python 代码实现k-means聚类分析的思路(不使用现成聚类库)
一、实验目标
1、使用 K-means 模型进行聚类,尝试使用不同的类别个数 K,并分析聚类结果。
2、按照 8:2 的比例随机将数据划分为训练集和测试集,至少尝试 3 个不同的 K 值,并画出不同 K 下 的聚类结果,及不同模型在训练集和测试集上的损失。对结果进行讨论,发现能解释数据的最好的 K 值。二、算法原理
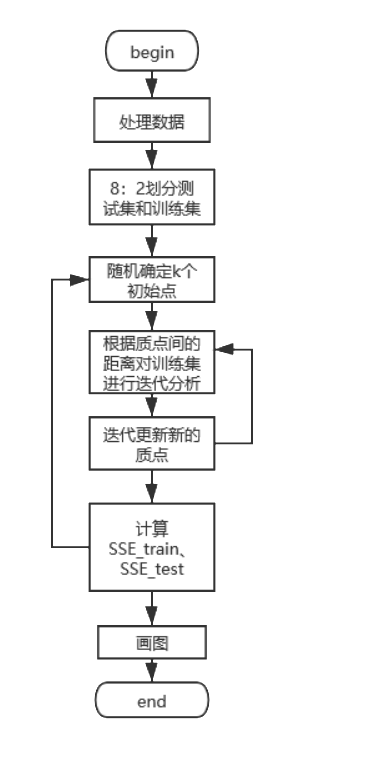
首先确定k,随机选择k个初始点之后所有点根据距离质点的距离进行聚类分析,离某一个质点a相较于其他质点最近的点分配到a的类中,根据每一类mean值更新迭代聚类中心,在迭代完成后分别计算训 练集和测试集的损失函数SSE_train、SSE_test,画图进行分析。
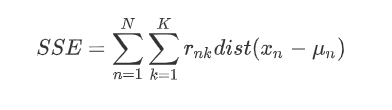
伪代码如下:
num=10 #k的种类 for k in range(1,num): 随机选择k个质点 for i in range(n): #迭代n次 根据点与质点间的距离对于X_train进行聚类 根据mean值迭代更新质点 计算SSE_train 计算SSE_test 画图
算法流程图:
三、代码实现
1、导入库
import pandas as pd import matplotlib.pyplot as plt import numpy as np from sklearn.model_selection import train_test_split
2、计算距离
def distance(p1,p2): return np.sqrt((p1[0]-p2[0])**2+(p1[1]-p2[1])**2)
3、计算均值
def means(arr): return np.array([np.mean([p[0] for p in arr]),np.mean([p[1] for p in arr])])
4、二维数据处理
#数据处理
data= pd.read_table('cluster.dat',sep='\t',header=None)
data.columns=['x']
data['y']=None
for i in range(len(data)): #遍历每一行
column = data['x'][i].split( ) #分开第i行,x列的数据。split()默认是以空格等符号来分割,返回一个列表
data['x'][i]=column[0] #分割形成的列表第一个数据给x列
data['y'][i]=column[1] #分割形成的列表第二个数据给y列
list=[]
list1=[]
for i in range(len(data)):
list.append(float(data['x'][i]))
list.append(float(data['y'][i]))
list1.append(list)
list=[]
arr=np.array(list1)
print(arr)

5、划分数据集和训练集
#按照8:2划分数据集和训练集 X_train, X_test = train_test_split(arr,test_size=0.2,random_state=1)
6、主要聚类实现
count=10 #k的种类:1、2、3...10 SSE_train=[] #训练集的SSE SSE_test=[] #测试集的SSE n=20 #迭代次数 for k in range(1,count): cla_arr=[] #聚类容器 centroid=[] #质点 for i in range(k): j=np.random.randint(0,len(X_train)) centroid.append(list1[j]) cla_arr.append([]) centroids=np.array(centroid) cla_tmp=cla_arr #临时训练集聚类容器 cla_tmp1=cla_arr #临时测试集聚类容器 for i in range(n): #开始迭代 for e in X_train: #对于训练集中的点进行聚类分析 pi=0 min_d=distance(e,centroids[pi]) for j in range(k): if(distance(e,centroids[j])<min_d): min_d=distance(e,centroids[j]) pi=j cla_tmp[pi].append(e) #添加点到相应的聚类容器中 for m in range(k): if(n-1==i): break centroids[m]=means(cla_tmp[m])#迭代更新聚类中心 cla_tmp[m]=[] dis=0 for i in