keeplive+mysql+drbd高可用架构安装步骤
DRBD(DistributedReplicatedBlockDevice)是一个基于块设备级别在远程服务器直接同步和镜像数据的开源软件,类似于RAID1数据镜像,通常配合keepalived、heartbeat等HA软件来实现高可用性。
DRBD是一种块设备,可以被用于高可用(HA)之中.它类似于一个网络RAID-1功能,当你将数据写入本地文件系统时,数据还将会被发送到网络中另一台主机上.以相同的形式记录在一个文件系统中。
本地(master)与远程主机(backup)的保证实时同步,如果本地系统出现故障时,远程主机上还会保留有一份相同的数据,可以继续使用.在高可用(HA)中使用DRBD功能,可以代替使用一个共享盘阵.因为数据同时存在于本地主机和远程主机上,切换时,远程主机只要使用它上面的那份备份数据。
一、实施环境
系统版本:CentOS 6.5
DRBD版本: drbd-8.3.15
Keepalived:keepalived-1.1.15
Master:192.168.10.128
Backup:192.168.10.130
二、初始化配置
1) 在128、130两台服务器/etc/hosts里面都添加如下配置:
192.168.149.128 node1
192.168.149.130 node2
2) 优化系统kernel参数,直接上sysctl.conf配置如下:
net.ipv4.ip_forward = 0 net.ipv4.conf.default.rp_filter = 1 net.ipv4.conf.default.accept_source_route = 0 kernel.sysrq = 0 kernel.core_uses_pid = 1 net.ipv4.tcp_syncookies = 1 kernel.msgmnb = 65536 kernel.msgmax = 65536 kernel.shmmax = 68719476736 kernel.shmall = 4294967296 net.ipv4.tcp_max_tw_buckets = 10000 net.ipv4.tcp_sack = 1 net.ipv4.tcp_window_scaling = 1 net.ipv4.tcp_rmem = 4096 87380 4194304 net.ipv4.tcp_wmem = 4096 16384 4194304 net.core.wmem_default = 8388608 net.core.rmem_default = 8388608 net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 net.core.netdev_max_backlog = 262144 net.core.somaxconn = 262144 net.ipv4.tcp_max_orphans = 3276800 net.ipv4.tcp_max_syn_backlog = 262144 net.ipv4.tcp_timestamps = 0 net.ipv4.tcp_synack_retries = 1 net.ipv4.tcp_syn_retries = 1 net.ipv4.tcp_tw_recycle = 1 net.ipv4.tcp_tw_reuse = 1 net.ipv4.tcp_mem = 94500000 915000000 927000000 net.ipv4.tcp_fin_timeout = 1 net.ipv4.tcp_keepalive_time = 30 net.ipv4.ip_local_port_range = 1024 65530 net.ipv4.icmp_echo_ignore_all = 1
3)两台服务器分别添加一块设备,用于DRBD主设备存储,我这里为/dev/sdb 20G硬盘;
执行如下命令:
mkfs.ext3 /dev/sdb ;dd if=/dev/zero of=/dev/sdb bs=1M count=1;sync
三、DRBD安装配置
Yum方式安装:
rpm -Uvh http://www.elrepo.org/elrepo-release-6-6.el6.elrepo.noarch.rpm
yum -y install drbd83* kmod-drbd83 ; modprobe drbd
源码安装方式:
http://oss.linbit.com/drbd/8.4/drbd-8.4.4.tar.gz
./configure --prefix=/usr/local/drbd --with-km
make KDIR=/usr/src/kernels/2.6.32-504.el6.x86_64/
make install
cp drbd/drbd.ko /lib/modules/`uname -r`/kernel/lib/
Yum方式和源码方式都需要执行:modprobe drbd 加载DRBD模块。
安装完成并加载drbd模块后,vi修改/etc/drbd.conf配置文件,内容如下:
global {
