pytorch model.cuda()花费时间很长的解决
解决方法之一:
如果pytorch在进行model.cuda()操作需要花费的时间很长,长到你怀疑GPU的速度了,那就是不正常的。
如果你用的pytorch版本是0.3.0,升级到0.3.1就好了!
.cuda()加载时间很长的其他解决方法
方法一:
pip install --upgrade --force-reinstall http://download.pytorch.org/whl/cu80/torch-0.2.0.post3-cp27-cp27mu-manylinux1_x86_64.whl
后面这个可以自己到官网上找自己对应的python和cuda版本的安装包,
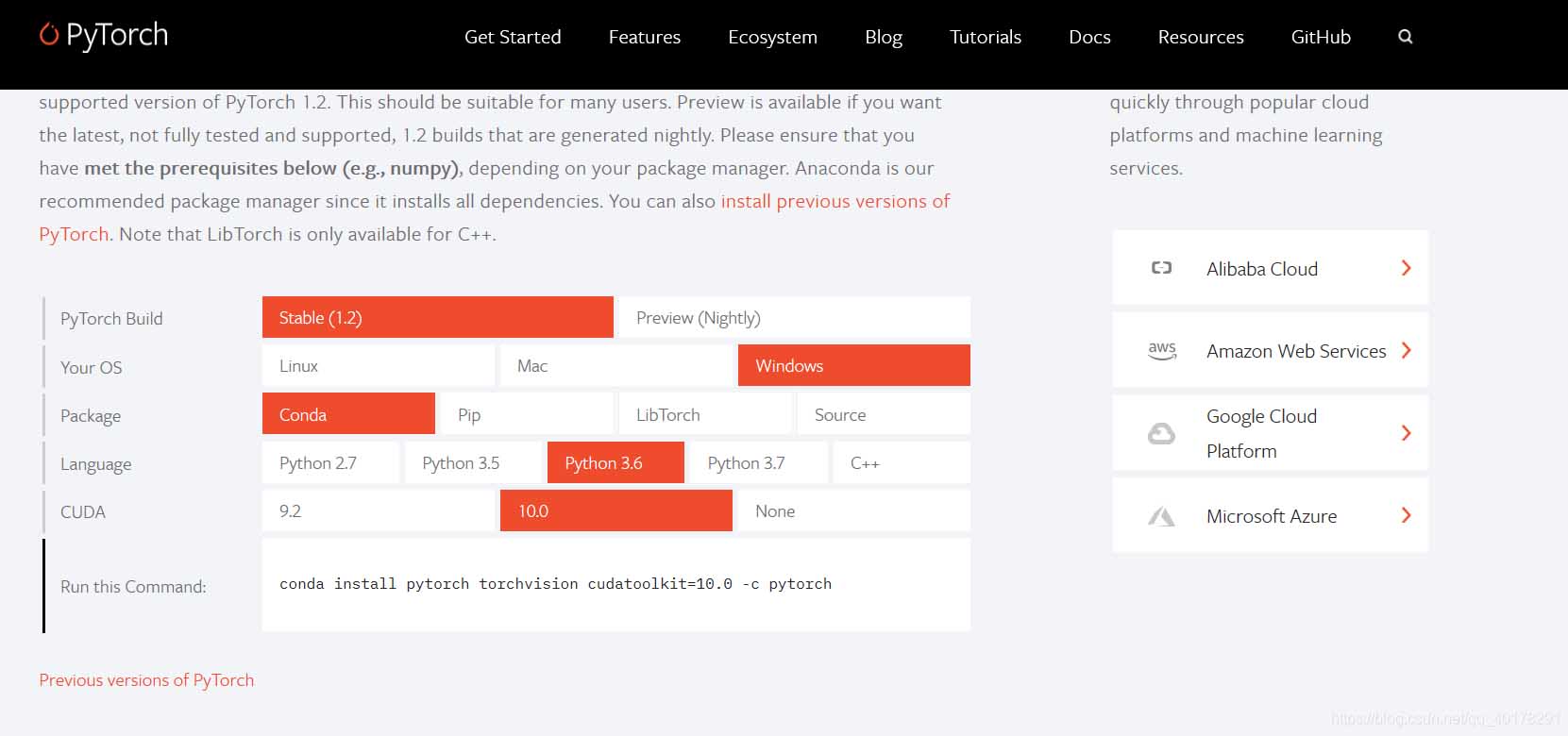
方法二:
conda install pytorch torchvision cuda80 -c soumith
这里可以根据自己cuda版本确定。查看cuda版本,在python命令行里面输入:
import torch torch.version.cuda
即可。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
pytorch 如何用cuda处理数据
1 设置GPU的一些操作 设置在os端哪些GPU可见,如果不可见,那肯定是不能够调用的~ import os GPU = '0,1,2' os.environ['CUDA_VISIBLE_DEVICES'] =GPU torch.cuda.is_available()查看cuda是否可用. if torch.cuda.is_available(): torch.backends.cudnn.benchmark = True ''' 如果网络的输入数据维度或类型上变化不大,设置 torch.bac
-
将pytorch的网络等转移到cuda
神经网络一般用GPU来跑,我们的神经网络框架一般也都安装的GPU版本,本文就简单记录一下GPU使用的编写. GPU的设置不在model,而是在Train的初始化上. 第一步是查看是否可以使用GPU self.GPU_IN_USE = torch.cuda.is_available() 就是返回这个可不可以用GPU的函数,当你的pytorch是cpu版本的时候,他就会返回False. 然后是: self.device = torch.device('cuda' if self.GPU_IN_USE
-

PyTorch CUDA环境配置及安装的步骤(图文教程)
Pytorch版本介绍 torch:1.6 CUDA:10.2 cuDNN:8.1.0 ✨安装 NVIDIA 显卡驱动程序 一般 电脑出厂/装完系统 会自动安装显卡驱动 如果有 可直接进行下一步 下载链接 http://www.nvidia.cn/Download/index.aspx?lang=cn 选择和自己显卡相匹配的显卡驱动 下载安装 ✨确认项目所需torch版本 # pip install -r requirements.txt # base ---------------------
-
Linux安装Pytorch1.8GPU(CUDA11.1)的实现
先说下自己之前的环境(都是Linux系统,差别不大): Centos7.6 NVIDIA Driver Version 440.33.01(等会需要更新驱动) CUDA10.1 Pytorch1.6/1.7 提示,如果想要保留之前的PyTorch1.6或1.7的环境,请不要卸载CUDA环境,可以通过Anaconda管理不同的环境,互不影响.但是需要注意你的NVIDIA驱动版本是否匹配. 在这里能够看到官方给的对应CUDA版本所需使用驱动版本. 通过上表可以发现,如果要使用CUDA11.1,那么需
