python3 解决requests出错重试的问题
对python3下的requests使用并不是很熟练,今天稍微用了下,请求几次下来后发现出现连接超时的异常,上网查了下,找到了一个还算中肯的解决方法。
retrying是python的一个自带的重试包
导入方式:
from retrying import retry
简单使用
retrying 这个包的用法原理就是在你不知道那段代码块是否会发生异常,若发生异常,可以再次执行该段的代码块,如果没有发生异常,那么就继续执行往下执行代码块
以前你的代码可能是这样写的:
def get_html(url): pass def log_error(url): pass url = "" try: get_page(url) except: log_error(url)
也有可能是这样子写的:
# 请求超过十次就放弃 attempts = 0 success = False while attempts < 10 and not success: try: get_html(url) success = True except: attempts += 1 if attempts == 10: break
使用 retrying 的写法:
import random
from retrying import retry
@retry()
def do_something_unreliable():
if random.randint(0, 10) > 1:
raise IOError("Broken sauce, everything is hosed!!!111one")
else:
return "Awesome sauce!"
result = do_something_unreliable()
print(result)
上面的是简单的用法,你可以试下,下面是一些可选参数的使用方式。
stop_max_attempt_number
用来设定最大的尝试次数,超过该次数就停止重试
stop_max_delay
超过时间段,函数就不会再执行了
wait_random_min和wait_random_max
用随机的方式产生两次retrying之间的停留时间
补充:python中Requests的重试机制
requests原生支持
import requests
from requests.adapters import HTTPAdapter
s = requests.Session()
# 重试次数为3
s.mount('http://', HTTPAdapter(max_retries=3))
s.mount('https://', HTTPAdapter(max_retries=3))
# 超时时间为5s
s.get('http://example.com', timeout=5)
requests使用的重试算法:BackOff(指数退避算法)
什么是指数退避算法
在wiki当中对指数退避算法的介绍是:
In a variety of computer networks, binary exponential backoff or truncated binary exponential backoff refers to an algorithm used to space out repeated retransmissions of the same block of data, often as part of network congestion avoidance.
翻译成中文的意思大概是“在各种的计算机网络中,二进制指数后退或是截断的二进制指数后退使用于一种隔离同一数据块重复传输的算法,常常做为网络避免冲突的一部分”
比如说在我们的服务调用过程中发生了调用失败,系统要对失败的资源进行重试,那么这个重试的时间如何把握,使用指数退避算法我们可以在某一范围内随机对失败的资源发起重试,并且随着失败次数的增加长,重试时间也会随着指数的增加而增加。
当然,指数退避算法并没有人上面说的那么简单,想具体了解的可以具体wiki上的介绍
当系统每次调用失败的时候,我们都会产生一个新的集合,集合的内容是0~2n-1,n代表调用失败的次数
第一次失败 集合为 0,1
第二次失败 集合为 0,1,2,3
第三次失败 集合为 0,1,2,3,4,5,6,7
在集合中随机选出一个值记为R,下次重试时间就是R*基本退避时间(对应在指数退避算法中争用期) 当然,为了防止系统无限的重试下去,我们会指数重新的最大次数
