解决PostgreSQL日志信息占用磁盘过大的问题
当PostgreSQL启用日志时,若postgresql.conf日志的相关参数还使用默认值的话磁盘很容易被撑爆.因此在启用了logging_collector参数时,需要对其它相关的参数进行调整.
系统默认参数如下
#log_destination = 'stderr' #日志格式,值为stderr, csvlog, syslog, and eventlog之一. logging_collector = on #启用日志 #log_directory = 'log' #日志文件存储目录 #log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log' #日志文件命名方,默认为每秒一个文件(postgresql-2017-10-18_231548.log) #log_file_mode = 0600 #日志文件权限 #log_truncate_on_rotation = off #是否截断日志文件
调整后的参数
log_destination = 'csvlog' #日志格式,值为stderr, csvlog, syslog, and eventlog之一. logging_collector = on #启用日志 log_directory = 'log' #日志文件存储目录 log_filename = 'postgresql-%j.log' #日志文件命名方式,最多保存一年的日志.同时要打开log_truncate_on_rotation,否则日志以追加的方式显示在后面. log_file_mode = 0600 #日志文件权限 log_truncate_on_rotation = on #是否截断日志文件
重点内容
log_destination = 'csvlog' log_filename = 'postgresql-%j.log' log_truncate_on_rotation = on
log_destination:建议设置为csvlog,以便将日志链接到PostgreSQL中查看.参看Error Reporting and Logging19.8.4. Using CSV-Format Log Output
log_filename :设置日志文件名,需结合log_truncate_on_rotation = on使用.可根据自己的需要调整, 例如:
log_filename = 'postgresql-%I.log' #最多保存12小时的日志,每小时一个文件 log_filename = 'postgresql-%H.log' #最多保存24小时的日志,每小时一个文件 log_filename = 'postgresql-%w.log' #最多保存一周的日志,每天一个文件 log_filename = 'postgresql-%d.log' #最多保存一个月的日志,每天一个文件 log_filename = 'postgresql-%j.log' #最多保存一年的日志,每天一个文件
补充:PostgreSQL 日志系统 及 设置错误导致磁盘塞满案例
