Pandas||过滤缺失数据||pd.dropna()函数的用法说明
看代码吧~
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False) Remove missing values.
pd.dropna()函数(官方文档)用于过滤数据中的缺失数据.
缺失数据在pandas中用NaN标记.
import pandas as pd
import numpy as np
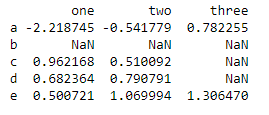
df = pd.DataFrame(np.random.randn(5, 3), index = list('abcde'), columns = ['one', 'two', 'three']) # 随机产生5行3列的数据
df.ix[1, :-1] = np.nan # 将指定数据定义为缺失
df.ix[1:-1, 2] = np.nan
print(df)
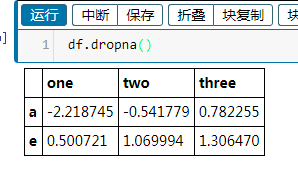
df.dropna() #删除所有带缺失数据的行
| parameters | 详解 |
|---|---|
| axis | default 0指行,1为列 |
| how | {‘any', ‘all'}, default ‘any'指带缺失值的所有行;'all'指清除全是缺失值的行 |
| thresh | int,保留含有int个非空值的行 |
| subset | 对特定的列进行缺失值删除处理 |
| inplace | 这个很常见,True表示就地更改 |
补充:Python-pandas的dropna()方法-丢弃含空值的行、列
0.摘要
dropna()方法,能够找到DataFrame类型数据的空值(缺失值),将空值所在的行/列删除后,将新的DataFrame作为返回值返回。
1.函数详解
函数形式:dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
参数:
axis:轴。0或'index',表示按行删除;1或'columns',表示按列删除。
how:筛选方式。‘any',表示该行/列只要有一个以上的空值,就删除该行/列;‘all',表示该行/列全部都为空值,就删除该行/列。
thresh:非空元素最低数量。int型,默认为None。如果该行/列中,非空元素数量小于这个值,就删除该行/列。
subset:子集。列表,元素为行或者列的索引。如果axis=0或者‘index',subset中元素为列的索引;如果axis=1或者‘column',subset中元素为行的索引。由subset限制的子区域,是判断是否删除该行/列的条件判断区域。
inplace:是否原地替换。布尔值,默认为False。如果为True,则在原DataFrame上进行操作,返回值为None。
2.示例
创建DataFrame数据:
import numpy as np
import pandas as pd
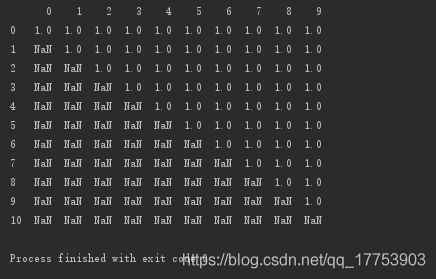
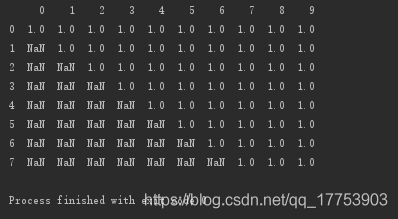
a = np.ones((11,10))
for i in range(len(a)):
a[i,:i] = np.nan
d = pd.DataFrame(data=a)
print(d)
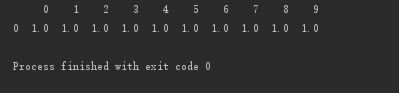
按行删除:存在空值,即删除该行
# 按行删除:存在空值,即删除该行 print(d.dropna(axis=0, how='any'))
按行删除:所有数据都为空值,即删除该行
# 按行删除:所有数据都为空值,即删除该行 print(d.dropna(axis=0, how='all'))
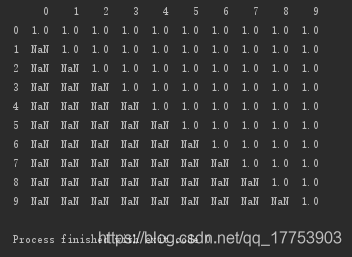
按列删除:该列非空元素小于5个的,即删除该列
# 按列删除:该列非空元素小于5个的,即删除该列 print(d.dropna(axis='columns', thresh=5))
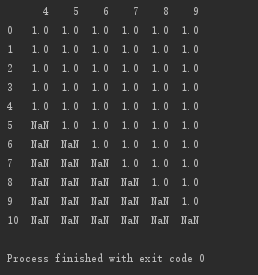