为什么要使用指数退避算法
使用指数退避算法,可以防止连续的失败,从某方面讲也可以减轻失败服务的压力,试想一下,如果一个服务提供者的服务在某一时间发生了异常、超时或是网络抖动,那么频繁的重试所得到的结果也大致都是失败。这样的频繁的重试不仅没有效果,反而还会增服务的负担。
应用场景有哪些
接入三方支付服务,在三方支付提供的接入接口规范中,服务方交易结束结果通知和商户主动查询交易结果都用到重发机制
在app应用中,很多场景会遇到轮询一类的问题,轮询对于app性能和电量的消耗都过大。
代码示例
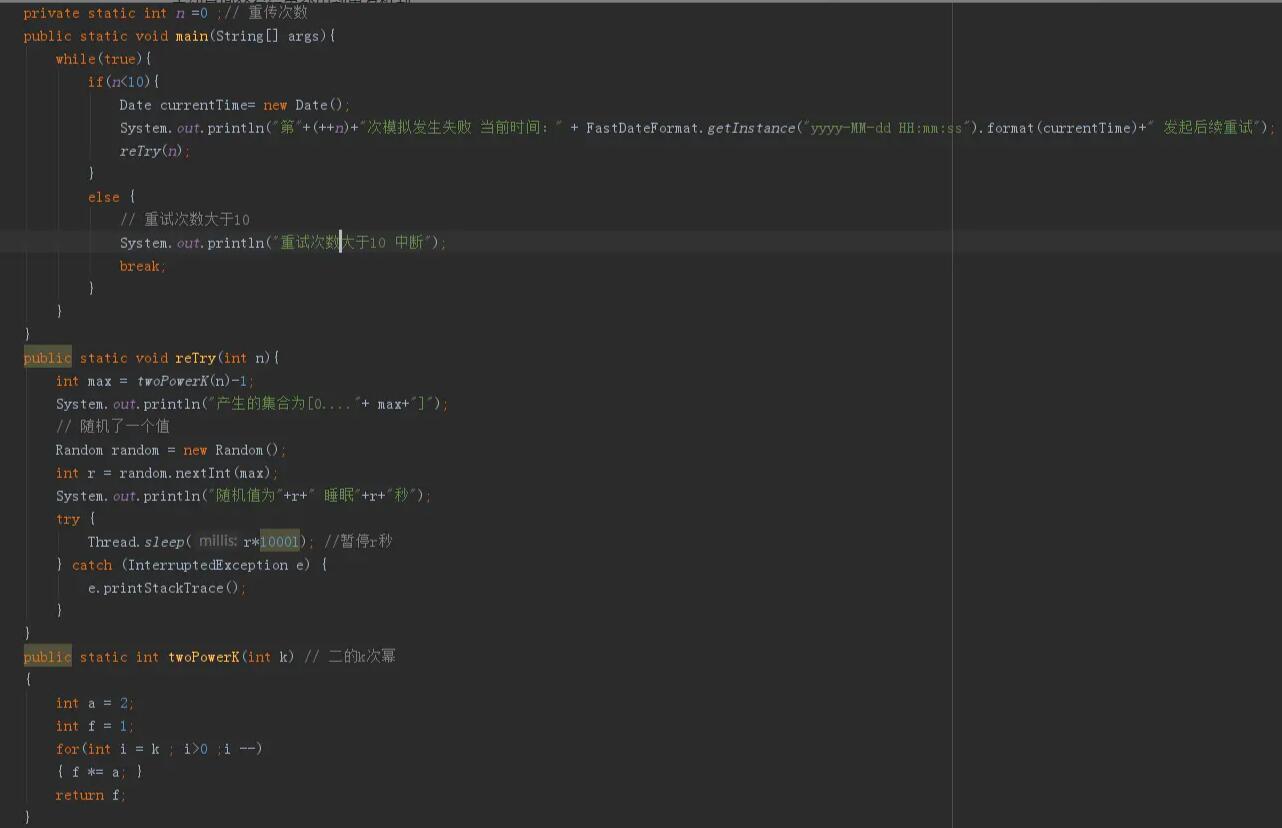

以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-

python软件测试Jmeter性能测试JDBC Request(结合数据库)的使用详解
JDBC Request 这个 Sampler 可以向数据库发送一个 jdbc 请求(sql 语句),并获取返回的数据库数据进行操作.它 经常需要和 JDBC Connection Configuration 配置原件(配置数据库连接的相关属性,如连接名.密码 等)一起使用. 1.本文使用的是 mysql 数据库进行测试 数据库的用户名为 root,用户名密码为 *********(看个人数据库用户名和密码填写) 2.数据库中有表:test,表的数据结构如下: 表中数据如下: select *
-
python爬虫之利用Selenium+Requests爬取拉勾网
一.前言 利用selenium+requests访问页面爬取拉勾网招聘信息 二.分析url 观察页面可知,页面数据属于动态加载 所以现在我们通过抓包工具,获取数据包 观察其url和参数 url="https://www.lagou.com/jobs/positionAjax.json?px=default&needAddtionalResult=false" 参数: city=%E5%8C%97%E4%BA%AC ==>城市 first=true ==>无用 pn=
-
python 实现Requests发送带cookies的请求
一.缘 起 最近学习[悠悠课堂]的接口自动化教程,文中提到Requests发送带cookies请求的方法,笔者随之也将其用于手头实际项目中,大致如下 二.背 景 实际需求是监控平台侧下发消息有无异常,如有异常便触发报警推送邮件,项目中下发消息接口需要带cookies 三.说 明 脚本的工程名为ynJxhdSendMsg,大致结构如下图 sendMsg.py为主程序,函数checkMsg为在已发消息列表中查找已下发消息,函数sendMsg为发消息并根据结果返回对应的标识 sendAlertEmai
-
python实现文件+参数发送request的实例代码
需求: 该接口,含两个参数,一个是file,一个是paperName.其中file为上传的文件.content-type为form-data. 根据python中的request源代码,可知,发送一个request,可以传递的参数有很多.而我们这次主要用到的就是files,当然method.url.headers.及data/json也是每次发送request必备的. 主要的实现方式: # 用二进制的方式打开需上传的文件. f = open(filename, "rb") file =
-
Python requests库参数提交的注意事项总结
字典与json字符串区别 # python 中的字典格式,是dict类型 {'a': 'sd'} 如果声明a = {"a": "sd"},它仍是字典,不过python会默认将双引号换成单引号,最后打印的仍然为{'a': 'sd'} # python 中的json字符串,是str类型 {"a": "sd"} 两者差别在于引号 在爬虫的过程中有些请求参数是json字符串的,有的是字典类型的,要区分json字符串和字典 json字符
-
python+requests+pytest接口自动化的实现示例
1.发送get请求 #导包 import requests #定义一个url url = "http://xxxxxxx" #传递参数 payload="{\"head\":{\"accessToken\":\"\",\"lastnotice\":0,\"msgid\":\"\"},\"body\":{\"user_name\&
