Java 输入流中的read(byte[] b)方法详解
我就废话不多说了,大家还是直接看代码吧~
public int read(byte[] b) throws IOException
从一个输入流中读取一定数量的字节,并将这些字节存储到其缓冲作用的数组b中。这个函数会返回一次性读取的字节数。
这个函数是一个阻塞式的函数,当它读到有效数据、确认的文件尾(EOF)或者抛出一个异常时它才会执行其他语句,否则一直停在read()函数处等待。
比如下面的列子:
ServerSocket server = new ServerSocket(port) Socket client = server.accept(); BufferedInputStream bis = new BufferedInputStream(client.getInputStream);
byte[] box = new byte[1024];
int len = 0;
while(-1!=(len = bis.read(box))) {
System.out.println(len);
String msg = new String(box, 0, len);
}语句1;语句二;
在这种情况下,当从客户端接收了一条信息并转成msg字符串后,while循环会又回到read()函数,不会跳出循环执行语句一和二。
因为这时read()函数并没有遇到文件尾或者抛出异常,所以下一次while条件判断read()函数会一直等待有效数据的输入,而不是返回-1。此时整个程序将会阻塞在这里。
如果我们是从文件用这个函数以这种while循环方式读取数据的话并不会遇到这个问题,因为读到最后会遇到EOF的。
如果用这种方式读取控制台的输入的话,我们可以选择不要while循环。或者设置条件跳出循环,即如果len小于box的长度话就跳出循环。
我们还可以选择用DataInputStream的readUTF()函数也可以。还有就是我们可以采用监听机制,当监听到输入流中有数据之后再读取。
补充:教你完全理解IO流里的 read(),read(byte[]),read(byte[],int off,int len)以及write
好的我们先来讲它们的作用,然后再用代码来实现给大家看
read():
1.从读取流读取的是一个一个字节
2.返回的是字节的(0-255)内的字节值
3.读一个下次就自动到下一个,如果碰到-1说明没有值了.
read(byte[] bytes)
1.从读取流读取一定数量的字节,如果比如文件总共是102个字节
2.我们定义的数组长度是10,那么默认前面10次都是读取10个长度
3.最后一次不够十个,那么读取的是2个
4.这十一次,每次都是放入10个长度的数组.
read(byte[] bytes,int off ,int len)
1.从读取流读取一定数量的字节,如果比如文件总共是102个字节
2.我们定义的数组长度是10,但是这里我们写read(bytes,0,9)那么每次往里面添加的(将只会是9个长度),就要读12次,最后一次放入3个.
3.所以一般读取流都不用这个而是用上一个方法:read(byte[]);
下面讲解write
write(int i);
直接往流写入字节形式的(0-255)int值.
write(byte[] bytes);
往流里边写入缓冲字节数组中的所有内容,不满整个数组长度的”空余内容”也会加入,这个下面重点讲,
write(byte[] bytes,int off,int len);
1.这个是更严谨的写法,在外部定义len,然后每次len(为的是最后一次的细节长度)都等于流往数组中存放的长度
2.如上述read(bytes),前面每次都放入十个,第十一次放入的是2个,如果用第二种write(bytes),将会写入输出流十一次,每次写入十个长度,造成后面有8个空的,比原来的内容多了
3.所以用write(byte[] bytes,int off,int len);就不会出现多出来的空的情况,因为最后一次len不同
下面是详细的代码
public class Test{
public static void main(String[] args) throws Exception {
UseTimeTool.getInstance().start();
FileInputStream fis = new FileInputStream("D:\\1.mp3");
FileOutputStream fos = new FileOutputStream("D:\\1copy.mp3");
//(PS:一下3个大家分开来写和测试,为了方便我都列出来了)
/*--------------不使用缓冲--------------*/
//如果不缓冲,花了差不多14"秒"
int len = -1;
while ((len = fis.read()) != -1) {
//这里就不是长度的问题了,而是读取的字节"内容",读到一个写一个,相当慢.
System.out.println("len : "+ len);
fos.write(len);
}
/*--------------使用缓冲--------------*/
//缓冲方法复制歌曲用了不到20"毫秒"
//创建一个长度为1024的字节数组,每次都读取5kb,目的是缓存,如果不用缓冲区,用fis.read(),就会效率低,一个一个读字节,缓冲区是一次读5000个
byte[] bytes = new byte[1024*5];
//每次都是从读取流中读取(5k)长度的数据,然后再写到文件去(5k的)数据,注意,每次读取read都会不同,是获取到下一个,直到后面最后一个.
while (fis.read(bytes)!=-1) {
//write是最追加到文件后面,所以直接每次添5K.
