Python实现JS解密并爬取某音漫客网站
首先打开网站
https://www.zymk.cn/1/37988.html
打开开发者工具
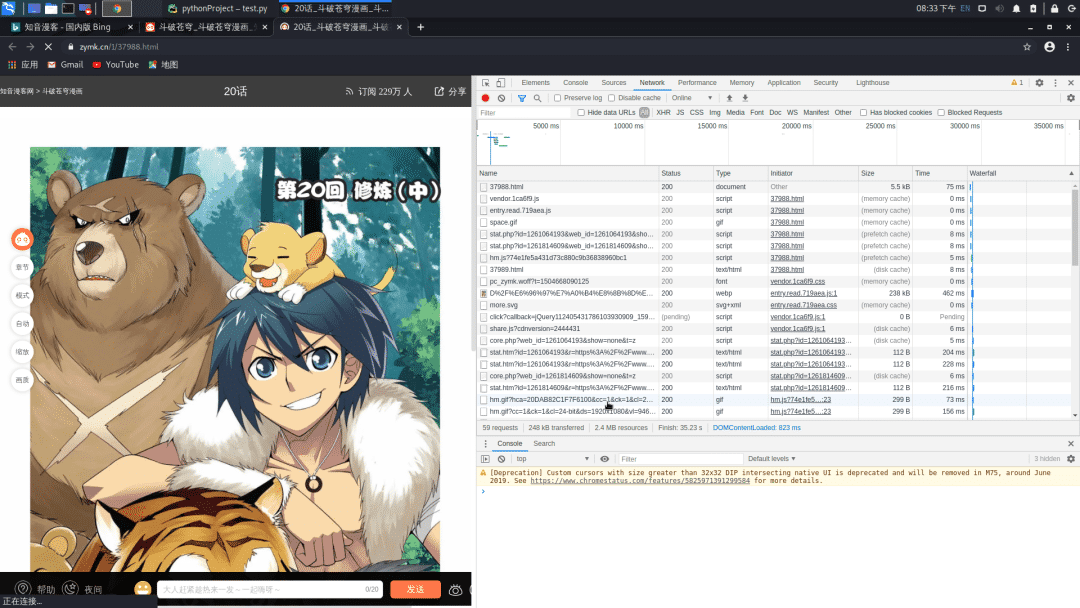
选择XHR标签页,没有找到什么
再查看一下这些图片的URL值
http://mhpic.xiaomingtaiji.net/comic/D%2F%E6%96%97%E7%A0%B4%E8%8B%8D%E7%A9%B9%E6%8B%86%E5%88%86%E7%89%88%2F20%E8%AF%9D%2F1.jpg-zymk.middle.webp
尝试搜索图片元素


发现有一个js文件,打开搜索
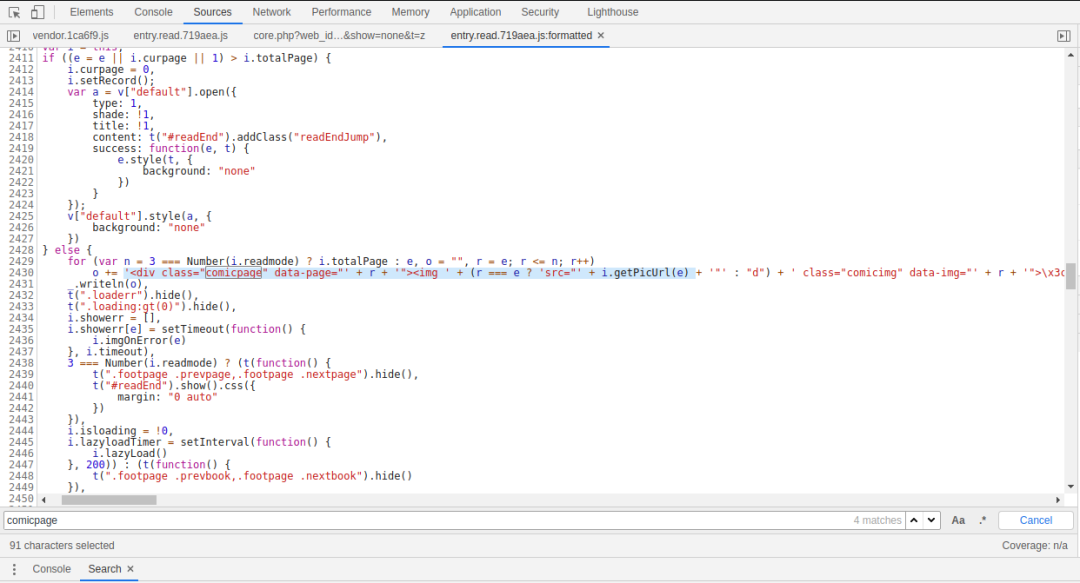
发现这里有一个疑点,这不是html里面的字段吗,那么 “i.getPicUrl(e)” 不就是那个图片的URL的值了吗
在这里下一个断点,走你
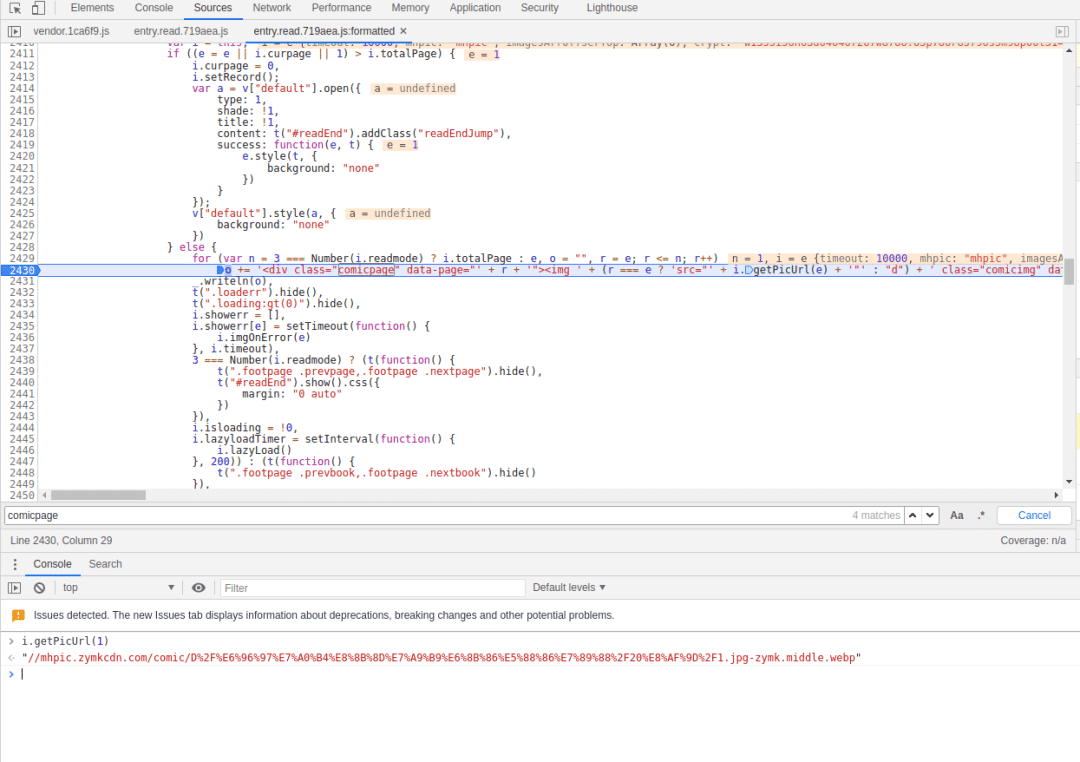
果然,这个就那个图片URL生成的切入点,现在就是看调用栈,找到这个函数的起点,点击右侧的 ”e.init“,这里有一个setInitData函数,从名字来看,应该就是设置初始数据的地方,在这里下一个断点,进去看看
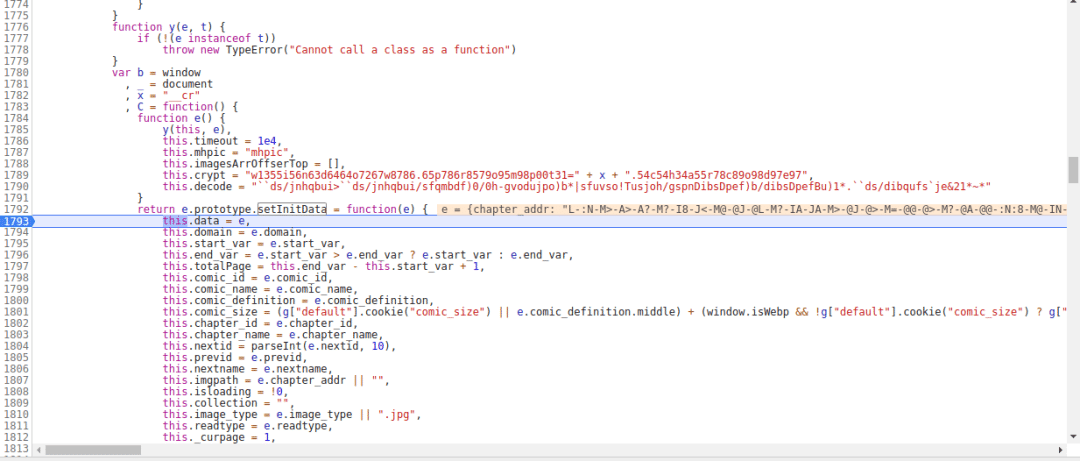
这里有一个this.imgpath,这个应该就是图片的URL值了,点击F10,再单步调式,来到了charcode函数

进去看看,这里应该就是加密函数了

这里一步步调式,不要着急,来到了这里

继续单步调式,在第二次打开这么VM文件的时候,”__cr.imgpath“这个看起来很熟悉呀
Plain Text
"L-:N-M>-A>-A?-M?-I8-J<-M@-@J-@L-M?-IA-JA-M>-@J-@>-M=-@@-@>-M?-@A-@@-:N:8-M@-IN-AL-:N"
打开页面源代码,就在这里啦,不仅仅有图片的URL加密值,还有其他数据,这些都是在后面图片URL拼接需要使用到的
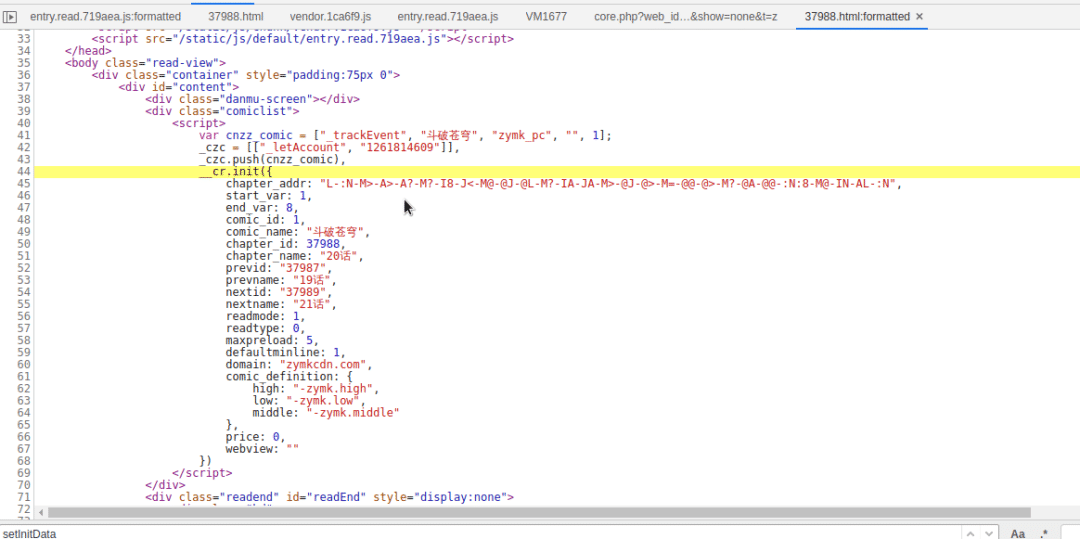
现在我们再重新看看那个加密函数,它无非就是遍历那个加密值的每个字符,获取其Unicode值,再与__cr.chapter_id进行相关运算,然后再得到的Unicode数值返回字符
现在我们可以用python仿写这个算法

接下就是平常get请求获取必要的数据了,通过正则获取元素,拼接,以下是源码

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
vue项目中 使用 pako.js 解密 gzip加密字符串的代码详解
