Pandas爆炸函数的使用技巧
本文中记录的是如何使用pandas来实现hive中爆炸函数的功能
具体需求
统计每个员工的销售记录:
- 有作为销售员、跟单员、结单员的任意一种,即可说明参与了该订单的销售记录;
- 同一个订单中,一个员工参与多次只记为一次
爆炸函数到底实现的是什么功能呢?看图:
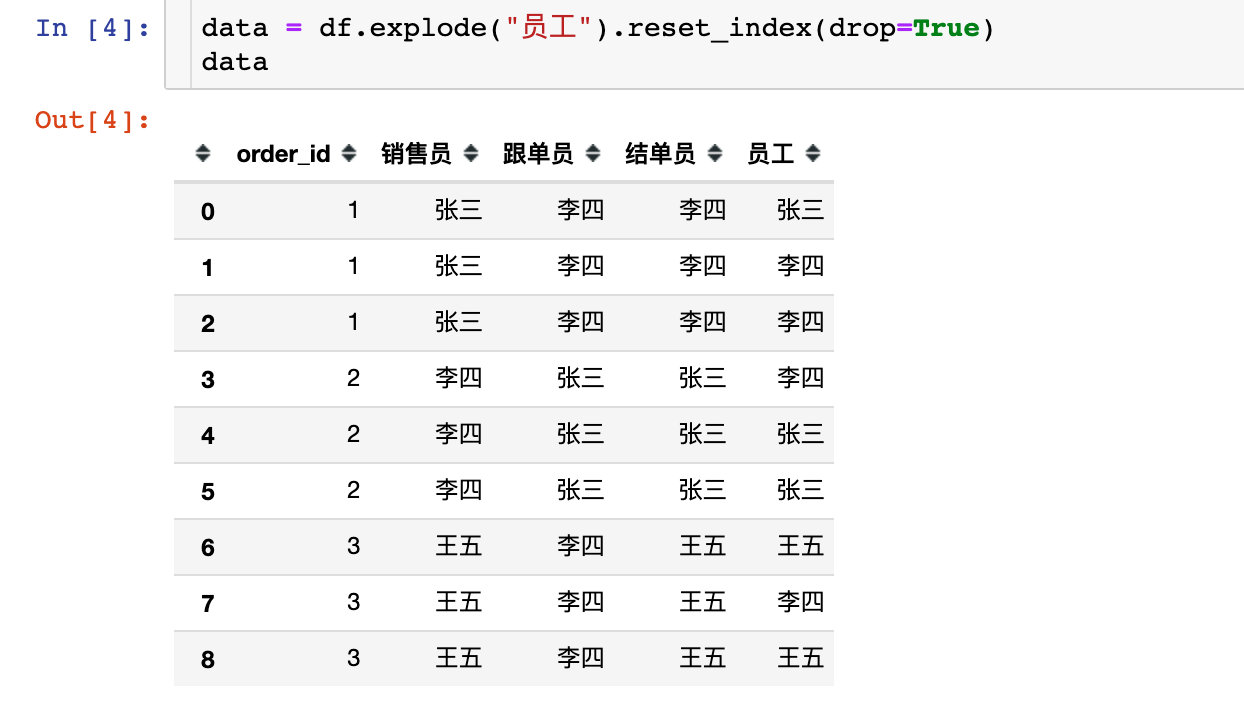
- 张三:参加了订单号1-销售员,订单号2-跟单员、结单员,数量2
- 李四:参加了订单号1-跟单员、结单员,订单2-销售员,订单号3-跟单员,数量3
- 王五:参加了订单号3-销售员、结单员,数量1

具体过程


至此,实现了爆炸函数的功能,如下:

到此这篇关于Pandas爆炸函数的使用技巧的文章就介绍到这了,更多相关Pandas爆炸函数内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Pandas DataFrame转换为字典的方法
该to_dict()方法将列名设置为字典键将"ID"列设置为索引然后转置DataFrame是实现此目的的一种方法.to_dict()还接受一个'orient'参数,您需要该参数才能输出每列的值列表.否则,{index: value}将为每列返回表单的字典. 可以使用以下行完成这些步骤: >>> df.set_index('ID').T.to_dict('list') {'p': [1, 3, 2], 'q': [4, 3, 2], 'r': [4, 0, 9]} 如果
-