fos.write(bytes);
}
/*--------------解释len--------------*/
//告诉你为什么用len
byte[] bytes = new byte[1024*5];
int len = -1;
//解释这个fis.read(bytes)的意思:从读取流"读取数组长度"的数据(打印len可知),并放入数组
while ((len = fis.read(bytes,0,1024)) != -1) {
//虽然数组长度的*5,但是这里我们设置了1024所以每次输出1024
System.out.println("len : "+ len);
//因为每次得到的是新的数组,所以每次都是新数组的"0-len"
fos.write(bytes,0,len);
}
fis.close();
fos.close();
UseTimeTool.getInstance().stop();
}
}
为了方便大家,也给大家一个统计时间的工具类
class UseTimeTool {
private static UseTimeTool utt = new UseTimeTool();
private UseTimeTool() {
}
public static UseTimeTool getInstance() {
return utt;
}
private long start;
public void start() {
start = System.currentTimeMillis();
}
public void stop() {
long end = System.currentTimeMillis();
System.out.println("所用時間 : " + (end - start) + "毫秒");
}
}
好了最后一个:len问题 最后多出数组不满的部分我特再写一个出来给大家分析
首先,文本的内容是
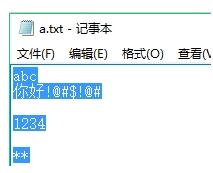
public class Test{
public static void main(String[] args) throws Exception {
UseTimeTool.getInstance().start();
FileInputStream fis = new FileInputStream("D:\\a.txt");
FileOutputStream fos = new FileOutputStream("D:\\acopy.txt");
不使用len:
byte[] bytes = new byte[1024*5];
while (fis.read(bytes)!=-1) {
fos.write(bytes);
}
得到的效果:

发现后续后很多的空部分,所以说不严谨
使用len:
byte[] bytes = new byte[1024*5];
int len = -1;
while ((len = fis.read(bytes,0,1024)) != -1) {
fos.write(bytes,0,len);
}
得到的效果

和原来一模一样,讲了那么多就是希望能帮助大家真正的理解。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
Java之InputStreamReader类的实现
InputStreamReader 类 1.概述 转换流 java.io.InputStreamReader ,是Reader的子类,是从字节流到字符流的桥梁. 该类读取字节,并使用指定的字符集将其解码为字符.它的字符集可以由名称指定,也可以接受平台的默认字符集. 2.继承自父类的共性成员方法 该类继承于 Reader 类,继承了父类的共性成员方法: int read() 读取单个字符并返回. int read(char[] cbuf)一次读取多个字符,将字符读入数组. void close()
-
Java BufferedReader相关源码实例分析
1.案例代码 假设b.txt存储了abcdegfhijk public static void main(String[] args) throws IOException { //字符缓冲流 BufferedReader bufferedReader=new BufferedReader(new FileReader (new File("H:\\ioText\\b.txt")),8); //存储读取的数据 char[] charsRead=new char[5]; //读取数据 b
-

Java中ThreadLocal的一些理解
前言 面试的时候被问到ThreadLocal的相关知识,没有回答好(奶奶的,现在感觉问啥都能被问倒),所以我决定先解决这几次面试中都遇到的高频问题,把这几个硬骨头都能理解的透彻的说出来了,感觉最起码不能总是一轮游. ThreadLocal介绍 ThreadLocal是JDK1.2开始就提供的一个用来存储线程本地变量的类.ThreadLocal中的变量是在每个线程中独立存在的,当多个线程访问ThreadLocal中的变量的时候,其实都是访问的自己当前线程的内存中的变量,从而保证的变量的线程安全.
-
java中ThreadLocal取不到值的两种原因
1.两种原因 第一种,也是最常见的一种,就是多个线程使用ThreadLocal 第二种,类加载器不同造成取不到值,本质原因就是不同类加载器造成多个ThreadLocal对象 public class StaticClassLoaderTest { protected static final ThreadLocal<Object> local = new ThreadLocal<Object>(); //cusLoader加载器加载的对象 private Test3 test3;
-
Java输入流Scanner/BufferedReader使用方法示例
1.使用Scanner 使用时需要引入包import java.util.Scanner;首先定义Scanner对象 Scanner sc = new Scanner(System.in);如果要输入整数,则 int n = sc.nextInt();String类型的,则String temp = sc.next(); 比如: 复制代码 代码如下: import java.util.Scanner; public class Test { @SuppressWarnings("resou