前言 今天跟后台对接一个接口,接受到一个加密的值,说是通过gzip加密过的,然后就蒙蔽了, 赶紧上百度找了一下资料,通过一篇文章(原文在底部)发现有个js库可以解密,就下载轻松解密了 实现代码 poko.js可至Github下载 https://github.com/nodeca/pako or npm install pako import pako from 'pako' // 一个是加密:window.btoa(),一个是解密:window.atob() function decode(e
-
Js通过AES加密后PHP用Openssl解密的方法
前言 最近遇到的几个网站在提交密码时提交的已经是密文,也就是说在网络上传输的密码是密文,这样提升了密码在网络传输中的安全性. 后端语言加解密已经有很成熟的方案了,前端的话Google之前出过一个crypto-js,为浏览器的js提供了加解密方案.今天一起来了解一下基于AES的前后端加解密流程. Javascript 1.安装npm包 npm install crypto-js 2.加密代码 const CryptoJS = require("crypto-js"); const key
-

RSA实现JS前端加密与PHP后端解密功能示例
本文实例讲述了RSA实现JS前端加密与PHP后端解密功能.分享给大家供大家参考,具体如下: web前端,用户注册与登录,不能直接以明文形式提交用户密码,容易被截获,这时就引入RSA. 前端加密 需引入4个JS扩展文件,jsbn.js.prng4.js.rng.js和rsa.js. <html> <head> <title>RSA Login Test</title> <meta charset="utf-8"> <scr
-
JS eval代码快速解密实例解析
有一段js代码内容如下: eval(function(E,I,A,D,J,K,L,H){function C(A)后面内容省略... 解密可以采用如下方法: 方法一: 打开谷歌浏览器,按F12,在Console窗口中把eval代码复制粘贴进去,回车运行,即可就到源码. 方法二: 新建一个html文件,把上面eval替换成document.write输出即可. 备注,前后加xmp标签的作用是完整的输出html标签,并且不做任何转义. <html> <head> <title&g
-
js将URL网址转为16进制加密与解密函数
十六进制(Hexadecimal)是计算机中数据的一种表示方法.同日常生活中的表示法不一样,它由0-9,A-F组成,字母不区分大小写.与10进制的对应关系是:0-9对应0-9:A-F对应10-15:N进制的数可以用0~(N-1)的数表示,超过9的用字母A-F.不同电脑系统.编程语言对于16进制数值有不同的表示方式:如增加0x前缀. 这里推荐一个在线转换的小工具方便大家使用:http://tools.jb51.net/transcoding/decode_encode_tool php函数: bi
-
CryptoJS中AES实现前后端通用加解密技术