今天早上偶然看到QQ 群里面有一个人,在问问题,问题不重要,主要是没有人回答, 然后这个人马上就用非常让人难以接受的词汇,问候了群里面没有回答他的一干人等, 其实我有点可怜他, 问一个问题没有人回答,就如此,你是经历了什么,让你连5分钟的耐心都没有, 每个人都有自己的生活轨迹, 不回答你是很正常的,
终究 nothing is impossible , right?
正文
在众多的数据库中,POSTGRESQL 的日志的系统的丰富度和日志的详细的程度,都是可圈可点的,在网上不少同学都在问各种POSTGRESQL的问题,其实这些问题都可以在日志中找到答案,或者提交一些日志给问题的解决者,提高问题的解决速度和问题的定位的准确度。
首先我们先从日志的详细度来入手,log_min_messages 定义了日志的详细程度,其实我们在选择上可能会有一些纠结,纠结点在error warning notice 这三种,大部分人可能在选择error ,出错就报错误,warning 也有相关选择,实际上选择不同的日志的详细度也是有相关的一些考虑
1 如果你对PG本身不熟悉,测试系统可以开启notice ,这样便于你去查看一些你不理解,的东西并快速的进行学习,如果是生产系统初始阶段可以开启warning 对系统的初始时期的一些问题,可能是配置上,或者系统级别的一些问题进行更深的理解,如果是稳定运行一段时间的系统则可以将其调整到 error 方面,降低一些不必要的日志的写入,对性能和空间都有帮助。
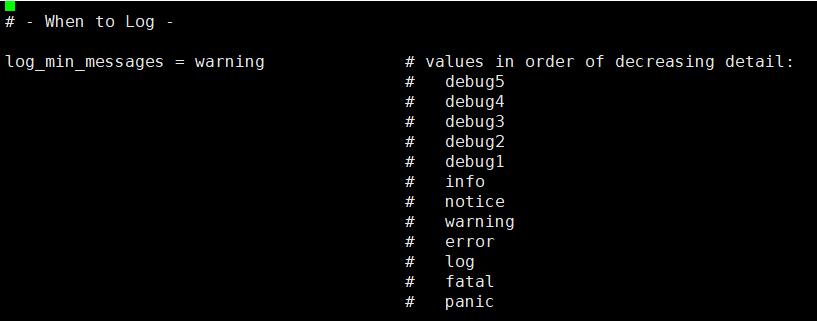
这里建议大家可以使用warning 来作为常规的日志的详细度的使用。
2 如果有人问,在语句执行的时候,我的语句被莫名其名的kill 了我怎么查出来。下面的 log_min_error_statment 设置的选择项就与其有关了,
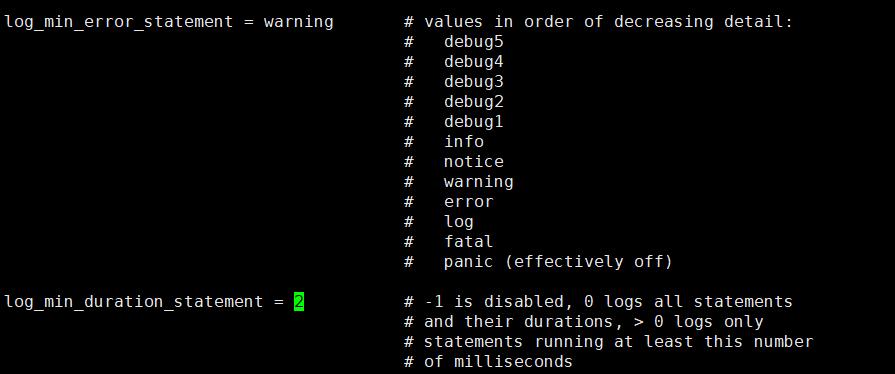
例如下面的错误
ERROR: current transaction is aborted, commands ignored until end of transaction block STATEMENT: SELECT * FROM mytable WHERE id = 1 FOR UPDATE;
log_min_duration_statement 是对应慢查询的日志,当设置的值大于0 后,则超过对应设置数字秒数的SQL 语句将被记录。
这里需要考虑你的系统是OLAP OR OLTP 的情况,如果设置为 1秒,但你的系统里面的SQL 语句经常要大于1秒,则你的日志中将大量充斥这样的SQL 导致你的日志变得非常大。
说到这个MYSQL的DB会觉得PG的日志太乱了,MYSQL的日志大部分是分开的,这样有利于日志的查看和分析。这里其实也建议PG是否可以考虑将日志分开,至少分为 SLOW LOG ERROR LOG SYSTEM LOG 等等。
当然说完不足,害的说优点,让其他数据库DB们羡慕的应该就是下面的选项,你不会在任何一个数据库中,找到如此丰富选择配置
1 log_checkpoint 对当前的checkpoint的操作进行记录,通过这个信息可以有两点
1 有相关的监控系统可以读这些信息,生成图标,让这些信息成为一个趋势图来对系统进行分析,并修正系统
2 也可以手工写python程序来收集信息,直接出报告或诊断

