pandas基础 Series与Dataframe与numpy对二进制文件输入输出
目录
- Series
- Python numpy对二进制文件输入输出
Series
series是一种一维的数组型对象,它包含了一个值序列和一个数据标签
import pandas as pd import numpy as np
创建第一个series:
s1=pd.Series([4,7,-5,3])#创建一个series,索引为默认值 print(s1)

通过简单的一个传入数组,就可以形成一个一维的数据表格
获取序列的值和标签序列,应该如何去做?

我们在想这样一个问题,这个序列标签是默认的0....,如果我们需要自己去定义那应该怎么办?

然后我们就可以通过索引去获取相应的值了
series可以看做一个定长的字典,有序的字典,这个和Python内部的不一样,因为它是无序的
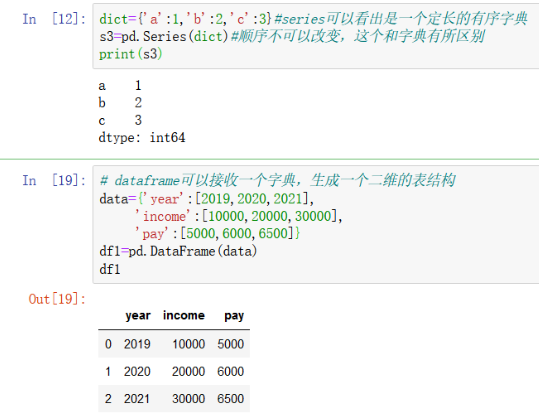
有时候我们已经有了一个字典,但是里面元素过于多,我只想要我要的数据,这个时候可以使用这个属性:pd.Series(data,index=indexs),datahi一个字典类型的数据集,indexs是我们需要的数据的键,我们可以把它组成一个列表然后,既可以提取又可以展示

如何自己确定行和列的标签:
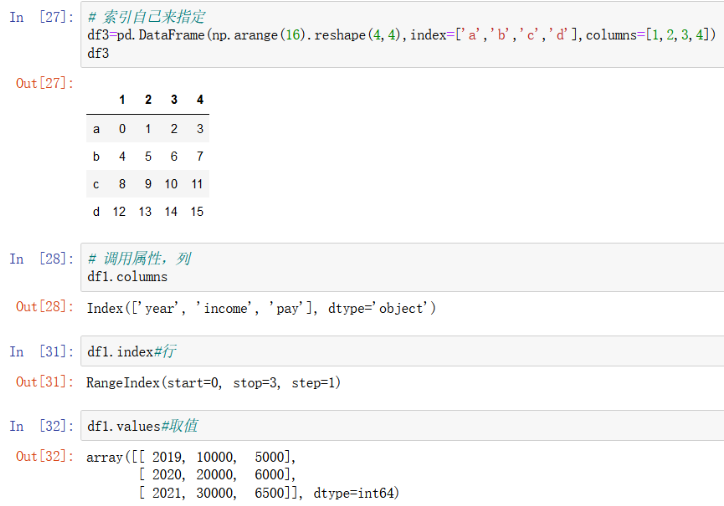
通过这个描述性的操作,我们可以对数据有一个大体的概念认识


排序操作:

上述的数据是随机生成的,对于基本的索引和切片与Python其实差不多的,我们需要掌握的是基础的语法和知识点,方便我们在后续操作的过程之中可以快速的查阅知识点
Python numpy对二进制文件输入输出
numpy可以在硬盘中将数据以文本或二进制文件的形式进行存入硬盘或由硬盘载入。在本篇文章里面我们需要简单的讨论内建二进制格式,而对于其他表格pandas才是“天选之子”
np.save和np.load是高效存取硬盘数据的两大工具函数。数组在默认情况下是以压缩的格式进行储存的,后缀名是.npy