range(k): #计算训练集的SSE_train for j in range(len(cla_tmp[i])): dis+=distance(centroids[i],cla_tmp[i][j]) SSE_train.append(dis) col = ['HotPink','Aqua','Chartreuse','yellow','red','blue','green','grey','orange'] #画出对应K的散点图 for i in range(k): plt.scatter([e[0] for e in cla_tmp[i]],[e[1] for e in cla_tmp[i]],color=col[i]) plt.scatter(centroids[i][0],centroids[i][1],linewidth=3,s=300,marker='+',color='black') plt.show() for e in X_test: #测试集根据训练集的质点进行聚类分析 ki=0 min_d=distance(e,centroids[ki]) for j in range(k): if(distance(e,centroids[j])<min_d): min_d=distance(e,centroids[j]) ki=j cla_tmp1[ki].append(e) for i in range(k): #计算测试集的SSE_test for j in range(len(cla_tmp1[i])): dis+=distance(centroids[i],cla_tmp1[i][j]) SSE_test.append(dis)

7、画图
SSE=[] #计算测试集与训练集SSE的差值
for i in range(len(SSE_test)):
SSE.append(SSE_test[i]-SSE_train[i])
x=[1,2,3,4,5,6,7,8,9]
plt.figure()
plt.plot(x,SSE_train,marker='*')
plt.xlabel("K")
plt.ylabel("SSE_train")
plt.show() #画出SSE_train的图
plt.figure()
plt.plot(x,SSE_test,marker='*')
plt.xlabel("K")
plt.ylabel("SSE_test")
plt.show() #画出SSE_test的图
plt.figure()
plt.plot(x,SSE,marker='+')
plt.xlabel("K")
plt.ylabel("SSE_test-SSE_train")
plt.show() #画出SSE_test-SSE_train的图

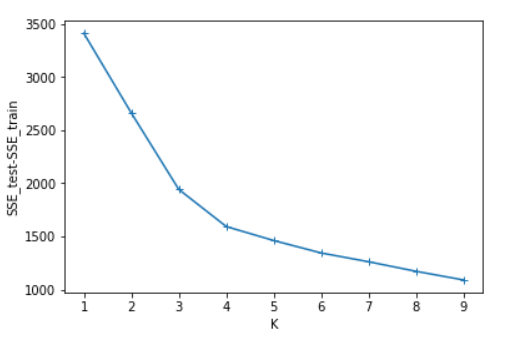
四、实验结果分析
可以看出SSE随着K的增长而减小,测试集和训练集的图形趋势几乎一致,在相同的K值下,测试集的SSE大于训练集的SSE。于是我对于在相同的K值下的SSE_test和SSE_train做了减法(上图3),可知K=4时数据得出结果最好。这里我主要使用肘部原则来判断。本篇并未实现轮廓系数,参考文章:https://www.jb51.net/article/187771.htm
总结
到此这篇关于python 代码实现k-means聚类分析(不使用现成聚类库)的文章就介绍到这了,更多相关python k-means聚类分析内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python实现k-means算法
本文实例为大家分享了Python实现k-means算法的具体代码,供大家参考,具体内容如下 这也是周志华<机器学习>的习题9.4. 数据集是西瓜数据集4.0,如下 编号,密度,含糖率 1,0.697,0.46 2,0.774,0.376 3,0.634,0.264 4,0.608,0.318 5,0.556,0.215 6,0.403,0.237 7,0.481,0.149 8,0.437,0.211 9,0.666,0.091 10,0.243,0.267 11,0.245,0.057 12
-

Python聚类算法之凝聚层次聚类实例分析
本文实例讲述了Python聚类算法之凝聚层次聚类.分享给大家供大家参考,具体如下: 凝聚层次聚类:所谓凝聚的,指的是该算法初始时,将每个点作为一个簇,每一步合并两个最接近的簇.另外即使到最后,对于噪音点或是离群点也往往还是各占一簇的,除非过度合并.对于这里的"最接近",有下面三种定义.我在实现是使用了MIN,该方法在合并时,只要依次取当前最近的点对,如果这个点对当前不在一个簇中,将所在的两个簇合并就行: 单链(MIN):定义簇的邻近度为不同两个簇的两个最近的点之间的距离. 全链(MAX