-
pytorch中.to(device) 和.cuda()的区别说明
原理 .to(device) 可以指定CPU 或者GPU device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 单GPU或者CPU model.to(device) #如果是多GPU if torch.cuda.device_count() > 1: model = nn.DataParallel(model,device_ids=[0,1,2]) model.to(
-
pytorch model.cuda()花费时间很长的解决
解决方法之一: 如果pytorch在进行model.cuda()操作需要花费的时间很长,长到你怀疑GPU的速度了,那就是不正常的. 如果你用的pytorch版本是0.3.0,升级到0.3.1就好了! .cuda()加载时间很长的其他解决方法 方法一: pip install --upgrade --force-reinstall http://download.pytorch.org/whl/cu80/torch-0.2.0.post3-cp27-cp27mu-manylinux1_x86_64
-
解决idea中svn提交时performing vcs refresh时间很长的问题
出现场景:idea软件重装了一次,项目空间是沿用原来的,所有的项目配置也是之前的,导致svn提交异常缓慢. 1.解决方案:重新建立工作区间project 将svnd的项目导出来,并且配置好项目运行环境 再次提交代码到svn就不卡了 2.将设置的值设为300 3.设置一下这里 重启idea,再次提交到svn 亲测有效!!!! 补充知识:idea使用svn(日常使用) 本文记录了svn的日常使用!!!非常详细!!!持续更新- 更新svn的项目到本地(一般是先更新再进行提交) 选择你的svn(服务器)
-
Apache Spark 2.0 在作业完成时却花费很长时间结束
现象 大家在使用 Apache Spark 2.x 的时候可能会遇到这种现象:虽然我们的 Spark Jobs 已经全部完成了,但是我们的程序却还在执行.比如我们使用 Spark SQL 去执行一些 SQL,这个 SQL 在最后生成了大量的文件.然后我们可以看到,这个 SQL 所有的 Spark Jobs 其实已经运行完成了,但是这个查询语句还在运行.通过日志,我们可以看到 driver 节点正在一个一个地将 tasks 生成的文件移动到最终表的目录下面,当我们作业生成的文件很多的情况下,就很容
-
pytorch 运行一段时间后出现GPU OOM的问题
pytorch的dataloader会将数据传到GPU上,这个过程GPU的mem占用会逐渐增加,为了避免GPUmen被无用的数据占用,可以在每个step后用del删除一些变量,也可以使用torch.cuda.empty_cache()释放显存: del targets, input_k, input_mask torch.cuda.empty_cache() 这时能观察到GPU的显存一直在动态变化. 但是上述方式不是一个根本的解决方案,因为他受到峰值的影响很大.比如某个batch的数据量明显大于
-
pytorch:model.train和model.eval用法及区别详解