教你使用Pandas直接核算Excel中快递费用
一.确定核算规则 二.根据核算规则编写代码,生成核算列 # -*- coding:utf-8 -*- import pandas as pd from math import ceil import os def account(adress,weight): if adress == "湖南": if weight <= 3: totel = 2.5 elif (weight >= 3) and (weight<=5): totel = 3.5 + ceil((we
-
解决python3安装pandas出错的问题
安装pandas出错: Running setup.py (path:/data/envs/py3/build/pandas/setup.py) egg_info for package pandas Traceback (most recent call last): File "<string>", line 17, in <module> File "/data/envs/py3/build/pandas/setup.py", line
-
pandas中DataFrame检测重复值的实现
本文详解如何使用pandas查看dataframe的重复数据,判断是否重复,以及如何去重 DataFrame.duplicated(subset=None, keep='first') subset:如果你认为几个字段重复,则数据重复,就把那几个字段以列表形式放到subset后面.默认是所有字段重复为重复数据. keep: 默认为'first' ,也就是如果有重复数据,则第一条出现的定义为False,后面的重复数据为True. 如果为'last',也就是如果有重复数据,则最后一条出现的定义为Fa
-
使用pandas或numpy处理数据中的空值(np.isnan()/pd.isnull())
最近在做数据处理的时候,遇到个让我欲仙欲死的问题,那就是数据中的空值该如何获取. 我的目的本来是获取数据中的所有非零且非空值,然后再计算获得到的所有数据计算均值,再用均值把0和空值填上.这个操作让我意识到了i is None/np.isnan(i)/i.isnull()之间的差别,再此做简单介绍: 1.关于np.nan: 先明确一个问题,即空值的产生只有np.nan()一种方法. # np.nan()的一些奇妙性质: np.nan == np.nan >>> False np.isnan
-
教你漂亮打印Pandas DataFrames和Series
一.前言 当我们必须处理可能有多个列和行的大型DataFrames时,能够以可读格式显示数据是很重要的.这在调试代码时非常有用. 默认情况下,当打印出DataFrame且具有相当多的列时,仅列的子集显示到标准输出. 显示的列甚至可以多行打印出来. 二.问题 假设我们有以下DataFrame: import pandas as pd import numpy as np df = pd.DataFrame( np.random.randint(0, 100, size=(100, 25)), co
-
pandas DataFrame.shift()函数的具体使用
pandas DataFrame.shift()函数可以把数据移动指定的位数 period参数指定移动的步幅,可以为正为负.axis指定移动的轴,1为行,0为列. eg: 有这样一个DataFrame数据: import pandas as pd data1 = pd.DataFrame({ 'a': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9], 'b': [9, 8, 7, 6, 5, 4, 3, 2, 1, 0] }) print data1 a b 0 0 9 1 1 8
-
Pandas||过滤缺失数据||pd.dropna()函数的用法说明
看代码吧~ DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False) Remove missing values. pd.dropna()函数(官方文档)用于过滤数据中的缺失数据. 缺失数据在pandas中用NaN标记. import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(5, 3), index = lis
-
pandas取dataframe特定行列的实现方法
1.按列取.按索引/行取.按特定行列取 import numpy as np from pandas import DataFrame import pandas as pd df=DataFrame(np.arange(12).reshape((3,4)),index=['one','two','thr'],columns=list('abcd')) df['a']#取a列 df[['a','b']]#取a.b列 #ix可以用数字索引,也可以用index和column索引 df.ix[0]#取
-
利用python Pandas实现批量拆分Excel与合并Excel
一.实例演示 1.将一个大Excel等份拆成多个Excel 2.将多个小Excel合并成一个大Excel并标记来源 work_dir="./course_datas/c15_excel_split_merge" splits_dir=f"{work_dir}/splits" import os if not os.path.exists(splits_dir): os.mkdir(splits_dir) 二.读取源Excel到Pandas import pandas