上面就介绍了数据的存储和数据的加载方法,np.savez:用于未压缩文件中保存多个数据
到此这篇关于pandas基础 Series与Dataframe与numpy对二进制文件输入输出的文章就介绍到这了,更多相关pandas Series内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
NumPy.npy与pandas DataFrame的实例讲解
用CSV格式来保存文件是个不错的主意,因为大部分程序设计语言和应用程序都能处理这种格式,所以交流起来非常方便.然而这种格式的存储效率不是很高,原因是CSV及其他纯文本格式中含有大量空白符;而后来发明的一些文件格式,如zip.bzip和gzip等,压缩率则有了显著提升. 首先导入模块: In [1]: import numpy as np In [2]: import pandas as pd In [3]: from tempfile import NamedTemporaryFile In [
-

详解将Pandas中的DataFrame类型转换成Numpy中array类型的三种方法
在用pandas包和numpy包对数据进行分析和计算时,经常用到DataFrame和array类型的数据.在对DataFrame类型的数据进行处理时,需要将其转换成array类型,是以下列出了三种转换方法. 首先导入numpy模块.pandas模块.创建一个DataFrame类型数据df import numpy as np import pandas as pd df=pd.DataFrame({'A':[1,2,3],'B':[4,5,6],'C':[7,8,9]}) 1.使用DataFra
-
教你漂亮打印Pandas DataFrames和Series
一.前言 当我们必须处理可能有多个列和行的大型DataFrames时,能够以可读格式显示数据是很重要的.这在调试代码时非常有用. 默认情况下,当打印出DataFrame且具有相当多的列时,仅列的子集显示到标准输出. 显示的列甚至可以多行打印出来. 二.问题 假设我们有以下DataFrame: import pandas as pd import numpy as np df = pd.DataFrame( np.random.randint(0, 100, size=(100, 25)), co
-
pandas如何使用列表和字典创建 Series
目录 01 使用列表创建 Series 02 使用 name 参数创建 Series 03 使用简写的列表创建 Series 04 使用字典创建 Series 05 如何使用 Numpy 函数创建 Series 06 如何获取 Series 的索引和值 07 如何在创建 Series 时指定索引 08 如何获取 Series 的大小和形状 09 如何获取 Series 开始或末尾几行数据 10 使用切片获取 Series 子集 前言: Pandas 纳入了大量库和一些标准的数据模型,提供了高效地
-
使用python计算方差方式——pandas.series.std()
目录 如何计算方差 Python计算方差.标准差 方差.标准差 1.方差 2.标准差 如何计算方差 简单展示一下pandas里怎么计算方差: 官方文档: def def_std(df): for ix,row in df.iterrows(): std = row.std() df.loc[ix,"std"] = std return df Python计算方差.标准差 方差.标准差 1.离散程度的测度值之一 2.最常用的测度值 3.反应了数据的分布 4.反应了
-
Pandas把dataframe或series转换成list的方法
把dataframe转换为list 输入多维dataframe: df = pd.DataFrame({'a':[1,3,5,7,4,5,6,4,7,8,9], 'b':[3,5,6,2,4,6,7,8,7,8,9]}) 把a列的元素转换成list: # 方法1df['a'].values.tolist() # 方法2df['a'].tolist() 把a列中不重复的元素转换成list: df['a'].drop_duplicates().values.tolist() 输入一维datafram
-
Pandas数据结构详细说明及如何创建Series,DataFrame对象方法
目录 1. Pandas的两种数据类型 2. Series类型 通过numpy array 通过Python字典 通过标量值(Scalar) name属性 3. DataFrame类型 通过包含列表的Python List 通过包含Python 字典的Python List 通过Series 在网络上的Pandas教程中,很多都提到了如何使用Pandas将已有的数据(如csv,如hdfs等)直接加载成Pandas数据对象,然后在其基础上进行数据分析操作,但是,很多时候,我们需要自己创建Panda
-
pandas基础 Series与Dataframe与numpy对二进制文件输入输出
目录 Series Python numpy对二进制文件输入输出 Series series是一种一维的数组型对象,它包含了一个值序列和一个数据标签 import pandas as pd import numpy as np 创建第一个series: s1=pd.Series([4,7,-5,3])#创建一个series,索引为默认值 print(s1) 通过简单的一个传入数组,就可以形成一个一维的数据表格 获取序列的值和标签序列,应该如何去做? 我们在想这样一个问题,这个序列标签是默认的0