在项目中如果要对前后端传输的数据双向加密, 比如避免使用明文传输用户名,密码等数据. 就需要对前后端数据用同种方法进行加密,方便解密.这里介绍使用 CryptoJS 实现 AES 加解密. 首先需要下载前台使用 CryptoJS 实现 AES 加解密的,所以要先下载组件,下载 CryptoJS-v3.1.2 版本之后,文件中包含components 和 rollups 两个文件夹,components 文件夹下是单个组件,rollups 文件夹下是汇总,引用 rollups 下的 aes.js
-
NodeJS加密解密及node-rsa加密解密用法详解
要用nodejs开发接口,实现远程调用,如果裸奔太危险了,就在网上找了一下nodejs的加密,感觉node-rsa挺不错的,下面来总结一下简单的rsa加密解密用法 初始化环境 新建一个文件夹 node-rsa-demo , 终端进入,运行下面命令初始化 cd node-rsa-demo npm init # 一路回车即可 npm install --save node-rsa 生成公钥私钥 在 node-rsa-demo 下新建一个文件 index.js 写上如下代码 var NodeRSA =
-
JavaScript实现的前端AES加密解密功能【基于CryptoJS】
本文实例讲述了JavaScript实现的前端AES加密解密功能.分享给大家供大家参考,具体如下: js前端AES加密 最近由于项目需求做了一次MITM,突然即使发现使用HTTPS,也不能保证数据传输过程中的安全性. 通过中间人攻击,可以直接获取到Http协议的所有内容. 于是开始尝试做一些简单的加密,在一定程度上保证安全性. 本次采用AES加密数据,所以客户端和服务端使用的相同秘钥.(仅作为演示,正式环境推荐使用RSA) 首先准备一份明文密码和加密使用的KEY var source = "ABC
-
VueJs里利用CryptoJs实现加密及解密的方法示例
第一步 安装 安装crypto-js 第二步 创建 在js文件目录下创建一个js文件secret /** * 对页面上输入的密码进行加密传输给后台进行验证,对返回的数据进行解密,在页面展示 */ let CryptoJS = require('crypto-js'); // 引入AES源码js export default { /* * 对密码进行加密,传输给后台进行验证 * @param {String} word 需要加密的密码 * @param {String} keyStr 对密码加密的
-
Python实现JS解密并爬取某音漫客网站
首先打开网站 https://www.zymk.cn/1/37988.html 打开开发者工具 选择XHR标签页,没有找到什么 再查看一下这些图片的URL值 http://mhpic.xiaomingtaiji.net/comic/D%2F%E6%96%97%E7%A0%B4%E8%8B%8D%E7%A9%B9%E6%8B%86%E5%88%86%E7%89%88%2F20%E8%AF%9D%2F1.jpg-zymk.middle.webp 尝试搜索图片元素 发现有一个js文件,打开搜索 发现这