-
Java 输入流中的read(byte[] b)方法详解
我就废话不多说了,大家还是直接看代码吧~ public int read(byte[] b) throws IOException 从一个输入流中读取一定数量的字节,并将这些字节存储到其缓冲作用的数组b中.这个函数会返回一次性读取的字节数. 这个函数是一个阻塞式的函数,当它读到有效数据.确认的文件尾(EOF)或者抛出一个异常时它才会执行其他语句,否则一直停在read()函数处等待. 比如下面的列子: ServerSocket server = new ServerSocket(port) Soc
-
Java链表中元素删除的实现方法详解【只删除一个元素情况】
本文实例讲述了Java链表中元素删除的实现方法.分享给大家供大家参考,具体如下: 该部分与上一节是息息相关的,关于如何在链表中删除元素,我们一步一步来分析: 一.图示删除逻辑 假设我们需要在链表中删除索引为2位置的元素,此时链表结构为: 若要删除索引为2位置的元素,需要获取索引为2位置的元素之前的前置节点(此时为索引为1的位置的元素),因此我们需要设计一个变量prev来记录前置节点. 1.初始时变量prev指向虚拟头结点dummyHead: 2.寻找到前置节点位置,(对于该例子前置节点为索引为1
-
Java中Optional类及orElse方法详解
目录 引言 Java 中的 Optional 类 ofNullable() 方法 orElse() 方法 案例 orElseGet() 方法 案例 orElse() 与 orElseGet() 之间的区别 引言 为了让我更快的熟悉代码,前段时间组长交代了一个小任务,大致就是让我整理一下某个模块中涉及的 sql,也是方便我有目的的看代码,也是以后方便他们查问题(因为这个模块,涉及的判断很多,所以之前如果 sql 出错了,查问题比较繁琐). 昨天算是基本完成了,然后今天组长就让给我看一个该模块的缺陷
-
Java实现API sign签名校验的方法详解
目录 1. 前言 2. 签名生成策略 3. API 签名算法 Java 实现 4. 测试一下 1. 前言 目的:为防止中间人攻击. 场景: 项目内部前后端调用,这种场景只需要做普通参数的签名校验和过期请求校验,目的是为了防止攻击者劫持请求 url 后非法请求接口. 开放平台向第三方应用提供能力,这种场景除了普通参数校验和请求过期校验外,还要考虑 3d 应用的授权机制,不被授权的应用就算传入了合法的参数也不能被允许请求成功. 2. 签名生成策略 接下来详述场景 2,其实场景 1 也包含在场景 2
-
Java操作Excel文件解析与读写方法详解
目录 一.概述 二.Apache POI 三.XSSF解析Excel文件 1.Workbook(Excel文件) 2.Sheet(工作簿) 3.Row(数据行) 4.Cell(单元格) 四.超大Excel文件读写 1.使用POI写入 2.使用EasyExcel 一.概述 在应用程序的开发过程中,经常需要使用 Excel 文件来进行数据的导入或导出.所以,在通过Java语言实现此 类需求的时候,往往会面临着Excel文件的解析(导入)或生成(导出). 在Java技术生态圈中,可以进行Excel文件
-
struts2中使用注解配置Action方法详解
使用注解来配置Action可以实现零配置,零配置将从基于纯XML的配置转化为基于注解的配置.使用注解,可以在大多数情况下避免使用struts.xml文件来进行配置. struts2框架提供了四个与Action相关的注解类型,分别为ParentPackage.Namespace.Result和Action. ParentPackage:ParentPackage注解用于指定Action所在的包要继承的父包.该注解只有一个value参数.用于指定要继承的父包. 示例: 使用ParentPackage
-
java线程中start和run的区别详解
这篇文章主要介绍了java线程中start和run的区别详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 public class Test1 extends Thread { @Override public void run() { while (true) { System.out.println(Thread.currentThread().getName()); } } public static void main(String[
-
Spring Boot项目中定制拦截器的方法详解
这篇文章主要介绍了Spring Boot项目中定制拦截器的方法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 Servlet 过滤器属于Servlet API,和Spring关系不大.除了使用过滤器包装web请求,Spring MVC还提供HandlerInterceptor(拦截器)工具.根据文档,HandlerInterceptor的功能跟过滤器类似,但拦截器提供更精细的控制能力:在request被响应之前.request被响应之后.视
-
Java开发中synchronized的定义及用法详解
概念 是利用锁的机制来实现同步的. 互斥性:即在同一时间只允许一个线程持有某个对象锁,通过这种特性来实现多线程中的协调机制,这样在同一时间只有一个线程对需同步的代码块(复合操作)进行访问.互斥性我们也往往称为操作的原子性. 可见性:必须确保在锁被释放之前,对共享变量所做的修改,对于随后获得该锁的另一个线程是可见的(即在获得锁时应获得最新共享变量的值),否则另一个线程可能是在本地缓存的某个副本上继续操作从而引起不一致. 用法 修饰静态方法: //同步静态方法 public synchronized
-
Java 添加超链接到 Word 文档方法详解
在Word文档中,超链接是指在特定文本或者图片中插入的能跳转到其他位置或网页的链接,它也是我们在编辑制作Word文档时广泛使用到的功能之一.今天这篇文章就将为大家演示如何使用Free Spire.Doc for Java在Word文档中添加文本超链接和图片超链接. Jar包导入 方法一:下载Free Spire.Doc for Java包并解压缩,然后将lib文件夹下的Spire.Doc.jar包作为依赖项导入到Java应用程序中. 方法二:通过Maven仓库安装JAR包,配置pom.xml文件