-
python基于K-means聚类算法的图像分割
1 K-means算法 实际上,无论是从算法思想,还是具体实现上,K-means算法是一种很简单的算法.它属于无监督分类,通过按照一定的方式度量样本之间的相似度,通过迭代更新聚类中心,当聚类中心不再移动或移动差值小于阈值时,则就样本分为不同的类别. 1.1 算法思路 随机选取聚类中心 根据当前聚类中心,利用选定的度量方式,分类所有样本点 计算当前每一类的样本点的均值,作为下一次迭代的聚类中心 计算下一次迭代的聚类中心与当前聚类中心的差距 如4中的差距小于给定迭代阈值时,迭代结束.反之,至2继续下
-
python中实现k-means聚类算法详解
算法优缺点: 优点:容易实现 缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢 使用数据类型:数值型数据 算法思想 k-means算法实际上就是通过计算不同样本间的距离来判断他们的相近关系的,相近的就会放到同一个类别中去. 1.首先我们需要选择一个k值,也就是我们希望把数据分成多少类,这里k值的选择对结果的影响很大,Ng的课说的选择方法有两种一种是elbow method,简单的说就是根据聚类的结果和k的函数关系判断k为多少的时候效果最好.另一种则是根据具体的需求确定,比如说进行衬衫尺寸的聚
-
详解K-means算法在Python中的实现
K-means算法简介 K-means是机器学习中一个比较常用的算法,属于无监督学习算法,其常被用于数据的聚类,只需为它指定簇的数量即可自动将数据聚合到多类中,相同簇中的数据相似度较高,不同簇中数据相似度较低. K-MEANS算法是输入聚类个数k,以及包含 n个数据对象的数据库,输出满足方差最小标准k个聚类的一种算法.k-means 算法接受输入量 k :然后将n个数据对象划分为 k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高:而不同聚类中的对象相似度较小. 核心思想 通过迭代寻找
-
Python聚类算法之DBSACN实例分析
本文实例讲述了Python聚类算法之DBSACN.分享给大家供大家参考,具体如下: DBSCAN:是一种简单的,基于密度的聚类算法.本次实现中,DBSCAN使用了基于中心的方法.在基于中心的方法中,每个数据点的密度通过对以该点为中心以边长为2*EPs的网格(邻域)内的其他数据点的个数来度量.根据数据点的密度分为三类点: 核心点:该点在邻域内的密度超过给定的阀值MinPs. 边界点:该点不是核心点,但是其邻域内包含至少一个核心点. 噪音点:不是核心点,也不是边界点. 有了以上对数据点的划分,聚合可
-
python实现鸢尾花三种聚类算法(K-means,AGNES,DBScan)
一.分散性聚类(kmeans) 算法流程: 1.选择聚类的个数k. 2.任意产生k个聚类,然后确定聚类中心,或者直接生成k个中心. 3.对每个点确定其聚类中心点. 4.再计算其聚类新中心. 5.重复以上步骤直到满足收敛要求.(通常就是确定的中心点不再改变. 优点: 1.是解决聚类问题的一种经典算法,简单.快速 2.对处理大数据集,该算法保持可伸缩性和高效率 3.当结果簇是密集的,它的效果较好 缺点 1.在簇的平均值可被定义的情况下才能使用,可能不适用于某些应用 2.必须事先给出k(要生成的簇的数
-
python 代码实现k-means聚类分析的思路(不使用现成聚类库)
一.实验目标 1.使用 K-means 模型进行聚类,尝试使用不同的类别个数 K,并分析聚类结果. 2.按照 8:2 的比例随机将数据划分为训练集和测试集,至少尝试 3 个不同的 K 值,并画出不同 K 下 的聚类结果,及不同模型在训练集和测试集上的损失.对结果进行讨论,发现能解释数据的最好的 K 值.二.算法原理 首先确定k,随机选择k个初始点之后所有点根据距离质点的距离进行聚类分析,离某一个质点a相较于其他质点最近的点分配到a的类中,根据每一类mean值更新迭代聚类中心,在迭代完成后分别
-
Python脚本实现监听服务器的思路代码详解
开前准备 Schedule使用方法. 基本的Linux操作 Python3环境 Step1 首先我得先假设你会了如何每十五分钟去运行一次检查这件事情.(后期我会补上如何去做定时任务,相信我!) 代码量比较少,选择在Linux环境下直接写脚本. import os #使用os的popen执行bash命令 content=os.popen("lsof -i:8080").read() 输出一下content看看,就是命令行执行输出的内容,看关键词webcache,但是输出的已经是文本文件了
-
以Python代码实例展示kNN算法的实际运用
