Python计算双重差分模型DID及其对应P值使用详解
目录
- 1. DID(Differences-in-Differences)定义
- 2. DID模型形式
- 3. OLS多项式拟合
1. DID(Differences-in-Differences)定义
双重差分法,其主要被用于社会学中的政策效果评估。这种方法需要两个「差异」数据。一个是干预前后的「差异」,这个是自身实验前后的差异。另外一个是干预组与对照组的「差异」。DID利用这两个「差异」的差异来推算干预的效果。因此,顾名思义叫做双重差分法。
其原理是基于一个反事实的框架来评估政策发生和不发生这两种情况下被观测因素y的变化。如果一个外生的政策冲击将样本分为两组:受政策干预的Treat组和未受政策干预的Control组(在政策冲击前,Treat组和Control组的y没有显著差异)。那么,可以将Control组在政策发生前后y的变化看作Treat组未受政策冲击时的状况(反事实的结果)。通过比较Treat组y的变化(D1)以及Control组y的变化(D2),就可以得到政策冲击的实际效果(DD=D1-D2)。
注意:只有在满足“政策冲击前Treat组和Control组的y没有显著差异”(即平行性假定)的条件下,得到的双重差分估计量才是无偏的。
如下图所示:
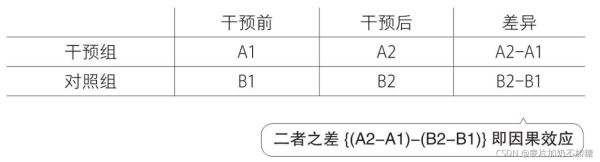
干预组实验前为A1,实验后为A2。对照组实验前为B1,实验后为B2。对于干预组实验前后差异为A2-A1,对于对照组实验后为B2-B1。两者之差(A2-A1)-(B2-B1)即为DID结果,因果效应/处理效应。如下图处理效应所代表的部分。

2. DID模型形式

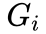 为分组虚拟变量(处理组=1,控制组=0);
为分组虚拟变量(处理组=1,控制组=0);
 为分期虚拟变量(政策实施后=1,政策实施前=0);
为分期虚拟变量(政策实施后=1,政策实施前=0);
交互项  表示处理组在政策实施后的效应,其系数即为双重差分模型重点考察的处理效应。
表示处理组在政策实施后的效应,其系数即为双重差分模型重点考察的处理效应。
3. OLS多项式拟合
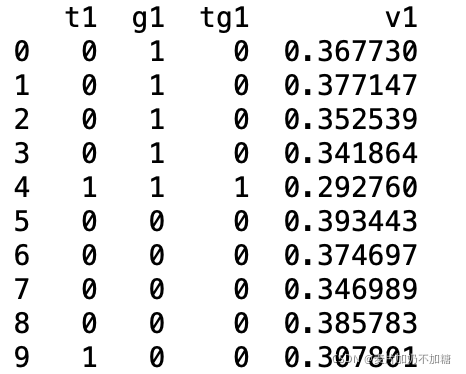
根据DID公式,我们可以通过使用多项式拟合的方法来求得DID及其P值。以下为Pyhton方法:使用statsmodels库中ols方法,需要根据上述公式准备数据,t代表时间(干预前=0,干预后=1)、g代表分组(干预组=1,对照组=0)、还有一个是交叉项tg(计算其t*g即可)。
代码如下:
import statsmodels.formula.api as smf
import pandas as pd
v1 =[0.367730,0.377147,0.352539,0.341864,0.29276,0.393443,0.374697,0.346989,0.385783,0.307801]
t1 = [0,0,0,0,1,0,0,0,0,1]
g1 =[1,1,1,1,1,0,0,0,0,0]
tg1 = [0,0,0,0,1,0,0,0,0,0]
aa = pd.DataFrame({'t1':t1,'g1':g1,'tg1':tg1,'v1':v1})
X = aa[['t1', 'g1','tg1']]
y = aa['v1']
est = smf.ols(formula='v1 ~ t1 + g1 + tg1', data=aa).fit()
y_pred = est.predict(X)
aa['v1_pred'] = y_pred
print(aa)
print(est.summary())
print(est.params)
准备数据格式如下:
OLS结果Summary如下:
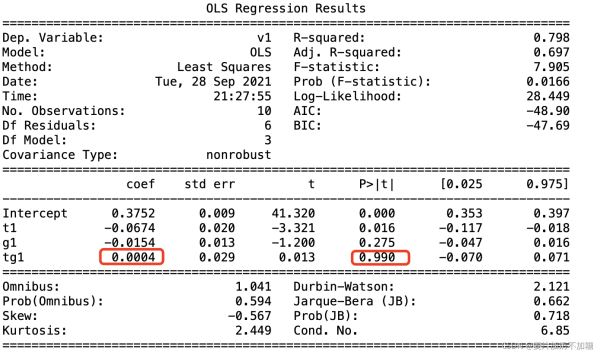
交叉项的系数就是DID结果,处理效应。P>| t |为其P值,小于0.05表示差异显著。
参考资料:
2. 什么是双重差分模型(:difference-in-differences model)? - 知乎
3. Python 普通最小二乘法(OLS)进行多项式拟合的方法
以上就是Python计算DID及其对应P值使用详解的详细内容,更多关于Python计算DID及对应P值的资料请关注我们其它相关文章!