usage-count yes;
}
common {
syncer { rate 100M; }
}
resource r0 {
protocol C;
startup {
}
disk {
on-io-error detach;
#size 1G;
}
net {
}
on node1 {
device /dev/drbd0;
disk /dev/sdb;
address 192.168.10.128:7898;
meta-disk internal;
}
on node2 {
device /dev/drbd0;
disk /dev/sdb;
address 192.168.10.130:7898;
meta-disk internal;
}
}
配置修改完毕后执行如下命令初始化:
drbdadm create-md r0 ;/etc/init.d/drbd restart ;/etc/init.d/drbd status
如下图:
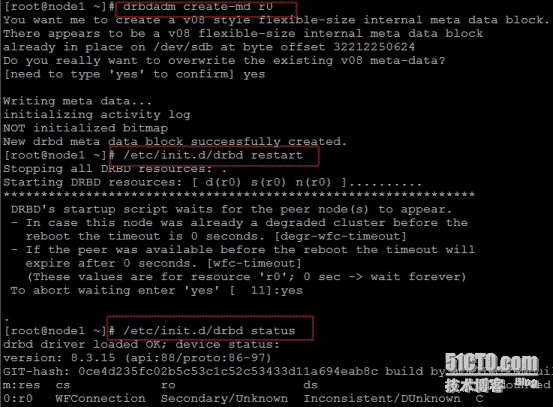
以上步骤,需要在两台服务器都执行,两台都配置完毕后,在node2从上面执行如下命令:/etc/init.d/drbd status 看到如下信息,表示目前两台都为从,我们需要设置node1为master,命令如下:
drbdadm -- --overwrite-data-of-peer primary all
mkfs.ext4 /dev/drbd0
mkdir /app ;mount /dev/drbd0 /app
自此,DRBD配置完毕,我们可以往/app目录写入任何东西,当master出现宕机或者其他故障,手动切换到backup,数据没有任何丢失,相当于两台服务器做网络RAID1。
四、Keepalived配置
wget http://www.keepalived.org/software/keepalived-1.1.15.tar.gz ; tar -xzvf keepalived-1.1.15.tar.gz ;cd keepalived-1.1.15 ; ./configure ; make ;make install
DIR=/usr/local/ ;cp $DIR/etc/rc.d/init.d/keepalived /etc/rc.d/init.d/ ; cp $DIR/etc/sysconfig/keepalived /etc/sysconfig/ ;
mkdir -p /etc/keepalived ; cp $DIR/sbin/keepalived /usr/sbin/
两台服务器均安装keepalived,并进行配置,首先在node1(master)上配置,keepalived.conf内容如下:
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
}
vrrp_script check_mysql {
script "/data/sh/check_mysql.sh"
interval 5
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 52
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.10.100
}
track_script {
check_mysql
}
}
然后创建check_mysql.sh检测脚本,内容如下:
#!/bin/sh
A=`ps -C mysqld --no-header |wc -l`
if
[ $A -eq 0 ];then
/bin/umount /app/
drbdadm secondary r0
killall keepalived
fi
添加node2(backup)上配置,keepalived.conf内容如下:
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
}
vrrp_sync_group VI{
group {
VI_1
}
notify_master /data/sh/master.sh
notify_backup /data/sh/backup.sh
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 52
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.10.100
}
}
创建master.sh检测脚本,内容如下:
#!/bin/bash drbdadm primary r0 /bin/mount /dev/drbd0 /app/ /etc/init.d/mysqld start
创建backup.sh检测脚本,内容如下:
#!/bin/bash /etc/init.d/mysqld stop /bin/umount /dev/drbd0 drbdadm secondary r0
发生脑裂恢复步骤如下:
Master执行命令:
drbdadm secondary r0
drbdadm -- --discard-my-data connect r0