2 log_connections 用户的登陆信息
3 log_disconnections 用户的断开的登陆的信息
4 log_error_verbosity 记录信息的详细程度,默认default
5 log_hostname 默认记录信息中带有客户端的IP地址,不带有对方的机器名
6 log_line_prefix 相当于对日志的打印的格式和信息的设置,有些监控系统对此是有要求的,请按照你安装的监控系统的要求配置此栏
7 log_lock_waits 记录语句执行中的锁等待时间
8 log_statement 对于什么语句进行记录,(这个与上面的无关,有语句审计的时候可能需要打开这个开关,进行语句的收集,不建议使用all 否则对于系统的负担太重,相当于在MYSQL中开启genernal log)
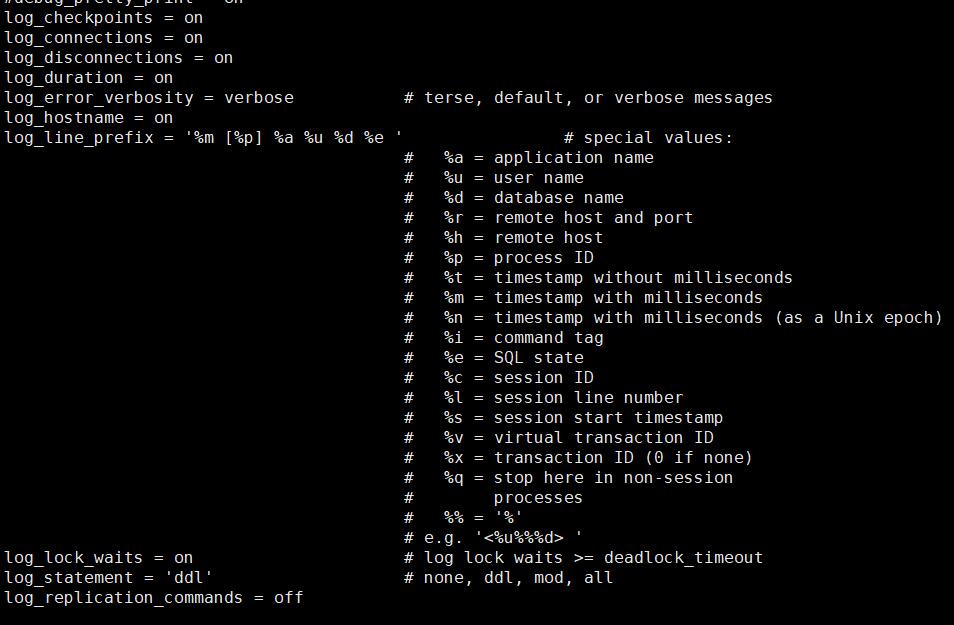
实际上很多人在操作POSTGERSQL开始的时候,是找不到日志的,因为默认PG的日志默认是不打开的,关键的参数在 logging_collector 默认是off,所以安装PG后的启动前的第一件事情就是要将这个设置变为ON ,好让PG从开始就开始记录日志。
另外日志的定期清理方面PG比其他的开源数据库要做到好多了,因为不少人都的自己写日志的rotate 和 clean up的脚本,PG 这里不需要,你只需要在 log_rotation_age中设置你要保留几天的日志,同时 log_truncate_on_rotation 设置为on 就可以了,这点是非常人性化的。或者你也可以根据日志的大小进行设置如何抛弃他。
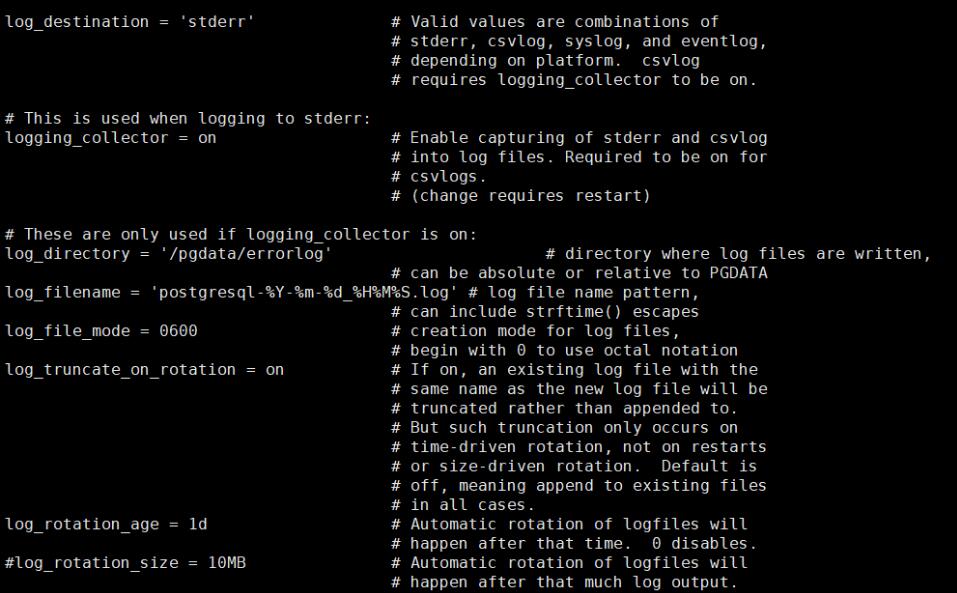
说完这些,我们来看看实际当中会遇到什么问题,以一个案例
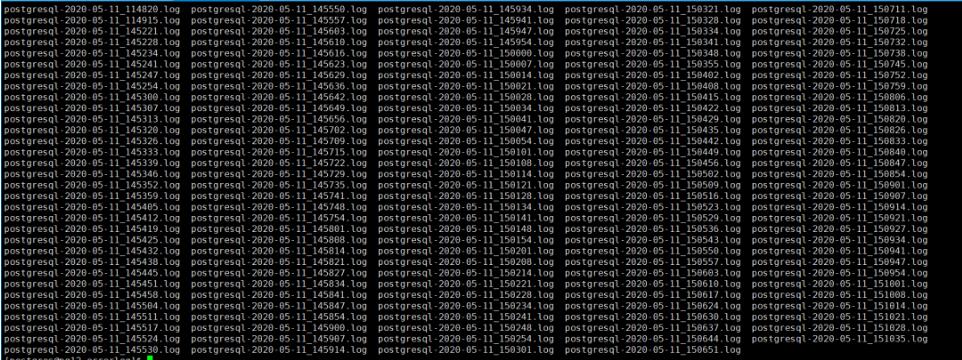
在搭建完PG后,系统上线前并无问题,在系统上线后第二天,有人反馈PG的日志将系统的磁盘空间大量的占用,并且7 分钟就产生一个日志文件,后续为了减少相关的日志的数量较快的增长,做了如下修改
log_rotation_size = 100MB
将日志的容量以及重置设置的更大
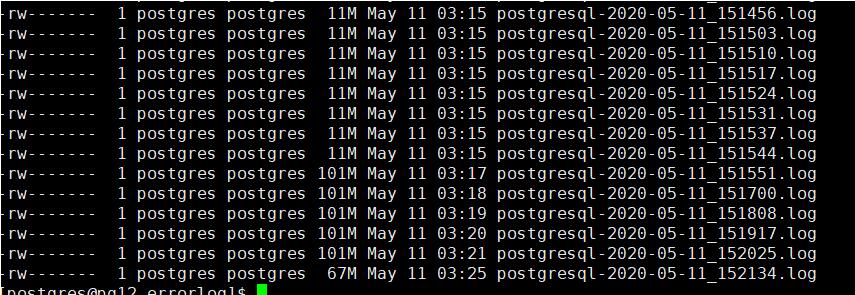
修改完毕后,不重新系统,直接加载后,日志的增长频率已经更改了。但日志的对磁盘空间的占用的问题还是没有解决。
打开日志,系统记录了大量如下的信息
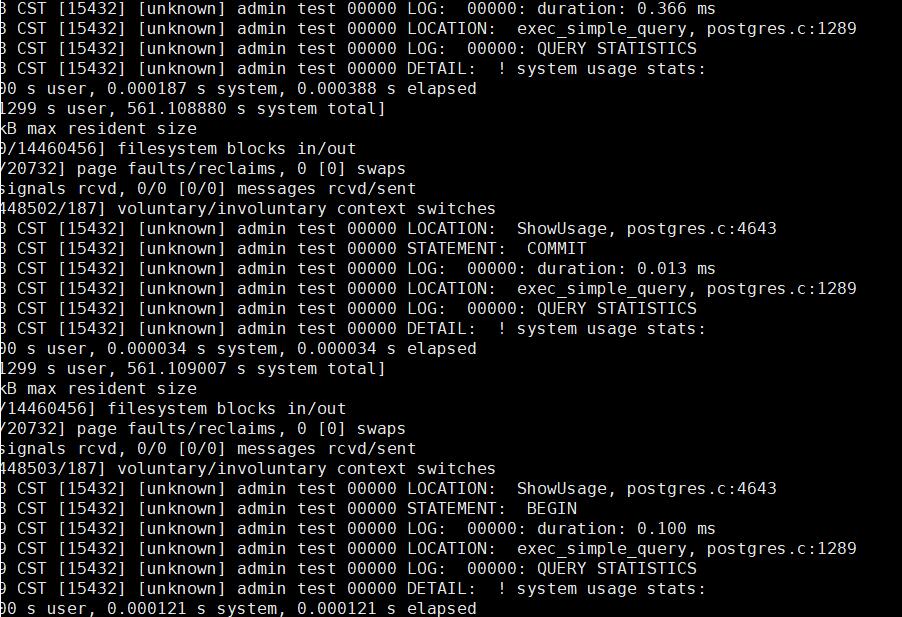
罪魁祸首就是下面图中的log_statement_stats 这个设置,将他打开后,系统会根据每个SQL 产生一个语句的性能方面的统计信息,可以想象如果将他打开可以看到每条语句在执行中的状态, duration 等等信息,但这样就会产生大量的日志,经过统计次系统1秒产生1MB的日志,(此系统每秒插入上百条数据),在关闭后,问题解决。
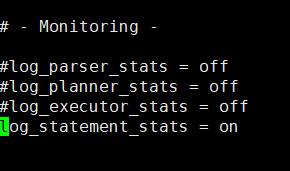
所以看似一个日志的设置,如果不熟悉系统,也会造成类似的问题,并且在紧急的状态下,可能会用较长的时间来解决。实际上日志系统还有一些其他的细节,例如时区的问题,找机会可以在说说吧