-
requests在python中发送请求的实例讲解
当我们想给服务器发送一些请求时,可以选择requests库来实现.相较于其它库而言,这种库的使用还是非常适合新手使用的.本篇要讲的是requests.get请求方法,这里需要先对get请求时的一些参数进行学习,在掌握了基本的用法后,可以就下面的requests.get请求实例进一步的探究. 1.get请求的部分参数 (1) url(请求的url地址,必需 ) import requests url="http://www.baidu.com" resp=requests.get(url
-
Python requests timeout的设置
背景 最近在搞爬虫,很多小组件里面都使用了 Python 的 requests 库,很好用,很强大. 但最近发现很多任务总是莫名其妙的卡住,不报错,但是就是不继续执行. 排查了一圈,最后把问题锁定在 requests 的 timeout 机制上. 注:本文讨论的是 Python 的第三方模块 requests,并不是 Python 内建模块 urllib 中的 request 模块,请注意区分. 如何设置超时时间 requests 设置超时时间有两种方式. 一种是设置单一值作为 timeout,
-
Python爬虫基础之requestes模块
一.爬虫的流程 开始学习爬虫,我们必须了解爬虫的流程框架.在我看来爬虫的流程大概就是三步,即不论我们爬取的是什么数据,总是可以把爬虫的流程归纳总结为这三步: 1.指定 url,可以简单的理解为指定要爬取的网址 2.发送请求.requests 模块的请求一般为 get 和 post 3.将爬取的数据存储 二.requests模块的导入 因为 requests 模块属于外部库,所以需要我们自己导入库 导入的步骤: 1.右键Windows图标 2.点击"运行" 3.输入"cmd&q
-
python requests库的使用
requests模块 使用requests可以模拟浏览器的请求,requests模块的本质是封装了urllib3模块的功能,比起之前用到的urllib,requests模块的api更加便捷 requests库发送请求将网页内容下载下来以后,并不会执行js代码,这需要我们自己分析目标站点然后发起新的request请求,但是selenium模块就可以执行js的操作. 安装: pip3 install requests 请求方式:主要用到的就get和post两种 #各种请求方式:常用的就是reques
-
python requests完成接口文件上传的案例
最近在准备一个公开课,主题就是利用不同的语言和不同的工具去实现文件的上传和下载. 在利用Jmeter去实现功能的时候,以及利用loadrunner去写脚本的时候,都很顺利,没有任何问题,当我尝试用Python去解决这个问题的时候,花了一些时间. 这也让我在学习和尝试中,找到了很多乐趣,下面给大家分享下,如何去实现操作. 前提: 1:有一个上传接口,地址如下:http://xx.xx.xx.xx//upload/stream(公司的服务,地址不便外发~有兴趣的同志可以来看我们的公开课!) 2:上传
-
python urllib.request模块的使用详解
python的urllib模块提供了一系列操作url的功能,可以让我们通过url打开任意资源.其中比较常用的就是request模块,本篇主要介绍requset模块. urllib子模块 urllib.request 打开或请求url urllib.error 捕获处理请求时产生的异常 urllib.parse 解析url urllib.robotparser 用于解析robots.txt文件 robots.txt是一种存放于网站根目录下文本文件,用来告诉网络爬虫服务器上的那些文件可以被查看.又被
-
python爬取豆瓣电影排行榜(requests)的示例代码
''' 爬取豆瓣电影排行榜 设计思路: 1.先获取电影类型的名字以及特有的编号 2.将编号向ajax发送get请求获取想要的数据 3.将数据存放进excel表格中 ''' 环境部署: 软件安装: Python 3.7.6 官网地址:https://www.python.org/ 安装地址:https://www.python.org/ftp/python/3.7.6/python-3.7.6-amd64.exe PyCharm 2020.2.2