StringBuider 在什么条件下、如何使用效率更高
引言
都说 StringBuilder 在处理字符串拼接上效率要强于 String,但有时候我们的理解可能会存在一定的偏差。最近我在测试数据导入效率的时候就发现我以前对 StringBuilder 的部分理解是错误的。 后来我通过实践测试 + 找原理 的方式搞清楚了这块的逻辑。现在将过程分享给大家
测试用例
我们的代码在循环中拼接字符串一般有两种情况
第一种就是每次循环将对象中的几个字段拼接成一个新字段,再赋值给对象第二种操作是在循环外创建一个字符串对象,每次循环向该字符串拼接新的内容。循环结束后得到拼接好的字符串
对于这两种情况,我创建了两个对照组
第一组:
在每次 For 循环中拼接字符串,即拼即用、用完即毁。分别使用 String 和 StringBuilder 拼接
/**
* 循环内 String 拼接字符串,一次循环后销毁
*/
public static void useString(){
for (int i = 0; i < CYCLE_NUM_BIGGER; i++) {
String str = str1 + i + str2 + i + str3 + i + str4 ;
}
}
/**
* 循环内 使用 StringBuilder 拼接字符串,一次循环后销毁
*/
public static void useStringBuilder(){
for (int i = 0; i < CYCLE_NUM_BIGGER; i++) {
StringBuilder sb = new StringBuilder();
String s = sb.append(str1).append(i).append(str2).append(i).append(str3).append(i).append(str4).toString();
}
}
第二组:
多次 For 循环拼接一个字符串,循环结束后使用字符串,使用后由垃圾回收器回收。也是分别使用 String 和 StringBuilder 拼接
/**
* 多次循环拼接成一个字符串 用 String
*/
public static void useStringSpliceOneStr (){
String str = "";
for (int i = 0; i < CYCLE_NUM_LOWER; i++) {
str += str1 + str2 + str3 + str4 + i;
}
}
/**
* 多次循环拼接成一个字符串 用 StringBuilder
*/
public static void useStringBuilderSpliceOneStr(){
StringBuilder sb = new StringBuilder();
for (int i = 0; i < CYCLE_NUM_LOWER; i++) {
sb.append(str1).append(str2).append(str3).append(str4).append(i);
}
}
为了保证测试质量,在每个测试项目进行前。线程休息 2s,之后空跑 5 次热身。最后执行 5 次求平均时间的方式计算时间
public static int executeSometime(int kind, int num) throws InterruptedException {
Thread.sleep(2000);
int sum = 0;
for (int i = 0; i < num + 5; i++) {
long begin = System.currentTimeMillis();
switch (kind){
case 1:
useString();
break;
case 2:
useStringBuilder();
break;
case 3:
useStringSpliceOneStr();
break;
case 4:
useStringBuilderSpliceOneStr();
break;
default:
return 0;
}
long end = System.currentTimeMillis();
if(i > 5){
sum += (end - begin);
}
}
return sum / num;
}
主方法
public class StringTest {
public static final int CYCLE_NUM_BIGGER = 10_000_000;
public static final int CYCLE_NUM_LOWER = 10_000;
public static final String str1 = "张三";
public static final String str2 = "李四";
public static final String str3 = "王五";
public static final String str4 = "赵六";
public static void main(String[] args) throws InterruptedException {
int time = 0;
int num = 5;
time = executeSometime(1, num);
System.out.println("String拼接 "+ CYCLE_NUM_BIGGER +" 次," + num + "次平均时间:" + time + " ms");
time = executeSometime(2, num);
System.out.println("StringBuilder拼接 "+ CYCLE_NUM_BIGGER +" 次," + num + "次平均时间:" + time + " ms");
time = executeSometime(3, num);
System.out.println("String拼接单个字符串 "+ CYCLE_NUM_LOWER +" 次," + num + "次平均时间:" + time + " ms");
time = executeSometime(4, num);
System.out.println("StringBuilder拼接单个字符串 "+ CYCLE_NUM_LOWER +" 次," + num + "次平均时间:" + time + " ms");
}
}
测试结果
测试结果如下
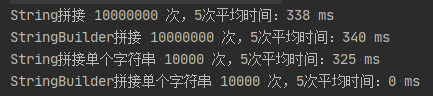
结果分析
第一组
10_000_000 次循环拼接,在循环内使用 String 和 StringBuilder 的效率是一样的!为什么呢?