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-

postgresql减少wal日志生成量的操作
1.在繁忙的系统中,如果需要降低checkpoint发生的频率,减少WAL日志的生成量,减轻对系统IO的压力,可以通过以下两种方法. 1) 调整WAL segment大小,最高可以调整到64MB,不过只能通过编译来调整.对于已有系统不太方便: 2) 增大checkpoint_segments设置,使得checkpoint不会过于频繁地被触发: 2.在9.5中,checkpoint_segments被废弃,可以通过新增参数max_wal_size来调整,该参数缺省为1GB,已经是9.4的2倍.但如
-
关于PostgreSQL错误日志与慢查询日志收集
PostgreSQL错误日志与慢查询日志对于线上系统分析.问题预警.问题排查起到非常重要的作用,在此不做赘述. 此文档记录错误日志与慢查询日志的收集.分析与存储展示的方法. 一.总体思路 PostgreSQL日志输出可以配置多种多样的格式,其中以csvlog格式输出的日志信息最全面.但是CSV日志只能以本地文件的方式收集,不能直接写入网络,实时上传日志服务器. 日志收集: PostgreSQL服务器分布在不同的机器,我们使用rsyslog客户端-服务器的方式来收集日志到日志服务器.具体方法:在P
-
Postgresql的日志配置教程详解
背景 公司的项目中使用了postgresql(简称pg)作为其数据库管理系统,前两天环境突然崩溃了,页面无法打开.经过排查,我发现是数据库所在机器磁盘满了,通过目录和文件排序,原来是pg的日志太多(大约保留了大半年的日志在磁盘上没有被清理). 我看了下pg的日志配置,发现基本都是用的默认配置,日志滚动没有开启,于是乎做了下相关配置优化后对pg进行重启,最后看了pg的日志滚动,恢复正常了.以下是我梳理的关于pg的日志配置项. 配置详解 配置文件:postgresql.conf 配置1:日志开启与关
-
PostgreSQL归档配置及自动清理归档日志的操作
在一般的生产环境中,数据库都需要开启归档模式,那么在pg中如何开启归档模式呢? pg中的归档配置涉及几个参数如下: # - Archiving - 是否开启归档 #archive_mode = off # enables archiving; off, on, or always # (change requires restart) 归档命令,注意 %p %f %% 格式化的含义. %p 是被归档的redo文件的路径, %f 是被归档的redo文档的文件名 %% 是百分号 #archive_c
-
Postgresql 如何清理WAL日志
WAL是Write Ahead Log的简写,和oracle的redo日志类似,存放在$PGDATA/pg_xlog中,10版本以后在$PGDATA/pg_wal目录. 如果开启了归档,在目录archive_status下会有一些文件,以ready结尾的,表示可以归档但还没有归档,done结尾的表示已经归档. 和WAL日志数量相关的几个参数: wal_keep_segments = 300 # in logfile segments, 16MB each; 0 disables checkpoi