设置子集:删除第0、5、6、7列都为空的行
# 设置子集:删除第0、5、6、7列都为空的行 print(d.dropna(axis='index', how='all', subset=[0,5,6,7]))
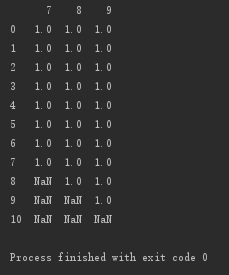
设置子集:删除第5、6、7行存在空值的列
# 设置子集:删除第5、6、7行存在空值的列 print(d.dropna(axis=1, how='any', subset=[5,6,7]))
原地修改
# 原地修改
print(d.dropna(axis=0, how='any', inplace=True))
print("==============================")
print(d)
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

Pandas的数据过滤实现
作者|Amanda Iglesias Moreno 编译|VK 来源|Towards Datas Science 从数据帧中过滤数据是清理数据时最常见的操作之一.Pandas提供了一系列根据行和列的位置和标签选择数据的方法.此外,Pandas还允许你根据列类型获取数据子集,并使用布尔索引筛选行. 在本文中,我们将介绍从Pandas数据框中选择数据子集的最常见操作: 按标签选择单列 按标签选择多列 按数据类型选择列 按标签选择一行 按标签选择多行 按位置选择一行 按位置选择多行 同时选择行和列 选
-
详解pandas如何去掉、过滤数据集中的某些值或者某些行?
摘要在进行数据分析与清理中,我们可能常常需要在数据集中去掉某些异常值.具体来说,看看下面的例子. 0.导入我们需要使用的包 import pandas as pd pandas是很常用的数据分析,数据处理的包.anaconda已经有这个包了,纯净版python的可以自行pip安装. 1.去掉某些具体值 数据集df中,对于属性appPlatform(最后一列),我们想删除掉取值为2的那些样本.如何做?非常简单. import pandas as pd df[(True-df['appPlatfor
-
Pandas过滤dataframe中包含特定字符串的数据方法
假如有一列全是字符串的dataframe,希望提取包含特定字符的所有数据,该如何提取呢? 因为之前尝试使用filter,发现行不通,最终找到这个行得通的方法. 举例说明: 我希望提取所有包含'Mr.'的人名 1.首先将他们进行字符串化,并得到其对应的布尔值: >>> bool = df.str.contains('Mr\.') #不要忘记正则表达式的写法,'.'在里面要用'\.'表示 >>> print('bool : \n', bool) 2.通过dataframe的
-
Pandas||过滤缺失数据||pd.dropna()函数的用法说明
看代码吧~ DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False) Remove missing values. pd.dropna()函数(官方文档)用于过滤数据中的缺失数据. 缺失数据在pandas中用NaN标记. import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(5, 3), index = lis
-
详解pandas删除缺失数据(pd.dropna()方法)
1.创建带有缺失值的数据库: import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(5, 3), index = list('abcde'), columns = ['one', 'two', 'three']) # 随机产生5行3列的数据 df.ix[1, :-1] = np.nan # 将指定数据定义为缺失 df.ix[1:-1, 2] = np.nan print('\ndf1') # 输出df1,
-
Pandas之缺失数据的实现