drbdadm -- --overwrite-data-of-peer primary all
Backup上执行命令:
drbdadm secondary r0
drbdadm connect r0
相关推荐
-
MySQL高可用MMM方案安装部署分享
1 install mysql 请参考http://www.jb51.net/article/47094.htm 2. Basic configuration of master 1 3. Create users GRANT REPLICATION CLIENT ON *.* TO 'mmm_monitor'@'%' IDENTIFIED BY 'mmm_monitor'; GRANT SUPER, REPLICATION CLIENT, PROCESS ON *.* TO 'mmm_agen
-

Keepalived+HAProxy实现MySQL高可用负载均衡的配置
Keepalived 由于在生产环境使用了mysqlcluster,需要实现高可用负载均衡,这里提供了keepalived+haproxy来实现. keepalived主要功能是实现真实机器的故障隔离及负载均衡器间的失败切换.可在第3,4,5层交换.它通过VRRPv2(Virtual Router Redundancy Protocol) stack实现的. Layer3:Keepalived会定期向服务器群中的服务器.发送一个ICMP的数据包(既我们平时用的Ping程序),如果发现某台服务的
-
MySQL数据库的高可用方案总结
高可用架构对于互联网服务基本是标配,无论是应用服务还是数据库服务都需要做到高可用.虽然互联网服务号称7*24小时不间断服务,但多多少少有一些时候服务不可用,比如某些时候网页打不开,百度不能搜索或者无法发微博,发微信等.一般而言,衡量高可用做到什么程度可以通过一年内服务不可用时间作为参考,要做到3个9的可用性,一年内只能累计有8个小时不可服务,而如果要做到5个9的可用性,则一年内只能累计5分钟服务中断.所以虽说每个公司都说自己的服务是7*24不间断的,但实际上能做到5个9的屈指可数,甚至根本做不到
-
MySQL高可用解决方案MMM(mysql多主复制管理器)
一.MMM简介: MMM即Multi-Master Replication Manager for MySQL:mysql多主复制管理器,基于perl实现,关于mysql主主复制配置的监控.故障转移和管理的一套可伸缩的脚本套件(在任何时候只有一个节点可以被写入),MMM也能对从服务器进行读负载均衡,所以可以用它来在一组用于复制的服务器启动虚拟ip,除此之外,它还有实现数据备份.节点之间重新同步功能的脚本.MySQL本身没有提供replication failover的解决方案,通过MMM方案能实
-
MySQL下高可用故障转移方案MHA的超级部署教程
MHA介绍 MHA是一位日本MySQL大牛用Perl写的一套MySQL故障切换方案,来保证数据库系统的高可用.在宕机的时间内(通常10-30秒内),完成故障切换,部署MHA,可避免主从一致性问题,节约购买新服务器的费用,不影响服务器性能,易安装,不改变现有部署. 还支持在线切换,从当前运行master切换到一个新的master上面,只需要很短的时间(0.5-2秒内),此时仅仅阻塞写操作,并不影响读操作,便于主机硬件维护. 在有高可用,数据一致性要求的系统上,MHA 提供了有用的功能
-
详解MySQL高可用MMM搭建方案及架构原理
先来看看架构,如下图: 部署 1.修改hosts 在所有的服务器中执行相同的操作. vim /etc/hosts 192.168.137.10 master 192.168.137.20 backup 192.168.137.30 slave 192.168.137.40 monitor 2.添加mysql用户 只需要在所有的数据库端执行即可,监控端不需要. GRANT REPLICATION CLIENT ON *.* TO 'mmm_monitor'@'192.168.137.%' IDEN
-
keeplive+mysql+drbd高可用架构安装步骤
DRBD(DistributedReplicatedBlockDevice)是一个基于块设备级别在远程服务器直接同步和镜像数据的开源软件,类似于RAID1数据镜像,通常配合keepalived.heartbeat等HA软件来实现高可用性. DRBD是一种块设备,可以被用于高可用(HA)之中.它类似于一个网络RAID-1功能,当你将数据写入本地文件系统时,数据还将会被发送到网络中另一台主机上.以相同的形式记录在一个文件系统中. 本地(master)与远程主机(backup)的保证实时同步,如果本地
-
MySQL之高可用架构详解
目录 引言 MySQL高可用 一主一备: MySQL主从同步的几种模式: 总结 引言 "高可用"是互联网一个永恒的话题,先避开MySQL不谈,为了保证各种服务的高可用有几种常用的解决方案. 服务冗余:把服务部署多份,当某个节点不可用时,切换到其他节点.服务冗余对于无状态的服务是相对容易的. 服务备份:有些服务是无法同时存在多个运行时的,比如说:Nginx的反向代理,一些集群的leader节点.这时可以存在一个备份服务,处于随时待命状态. 自动切换:服务冗余之后,当某个节点不可用时,要做