-
解决PostgreSQL日志信息占用磁盘过大的问题
当PostgreSQL启用日志时,若postgresql.conf日志的相关参数还使用默认值的话磁盘很容易被撑爆.因此在启用了logging_collector参数时,需要对其它相关的参数进行调整. 系统默认参数如下 #log_destination = 'stderr' #日志格式,值为stderr, csvlog, syslog, and eventlog之一. logging_collector = on #启用日志 #log_directory = 'log' #日志文件存储目录 #lo
-
docker清理大杀器/docker的overlay文件占用磁盘太大的解决
[看网上都是什么迁移文件的就感觉不靠谱,治标不治本啊(这不应该是一个新生代coder的样子)] du -sh* 一路查下去,发现overlay这个文件夹已经爆了. docker system prune -a 才清理了7g的空间,那个文件夹还是30g 磁盘占用路从100%下降到80%左右,这哪里行啊,再跑两天还是满! 最后大杀器来了 安装portainer docker安装教程一堆 我这里使用dokcer-compose部署的所以下面是配置 portainer: image: portainer
-
linux下使用 du查看某个文件或目录占用磁盘空间的大小方法
du -ah --max-depth=1 这个是我想要的结果 a表示显示目录下所有的文件和文件夹(不含子目录),h表示以人类能看懂的方式,max-depth表示目录的深度. du命令用来查看目录或文件所占用磁盘空间的大小.常用选项组合为:du -sh 一.du的功能:`du` reports the amount of disk space used by the specified files and for each subdirectory (of directory arguments)
-
OpenStack Ceilometer用MongoDB解决占用磁盘空间过大问题
OpenStack Ceilometer用MongoDB解决占用磁盘空间过大问题 背景:Ceilometer使用MongoDB作为数据库,不断进行采样,导致数据量膨胀,占用过多的磁盘空间. 知识背景 1.数据库文件类型 1.1. journal 日志文件 跟一些传统数据库不同,MongoDB的日志文件只是用来在系统出现宕机时候恢复尚未来得及同步到硬盘的内存数据.日志文件会存放在一个分开的目录下面.启动时候MongoDB会自动预先创建3个每个为1G的日志文件(初始为空). 1.2. namespa
-
PostgreSQL 打印日志信息所在的源文件和行数的实例
一直好奇在PG中, 当输出错误日志时, 如何能够附带错误信息所在的源代码文件名以及发生错误的代码行数. postgres.conf中, log信息冗余级别为"default(默认)", terse: 表示更加简单的日志信息, verbose: 表示更加冗余的日志信息(即: 附带"文件名和行数) #log_error_verbosity = default # terse, default, or verbose messages 修改为下面的"verbose&quo