使用 javap -c StringTest.class 反编译查看两个方法编译后的文件:
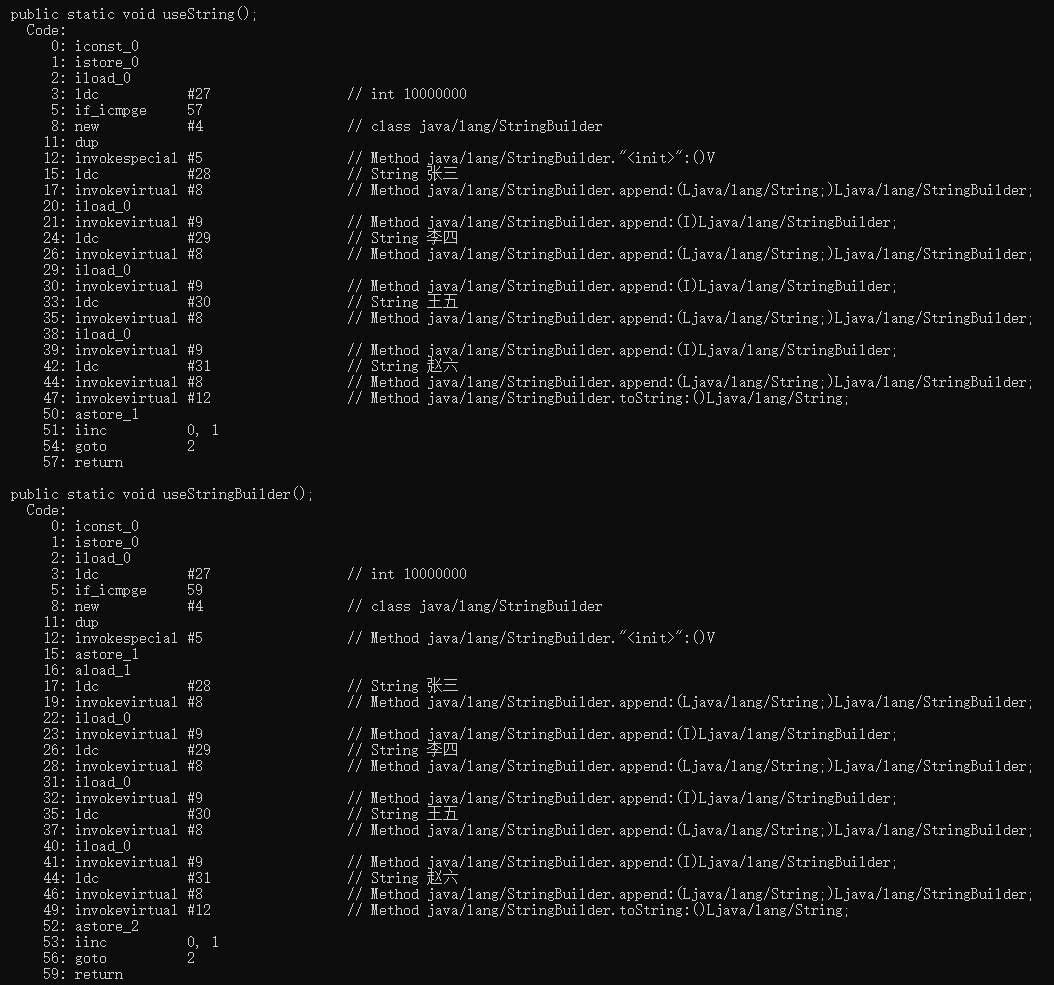
可以发现 String 方法拼接字符串编译器优化后使用的就是 StringBuilder、因此用例1 和用例2 的效率是一样的。
第二组
第二组的结果就是大家喜闻乐见的了,由于 10_000_000 次循环String 拼接实在太慢所以我采用了 10_000 次拼接来分析。
分析用例3:虽然编译器会对 String 拼接做优化,但是它每次在循环内创建 StringBuilder 对象,在循环内销毁。下次循环他有创建。相比较用例4在循环外创建,多了 n 次 new 对象、销毁对象的操作、n - 1 次将 StringBuilder 转换成 String 的操作 。效率低也是理所应当了。
扩展
第一组的测试还有一种写法:
/**
* 循环内 使用 StringBuilder 拼接字符串,一次循环后销毁
*/
public static void useStringBuilderOut(){
StringBuilder sb = new StringBuilder();
for (int i = 0; i < CYCLE_NUM_BIGGER; i++) {
// sb.setLength(0);
sb.delete(0, sb.length());
String s = sb.append(str1).append(i).append(str2).append(i).append(str3).append(i).append(str4).toString();
}
}
循环外创建 StringBuilder 每次循环开始的时候清空 StringBuilder 的内容然后拼接。这种写法无论使用 sb.setLength(0); 还是 sb.delete(0, sb.length()); 效率都比直接在循环内使用 String / StringBuilder 慢。奈何才疏学浅我一直想不明白为什么他慢。我猜测是 new 对象的速度比重置长度慢,于是这样测试了以下:
public static void createStringBuider() {
for (int i = 0; i < CYCLE_NUM_BIGGER; i++) {
StringBuilder sb = new StringBuilder();
}
}
public static void cleanStringBuider() {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < CYCLE_NUM_BIGGER; i++) {
sb.delete(0, sb.length());
}
}
但是结果是 cleanStringBuider 更快。让我摸不着头脑
如果有大神看到希望可以帮忙分析分析
结论
编译器会将 String 拼接优化成使用 StringBuilder,但是还是有一些缺陷的。主要体现在循环内使用字符串拼接,编译器不会创建单个 StringBuilder 以复用
对于多次循环内拼接一个字符串的需求:StringBuilder 很快,因为其避免了 n 次 new 对象、销毁对象的操作,n - 1 次将 StringBuilder 转换成 String 的操作
StringBuilder 拼接不适用于循环内每次拼接即用的操作方式。因为编译器优化后的 String 拼接也是使用 StringBuilder 两者的效率一样。后者写起来还方便...