-
MySQL高可用架构之MHA架构全解
目录 一.介绍 二.组成 三.工作过程 四.架构 五.实例展示 MHA(Master HA)是一款开源的 MySQL 的高可用程序,它为 MySQL 主从复制架构提供了 automating master failover 功能.MHA 在监控到 master 节点故障时,会提升其中拥有最新数据的 slave 节点成为新的master 节点,在此期间,MHA 会通过于其它从节点获取额外信息来避免一致性方面的问题.MHA 还提供了 master 节点的在线切换功能,即按需切换 master/sla
-
MySQL数据库实现高可用架构之MHA的实战
目录 一.MySQLMHA介绍 1.1什么是MHA? 1.2MHA的组成 1.3MHA的特点 二.MySQLMHA搭建 1.MHA架构部分 2.故障模拟部分 3.实验环境 三.实验步骤 1.关闭防火墙和SElinux 2.Master.Slave1.Slave2节点上安装mysql5.7 3.修改Master.Slave1.Slave2节点的主机名 4.修改Master.Slave1.Slave2节点的Mysql主配置文件/etc/my.cnf 5.在Master.Slave1.Slave2节点
-
MySQL之高可用集群部署及故障切换实现
一.MHA 1.概念 2.MHA 的组成 3.MHA 的特点 二.搭建MySQL+MHA 思路和准备工作 1.MHA架构 数据库安装 一主两从 MHA搭建 2.故障模拟 模拟主库失效 备选主库成为主库 原故障主库恢复重新加入到MHA成为从库 3.准备4台安装MySQL虚拟机 MHA高可用集群相关软件包 MHAmanager IP:192.168.221.30 MySQL1 IP:192.168.221.20 MySQL2 IP:192.168.221.100 MySQL3 IP: 192.168
-
MySQL系列之十四 MySQL的高可用实现
一.MHA 对主节点进行监控,可实现自动故障转移至其它从节点:通过提升某一从节点为新的主节点,基于主从复制实现,还需要客户端配合实现,目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库. 1.MHA工作原理 从宕机崩溃的master保存二进制日志事件(binlog events) 识别含有最新更新的slave 应用差异的中继日志(relay log)到其他的slave 应用从
-
MySQL数据库高可用HA实现小结
目录 MySQL数据库高可用HA实现 1. 数据库高可用分析 2.MySQL主从复制的容灾处理 1. 什么是数据库高可用 1.1. 什么是高可用集群 1.2. 高可用集群的衡量标准 1.3. 实现高可用的三种方式 1.4. MySQL数据的高可用实现 1.4.1. 主从方式(⾮对称) 1.4.2. 配置主从服务步骤 Master服务器配置 Slave服务器配置 主库授权 初始化数据 创建复制链路 从库的binlog是否写⼊? 问题:只同步其中三个表 1.4.2.1. GTID的⽅式来进⾏主从复制
-
Oracle和MySQL的高可用方案对比分析
关于Oracle和MySQL的高可用方案,其实一直想要总结了,就会分为几个系列来简单说说.通过这样的对比,会对两种数据库架构设计上的细节差异有一个基本的认识.Oracle有一套很成熟的解决方案.用我在OOW上的ppt来看,是MAA的方案,今年是这个方案的16周年了. 而MySQL因为开源的特点,社区里推出了更多的解决方案,个人的见解,InnoDB Cluster会是MySQL以后的高可用方案标配. 而目前来看,MGR固然不错,MySQL Cluster方案也有,PXC,Galera等方案,个人还
-
Ubuntu搭建Mysql+Keepalived高可用的实现(双主热备)
Mysql5.5双机热备 实现方案 安装两台Mysql 安装Mysql5.5 sudo apt-get update apt-get install aptitude aptitude install mysql-server-5.5 或 sudo apt-cache search mariadb-server apt-get install -y mariadb-server-5.5 卸载 sudo apt-get remove mysql-* dpkg -l |grep ^rc|awk '{
-
高可用架构etcd选主故障主备秒级切换实现
目录 什么是Etcd? 主备服务场景描述 jetcd具体实现 首先引入jetcd依赖 初始化客户端 关键api介绍 完整的测试用例 什么是Etcd? etcd是一个强大的一致性的分布式键值存储,它提供了一种可靠的方式来存储需要由分布式系统或机器群访问的数据.它优雅地处理网络分区期间的领导者选举,并且可以容忍机器故障,即使在领导者节点中也是如此.从简单的Web应用程序到Kubernetes,任何复杂的应用程序都可以读取数据并将数据写入etcd.这是官方对Etcd的描述,基于这些特性,Etcd常用于