-
使用python爬取抖音视频列表信息
如果看到特别感兴趣的抖音vlogger的视频,想全部dump下来,如何操作呢?下面介绍介绍如何使用python导出特定用户所有视频信息 抓包分析 Chrome Deveploer Tools Chrome 浏览器开发者工具 在抖音APP端,复制vlogger主页地址, 比如: http://v.douyin.com/kGcU4y/ , 在PC端用chrome浏览器打卡,并模拟手机,这里选择iPhone, 然后把复制的主页地址,放到浏览器进行访问,页面跳转到 https://www.iesdouy
-
Python爬虫实例——scrapy框架爬取拉勾网招聘信息
本文实例为爬取拉勾网上的python相关的职位信息, 这些信息在职位详情页上, 如职位名, 薪资, 公司名等等. 分析思路 分析查询结果页 在拉勾网搜索框中搜索'python'关键字, 在浏览器地址栏可以看到搜索结果页的url为: 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=', 尝试将?后的参数删除, 发现访问结果相同. 打开Chrome网页调试工具(F12), 分析每条搜索结果
-
python爬取抖音视频的实例分析
现在抖音的火爆程度,大家都是有目共睹的吧,之前小编在网络上发现好玩的事情,就是去爬取一些网站,因此,也考虑能否进行抖音上的破案去,在实际操作以后,真的实现出来了,利用自动化工具,就可以轻松实现了,后有小伙伴提出把appium去掉瘦身之后也是可以实现的,那么看下详细操作内容吧. 1.mitmproxy/mitmdump抓包 import requests path = 'D:/video/' num = 1788 def response(flow): global num target_urls
-
python爬虫系列Selenium定向爬取虎扑篮球图片详解
前言: 作为一名从小就看篮球的球迷,会经常逛虎扑篮球及湿乎乎等论坛,在论坛里面会存在很多精美图片,包括NBA球队.CBA明星.花边新闻.球鞋美女等等,如果一张张右键另存为的话真是手都点疼了.作为程序员还是写个程序来进行吧! 所以我通过Python+Selenium+正则表达式+urllib2进行海量图片爬取. 运行效果: http://photo.hupu.com/nba/tag/马刺 http://photo.hupu.com/nba/tag/陈露 源代码: # -*- coding: utf
-
Python多线程爬虫实战_爬取糗事百科段子的实例