相关推荐
-
Python 使用双重循环打印图形菱形操作
如下所示: a = int(input("请输入菱形行数:")) m = a #空格 d = a #倒三角 for i in range(1, a + 1): # 先打印正三角 print(" " * (m - 1), "*" * (2 * i - 1)) #2个*参数: 第一个是:空格 第二个是: *根据规律组成 m -= 1 if i == a: # 临界点,开始打印倒三角 for y in range(1, a): print("
-
Python使用pandas对数据进行差分运算的方法
如下所示: >>> import pandas as pd >>> import numpy as np # 生成模拟数据 >>> df = pd.DataFrame({'a':np.random.randint(1, 100, 10),\ 'b':np.random.randint(1, 100, 10)},\ index=map(str, range(10))) >>> df a b 0 21
-
python实现差分隐私Laplace机制详解
Laplace分布定义: 下面先给出Laplace分布实现代码: import matplotlib.pyplot as plt import numpy as np def laplace_function(x,beta): result = (1/(2*beta)) * np.e**(-1*(np.abs(x)/beta)) return result #在-5到5之间等间隔的取10000个数 x = np.linspace(-5,5,10000) y1 = [laplace_functio
-

Python计算双重差分模型DID及其对应P值使用详解
目录 1. DID(Differences-in-Differences)定义 2. DID模型形式 3. OLS多项式拟合 1. DID(Differences-in-Differences)定义 双重差分法,其主要被用于社会学中的政策效果评估.这种方法需要两个「差异」数据.一个是干预前后的「差异」,这个是自身实验前后的差异.另外一个是干预组与对照组的「差异」.DID利用这两个「差异」的差异来推算干预的效果.因此,顾名思义叫做双重差分法. 其原理是基于一个反事实的框架来评估政策发生和不发生这两
-
基于python计算滚动方差(标准差)talib和pd.rolling函数差异详解
我就废话不多说了,大家还是直接看代码吧! # -*- coding: utf-8 -*- """ Created on Thu Apr 12 11:23:46 2018 @author: henbile """ #计算滚动波动率可以使用专门做技术分析的talib包里面的函数,也可以使用pandas包里面的滚动函数. #但是两个函数对于分母的选择,就是使用N还是N-1作为分母这件事情上是有分歧的. #另一个差异在于:talib包计算基于numpy,
-
Python机器学习pytorch模型选择及欠拟合和过拟合详解
目录 训练误差和泛化误差 模型复杂性 模型选择 验证集 K折交叉验证 欠拟合还是过拟合? 模型复杂性 数据集大小 训练误差和泛化误差 训练误差是指,我们的模型在训练数据集上计算得到的误差. 泛化误差是指,我们将模型应用在同样从原始样本的分布中抽取的无限多的数据样本时,我们模型误差的期望. 在实际中,我们只能通过将模型应用于一个独立的测试集来估计泛化误差,该测试集由随机选取的.未曾在训练集中出现的数据样本构成. 模型复杂性 在本节中将重点介绍几个倾向于影响模型泛化的因素: 可调整参数的数量.当可调
-
用Python从0开始实现一个中文拼音输入法的思路详解
众所周知,中文输入法是一个历史悠久的问题,但也实在是个繁琐的活,不知道这是不是网上很少有人分享中文拼音输入法的原因,接着这次NLP Project的机会,我觉得实现一发中文拼音输入法,看看水有多深,结果发现还挺深的,但是基本效果还是能出来的,而且看别的组都做得挺好的,这次就分 享一下我们做的结果吧. (注:此文假设读者已经具备一些隐马尔可夫模型的知识) 任务描述 实现一个中文拼音输入法. 经过分析,分为以下几个模块来对中文拼音输入法进行实现: 核心功能包括拼音切分(SplitPinyin.py)