到此这篇关于StringBuider 在什么条件下、如何使用效率更高?的文章就介绍到这了,更多相关StringBuider如何使用效率更高内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

深入解析Java编程中的StringBuffer与StringBuider
String 的值是不可变的,每次对String的操作都会生成新的String对象,不仅效率低,而且耗费大量内存空间. StringBuffer类和String类一样,也用来表示字符串,但是StringBuffer的内部实现方式和String不同,在进行字符串处理时,不生成新的对象,在内存使用上要优于String. StringBuffer 默认分配16字节长度的缓冲区,当字符串超过该大小时,会自动增加缓冲区长度,而不是生成新的对象. StringBuffer不像String,只能通过 new
-
StringBuider 在什么条件下、如何使用效率更高
引言 都说 StringBuilder 在处理字符串拼接上效率要强于 String,但有时候我们的理解可能会存在一定的偏差.最近我在测试数据导入效率的时候就发现我以前对 StringBuilder 的部分理解是错误的. 后来我通过实践测试 + 找原理 的方式搞清楚了这块的逻辑.现在将过程分享给大家 测试用例 我们的代码在循环中拼接字符串一般有两种情况 第一种就是每次循环将对象中的几个字段拼接成一个新字段,再赋值给对象第二种操作是在循环外创建一个字符串对象,每次循环向该字符串拼接新的内容.循环结束
-
Java多线程中不同条件下编写生产消费者模型方法介绍
简介: 生产者.消费者模型是多线程编程的常见问题,最简单的一个生产者.一个消费者线程模型大多数人都能够写出来,但是一旦条件发生变化,我们就很容易掉进多线程的bug中.这篇文章主要讲解了生产者和消费者的数量,商品缓存位置数量,商品数量等多个条件的不同组合下,写出正确的生产者消费者模型的方法. 欢迎探讨,如有错误敬请指正 生产消费者模型 生产者消费者模型具体来讲,就是在一个系统中,存在生产者和消费者两种角色,他们通过内存缓冲区进行通信,生产者生产消费者需要的资料,消费者把资料做成产品.生产消费者模式
-
python复合条件下的字典排序
知乎上有人说,Python3.6以后字典有序且更高效了.群里有同学推荐了这篇文章给我看,并咨询字典排序的问题. 大致浏览了一下,我当即表示不能认同这个说法.这篇文章的作者,应该是一位资深的专业人士,对于Python解释器如何实现字典存储和检索有着深刻地理解.但他犯了一明显的常识性错误:在逻辑上,字典是数据的无序集合,仅依赖于键检索.我们说字典是无序,不是指字典在物理实体上实现的时候真的无序,而是指它的顺序对用户而言没有明确的界定,不能作为数据的特性使用.知乎上这篇文章讲的字典有序,是指字典在物理
-
vue 实现特定条件下绑定事件
今天写了个小功能,看起来挺简单,写的过程中发现了些坑. 1.div没有disabled的属性,所以得写成button 2.disabled在data时,默认是true,使得初始化时,默认置灰按钮,无法点击 <div class='form-item'> <div class="checkWrap clearfix" @click='checkMark()'> <div class="checkBox" v-show="chec
-
python 写函数在一定条件下需要调用自身时的写法说明