多线程爬虫:即程序中的某些程序段并行执行, 合理地设置多线程,可以让爬虫效率更高 糗事百科段子普通爬虫和多线程爬虫 分析该网址链接得出: https://www.qiushibaike.com/8hr/page/页码/ 多线程爬虫也就和JAVA的多线程差不多,直接上代码 ''' #此处代码为普通爬虫 import urllib.request import urllib.error import re headers = ("User-Agent","Mozilla/5.0
-
使用python爬虫实现网络股票信息爬取的demo
实例如下所示: import requests from bs4 import BeautifulSoup import traceback import re def getHTMLText(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def getStockList(lst, stockUR
-
基于Python的Post请求数据爬取的方法详解
为什么做这个 和同学聊天,他想爬取一个网站的post请求 观察 该网站的post请求参数有两种类型:(1)参数体放在了query中,即url拼接参数(2)body中要加入一个空的json对象,关于为什么要加入空的json对象,猜测原因为反爬虫.既有query参数又有空对象体的body参数是一件脑洞很大的事情. 一开始先在apizza网站 上了做了相关实验才发现上面这个规律的,并发现该网站的请求参数要为raw形式,要是直接写代码找规律不是一件容易的事情. 源码 import requests im
-
Python爬虫实现使用beautifulSoup4爬取名言网功能案例
本文实例讲述了Python爬虫实现使用beautifulSoup4爬取名言网功能.分享给大家供大家参考,具体如下: 爬取名言网top10标签对应的名言,并存储到mysql中,字段(名言,作者,标签) #! /usr/bin/python3 # -*- coding:utf-8 -*- from urllib.request import urlopen as open from bs4 import BeautifulSoup import re import pymysql def find_
-
Python进阶之使用selenium爬取淘宝商品信息功能示例
本文实例讲述了Python进阶之使用selenium爬取淘宝商品信息功能.分享给大家供大家参考,具体如下: # encoding=utf-8 __author__ = 'Jonny' __location__ = '西安' __date__ = '2018-05-14' ''' 需要的基本开发库文件: requests,pymongo,pyquery,selenium 开发流程: 搜索关键字:利用selenium驱动浏览器搜索关键字,得到查询后的商品列表 分析页码并翻页:得到商品页码数,模拟翻页