00:00:00',DATE_FORMAT(NOW(), '%Y-%m-%d %H:%i:%S')) 相差的分钟数: SELECT TIMESTAMPDIFF(MINUTE,'
-
mysql批量更新多条记录的同一个字段为不同值的方法
首先mysql更新数据的某个字段,一般这样写: UPDATE mytable SET myfield = 'value' WHERE other_field = 'other_value'; 也可以这样用in指定要更新的记录: UPDATE mytable SET myfield = 'value' WHERE other_field in ('other_values'); 这里注意 'other_values' 是一个逗号(,)分隔的字符串,如:1,2,3 如果更新多条数据而且每条记录要更新
-
在sql中对两列数据进行运算作为新的列操作
如下所示: select a1,a2,a1+a2 a,a1*a2 b,a1*1.0/a2 c from bb_sb 把a表的a1,a2列相加作为新列a,把a1,a2相乘作为新列b,注意: 相除的时候得进行类型转换处理,否则结果为0. select a.a1,b.b1,a.a1+b.b1 a from bb_sb a ,bb_cywzbrzb b 这是两个不同表之间的列进行运算. 补充知识:Sql语句实现不同记录同一属性列的差值计算 所使用的表的具体结构如下图所示 Table中主键是(plateN
-
Python 使用xlwt模块将多行多列数据循环写入excel文档的操作
我就废话不多说了,大家还是直接看代码吧~ #!/usr/bin/python # -*- coding: utf-8 -*- import xlwt import re def host_regex(dataline): host_regex = r"<host>(.*?)</host>" host = re.findall(host_regex, dataline) if host: return host[0] def ip_regex(dataline):
-
python读取excel指定列数据并写入到新的excel方法
如下所示: #encoding=utf-8 import xlrd from xlwt import * #------------------读数据--------------------------------- fileName="C:\\Users\\st\\Desktop\\test\\20170221131701.xlsx" bk=xlrd.open_workbook(fileName) shxrange=range(bk.nsheets) try: sh=bk.sheet
-

python 如何对Series中的每一个数据做运算
问题描述 最近- 发现对series里的元素操作挺复杂的,用for loop + Series.iloc[i]会发生卡死的状况,那么,lambda是解决办法: error 1 ratings['timestamp'] = ratings['timestamp'].apply(ratings['timestamp'].iloc[i].strftime("%Y-%m-%d %H:%M:%S", ts) for i in range(len(ratings))) TypeError: 'ge
-
R语言实现用cbind合并两列数据
我有两个数据文件,分别只有一列,这两列数据行数一行,我想把这两列合并到一个数据文件中,方便使用. 我的两个数据文件分别是1.txt,2.txt,保存后的文件名是3.txt. // 代码如下 gow1<-read.table("1.txt",header = FALSE) gow2<-read.table("2.txt",header = FALSE) View(gow1) View(gow2) gow<-cbind(gow1,gow2) View(
-
详解Pandas如何高效对比处理DataFrame的两列数据
目录 楔子 combine_first combine update 楔子 我们在用 pandas 处理数据的时候,经常会遇到用其中一列数据替换另一列数据的场景.比如 A 列和 B 列,对 A 列中不为空的数据不作处理,对 A 列中为空的数据使用 B 列对应索引的数据进行替换.这一类的需求估计很多人都遇到,当然还有其它更复杂的. 解决这类需求的办法有很多,这里我们来推荐几个. combine_first 这个方法是专门用来针对空值处理的,我们来看一下用法. import pandas as pd
-
mysql 实现互换表中两列数据方法简单实例
由于最近项目,有这样一个需求,是把数据库中的两列数据互换,经过好久才搞定,这里写个简单实例,做过记录. 1.创建表及记录用于测试 CREATE TABLE `product` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '产品id', `name` varchar(50) NOT NULL COMMENT '产品名称', `original_price` decimal(5,2) unsigned NOT NULL COMMEN
-
可视化Swing中JTable控件绑定SQL数据源的两种方法深入解析
在 MyEclipse 的可视化 Swing 中,有 JTable 控件.JTable 用来显示和编辑常规二维单元表.那么,如何将 数据库SQL中的数据绑定至JTable中呢?在这里,提供两种方法.JTable的构造方法通过查阅Java的API,可以可以得到JTable的两个重要的构造方法:JTable(Object[][] rowData, Object[] columnNames)构造一个 JTable 来显示二维数组 rowData 中的值,其列名称为 columnNames.JTable
-
在SQL中对同一个字段不同值,进行数据统计操作
应用场景: 需要根据印章的不同状态,统计不同状态下印章数量. 刚开始百度,确实写搜到了不同的答案,但只能怪自己对sql语法解读不够,还是没写出来,导致写出了下面错误的写法. select b.corporateOrgName, b.corporateOrgGuid companyId, count(case when bc.ftype not in(1,2) then 1 else 0 end ) total, count(case when bc.ftype in(3,4,5) then 1
-
sql语句将数据库一条数据通过分隔符切割成多列方法实例
目录 需求场景 应对措施 效果展示 具体代码 总结 sql语句,将数据库一条数据通过分隔符切割成多列 需求场景应对措施效果展示具体代码 需求场景 在实际场景之中,我们有时候会遇到一种情况,就是数据库中某一字段存了很长的一段字符串,里面用了分隔符进行分割,但是很不直观,你想查一下数据库把这个字段下的数据,按分隔符切割出来,并划分到下面几列上面,但又苦于只能写sql.这种情况下应该怎么办呢. 应对措施 首先这种情况下,sql是可以完全满足需求的.sql在代码中不仅可以用curd,更可以对数据的查询做