例如以下这个函数: state = 1 def set_state(state): while state: set = int(input('请输入9或5,显示"hello world"\n')) if set == 9 or set == 5: print('hello world') state = int(input('输入1继续,输入0停止!\n')) else: print('请输入要求的值!') set_state(state) # break set_state(sta
-
List集合多线程并发条件下不安全如何解决
目录 前言 一.List集合使用模拟并发测试 1.1 单线程环境下 1.2 多线程环境下 二.解决方案 2.1 使用Vector类 2.1 使用Collections.synchronizedList 2.3 使用并发容器CopyOnWriteArrayList 总结 前言 在日常开发过程中,List是我们常用的集合,比如查询数据库内容返回值比会用一个集合来装,但是在多线程并发的条件下,会出现安全问题吗?下面我们就来测试一下,如果出现安全问题,该如何解决. 一.List集合使用模拟并发测试 1.
-
PHP 字符串长度判断效率更高的方法
有经验的程序员发现,php判断字符串长度,使用isset()在速度上比strlen()更快,执行效率更高.即: 复制代码 代码如下: $str = 'aaaaaa';if(strlen($str) > 6)VSif(!isset($str{6}) 用例子简单测试下,情况基本属实,isset()效率几乎是strlen()的3倍.示例: 复制代码 代码如下: <?php //使用strlen方式 $arr = "123456"; $sTime = microtime(1); i
-
探讨++i与i++哪个效率更高
答案: 在内建数据类型的情况下,效率没有区别: 在自定义数据类型的情况下,++i效率更高! 分析: (自定义数据类型的情况下) ++i返回对象的引用: i++总是要创建一个临时对象,在退出函数时还要销毁它,而且返回临时对象的值时还会调用其拷贝构造函数. (重载这两个运算符如下) 复制代码 代码如下: #include <iostream>using namespace std; class MyInterger{public: long m_data;public: MyInter
-
详解Linux文件系统:ext4及更高版本
今天带大家了解一下ext4的历史,包括其与ext3和之前的其它文件系统之间的区别 大多数现代Linux发行版默认为ext 4文件系统,就像以前的Linux发行版默认为ext3.ext2,以及-如果追溯到足够远的话-ext. 如果您是Linux新手或者是文件系统新手,您可能会想知道ext 4给表带来了什么,而ext3却没有.考虑到诸如btrfs.XFS和ZFS等备用文件系统的新闻报道,您可能还想知道ext4是否还在积极开发中. 我们不能在一篇文章中涵盖所有关于文件系统的内容,但是我们将尝试让您了解
-
Spring AOP中的JDK和CGLib动态代理哪个效率更高?
一.背景 今天有小伙伴面试的时候被问到:Spring AOP中JDK 和 CGLib动态代理哪个效率更高? 二.基本概念 首先,我们知道Spring AOP的底层实现有两种方式:一种是JDK动态代理,另一种是CGLib的方式. 自Java 1.3以后,Java提供了动态代理技术,允许开发者在运行期创建接口的代理实例,后来这项技术被用到了Spring的很多地方. JDK动态代理主要涉及java.lang.reflect包下边的两个类:Proxy和InvocationHandler.其中,Invoc