-
Python实现K-means聚类算法并可视化生成动图步骤详解
K-means算法介绍 简单来说,K-means算法是一种无监督算法,不需要事先对数据集打上标签,即ground-truth,也可以对数据集进行分类,并且可以指定类别数目 牧师-村民模型 K-means 有一个著名的解释:牧师-村民模型: 有四个牧师去郊区布道,一开始牧师们随意选了几个布道点,并且把这几个布道点的情况公告给了郊区所有的村民,于是每个村民到离自己家最近的布道点去听课. 听课之后,大家觉得距离太远了,于是每个牧师统计了一下自己的课上所有的村民的地址,搬到了所有地址的中心地带,并且在海
-
python简单几步获取各种DOS命令显示的内容详解流程
我们经常在C/C++中用"system("pause");"作暂停语句外,还有很多可以用system()调用,比如以下这些dos命令的功能也很不错: system("title C++颜色设置程序"); //设置控制台窗口的标题,即cmd.exe的标题 system("mode con cols=64 lines=25"); //设置窗口宽度高度 system("date /t"); //显示日期 syst
-
python四则运算表达式求值示例详解
目录 四则运算表达式求值 思路说明 算法步骤 代码 四则运算表达式求值 思路说明 使用双栈来实现——存放数值的栈 nums 与存放运算符的栈 ops. 算法步骤 对原始表达式字符串 exp 进行预处理, 将其转为一个元素对应一个数值或运算符的列表 explist. 遍历 explist , 每个元素依次压入对应的栈中. 每次压入后, 判断当前两栈顶是否可进行乘除运算.栈顶可进行乘除运算的充要条件是, ops 栈顶为<*> ,</> 之一, 且 nums 中的元素比 ops 中的元素
-
python通过socket实现多个连接并实现ssh功能详解
一.前言 上一篇中我们已经知道了客户端通过socket来连接服务端,进行了一次数据传输,那如何实现客户端多次发生数据?而服务端接受多个客户端呢? 二.发送中文信息 在python3中,socket只能发送bytes类型的数据,bytes类型只能表示0-225的ASCII码的值,并不能表示中文,所以当我们需要发送中文时,需要使用到编码和解码. 客户端: import socket # 客户端 # 声明协议类型,同时生成socket对象 client = socket.socket() # clie
-
python爬虫系列Selenium定向爬取虎扑篮球图片详解
前言: 作为一名从小就看篮球的球迷,会经常逛虎扑篮球及湿乎乎等论坛,在论坛里面会存在很多精美图片,包括NBA球队.CBA明星.花边新闻.球鞋美女等等,如果一张张右键另存为的话真是手都点疼了.作为程序员还是写个程序来进行吧! 所以我通过Python+Selenium+正则表达式+urllib2进行海量图片爬取. 运行效果: http://photo.hupu.com/nba/tag/马刺 http://photo.hupu.com/nba/tag/陈露 源代码: # -*- coding: utf
-
python类的方法属性与方法属性的动态绑定代码详解
动态语言与静态语言有很多不同,最大的特性之一就是可以实现动态的对类和实例进行修改,在Python中,我们创建了一个类后可以对实例和类绑定心的方法或者属性,实现动态绑定. 最近在学习python,纯粹是自己的兴趣爱好,然而并没有系统地看python编程书籍,觉得上面描述过于繁琐,在网站找了一些学习的网站,发现廖雪峰老师的网站上面的学习资源很不错,而且言简意赅,提取了一些python中的重要的语法和案例.重要的是可以在线测试python的运行代码,缺点就是没有系统的看python的书籍,不能及时的将