前言 本章介绍pandas中的缺失数据,主要内容有: pandas中对np.nan的操作: 统计 . 删除 . 填充 . 插值 pandas中的Nullable类型及相关操作 在无特殊说明时,本章主要采用的df数据如下,不再重复说明: df = pd.read_csv('./data/learn_pandas.csv',usecols=['Grade','Name','Gender','Height','Weight','Transfer']) df 一.缺失值的统计和删除 1.缺失值的统计 我
-
Pandas之Dropna滤除缺失数据的实现方法
约定: import pandas as pd import numpy as np from numpy import nan as NaN 滤除缺失数据 pandas的设计目标之一就是使得处理缺失数据的任务更加轻松些.pandas使用NaN作为缺失数据的标记. 使用dropna使得滤除缺失数据更加得心应手. 一.处理Series对象 通过**dropna()**滤除缺失数据: se1=pd.Series([4,NaN,8,NaN,5]) print(se1) se1.dropna() 代码结
-
详解pandas中缺失数据处理的函数
目录 一.缺失值类型 1.np.nan 2.None 3.NA标量 二.缺失值判断 1.对整个dataframe判断缺失 2.对某个列判断缺失 三.缺失值统计 1.列缺失 2.行缺失 3.缺失率 四.缺失值筛选 五.缺失值填充 六.缺失值删除 1.全部直接删除 2.行缺失删除 3.列缺失删除 4.按缺失率删除 七.缺失值参与计算 1.加法 2.累加 3.计数 4.聚合分组 五.源码 今天分享一篇pandas缺失值处理的操作指南! 一.缺失值类型 在pandas中,缺失数据显示为NaN.缺失值有3
-
Pandas之Fillna填充缺失数据的方法
约定: import pandas as pd import numpy as np from numpy import nan as NaN 填充缺失数据 fillna()是最主要的处理方式了. df1=pd.DataFrame([[1,2,3],[NaN,NaN,2],[NaN,NaN,NaN],[8,8,NaN]]) df1 代码结果: 0 1 2 0 1.0 2.0 3.0 1 NaN NaN 2.0 2 NaN NaN NaN 3 8.0 8.0 NaN 用常数填充: df1.fill
-
Python Pandas中合并数据的5个函数使用详解
目录 join 索引一致 索引不一致 merge concat 纵向拼接 横向拼接 append combine 前几天在一个群里面,看到一位朋友,说到自己的阿里面试,被问了一些关于pandas的使用.其中一个问题是:pandas中合并数据的5中方法. 今天借着这个机会,就为大家盘点一下pandas中合并数据的5个函数.但是对于每个函数,我这里不打算详细说明,具体用法大家可以参考pandas官当文档. join主要用于基于索引的横向合并拼接: merge主要用于基于指定列的横向合并拼接: con
-
python使用pandas处理大数据节省内存技巧(推荐)
一般来说,用pandas处理小于100兆的数据,性能不是问题.当用pandas来处理100兆至几个G的数据时,将会比较耗时,同时会导致程序因内存不足而运行失败. 当然,像Spark这类的工具能够胜任处理100G至几个T的大数据集,但要想充分发挥这些工具的优势,通常需要比较贵的硬件设备.而且,这些工具不像pandas那样具有丰富的进行高质量数据清洗.探索和分析的特性.对于中等规模的数据,我们的愿望是尽量让pandas继续发挥其优势,而不是换用其他工具. 本文我们讨论pandas的内存使用,展示怎样
-
Python入门之使用pandas分析excel数据
1.问题 在python中,读写excel数据方法很多,比如xlrd.xlwt和openpyxl,实际上限制比较多,不是很方便.比如openpyxl也不支持csv格式.有没有更好的方法? 2.方案 更好的方法可以使用pandas,虽然pandas不是专门处理excel数据,但处理excel数据确实很方便. 本文使用excel的数据来自网络,数据内容如下: 2.1.安装 使用pip进行安装. pip3 install pandas 导入pandas: import pandas as pd 下文使