使用PyTorch进行训练和测试时一定注意要把实例化的model指定train/eval,eval()时,框架会自动把BN和DropOut固定住,不会取平均,而是用训练好的值,不然的话,一旦test的batch_size过小,很容易就会被BN层导致生成图片颜色失真极大!!!!!! Class Inpaint_Network() ...... Model = Inpaint_Nerwoek() #train: Model.train(mode=True) ..... #test: Model.ev
-
pytorch 查看cuda 版本方式
由于pytorch的whl 安装包名字都一样,所以我们很难区分到底是基于cuda 的哪个版本. 有一条指令可以查看 import torch print(torch.version.cuda) 补充知识:pytorch:网络定义参数的时候后面不能加".cuda()" pytorch定义网络__init__()的时候,参数不能加"cuda()", 不然参数不包含在state_dict()中,比如下面这种写法是错误的 self.W1 = nn.Parameter(tor
-
pytorch的Backward过程用时太长问题及解决
目录 pytorch Backward过程用时太长 问题描述 解决方案 Pytorch backward()简单理解 有几个重要的点 总结 pytorch Backward过程用时太长 问题描述 使用pytorch对网络进行训练的时候遇到一个问题,forward阶段很快(只需要几毫秒),backward阶段却用时很长(需要十多秒). 导致这个问题的原因很容易被大家忽视,而且网上基本上没有直接的解决方案,经过一天的折腾,总算把导致这个问题的原因搞清楚了. 解决方案 导致这个问题的原因在于训练数据的
-
C#计算程序执行过程花费时间的方法
本文实例讲述了C#计算程序执行过程花费时间的方法.分享给大家供大家参考.具体如下: 计算执行完程序花费的时间: void AddInfo() { System.Diagnostics.Stopwatch sw = new System.Diagnostics.Stopwatch(); sw.Start(); for (int i = 0; i < 1000; i++) { Console.WriteLine(i.ToString()); System.Threading.Thread.Sleep
-
浅谈pytorch、cuda、python的版本对齐问题
在使用深度学习模型训练的过程中,工具的准备也算是一个良好的开端吧.熟话说完事开头难,磨刀不误砍柴工,先把前期的问题搞通了,能为后期节省不少精力. 以pytorch工具为例: pytorch版本为1.0.1,自带python版本为3.6.2 服务器上GPU的CUDA_VERSION=9000 注意:由于GPU上的CUDA_VERSION为9000,所以至少要安装cuda版本>=9.0,虽然cuda=7.0~8.0也能跑,但是一开始可能会遇到各种各样的问题,本人cuda版本为10.0,安装cuda的
-
android studio错误: 常量字符串过长的解决方式
android studio 错误: 常量字符串过长错误 省市区三级联动,位置字符串. 这样不行 改用json方案 ,读取array中文件 String provsData = new GetJsonDataUtil().getJson(activity, "provsData.json");//获取assets目录下的json文件数据 String distsData = new GetJsonDataUtil().getJson(activity, "distsData.