解决Tomcat10 Catalina log乱码问题
运行环境,Idea2020版本,Tomcat10,运行的时候Tomcat CatalinaLog控制台中出现乱码

需要修改Tomcat中的配置文件D:\apache-tomcat\apache-tomcat-10.0.0-M9\conf\logging.properties
找到1catalina.org.apache.juli.AsyncFileHandler.encoding = utf-8
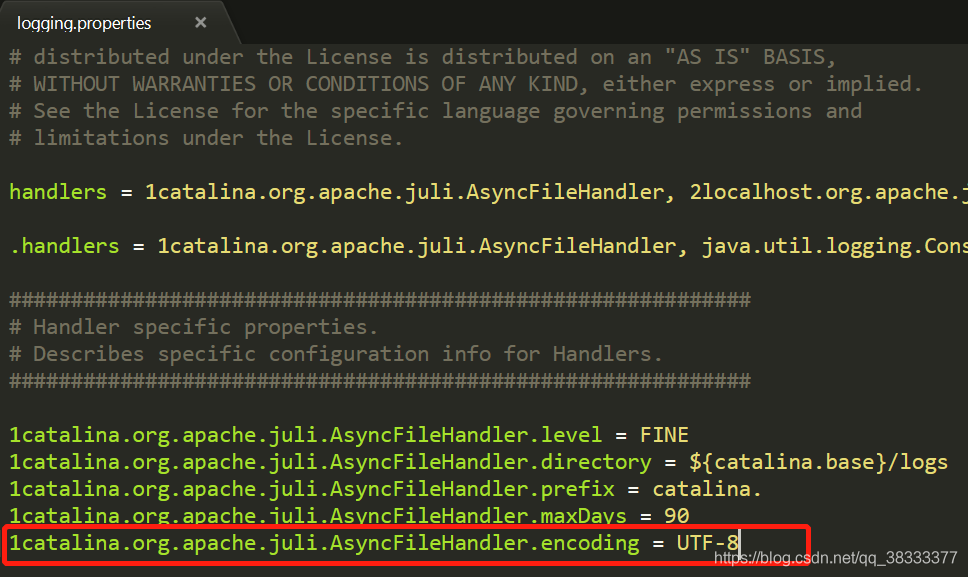
修改为
1catalina.org.apache.juli.AsyncFileHandler.encoding = GBK

修改完重新启动Tomcat,运行结果就好了。
到此这篇关于解决Tomcat10 Catalina log乱码问题的文章就介绍到这了,更多相关Tomcat Catalina log乱码内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Tomcat中的catalina.bat原理详细解析
前言 本文主要给大家详细解析了关于Tomcat中catalina.bat原理的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧. tomcat 的真正启动是在 catalina.bat 设置并启动的.startup.bat 只是找到catalina.bat 然后执行catalina.bat 来启动tomat的.下面我们来分析下catalina.bat 验证CATALINA_HOME 环境变量 验证CATALINA_HOME 设置是否正确,如果不正确,重新设置CATALIN
-
Tomcat 日志切割(logrotate)详细介绍
Tomcat 日志切割 logrotate是个强大的系统软件,它对日志文件有着一套完整的操作模式,譬如:转储.邮件和压缩等,并且默认logrotate加到cron(/etc/cron.daily/logrotate)作为每日任务执行.自动有了logrotate,我想不用再自己写日志切割脚本. 如下对Tomcat日志catalina.out日志切割 # ls -lh /usr/local/tomcat/logs/catalina.out -rw-r--r-- 1 www www 14M Aug 2
-
详解关于tomcat切割catalina.out日志的三种方式
1.log4j进行日志切分 1)准备三个包:log4j-1.2.17.jar tomcat-juli.jar tomcat-juli-adapters.jar 放到tomcat的lib目录或者是工程的WEB_INF/lib下, 2)在lib目录下新建log4j.properties,加入以下内容 log4j.rootLogger = INFO, CATALINA # Define all the appenders log4j.appender.CATALINA = org.
