PyTorch中model.zero_grad()和optimizer.zero_grad()用法
废话不多说,直接上代码吧~
model.zero_grad()
optimizer.zero_grad()
首先,这两种方式都是把模型中参数的梯度设为0
当optimizer = optim.Optimizer(net.parameters())时,二者等效,其中Optimizer可以是Adam、SGD等优化器
def zero_grad(self): """Sets gradients of all model parameters to zero.""" for p in self.parameters(): if p.grad is not None: p.grad.data.zero_()
补充知识:Pytorch中的optimizer.zero_grad和loss和net.backward和optimizer.step的理解
引言
一般训练神经网络,总是逃不开optimizer.zero_grad之后是loss(后面有的时候还会写forward,看你网络怎么写了)之后是是net.backward之后是optimizer.step的这个过程。
real_a, real_b = batch[0].to(device), batch[1].to(device) fake_b = net_g(real_a) optimizer_d.zero_grad() # 判别器对虚假数据进行训练 fake_ab = torch.cat((real_a, fake_b), 1) pred_fake = net_d.forward(fake_ab.detach()) loss_d_fake = criterionGAN(pred_fake, False) # 判别器对真实数据进行训练 real_ab = torch.cat((real_a, real_b), 1) pred_real = net_d.forward(real_ab) loss_d_real = criterionGAN(pred_real, True) # 判别器损失 loss_d = (loss_d_fake + loss_d_real) * 0.5 loss_d.backward() optimizer_d.step()
上面这是一段cGAN的判别器训练过程。标题中所涉及到的这些方法,其实整个神经网络的参数更新过程(特别是反向传播),具体是怎么操作的,我们一起来探讨一下。
参数更新和反向传播
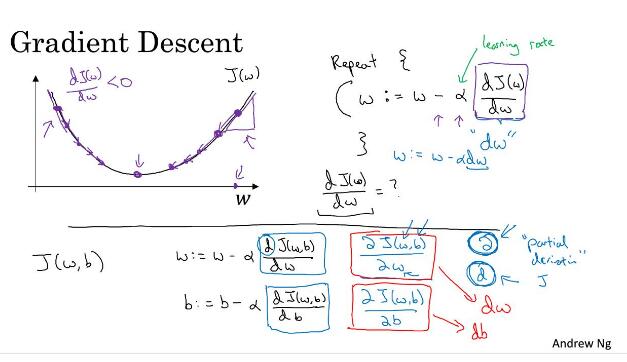
上图为一个简单的梯度下降示意图。比如以SGD为例,是算一个batch计算一次梯度,然后进行一次梯度更新。这里梯度值就是对应偏导数的计算结果。显然,我们进行下一次batch梯度计算的时候,前一个batch的梯度计算结果,没有保留的必要了。所以在下一次梯度更新的时候,先使用optimizer.zero_grad把梯度信息设置为0。
我们使用loss来定义损失函数,是要确定优化的目标是什么,然后以目标为头,才可以进行链式法则和反向传播。
调用loss.backward方法时候,Pytorch的autograd就会自动沿着计算图反向传播,计算每一个叶子节点的梯度(如果某一个变量是由用户创建的,则它为叶子节点)。使用该方法,可以计算链式法则求导之后计算的结果值。
optimizer.step用来更新参数,就是图片中下半部分的w和b的参数更新操作。
以上这篇PyTorch中model.zero_grad()和optimizer.zero_grad()用法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
使用PyTorch训练一个图像分类器实例
如下所示: import torch import torchvision import torchvision.transforms as transforms import matplotlib.pyplot as plt import numpy as np print("torch: %s" % torch.__version__) print("tortorchvisionch: %s" % torchvision.__version__) print(&
-
PyTorch的Optimizer训练工具的实现
torch.optim 是一个实现了各种优化算法的库.大部分常用的方法得到支持,并且接口具备足够的通用性,使得未来能够集成更加复杂的方法. 使用 torch.optim,必须构造一个 optimizer 对象.这个对象能保存当前的参数状态并且基于计算梯度更新参数. 例如: optimizer = optim.SGD(model.parameters(), lr = 0.01, momentum=0.9) optimizer = optim.Adam([var1, var2], lr = 0.00
-
PyTorch-GPU加速实例
硬件:NVIDIA-GTX1080 软件:Windows7.python3.6.5.pytorch-gpu-0.4.1 一.基础知识 将数据和网络都推到GPU,接上.cuda() 二.代码展示 import torch import torch.nn as nn import torch.utils.data as Data import torchvision # torch.manual_seed(1) EPOCH = 1 BATCH_SIZE = 50 LR = 0.001 DOWNLOA
-
pytorch中的优化器optimizer.param_groups用法
optimizer.param_groups: 是长度为2的list,其中的元素是2个字典: optimizer.param_groups[0]: 长度为6的字典,包括['amsgrad', 'params', 'lr', 'betas', 'weight_decay', 'eps']这6个参数: optimizer.param_groups[1]: 好像是表示优化器的状态的一个字典: import torch import torch.optim as optimh2 w1 = torch.r
-
PyTorch中model.zero_grad()和optimizer.zero_grad()用法
废话不多说,直接上代码吧~ model.zero_grad() optimizer.zero_grad() 首先,这两种方式都是把模型中参数的梯度设为0 当optimizer = optim.Optimizer(net.parameters())时,二者等效,其中Optimizer可以是Adam.SGD等优化器 def zero_grad(self): """Sets gradients of all model parameters to zero.""