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表. kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性.该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别. kNN方法在类别决策时,只与极少量的相邻样本有关.由于kNN方法主
-
使用Python代码实现Linux中的ls遍历目录命令的实例代码
一.写在前面 前几天在微信上看到这样一篇文章,链接为:https://www.jb51.net/it/692145.html,在这篇文章中,有这样一段话,吸引了我的注意: 在 Linux 中 ls 是一个使用频率非常高的命令了,可选的参数也有很多, 算是一条不得不掌握的命令.Python 作为一门简单易学的语言,被很多人认为是不需要认真学的,或者只是随便调个库就行了,那可就真是小瞧 Python 了.那这次我就要试着用 Python 来实现一下 Linux 中的 ls 命令, 小小地证明下 Py
-
使用pycharm和pylint检查python代码规范操作
pylint是一个不错的代码静态检查工具.将其配置在pycharm中,随时对代码进行分析,确保所有代码都符合pep8规范,以便于养成良好的习惯,将来受用无穷. 第一步,配置pylint - program: python安装目录下scripts/pylint.exe - arguments: --output-format=parseable --disable=R -rn --msg-template="{abspath}:{line}: [{msg_id}({symbol}), {obj}]
-
使用 Python 破解压缩文件的密码的思路详解
经常遇到百度网盘的压缩文件加密了,今天我们就破解它! 实现思路 上篇文章给大家介绍了爆破密码的思路,感兴趣的朋友可以了解下. 其实都大同小异:无非就是字典爆破,就看你是有现成密码字典,还是自己生成密码字典,然后进行循环输入密码,直到输入正确位置.现在很多都有防爆破限制,根本无法进行暴力破解,但是似乎zip这种大家都是用比较简单的密码而且没有什么限制. 因此 实现思路就是 生成字典->输入密码->成功解压 实现过程 1. 生成字典 生成密码字典其实就是一个字符组合的过程.小伙伴们可别用列表去组
-
11行Python代码实现解密摩斯密码
目录 1.引言 2.代码示例 2.1摩尔斯电码科普 2.2 加密 2.3 解密 3.总结 1.引言 小屌丝:鱼哥,快来求助求助! 小鱼:嗯? 啥事,让你这么慌慌张张的? 小屌丝:刚刚我女神给我发古来这一段符号,我不知道啥意思,能不能帮我翻译一下? 小鱼:啥符号? 小屌丝:这个"… …-- --… —… …— … …-- —… —… -----" 小鱼:这… 这不是摩斯密码吗,你女神啥时候这么厉害了? 小屌丝:鱼哥,别管那么多了,快看看能不能翻译出啥意思,万一是我的女神要找我压马路呢?
-
Python 代码性能优化技巧分享
如何进行 Python 性能优化,是本文探讨的主要问题.本文会涉及常见的代码优化方法,性能优化工具的使用以及如何诊断代码的性能瓶颈等内容,希望可以给 Python 开发人员一定的参考. Python 代码优化常见技巧 代码优化能够让程序运行更快,它是在不改变程序运行结果的情况下使得程序的运行效率更高,根据 80/20 原则,实现程序的重构.优化.扩展以及文档相关的事情通常需要消耗 80% 的工作量.优化通常包含两方面的内容:减小代码的体积,提高代码的运行效率. 改进算法,选择合适的数据结构 一个
-
盘点提高 Python 代码效率的方法
第一招:蛇打七寸:定位瓶颈 首先,第一步是定位瓶颈.举个简单的栗子,一个函数可以从1秒优化到到0.9秒,另一个函数可以从1分钟优化到30秒,如果要花的代价相同,而且时间限制只能搞定一个,搞哪个?根据短板原理,当然选第二个啦. 一个有经验的程序员在这里一定会迟疑一下,等等?函数?这么说,还要考虑调用次数?如果第一个函数在整个程序中需要被调用100000次,第二个函数在整个程序中被调用1次,这个就不一定了.举这个栗子,是想说明,程序的瓶颈有的时候不一定一眼能看出来.还是上面那个选择,程序员的你应该有
-
使用11行Python代码盗取了室友的U盘内容
序言 那个猥琐的家伙整天把个U盘藏着当宝,到睡觉了就拿出来插到电脑上. 我决定想个办法看他U盘里都藏了什么,直接去抢U盘是不可能的,骗也是不可能的.那不是丢我Python程序员的脸? 我必须在电脑上智取,而且不能被他发现. 这个是我的思路: 当一个usb插入时,在后台自动把usb里的东西拷贝到本地或上传到某个服务器. 那么我就可以先借他电脑玩一会,然后把我写好的Python程序在电脑后台运行.每当有usb插入的时候,就自动拷贝文件. 如何判断U盘是否插入? 首先打开电脑终端,进入/Volumes