-
pandas 对series和dataframe进行排序的实例
本问主要写根据索引或者值对series和dataframe进行排序的实例讲解 代码: #coding=utf-8 import pandas as pd import numpy as np #以下实现排序功能. series=pd.Series([3,4,1,6],index=['b','a','d','c']) frame=pd.DataFrame([[2,4,1,5],[3,1,4,5],[5,1,4,2]],columns=['b','a','d','c'],index=['one','
-
python pandas 对series和dataframe的重置索引reindex方法
reindex更多的不是修改pandas对象的索引,而只是修改索引的顺序,如果修改的索引不存在就会使用默认的None代替此行.且不会修改原数组,要修改需要使用赋值语句. series.reindex() import pandas as pd import numpy as np obj = pd.Series(range(4), index=['d', 'b', 'a', 'c']) print obj d 0 b 1 a 2 c 3 dtype: int64 print obj.reinde
-
Pandas中Series和DataFrame的索引实现
正文 在对Series对象和DataFrame对象进行索引的时候要明确这么一个概念:是使用下标进行索引,还是使用关键字进行索引.比如list进行索引的时候使用的是下标,而dict索引的时候使用的是关键字. 使用下标索引的时候下标总是从0开始的,而且索引值总是数字.而使用关键字进行索引,关键字是key里面的值,既可以是数字,也可以是字符串等. Series对象介绍: Series对象是由索引index和值values组成的,一个index对应一个value.其中index是pandas中的Inde
-
Pandas中Series的创建及数据类型转换
目录 一.实战场景 二.主要知识点 三.菜鸟实战 1.创建 python 文件,用Numpy创建Series 2.转换Series的数据类型 四.补充 1.创建 python 文件,数据list,变成Pandas的Series对象 2.数据dict变成Pandas的Series对象 3.把Pandas的Series对象变成数据list 一.实战场景 实战场景:Pandas中Series的创建和数据类型转换,Series的创建和数据类型转换,Series 类似于一维数组与字典(map)数据结构的结
-
浅谈Pandas:Series和DataFrame间的算术元素
如下所示: import numpy as np import pandas as pd from pandas import Series,DataFrame 一.Series与Series s1 = Series([1,3,5,7],index=['a','b','c','d']) s2 = Series([2,4,6,8],index=['a','b','c','e']) 索引对齐项相加,不对齐项的值取NaN s1+s2 1 a 3.0 b 7.0 c 11.0 d NaN e NaN d
-
对pandas中两种数据类型Series和DataFrame的区别详解
1. Series相当于数组numpy.array类似 s1=pd.Series([1,2,4,6,7,2]) s2=pd.Series([4,3,1,57,8],index=['a','b','c','d','e']) print s2 obj1=s2.values # print obj1 obj2=s2.index # print obj2 # print s2[s2>4] # print s2['b'] 1.Series 它是有索引,如果我们未指定索引,则是以数字自动生成. 下面是一些例
-
Pandas:Series和DataFrame删除指定轴上数据的方法
如下所示: import numpy as np import pandas as pd from pandas import Series,DataFrame 一.drop方法:产生新对象 1.Series o = Series([1,3,4,7],index=['d','c','b','a']) print(o.drop(['d','b'])) c 3 a 7 dtype: int64 2.DataFrame data = {'水果':['苹果','梨','草莓'], '数量':[3,2,5
-
浅析pandas 数据结构中的DataFrame
DataFrame 类型类似于数据库表结构的数据结构,其含有行索引和列索引,可以将DataFrame 想成是由相同索引的Series组成的Dict类型.在其底层是通过二维以及一维的数据块实现. 1. DataFrame 对象的构建 1.1 用包含等长的列表或者是NumPy数组的字典创建DataFrame对象 In [68]: import pandas as pd In [69]: from pandas import Series,DataFrame # 建立包含等长列表的字典类型 In [7