-
解析Tomcat的启动脚本--catalina.bat
概述 Tomcat 的三个最重要的启动脚本: startup.bat catalina.bat setclasspath.bat 上一篇咱们分析了 startup.bat 脚本 这一篇咱们来分析 catalina.bat 脚本. 至于 setclasspath.bat 这个脚本, 相信看完这一篇, 就可以自己看懂这个脚本了. 可以点击下载 [ setclasspath.bat 脚本 ]查看附注释的 setclasspath.bat 脚本 catalina.bat 这个脚本的代码有点多, 就单独弄
-
Tomcat使用Log4j输出catalina.out日志
Tomcat默认的日志是用java.util.logging,有几点不足,文件catalian.out不能像log4j一样按天生成,将越来越大.日志格式和项目中用log4j打出来的不一致,不利于解析. 从tomcat官网(https://tomcat.apache.org/tomcat-7.0-doc/logging.html)上找了下,修改一些配置.替换扩展包即可使用log4j输出catalian.out. 在$CATALINA_BASE/lib下创建log4j.properties文件 lo
-
解决Tomcat10 Catalina log乱码问题
运行环境,Idea2020版本,Tomcat10,运行的时候Tomcat CatalinaLog控制台中出现乱码 需要修改Tomcat中的配置文件D:\apache-tomcat\apache-tomcat-10.0.0-M9\conf\logging.properties 找到1catalina.org.apache.juli.AsyncFileHandler.encoding = utf-8 修改为 1catalina.org.apache.juli.AsyncFileHandler.enc
-
永久解决idea git log乱码的问题
问题描述: 在windows系统下,idea中,操作terminal控制台,使用git log查看日志时,出现如下乱码 为什么参考网上很多的git config *** 命令修改都不成功,还是乱码? 原因: 1.idea的terminal实质上是操作的本机cmd.exe程序,也就是windows的命令行 2.而网上大部分的教程都是教你修改git bash上的配置信息 3.所以很多网上的方法都没有用,因为默认情况下idea使用的是cmd.exe,不是git.exe(当然我们也可以直接把idea的控
-
彻底解决Spring MVC中文乱码问题的方案
乱码是让人很头疼的一件事,本文介绍了彻底解决Spring MVC中文乱码问题的方案,具体如下: 1:表单提交controller获得中文参数后乱码解决方案 注意: jsp页面编码设置为UTF-8 form表单提交方式为必须为post,get方式下面spring编码过滤器不起效果 <%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%> <form
-
解决Mysql5.7中文乱码的问题
在使用mysql5.7时,会发现通过web端向数据库中写入中文后会出现乱码,但是在数据库中直接操作SQL语句插入数据后中文就显示正常,这个问题怎么解决呢?此处不对MySQL的数据编码过程和原理进行讲解,如果有兴趣的同学可以自己百度. 下面我们就直接使用如下操作解决: 一.打开mysql控制台,输入命令show variables like 'character%'; 显示如下: +--------------------------+-------------------------------
-
完美解决gvim的菜单乱码问题
gvim的菜单乱码问题的解决方法: (乱码是由于系统内码不兼容导致,系统内码包括gb2312 gb18030 utf-8 utf-16[unicode]等) 生成文件 ~/.gvimrc 并添加如下语句: set encoding=chinese set langmenu=zh_CN.GBK set imcmdline set guifont="Serif 14" source $VIMRUNTIME/delmenu.vim source $VIMRUNTIME/menu.vim 保存
-
iOS中解决Xcode9的Log日志无法输出中文的问题小结
问题描述 Xcode的Log日志输出中文的问题,一般都是重写NSArray,NSDictionary的- (NSString *)descriptionWithLocale:(id)locale;方法进行处理,最近升级到Xcode9会后发现原来的处理逻辑也无法满足输出中文的需求,后台返回的状态描述涉及到中文的都变成了Unicode编码,其实这是重写的方法失效的问题,因为Xcode默认输出NSArray,NSDictionary的中文都是Unicode编码 正确的解决方案如下, 创建NSArray
-
解决Pandas to_json()中文乱码,转化为json数组的问题
问题出现与解决 Pandas进行数据处理之后,假如想将其转化为json,会出现一个bug,就是中文文字是以乱码存储的,也就是\uXXXXXX的形式,翻了翻官网文档,查了源码的参数,(多谢网友提醒)需要设置js001 = df1.to_json(force_ascii=False),即可显示中文编码 以下是原文的额外内容,DataFrame 转化为json数组 于是决定自己写一个.首先用demojson的类库尝试了一下,不行,依旧编码问题.之后考虑python 原生的 json 应该有编码转换功能
-
解决PyCharm控制台输出乱码的问题
最近公司新换了台电脑,各种开发环境要重新配置,想想Paas确实还是有市场的,如果有了,这种情况可以省下不少气力.吐槽一下,言归正传 装完python后,继续装好PyCharm.把之前的程序导进来试运行下安装是否成功,发现控制台里的显示结果有乱码.乱码部分是一个目录的输出,这个目录里含有中文路径 网上搜了下,有人说把下面图中的两个Encoding设置为UTF-8会解决这个问题.这么配置了下,发现不起作用,即使我代码里本身已经用了UTF-8编码了. 又过了两天,期间有时间就换着关键词百度,终于发现了
-
详解Python解决抓取内容乱码问题(decode和encode解码)
一.乱码问题描述 经常在爬虫或者一些操作的时候,经常会出现中文乱码等问题,如下 原因是源网页编码和爬取下来后的编码格式不一致 二.利用encode与decode解决乱码问题 字符串在Python内部的表示是unicode编码,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码. decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode('gb2312
-
解决python Markdown模块乱码的问题
有个需求需要把markdown转成html模块,查询了一下刚好有这个模块 安装 pip install amrkdown 安装完成直接转换并保存为html时,发现出现中文乱码的情况 用编辑器打开发现是缺少utf8编码 所以只需要在头增加一行<meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> 即可 查询Markdown包安装地址 pip install markdown