-
解决Oracle数据库归档日志占满磁盘空间问题
1.常用命令 SQL> show parameter log_archive_dest; SQL> archive log list; SQL> select * from V$FLASH_RECOVERY_AREA_USAGE; ARCHIVELOG 96.62 0 141 SQL> select sum(percent_space_used)*3/100 from v$flash_recovery_area_usage; 2.9904 SQL> show paramete
-
解决MongoDB占用内存过大频繁死机的方法详解
从MongoDB 3.4开始,默认的WiredTiger内部缓存大小是以下两者中的较大者: 50%(RAM-1 GB),或 256 MB 例如,在总共有4GB RAM的系统上,WiredTiger缓存将使用1.5GB RAM(). 相反,总内存为1.25 GB的系统将为WiredTiger缓存分配256 MB,因为这是总RAM的一半以上减去1 GB(). // 4GB 0.5 * (4 GB - 1 GB) = 1.5 GB // 1.25GB 0.5 * (1.25 GB - 1 GB) =
-
c#.NET中日志信息写入Windows日志中解决方案
1. 目的 应用系统的开发和维护离不开日志系统,选择一个功能强大的日志系统解决方案是应用系统开发过程中很重要的一部分.在.net环境下的日志系统解决方案有许多种,log4net是其中的佼佼者. 在Windows2000及以上操作系统中,有一个Windows日志系统,它包括应用程序(Application)事件日志.系统(System)日志和安全(Security)日志,事件日志也可以是自定义日志.在.net Framework中也提供了相应的类和接口来使用应用程序事件日志或者自定义事件日志
-
关于docker清理Overlay2占用磁盘空间的问题(亲测有效)
使用Docker过程中,长时间运行服务容器,导致不能进行上传文件等操作,通过命令df -h 发现overlay占用较高.通过命令docker system prune -a 清理无用镜像.缓存.挂载数据,也没有什么改变. 如果你也被这个问题所困扰,咱们就一起看一下 Docker 是如何使用磁盘空间的,以及如何回收. docker 占用的空间可以通过下面的命令查看: $ docker system df prune指令默认会清除所有如下资源: 已停止的容器(container) 未被任何容器所使用
-
MySQL占用内存过大解决方案图文详解
目录 前言 解决方案 1. 找到配置文件 2. 修改配置文件 3. 重启MySQL 后记 前言 对于部分小资玩家来说,服务器数量和内存往往是很有限的,像我个人的服务器配置就是2核4G5M. 4G内存对于Java玩家来说,真的不大,开几个中间件+自己的微服务真的还蛮挤的,然后又摊上MySQL这个大冤种.我本机上的MySQL仅仅只占几M内存(虽然我不怎么用,但是本机MySQL确实是开着的): 而服务器的则要占400M,怎么说其实没什么吞吐量,纯粹是自己玩一玩,这内存占用属实有点吃不消啊... 解决方