-

解决Pytorch中的神坑:关于model.eval的问题
有时候使用Pytorch训练完模型,在测试数据上面得到的结果令人大跌眼镜. 这个时候需要检查一下定义的Model类中有没有 BN 或 Dropout 层,如果有任何一个存在 那么在测试之前需要加入一行代码: #model是实例化的模型对象 model = model.eval() 表示将模型转变为evaluation(测试)模式,这样就可以排除BN和Dropout对测试的干扰. 因为BN和Dropout在训练和测试时是不同的: 对于BN,训练时通常采用mini-batch,所以每一批中的mean
-
pytorch中的model=model.to(device)使用说明
这代表将模型加载到指定设备上. 其中,device=torch.device("cpu")代表的使用cpu,而device=torch.device("cuda")则代表的使用GPU. 当我们指定了设备之后,就需要将模型加载到相应设备中,此时需要使用model=model.to(device),将模型加载到相应的设备中. 将由GPU保存的模型加载到CPU上. 将torch.load()函数中的map_location参数设置为torch.device('cpu')
-
聊聊PyTorch中eval和no_grad的关系
首先这两者有着本质上区别 model.eval()是用来告知model内的各个layer采取eval模式工作.这个操作主要是应对诸如dropout和batchnorm这些在训练模式下需要采取不同操作的特殊layer.训练和测试的时候都可以开启. torch.no_grad()则是告知自动求导引擎不要进行求导操作.这个操作的意义在于加速计算.节约内存.但是由于没有gradient,也就没有办法进行backward.所以只能在测试的时候开启. 所以在evaluate的时候,需要同时使用两者. mod
-
在pytorch中查看可训练参数的例子
pytorch中我们有时候可能需要设定某些变量是参与训练的,这时候就需要查看哪些是可训练参数,以确定这些设置是成功的. pytorch中model.parameters()函数定义如下: def parameters(self): r"""Returns an iterator over module parameters. This is typically passed to an optimizer. Yields: Parameter: module paramete
-
聊聊pytorch中Optimizer与optimizer.step()的用法
当我们想指定每一层的学习率时: optim.SGD([ {'params': model.base.parameters()}, {'params': model.classifier.parameters(), 'lr': 1e-3} ], lr=1e-2, momentum=0.9) 这意味着model.base的参数将会使用1e-2的学习率,model.classifier的参数将会使用1e-3的学习率,并且0.9的momentum将会被用于所有的参数. 进行单次优化 所有的optimiz
-
浅谈pytorch中为什么要用 zero_grad() 将梯度清零
pytorch中为什么要用 zero_grad() 将梯度清零 调用backward()函数之前都要将梯度清零,因为如果梯度不清零,pytorch中会将上次计算的梯度和本次计算的梯度累加. 这样逻辑的好处是,当我们的硬件限制不能使用更大的bachsize时,使用多次计算较小的bachsize的梯度平均值来代替,更方便,坏处当然是每次都要清零梯度. optimizer.zero_grad() output = net(input) loss = loss_f(output, target) los
-
Pytorch 中的optimizer使用说明
与优化函数相关的部分在torch.optim模块中,其中包含了大部分现在已有的流行的优化方法. 如何使用Optimizer 要想使用optimizer,需要创建一个optimizer 对象,这个对象会保存当前状态,并根据梯度更新参数. 怎样构造Optimizer 要构造一个Optimizer,需要使用一个用来包含所有参数(Tensor形式)的iterable,把相关参数(如learning rate.weight decay等)装进去. 注意,如果想要使用.cuda()方法来将model移到GP
-
Pytorch 中retain_graph的用法详解
用法分析 在查看SRGAN源码时有如下损失函数,其中设置了retain_graph=True,其作用是什么? ############################ # (1) Update D network: maximize D(x)-1-D(G(z)) ########################### real_img = Variable(target) if torch.cuda.is_available(): real_img = real_img.cuda() z = V